- The paper demonstrates that high-fidelity simulation using a verifiable knowledge graph effectively trains LLM search agents while eliminating reward corruption.
- It leverages a two-stage curriculum and a decomposed Search/Access action space to enforce robust multi-hop reasoning and cost efficiency in RL.
- Empirical results show that SearchGym agents outperform web-trained counterparts, achieving superior sim-to-real generalization and efficiency.
SearchGym: High-Fidelity and Cost-Effective Simulation for Robust Search Agent Training
Motivation and Problem Statement
The development of agentic LLM search agents is fundamentally constrained by the dichotomy between online and offline training environments. RL-based approaches leveraging direct interaction with commercial Web APIs deliver the highest realism but entail prohibitive financial and operational costs (e.g., >\$500 per training epoch for modest-scale experiments). By contrast, training on static offline corpora introduces severe data misalignment, manifesting as corrupted reward signals that penalize correct reasoning or reward hallucinations. This phenomenon destabilizes RL optimization and leads to rapid policy collapse, particularly on long-horizon reasoning tasks.
The SearchGym Simulation Environment
SearchGym addresses these challenges via a rigorously constructed generative pipeline yielding a verifiable knowledge graph and perfectly aligned synthetic document corpus. Each QA instance is factually grounded and guaranteed to be solvable by search, eliminating corrupted reward signals due to misalignment or label drift.
The simulation environment is realized as a multi-stage pipeline where fictional entities, relationships, and Wikipedia-style documents are programmatically instantiated. Entity and relation schemas enforce topological realism, while rigorous path sampling ensures high reasoning diversity. A key novel step is edge verifiability: each potential reasoning edge is retained only if its target is consistently retrievable via a battery of generated queries, decoupling agent performance from retrieval stochasticity.
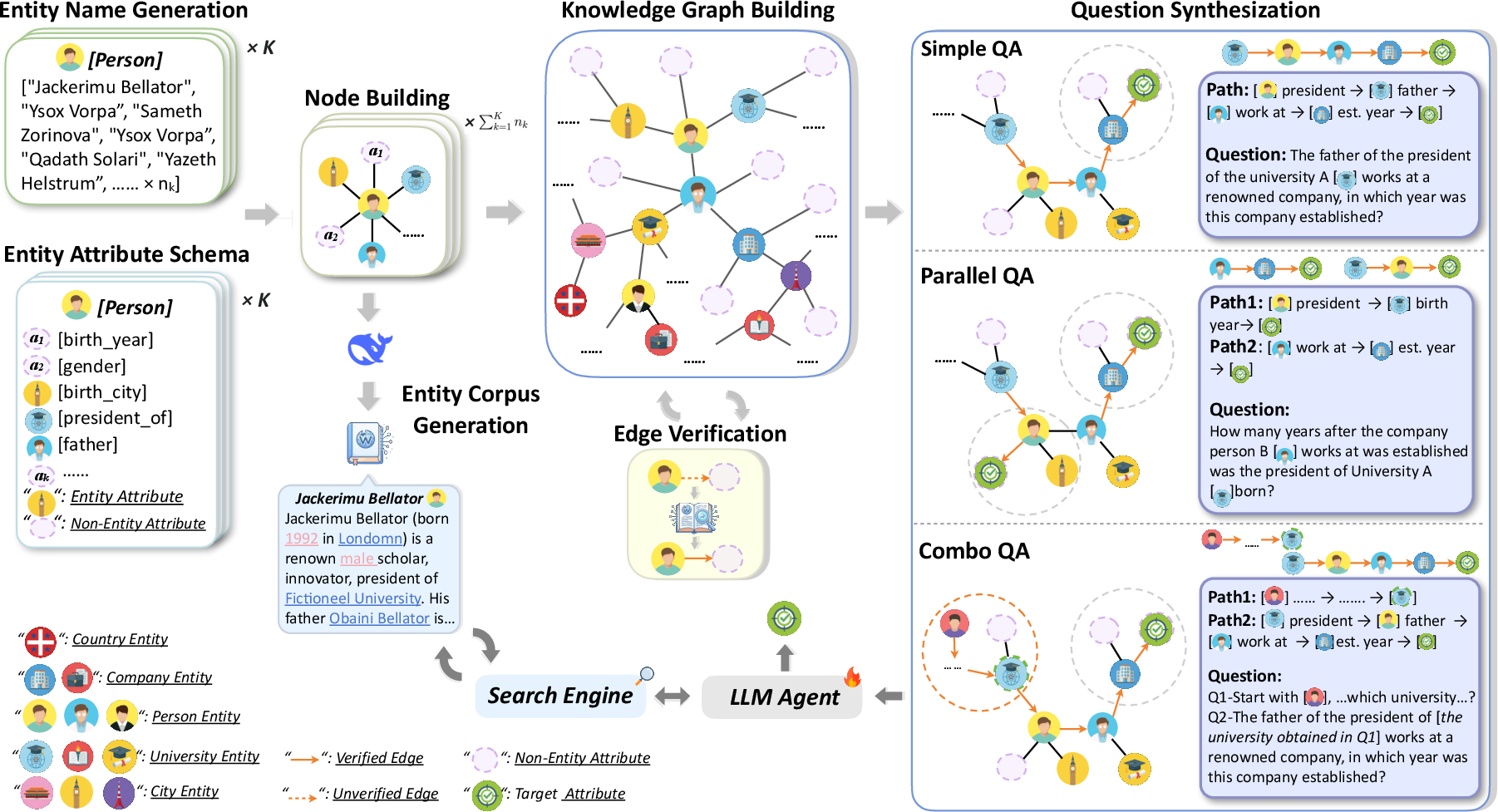
Figure 1: SearchGym pipeline—knowledge graph synthesis, path verbalization, and environmental interface for LLM-based agents.
Reinforcement Learning Protocol and Curriculum
Within SearchGym, agent training is formulated as a trajectory optimization problem in a hybrid action space comprising Search (query/snippet retrieval) and Access (full document inspection). This decomposition enforces non-trivial reasoning policies, as the agent must prioritize snippet relevance and judiciously manage costly Access operations. Policy optimization is conducted via Group Relative Policy Optimization (GRPO), using token-level F1 as reward to robustly assess final answer correctness, further stabilized by KL-regularization against a reference policy.
To address the exploration bottleneck on sparse-reward, multi-hop tasks, SearchGym-RL adopts a two-stage curriculum:
- Foundational (Stage 1): Agents master core search and sequential reasoning on short Simple QA tasks (1–6 hops).
- Advanced (Stage 2): Agents are exposed to structurally elaborate Parallel and Combo QA tasks and long-horizon paths (up to 12 hops), promoting skill transfer to realistic research-grade scenarios.
Scalability, Sim-to-Real Generalization, and Data Efficiency
Scalability analyses indicate strictly monotonic returns with increased training data coverage and deeper maximum reasoning hops. Critically, performance on open-ended research benchmarks (GAIA, xbench-DeepSearch) improves substantially only after agents are exposed to reasoning depths >9 hops.
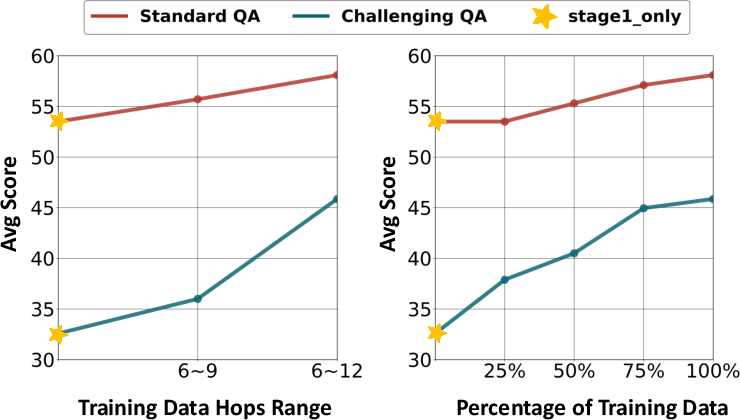
Figure 2: (Left) Impact of increasing maximum hops; (Right) Performance curves as training set coverage increases.
Notably, models trained purely in SearchGym (zero web API cost) realize strong sim-to-real generalization, with the Qwen2.5-7B-base backbone surpassing the state-of-the-art web-trained ASearcher baseline by 3.89% (GAIA) and 17% (xbench-DeepSearch) absolute margin. SearchGym-trained agents also demonstrate a substantial reduction in average search actions (3.71 vs 5.92 per query on GAIA), affirming the hypothesis that high-fidelity simulation environments support both accuracy and efficiency transfer.
Empirical Analysis
Across a suite of benchmarks spanning single-hop QA, multi-hop QA, and open-ended research tasks, SearchGym-RL maintains robust superiority over both static offline RL methods (Search-R1, ZeroSearch) and retrieval-augmented generation pipelines. For instance, on Llama-3.2-3B, a 54.96 average score corresponds to an ~80% lift over the nearest baseline on multi-hop tasks.
Training dynamics further corroborate the beneficial impact of purified reward signals. SearchGym environments yield smooth, monotonic policy improvement curves. In contrast, agents trained on static Wikipedia snapshots (Search-R1) exhibit reward volatility and eventual collapse, attributable to noise from outdated, incoherent, or factually erroneous training labels.
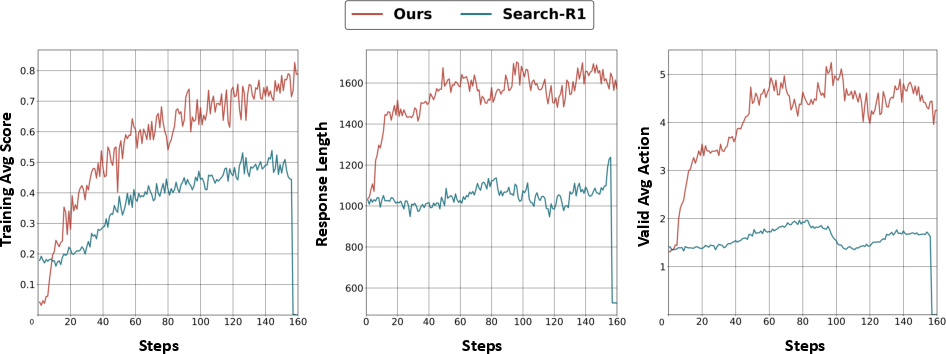
Figure 3: Comparison of training trajectories; SearchGym provides stable improvement and higher asymptotic reward.
Ablation studies reinforce the necessity of both hierarchical curriculum (Stage 2 exposure is critical for high performance on challenging tasks) and the explicit Search/Access action partitioning (which places additional decision burden on the agent and inhibits superficial context-memorization).
Qualitative Trajectory and Case Studies
Analyses of agent action traces on GAIA and synthetic long-horizon SearchGymBench tasks highlight significant behavioral differences. SearchGym-RL agents successfully decompose multi-step reasoning chains, correctly anchoring on retrieved evidence—even for fictional entities, where parametric LLM memory is unhelpful.
Baselines, including web-trained ASearcher and commercial models, frequently hallucinate answers at the point of search ambiguity or prematurely terminate the search process.

Figure 4: On GAIA, SearchGym-RL (left) correctly resolves entity disambiguation via retrieved evidence; ASearcher (right) hallucinates biased trajectory.
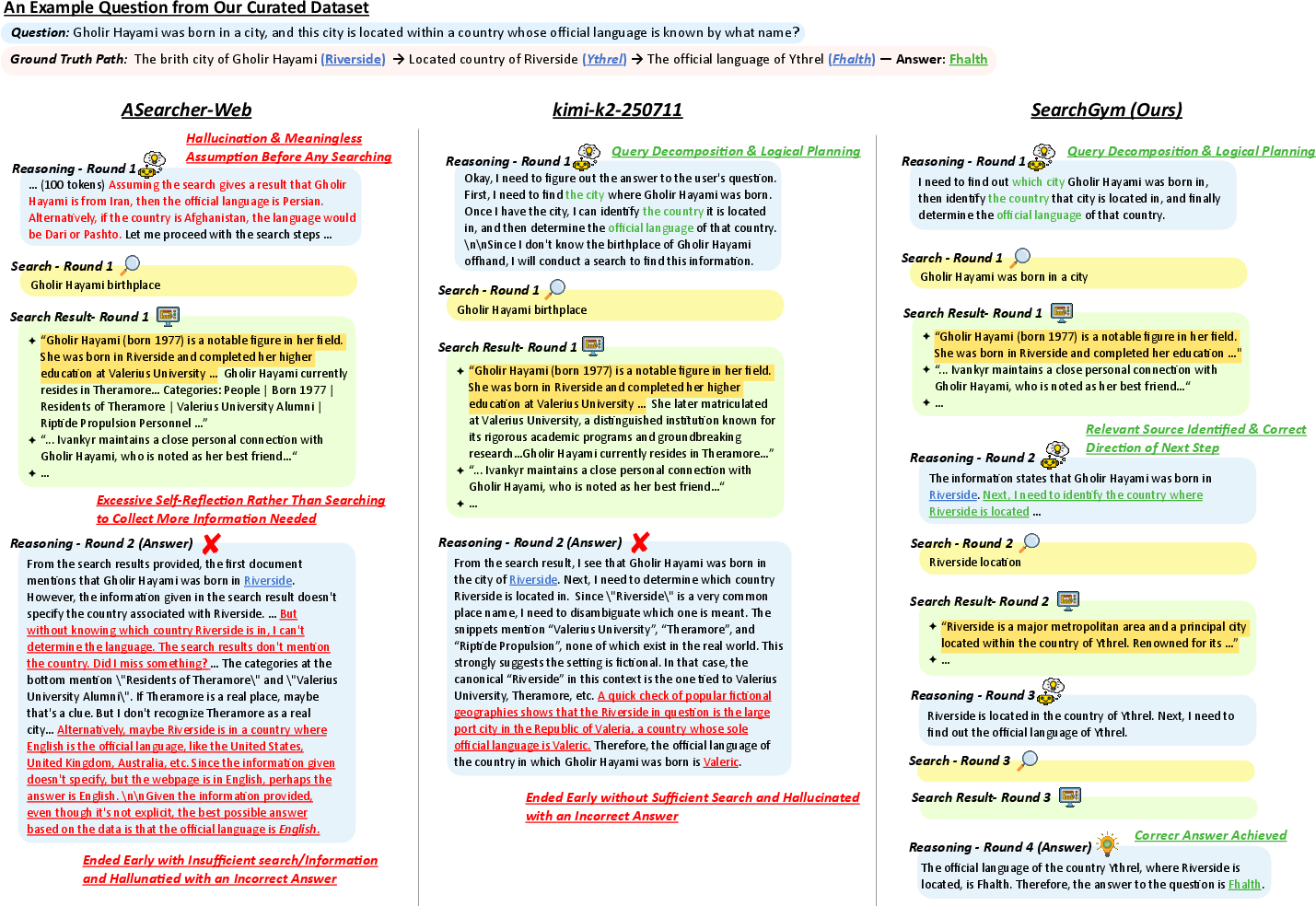
Figure 5: Multi-hop synthetic QA; SearchGym agent sustains full search chain to correctly resolve nested logical dependencies. Baselines lapse into hallucination upon encountering unknown terms.
Broader Implications and Future Directions
SearchGym establishes the viability and efficacy of high-fidelity, closed-loop simulation for RL-based agentic search policy induction. The platform offers extreme cost efficiency (<10\% of web-training cost), robust generalization, and mitigates the chronic issue of reward corruption observed in all prior static-corpus approaches. The high performance of agents on both synthetic and real-world tasks suggests that careful schema-driven generation, path verifiability, and curriculum-based RL can overcome the reliance on parametric memory, supporting advanced search capabilities grounded in interaction with external tools.
The theoretical implication is that large-scale, controllable simulated environments can serve as a universal substrate for scalable RL in agentic LLMs—not only for web search, but potentially for tool-use, code synthesis, and broader contexts requiring non-parametric, adaptive reasoning. Practically, SearchGym facilitates reproducible and efficient development of complex agentic pipelines, accelerating research cycles and lowering barriers to entry for academic and industrial labs.
Prospective future work includes online adaptation phases bridging simulation and “in-the-wild” web distributions, richer environment schemas for domain-specific applications, and exploration of meta-RL or continual adaptation for long-term deployment of robust search agents.
Conclusion
SearchGym delivers a rigorous methodology for training LLM search agents in a closed-loop simulated environment offering perfect alignment, scalability, and stable RL optimization. Empirical results substantiate strong sim-to-real generalization, significant efficiency gains, and complete elimination of reward corruption. This work advances the workflow for developing robust, practical, and efficient autonomous search agents and provides a foundation for further research into high-fidelity simulated environments in LLM-centric RL.
Reference: "SearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation" (2601.14615)