- The paper introduces a novel tree-structured reasoning framework that enriches information-seeking tasks with entity-intensive synthetic data.
- It develops three task synthesis variants and uses dual metrics (ISR and ISE) to ensure both effective and efficient agent training.
- The hybrid reward system with GRPO and extensive ablation studies demonstrate superior performance on multiple challenging benchmarks.
WebLeaper: Enhancing WebAgent Efficiency and Efficacy via Info-Rich Seeking
Introduction
WebLeaper addresses a critical bottleneck in LLM-based information-seeking (IS) agents: the inefficiency of search behaviors, which is attributed to the sparsity of target entities in conventional training tasks. The framework introduces a novel approach to IS task synthesis and trajectory curation, aiming to simultaneously optimize both the completeness and efficiency of information gathering. By formulating IS as a tree-structured reasoning problem and leveraging entity-intensive synthetic data, WebLeaper systematically increases the density and complexity of IS tasks, thereby providing a more robust training signal for agentic reasoning and decision-making.
Tree-Structured Reasoning and Task Synthesis
WebLeaper models IS as a tree-structured reasoning process, enabling the inclusion of a substantially larger set of target entities within a constrained context. The framework introduces three task synthesis variants:
- Version-I (Basic): Constructs a simple reasoning tree from a single structured information source (e.g., a Wikipedia table). The root node represents the question entity, the second layer contains key entities (e.g., authors), and the third layer encodes their attributes (e.g., nationality, award year).
- Version-II (Union): Increases task complexity by uniting reasoning trees from multiple sources that share common relations in their subtrees. This requires the agent to perform relational joins (e.g., intersection of Nobel and Booker Prize winners) and integrate evidence across heterogeneous sources.
- Version-III (Reverse-Union): Further elevates reasoning difficulty by reversing the logical flow. The agent is provided with fuzzed clues (third-layer entities) as the query, necessitating deduction of an anchor entity (second layer) before executing a union-based search for the final answer set.
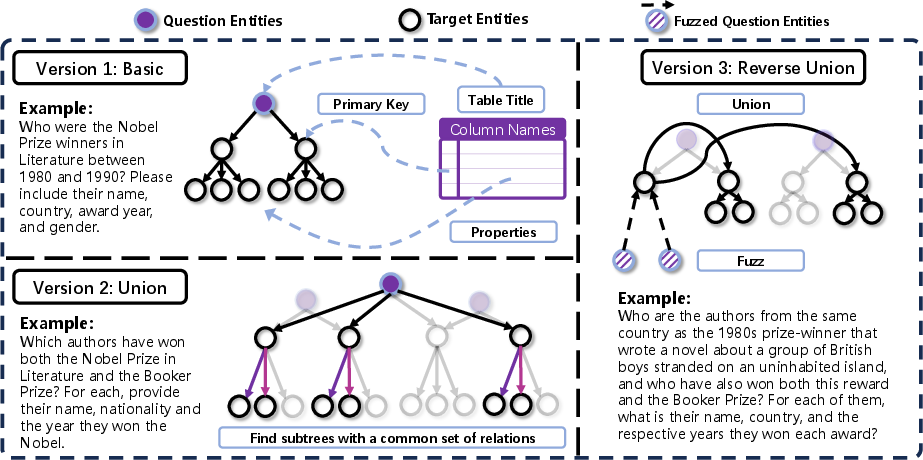
Figure 1: Overview of WebLeaper's three task synthesis variants, illustrating the progression from single-source reasoning to complex, multi-source, and reverse-logic tasks.
This hierarchical and compositional task design not only increases the number of target entities per instance but also enforces multi-hop, multi-source reasoning, mitigating shortcut exploitation and promoting generalizable search strategies.
WebLeaper introduces a dual-metric filtering mechanism for trajectory curation:
- Information-Seeking Rate (ISR): Measures the fraction of required entities successfully retrieved, providing a direct signal for completeness.
- Information-Seeking Efficiency (ISE): Quantifies the average number of action steps per discovered entity, incentivizing concise and targeted search behaviors.
Only trajectories that satisfy both high ISR and ISE thresholds are retained for training, ensuring that the agent is exposed to solution paths that are both accurate and efficient. Theoretical analysis demonstrates that the variance of ISE decreases as the number of target entities increases, making it a stable and reliable metric for complex, entity-rich tasks.
Hybrid Reward System and Reinforcement Learning
To address the reward sparsity and evaluation brittleness in RL for entity-intensive tasks, WebLeaper implements a hybrid reward system:
- For synthetic, entity-rich tasks, a granular F-score-based reward is computed using soft precision and recall, with semantic similarity scoring at the entity level to accommodate minor variations (e.g., "USA" vs. "United States").
- For legacy benchmark data, the original reward functions are preserved.
This hybridization enables fine-grained, scalable, and robust policy optimization. The agent is trained using Group Relative Policy Optimization (GRPO), which standardizes rewards within trajectory groups, further stabilizing learning.
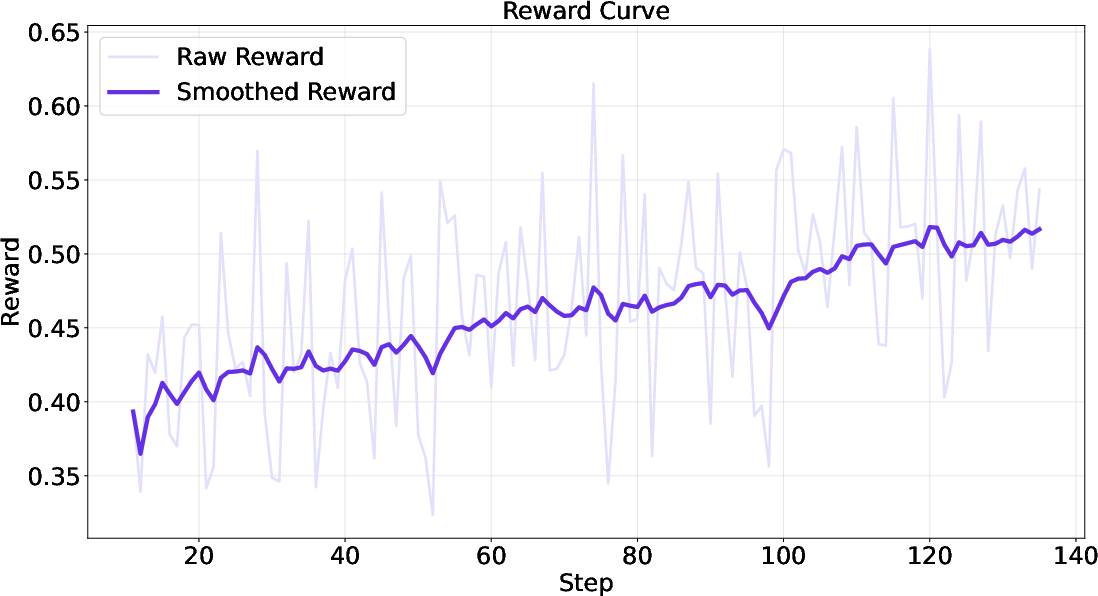
Figure 2: Training curve of the hybrid reward system, demonstrating stable reward improvement during RL with WebLeaper data.
Empirical Results and Analysis
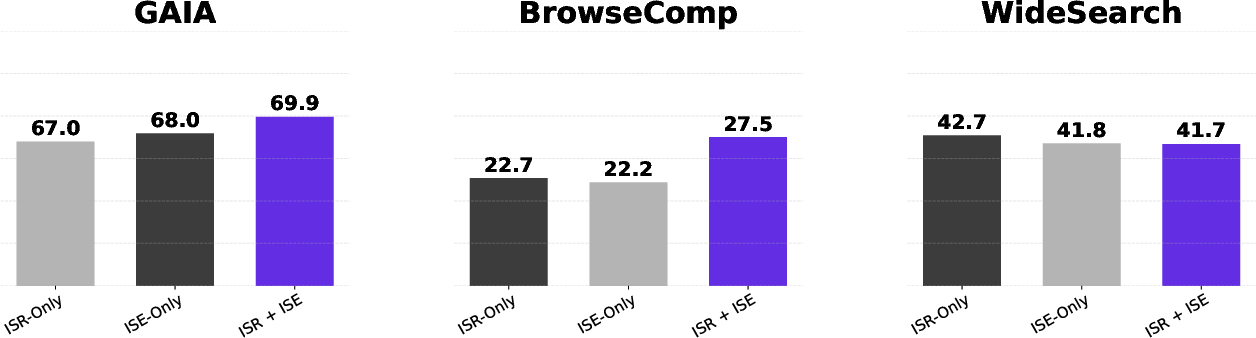
WebLeaper is evaluated on five challenging IS benchmarks: BrowseComp, GAIA, xbench-DeepSearch, WideSearch, and Seal-0. The framework consistently outperforms strong open-source baselines and achieves performance competitive with proprietary agents on most tasks.

Figure 3: WebLeaper's results on comprehensive training settings, showing superior accuracy and success rates across multiple benchmarks.
Ablation studies reveal that:
Efficiency-effectiveness trade-off analysis demonstrates that WebLeaper achieves higher task performance with fewer tool calls compared to baselines, indicating a more targeted and cost-effective search strategy.
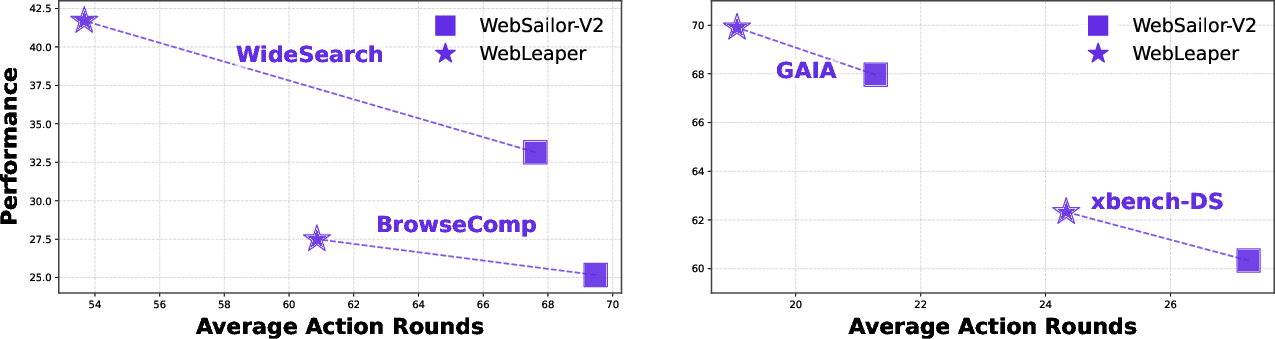
Figure 5: WebLeaper vs. WebSailor-V2: joint effectiveness and efficiency comparison, with WebLeaper dominating in both dimensions.
Data Distribution and Task Complexity
The training data synthesized by WebLeaper exhibits a high degree of entity richness, with a significant portion of samples containing over 100 entities. This complexity is essential for robustly measuring and optimizing search efficiency.
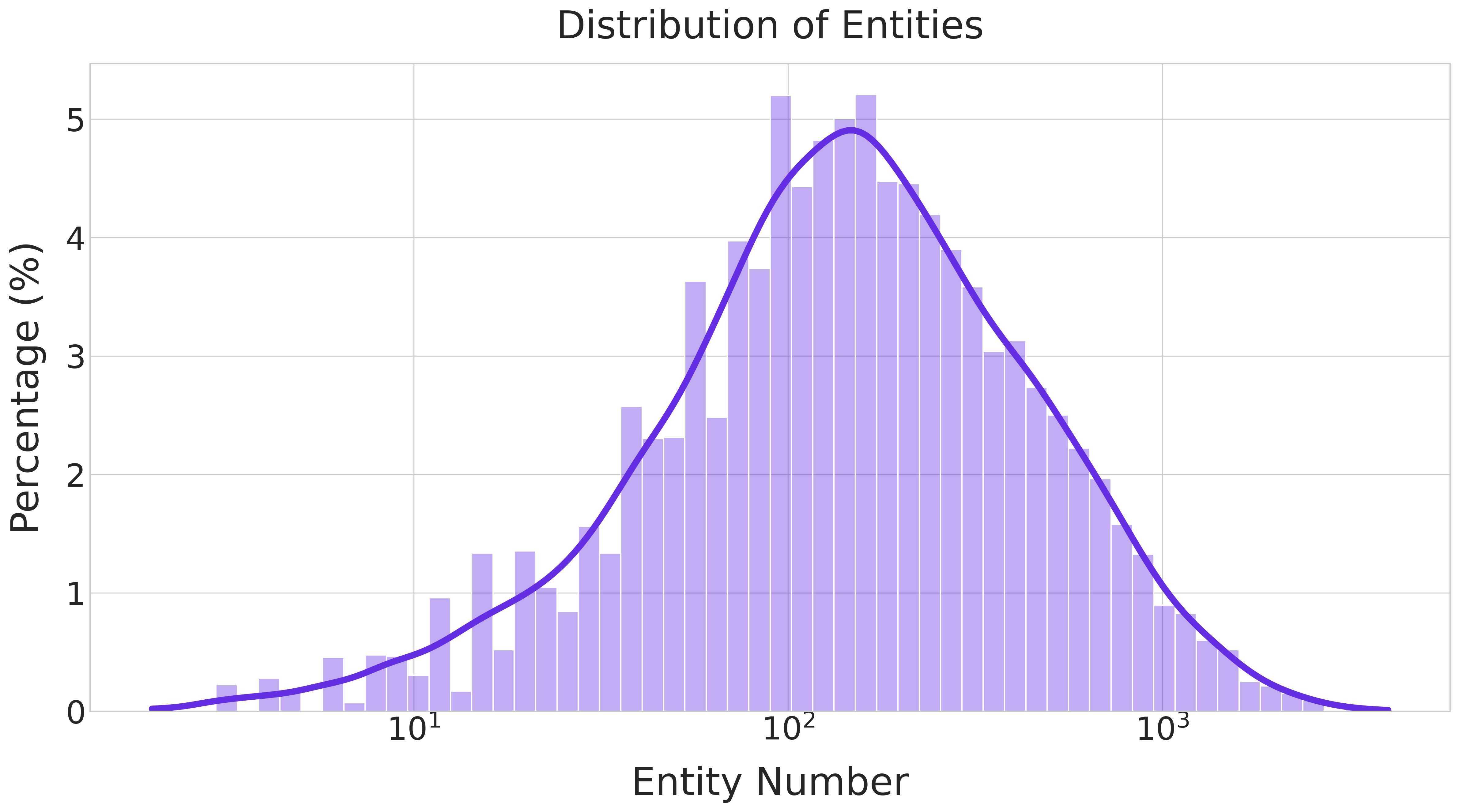
Figure 6: Entity count distribution in training data, emphasizing the prevalence of high-entity tasks and their role in stabilizing efficiency metrics.
Implications and Future Directions
WebLeaper's approach demonstrates that increasing the semantic and structural richness of IS tasks, coupled with rigorous trajectory curation and hybrid reward optimization, can substantially enhance both the efficiency and efficacy of web-based LLM agents. The framework's design principles—entity-intensive task synthesis, multi-source reasoning, and efficiency-oriented supervision—are broadly applicable to other domains requiring complex, long-horizon information gathering.
Practically, WebLeaper's methodology can be extended to domains such as scientific literature review, legal research, and enterprise knowledge management, where comprehensive and efficient information acquisition is critical. Theoretically, the work suggests that future advances in agentic reasoning will require not only architectural innovations but also the systematic enrichment of training environments and reward structures.
Conclusion
WebLeaper provides a comprehensive solution to the inefficiency of LLM-based IS agents by introducing entity-rich, tree-structured task synthesis, information-guided trajectory curation, and a hybrid reward system for RL. The framework achieves strong empirical results, with notable improvements in both effectiveness and efficiency across multiple benchmarks. The work establishes a new paradigm for training and evaluating web agents, emphasizing the importance of info-rich seeking and efficient reasoning in the development of next-generation autonomous systems.