- The paper introduces a modular framework that separates a trainable search planner from a frozen answer generator, enhancing efficiency and scalability.
- It employs a dual-reward mechanism aligning outcome quality and process coherence to achieve a Pareto-optimal balance between utility and cost.
- Empirical results show a 10.76% improvement over non-planning baselines, demonstrating strong generalization across various models and datasets.
Modular Agentic Search via Pareto-Optimal Multi-Objective Reinforcement Learning: The AI-SearchPlanner Framework
Motivation and Background
The integration of LLMs with search engines has become a central paradigm for knowledge-intensive reasoning tasks. While RAG architectures have enabled LLMs to access external information, their static retrieval mechanisms and lack of adaptive planning limit performance, especially for multi-hop and compositional queries. RL-based approaches have recently shown promise in enabling LLMs to learn search strategies through reward-driven multi-turn interactions. However, most prior RL-based search agents employ a monolithic LLM for both search planning and QA, constraining the optimization of each component and impeding scalability in real-world deployments where frozen, large LLMs are preferred for QA.
Framework Overview and Architectural Decoupling
AI-SearchPlanner introduces a modular agentic search framework that explicitly decouples the search planner and the answer generator. The search planner is a small, trainable LLM responsible for orchestrating multi-turn search interactions, while the generator is a large, frozen LLM dedicated to answer synthesis. This separation enables efficient training and deployment, allowing the planner to specialize in search strategy optimization and the generator to leverage its pre-trained QA capabilities.
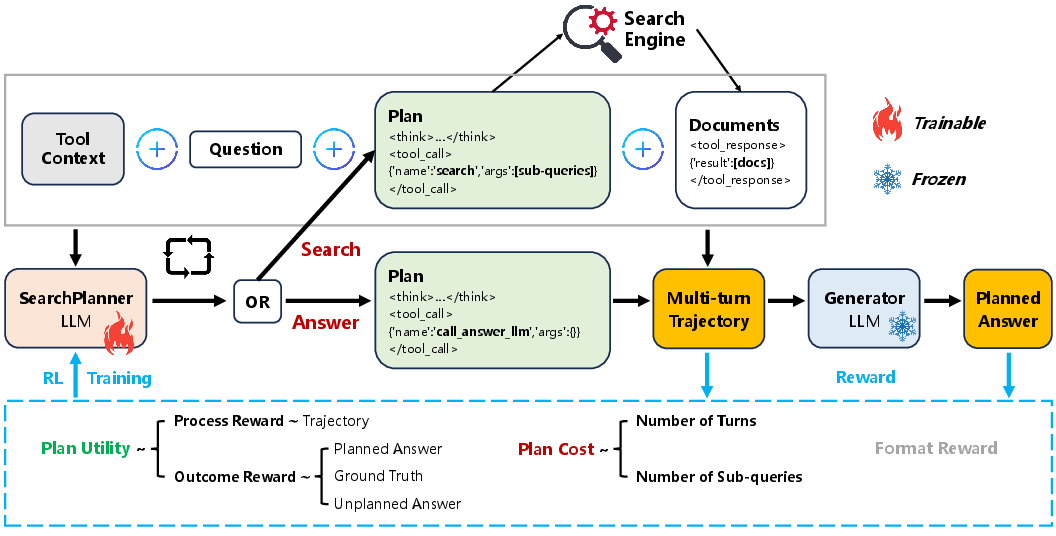
Figure 1: The overview of AI-SearchPlanner framework.
The planner iteratively decides whether to issue sub-queries to the search engine or to terminate and invoke the generator with the accumulated context. This modularity supports plug-and-play integration with various frozen LLMs and retrievers, facilitating transferability across domains and models.
Dual-Reward Alignment for Search Planning
A key innovation is the dual-reward mechanism for search planning, which aligns the planner's policy with both outcome-level and process-level objectives:
- Outcome Reward quantifies the performance gain of search planning over non-planning baselines (direct inference, naive RAG), using an LLM-based scoring function for answer correctness.
- Process Reward evaluates the rationality and coherence of the search trajectory, penalizing unclear references, redundant queries, and inefficient strategies via a prompt-based rubric.
The combined utility reward ensures that the planner not only improves answer accuracy but also generates interpretable, efficient search trajectories.
Pareto Optimization of Utility and Cost
AI-SearchPlanner formalizes search planning as a multi-objective RL problem, balancing planning utility (answer quality, trajectory rationality) against planning cost (number of search turns, sub-query frequency). The overall reward is:
Rpareto=Rutility+α⋅Rcost+Rformat
where α controls the trade-off between utility and cost, and Rformat enforces output correctness. By varying α, the framework explores the Pareto frontier, enabling practitioners to select operating points that optimize for either performance or efficiency.
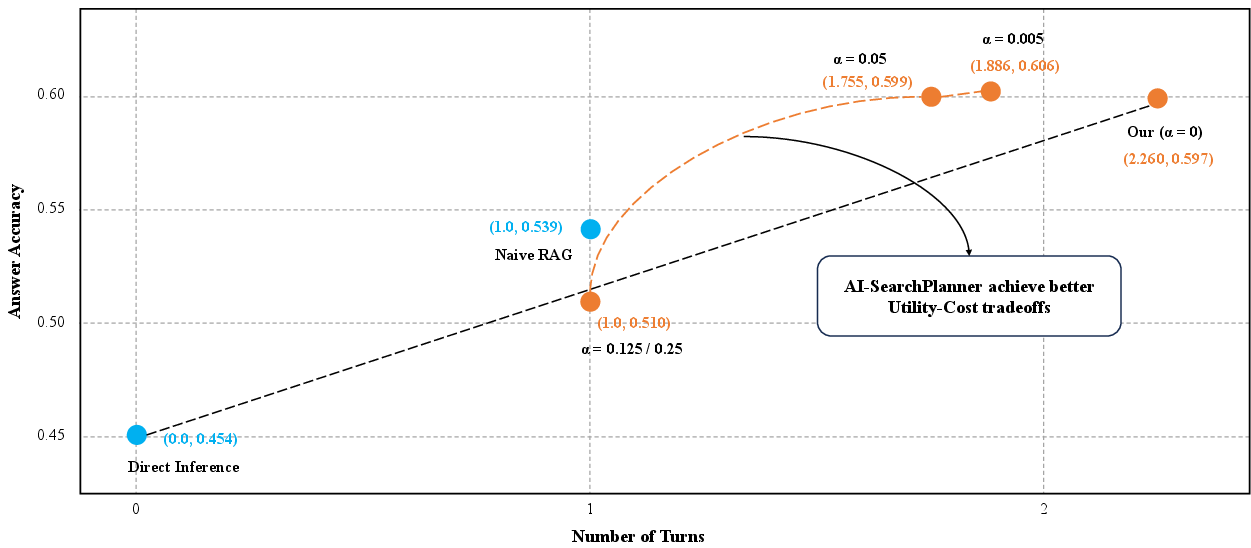
Figure 2: Utility-Cost tradeoffs on Wikipedia-based datasets. Blue points: non-planning baselines; orange points: AI-SearchPlanner with different cost coefficient α.
Reinforcement Learning Training and Implementation
The planner is trained using PPO, with loss masking applied to retrieved tokens to prevent gradient interference from environmental observations. Each rollout consists of a full search trajectory, culminating in answer generation by the frozen LLM and reward computation. The RL objective is:
L(θ)=Eτ∼πθ[t=0∑Tmin(πold(at∣st)πθ(at∣st)At,clip(πold(at∣st)πθ(at∣st),1−ϵ,1+ϵ)At)]
This approach is agnostic to the choice of retriever and generator, supporting flexible deployment.
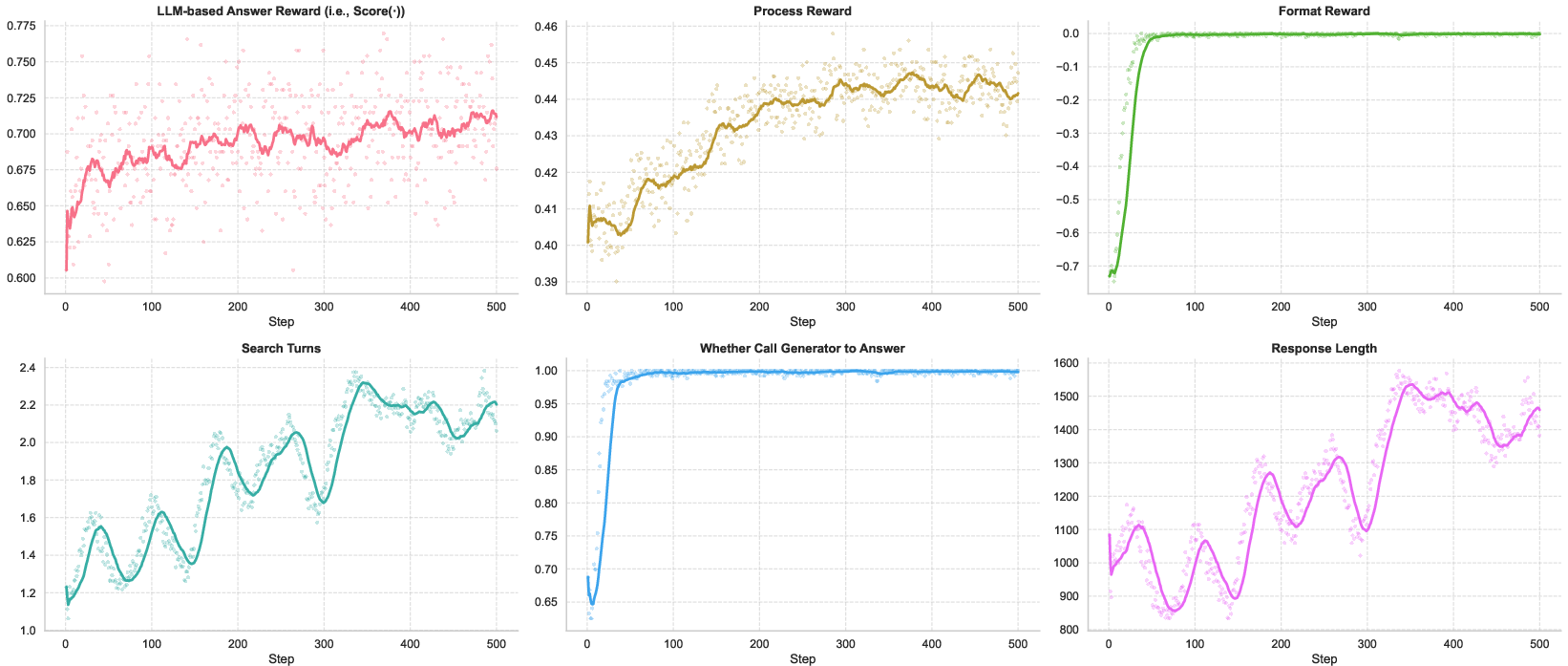
Figure 3: Training dynamics of AI-SearchPlanner with cost coefficient α=0.
Empirical Results and Analysis
Experiments on seven Wikipedia-based and two web-based datasets demonstrate that AI-SearchPlanner consistently outperforms non-planning and planning baselines in both answer accuracy and efficiency. Notably:
- With α=0, AI-SearchPlanner achieves a 10.76% improvement in average QA accuracy over the best non-planning baseline on Wikipedia datasets.
- The model exhibits strong generalization across frozen generators (Qwen3-32b, Deepseek-V3, Deepseek-R1) and domains, with robust transferability to web-based QA tasks.
- Increasing α reduces planning cost (number of turns) with only marginal initial loss in accuracy, enabling practitioners to tune for latency or resource constraints.
- Ablation studies confirm that both outcome and process rewards are necessary for optimal performance, and RL training of the planner is essential for generalization to complex multi-hop queries.
Implementation Considerations
- Resource Requirements: The decoupled architecture allows the planner to be lightweight, reducing inference latency and memory footprint compared to monolithic RL agents.
- Deployment: The modular design supports integration with production QA systems using frozen LLMs, retrievers, and search APIs.
- Limitations: The framework relies on the quality of the retriever and the frozen generator; suboptimal retrieval or answer synthesis can bottleneck overall performance. The LLM-based scoring function for answer correctness may introduce evaluation bias if not calibrated.
Implications and Future Directions
AI-SearchPlanner advances the agentic search paradigm by enabling modular, efficient, and transferable search planning. The Pareto optimization framework provides a principled approach to balancing answer quality and computational cost, which is critical for real-world applications with latency or resource constraints. The dual-reward alignment mechanism ensures that search trajectories are both effective and interpretable, supporting downstream auditing and debugging.
Future research may extend this framework to multi-modal search tasks, incorporate dynamic reward shaping for improved generalization, and explore hierarchical planner architectures for even more complex reasoning scenarios. The modularity of AI-SearchPlanner positions it as a foundation for scalable, adaptive agentic search systems in both academic and industrial settings.
Conclusion
AI-SearchPlanner presents a modular RL-based framework for agentic search, decoupling search planning from answer generation and optimizing for both utility and cost via Pareto frontier exploration. Empirical results demonstrate superior performance and efficiency over existing baselines, with strong generalization across models and domains. The framework's innovations in dual-reward alignment and multi-objective optimization have significant implications for the design of scalable, resource-efficient AI search systems. Future work should investigate extensions to multi-modal reasoning and dynamic reward mechanisms to further enhance adaptability and robustness.

