- The paper introduces a simulated web search environment enabling fully offline, scalable RL training that outperforms larger models with a 4B parameter agent.
- It leverages a curriculum-driven RL protocol and co-evolving synthetic datasets to foster continuous agent improvement while reducing redundancy.
- Empirical results demonstrate significant cost and latency reductions, with performance parity or superiority to high-cost online systems.
LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agents
Motivation and Overview
LiteResearcher addresses two tightly coupled bottlenecks impeding scalable reinforcement learning (RL) for LLM-based agentic research: the inability of hand-crafted synthetic data to drive genuine real-world search competence, and the instability and prohibitive costs inherent in RL training environments dependent on live internet interactions. The framework develops a scalable, stable, and isolated virtual world mirroring real web search dynamics, providing RL agents with the necessary scale, diversity, and controllability for sustained improvement. Crucially, LiteResearcher achieves parity or superiority relative to much larger open-source and proprietary models on key research benchmarks—all with only a 4 billion parameter agent.
System Architecture and Methodology
The central innovation of LiteResearcher lies in the orchestration of data-corpus co-evolution, the construction of a local tool environment, and a curriculum-driven RL protocol (Figure 1(#figure2)). These components form the backbone of the scalable training stack. The corpus is continuously enriched by iteratively synthesizing training queries and appending related webpages returned from live searches, ensuring a massively diverse and evolving base over which tool-based agent interaction is realized.
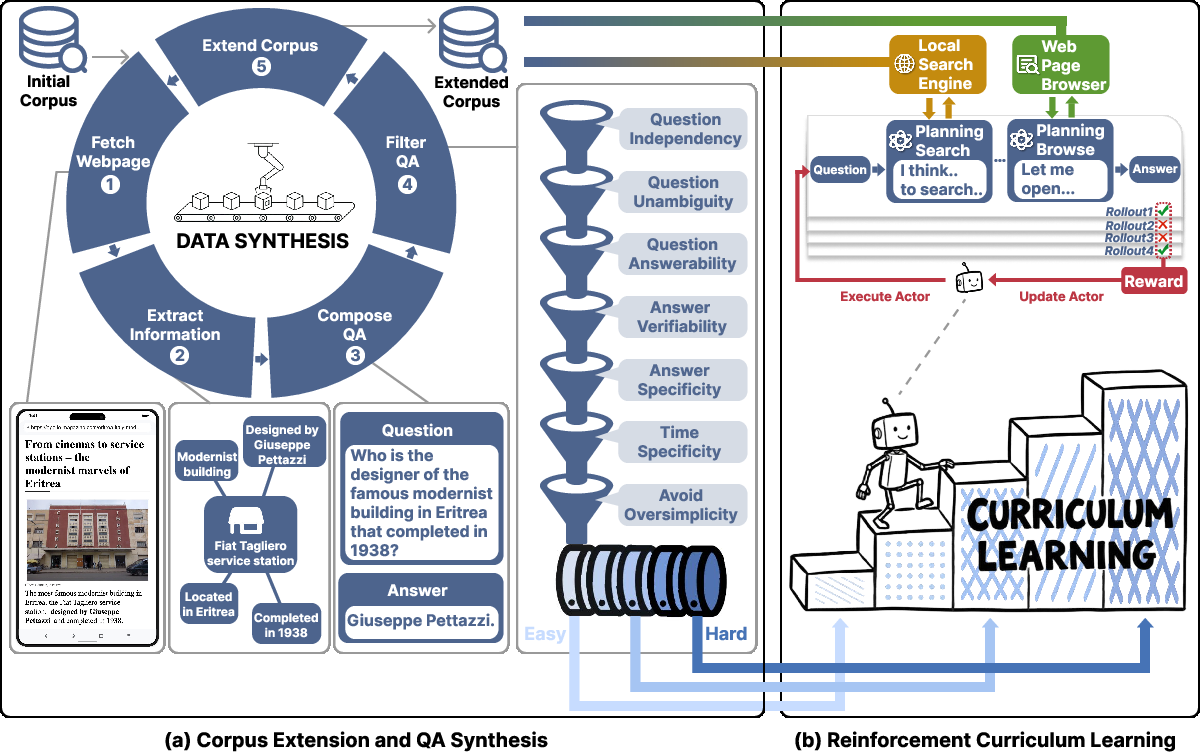
Figure 1: System overview comprising co-evolving corpus/data generation and a curriculum-driven RL loop in a local simulated search environment, enabling scalable offline agent training.
Synthetic QA tasks are generated with careful coverage of five atomic research skills—direct information retrieval, aggregation, enumeration, cross-verification, and statistical extraction—each mapped from factual entities in seed corpora and subsequently expanded via masking and rigorous filtering. The local web corpus, reaching over 32M unique pages spanning 1M+ domains, is then indexed to power high-throughput, deterministic, query/browse tool APIs, which successfully approximate live web search dynamics (Figure 2(#figure5)).
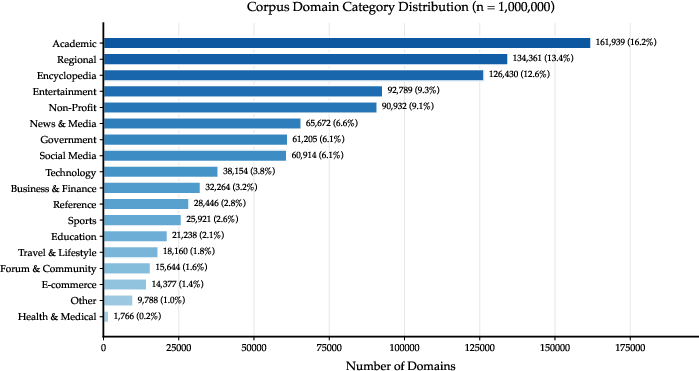
Figure 2: Domain composition of the local corpus evidences broad coverage, closely reflecting the distributional structure of real-world web content.
Hard task selection and progression is automated by difficulty-aware filters, implemented via pass@8 performance thresholds for each candidate query. This practice robustly eliminates both trivial and impossible samples, ensuring continuous learning signal throughout multi-stage curriculum RL. The on-policy GRPO optimization framework is preferred—contrasted with more unstable off-policy variants—resulting in consistently monotonic reward improvements as shown in controlled comparisons (Figure 3(#figure3)).
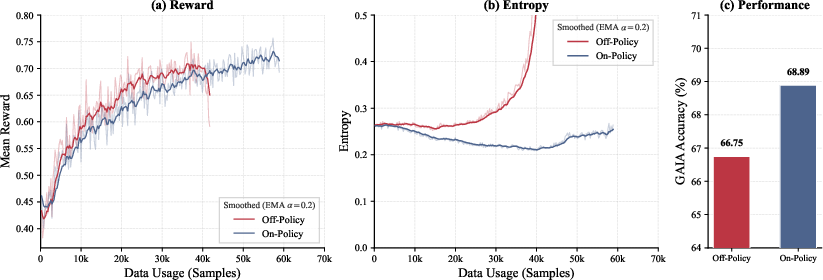
Figure 3: On-policy GRPO training manifests higher accuracy and more stable reward dynamics compared to off-policy methods.
Progression through curriculum stages allows the agent to escape the stagnation typically seen in single-stage RL in complex research environments, sustaining incremental accuracy increases at each escalation in query difficulty (Figure 4(#figure4)).
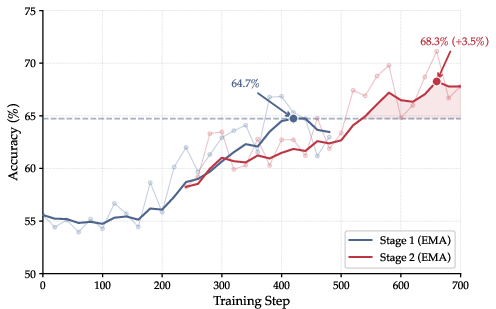
Figure 4: Two-stage curriculum RL overcomes performance plateaus seen with static task distributions, yielding continuous improvement on GAIA accuracy.
Empirical Results
LiteResearcher-4B demonstrates strong empirical results, achieving 71.3% on GAIA and 78.0% on Xbench-DeepSearch, decisively surpassing all open-source baselines up to 8× its parameter scale and matching or exceeding proprietary giants such as Claude-4.5 Sonnet and GLM-4.6 (Figure 5(#figure1)). Crucially, this performance comes at a fraction of their inference cost and rollout latency, enabled by the highly optimized local tool stack.
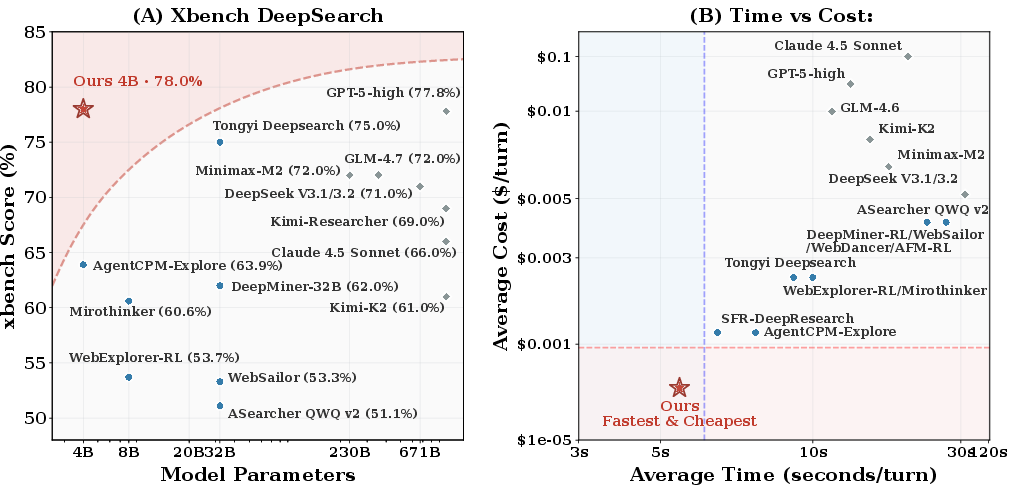
Figure 5: Left: Benchmark accuracy on Xbench DeepSearch for models of various scales; right: Rollout latency and per-turn cost, with LiteResearcher-4B providing a compelling performance-efficiency tradeoff.
Moreover, experiments confirm that the agent trained fully offline in the local simulated environment generalizes at least as well as, if not better than, agents trained via high-cost and high-variance online APIs. Further ablations indicate that a high-diversity, co-evolving synthetic dataset underlies these gains; removing the synthetic component leads to marked performance degradation.
The RL protocol not only boosts accuracy, but effectually eliminates detrimental repetition and loop artifacts inherited from the SFT phase, as evidenced by pronounced decreases in mean response length, interaction count, and context-overflow clipping—despite the absence of explicit penalties for length or redundancy (Figure 6(#figure7)).
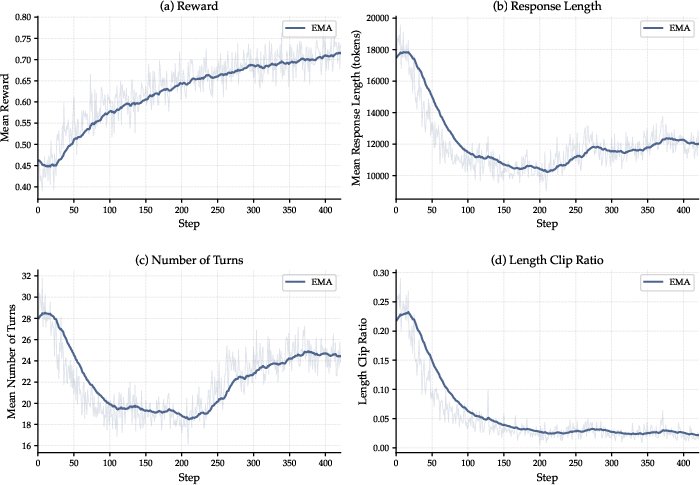
Figure 6: RL stage corrects repetitive SFT artifacts, reducing trajectory length, interaction count, and clipping, with clear reward gains solely from the outcome-based signal.
Training dynamics across the curriculum further show increasing tool sophistication: early RL saturates by pruning redundancy, while subsequent stages drive up tool usage and trajectory complexity as the agent addresses harder queries and leverages extended context (Figure 7(#figure8)).
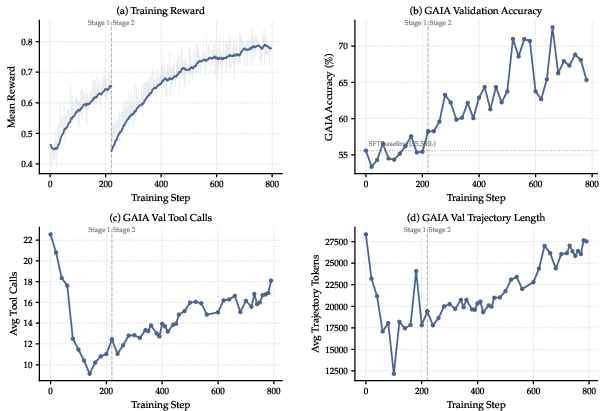
Figure 7: Metrics over RL show initial redundancy reduction followed by increased tool complexity and longer, more purposeful search as curriculum advances.
Infrastructure and Scalability
The fully local corpus and search/browse stack, with dense and sparse embedding fusion and efficient page-level indexing, delivers orders-of-magnitude lower latency and cost compared to relying on commercial search/Browse APIs. Over 73.2M tool calls during RL incur zero marginal cost and ensure consistent, reproducible results that are unachievable with live internet dependence.
Implications and Directions
Practically, LiteResearcher establishes that high-impact research-capable RL agents can be trained fully offline, at minimal hardware scale and cost, provided the data-environment axis is adequately provisioned. The decoupling of training from internet APIs democratizes both agent development and downstream deployment in privacy-critical and resource-constrained settings.
Theoretically, these results challenge prevailing assumptions about necessary LLM scale for competent research agents. They suggest that agent environment and data design—particularly diversity, task difficulty calibration, and environment determinacy—are as determinative as parameter count for real-world generalization in agentic RL.
Future work should focus on extending corpus evolution protocols (e.g., incorporating multimodal context, dynamic temporal ground truth), scaling curriculum depth, and exploiting further tool augmentation (e.g., code execution, mathematical solvers) to push the frontier on research complexity solvable by lightweight agents.
Conclusion
LiteResearcher demonstrates that scalable agentic RL for deep research is both feasible and highly effective when grounded in a simulated, richly diversified, and locally provisioned environment. By leveraging virtual online-like tool APIs, adaptive synthetic datasets, and curriculum-driven RL, LiteResearcher-4B achieves open-source state-of-the-art on major benchmarks despite modest scale, at fraction of latency and cost. These findings emphasize that future advances in LLM-based research agents should prioritize scalable, diversity-rich environment simulation and disciplined RL pipeline management alongside model architecture exploration.

