- The paper introduces a dual-grained efficiency-aware RL framework that fuses visual grounding and retrieval for concurrent multi-entity search.
- It demonstrates significant improvements, achieving up to +9.9% accuracy boost and 7.6× efficiency gains with fewer tool-call rounds.
- The work establishes a unified grounded search paradigm and the IMEB benchmark, paving the way for robust, energy-efficient multimodal assistants.
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
Motivation and Paradigm Shift
HyperEyes introduces a paradigm shift in multimodal search agent design by directly addressing the operational inefficiency inherent in conventional sequential search agents. Standard multimodal agents process decomposable queries through successive tool invocations—each entity is localized and retrieved in its own interaction round—resulting in redundant tool calls, compounded latency, and error propagation across lengthy reasoning chains. HyperEyes advocates the "search wider, not longer" principle: it fuses visual grounding and retrieval so multiple entities are concurrently processed in a single atomic action, leveraging parallel multimodal pathways for efficient search.
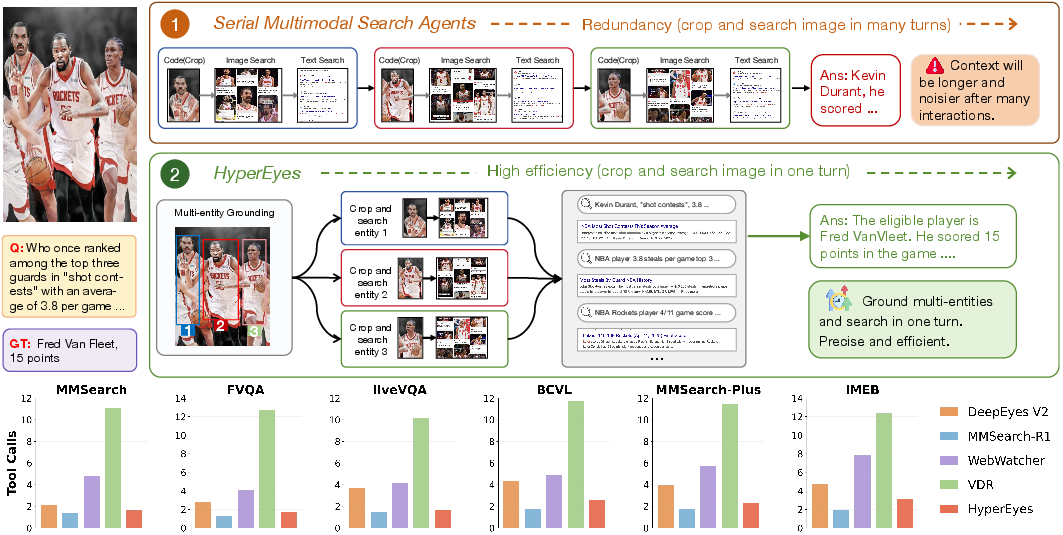
Figure 1: HyperEyes avoids the redundancy of conventional serial multimodal search agents by grounding and searching multiple entities in one turn.
This design decouples entity identification from downstream reasoning, reducing both overall token consumption and latency. Accuracy and efficiency are treated as complementary objectives in HyperEyes, rather than competing factors as in prior work.
Methodological Overview
HyperEyes employs a two-phase training framework to realize strict parallel dispatch behavior that minimizes tool-call round redundancy and optimizes accuracy:
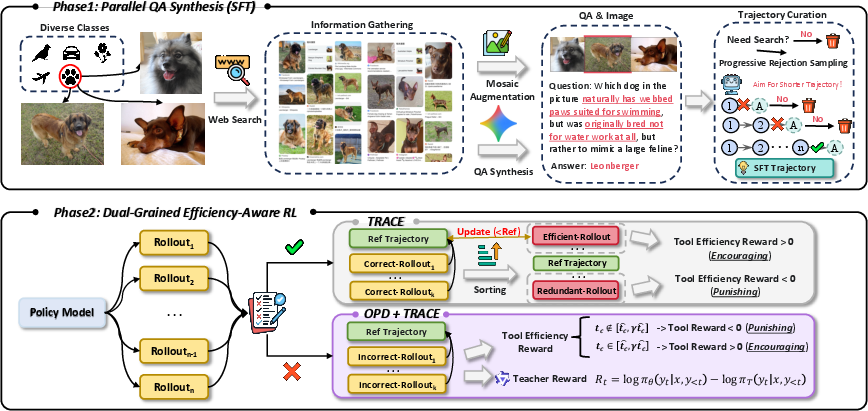
Figure 2: The HyperEyes training framework: parallel-amenable data synthesis and dual-grained efficiency-aware RL jointly optimize for concurrent multimodal search behaviors.
Parallel-Amenable Data Synthesis
Cold-start supervision is achieved by constructing a large corpus of multi-entity visual and textual queries explicitly designed to require parallel tool invocation. High-fidelity trajectories are sampled via Progressive Rejection Sampling, ensuring that only the shortest successful trajectories—exhibiting single-turn parallel precision—are retained. Rigorous quality filtering is applied so data volume is traded for operational density, with strong empirical evidence that filtered trajectories outperform raw high-volume datasets.
Dual-Grained Efficiency-Aware Reinforcement Learning
HyperEyes couples macro trajectory-level and micro token-level optimization using:
- TRACE (Tool-use Reference-Adaptive Cost Efficiency): An adaptive reward mechanism, dynamically tightening per-query round and invocation references during training. TRACE penalizes redundant tool use while accommodating legitimate multi-hop reasoning, anchoring optimization at a moving boundary determined by achievable policy efficiency.
- OPD (On-Policy Distillation): Dense corrective signals from a stronger, efficiency-aligned teacher model are injected at the token level, but only for failed rollouts. This mitigates the credit assignment deficiency of sparse RL reward signals, ensuring intermediate reasoning steps are not indiscriminately penalized.
The combination of the two ensures both global operational efficiency and local reasoning robustness.
Unified Grounded Search Action Space
In contrast to brittle “crop-then-search” pipelines, Unified Grounded Search (UGS) reformulates entity localization as a parameter of the retrieval action itself. Instead of sequential cropping and subsequent search, bounding boxes for all target entities are predicted concurrently and dispatched in a single tool-call round, extending parallelism from text-based modalities into the visual domain. Comparative experiments against LLM crop and code-crop baselines confirm that UGS achieves both higher accuracy and lower tool-call rounds across all tested benchmarks.
Benchmarking: IMEB and Evaluation Setup
To remedy the limitations of current multimodal search benchmarks (which focus exclusively on final answer accuracy), the paper introduces the Image Multi-Entity Benchmark (IMEB). IMEB is a rigorously curated testbed containing 300 multi-entity visual instances requiring concurrent localization and retrieval. A cost-aware metric, CAS (Cost-Aware Score), is proposed to jointly penalize inference token consumption and sequential tool-call rounds, establishing efficiency as a first-class evaluation axis.
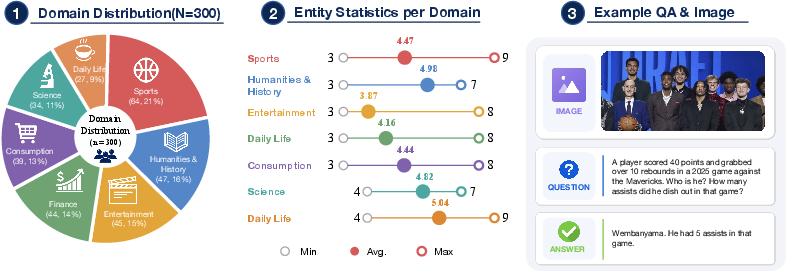
Figure 3: The IMEB benchmark spans diverse domains, entity counts, and question formulations for joint evaluation of multimodal search capability and efficiency.
Empirical Results
Experimental comparisons span six multimodal search benchmarks. HyperEyes is instantiated on both Qwen3-VL-30B and Qwen3-VL-235B backbones and is evaluated against leading commercial models (Gemini-3.1-Pro, Claude-Opus-4.6, Kimi-K2.5) and open-source multimodal search agents (DeepEyes-V2, MMSearch-R1, WebWatcher, VDR, REDSearch).
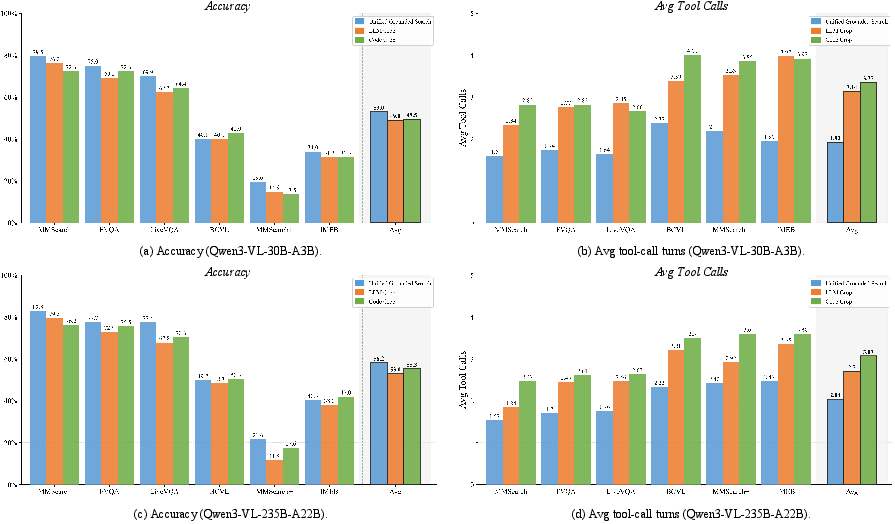
Figure 4: Unified Grounded Search achieves superior accuracy and minimizes tool-call rounds compared to serial and code-crop baselines across six benchmarks.
Key quantitative highlights:
- HyperEyes-30B (RL) achieves +9.9% accuracy with 5.3× fewer tool-call rounds than the best scalable open-source agent (VDR-8B).
- HyperEyes-235B (RL) closes the performance gap with Gemini-3.1-Pro to 1.1 accuracy points, primarily due to richer parametric knowledge in Gemini rather than superior search policy.
- Under CAS, HyperEyes achieves up to 7.6× CAS gains over competitors on IMEB, demonstrating higher information density per unit compute.
Ablation studies confirm that data quality dominates volume and the adaptive TRACE reward is essential for suppressing redundant tool usage while increasing answer accuracy. On-Policy Distillation is only effective with an aligned efficiency-oriented teacher; distilling from a vanilla model yields severe accuracy drops.
Case Study: Serial vs Parallel Multi-Entity Search
A head-to-head comparison between DeepEyes-V2 and HyperEyes on complex multi-entity queries reveals the practical value of parallel grounded search:

Figure 5: DeepEyes-V2 serially processes each person via crop-then-search, accumulating noisy context and errors; HyperEyes performs concurrent localization and retrieval, resolving the task in a fraction of the rounds with higher accuracy.
Robustness and Generalization
HyperEyes demonstrates increased robustness to distractor evidence and noise injection in retrieval contexts, maintaining high answer fidelity as in-domain, answer-misleading evidence is added. The parallel-amenable SFT corpus imbues the policy with sharper sensitivity to relevant evidence and generalizes beyond the training distribution.
Implications and Future Prospects
Practically, HyperEyes reduces energy consumption and latency for multimodal assistants through minimized tool-invocation turns, making real-time grounded QA viable on resource-constrained devices and democratizing research access. Theoretically, it demonstrates that reinforcement learning can simultaneously optimize accuracy and efficiency in agentic settings, challenging the prevailing assumption of their incompatibility.
The paradigm naturally extends to broader applications—education, scientific literature exploration, accessibility for visually impaired users—where parallel search and grounded answers are vital. Future development should focus on expanding beyond static visual and textual modalities to include spatial-temporal domains (video, audio), scaling reinforcement learning infrastructure for frontier models, and diversifying multimodal corpora for training.
Conclusion
HyperEyes establishes a robust, efficiency-aware recipe for parallel multimodal search agents, Pareto dominating existing open-source solutions in both accuracy and operational efficiency. The dual-grained RL framework and unified grounded search action space form a generalizable blueprint for high-throughput, reliable multimodal assistants, with IMEB providing a reproducible evaluation platform for both capability and efficiency. The empirical findings refute any dichotomy between search accuracy and efficiency, underscoring their complementarity in agentic multimodal reasoning (2605.07177).

