- The paper introduces WebExplorer, a framework that synthesizes challenging QA pairs through model-based exploration and iterative query evolution.
- It employs a two-phase training paradigm combining supervised fine-tuning with reinforcement learning to enhance long-horizon reasoning.
- Experiments demonstrate that the 8B-parameter WebExplorer model outperforms larger models on multiple benchmarks, highlighting the value of autonomous data synthesis.
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
Introduction
The paper introduces WebExplorer, a framework for synthesizing challenging query-answer (QA) pairs to train long-horizon web agents. The central hypothesis is that the bottleneck in developing capable web agents is the lack of sufficiently difficult and diverse training data. Existing open-source agents underperform on complex information-seeking tasks, and commercial models lack transparency. WebExplorer addresses this by combining model-based exploration with iterative, long-to-short query evolution, producing QA pairs that require multi-step reasoning and complex web navigation. The resulting WebExplorer-8B model, trained via supervised fine-tuning and reinforcement learning (RL), achieves state-of-the-art results at its scale across multiple benchmarks, outperforming much larger models.
Model-Based Exploration and Iterative Query Evolution
WebExplorer departs from prior graph-based and evolution-based data synthesis methods by leveraging LLMs to autonomously explore the information space and generate QA pairs. The process begins with a seed entity (e.g., from Wikipedia), and the model performs iterative search and browse actions to discover interconnected facts. This simulates implicit graph construction without explicit node/edge management, allowing for flexible and dynamic information gathering.
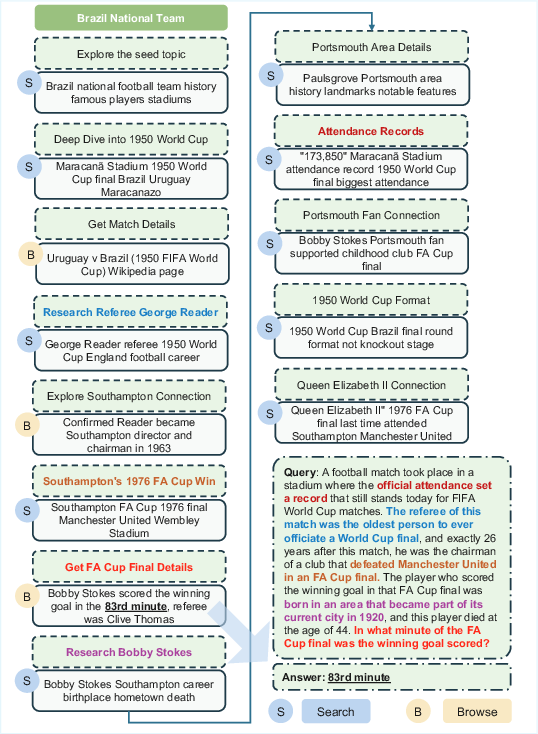
Figure 1: Model-based exploration and initial QA synthesis, where the agent discovers interconnected facts via search and browse actions, then synthesizes a challenging QA pair.
After the initial QA pair is generated, an iterative query evolution process is applied. Unlike previous methods that increase complexity by adding information, WebExplorer increases difficulty by systematically removing salient clues and introducing obfuscation. This long-to-short evolution transforms explicit, easily solvable queries into ones that require deeper reasoning and more exploratory search attempts.
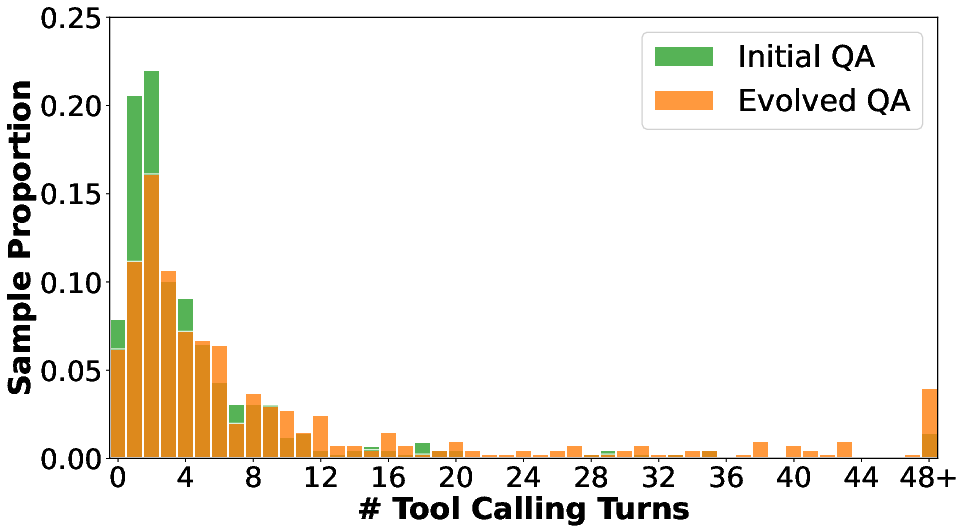
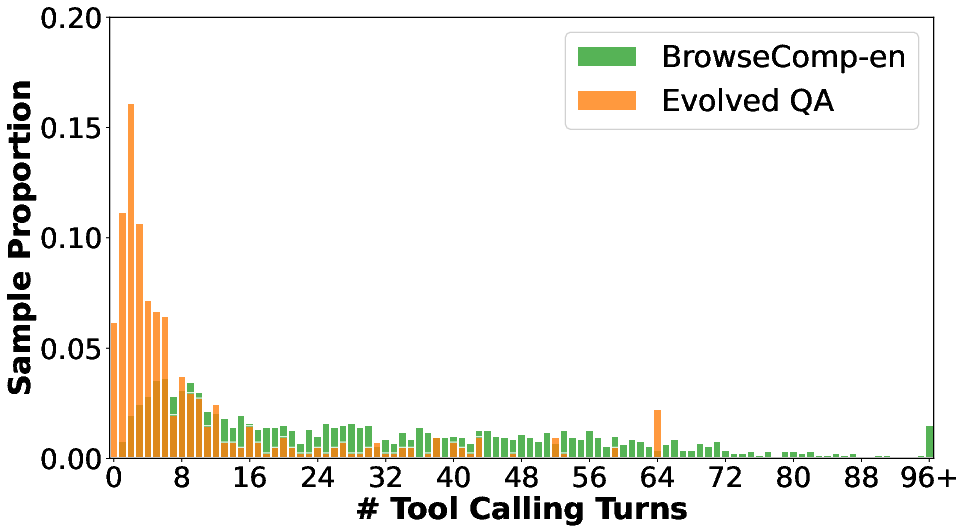
Figure 2: Comparison between initial QA and evolved QA, illustrating the increased obfuscation and reasoning complexity in the evolved version.
Empirical analysis demonstrates that this evolution process significantly increases the average number of tool calls required to solve a query and reduces the accuracy of strong proprietary models, indicating higher task complexity.
Dataset Construction and Analysis
The WebExplorer-QA dataset is constructed by applying the above methodology to a diverse set of seed entities, with five rounds of query evolution per seed. The final dataset contains approximately 40K evolved QA pairs, which are used for both supervised fine-tuning and RL.
Comparative evaluation against datasets from WebDancer, SailorFog, WebShaper, and ASearcher shows that WebExplorer-QA's evolved queries require the highest average number of tool calls and are more challenging for strong LLMs to solve. The distribution of tool calling turns further confirms that the evolution process shifts the dataset toward more complex, long-horizon tasks, while maintaining reasonable solvability.
Training Paradigm: Supervised Fine-Tuning and Reinforcement Learning
WebExplorer-8B is trained in two phases:
- Supervised Fine-Tuning (SFT): The model is initialized using high-quality trajectories collected from a commercial LLM, filtered via rejection sampling to ensure correctness. The ReAct framework is used, with explicit > , <tool_call>, and <tool_response> tags to structure the agent's reasoning and actions.
>
> 2. Reinforcement Learning (RL): The model is further optimized using the GRPO algorithm, with a composite reward function balancing response format correctness and answer accuracy (the latter judged by DeepSeek-V3). RL training progressively increases the context length (up to 128K tokens) and the maximum number of tool calling turns (up to 100), enabling the model to handle long-horizon tasks.
>
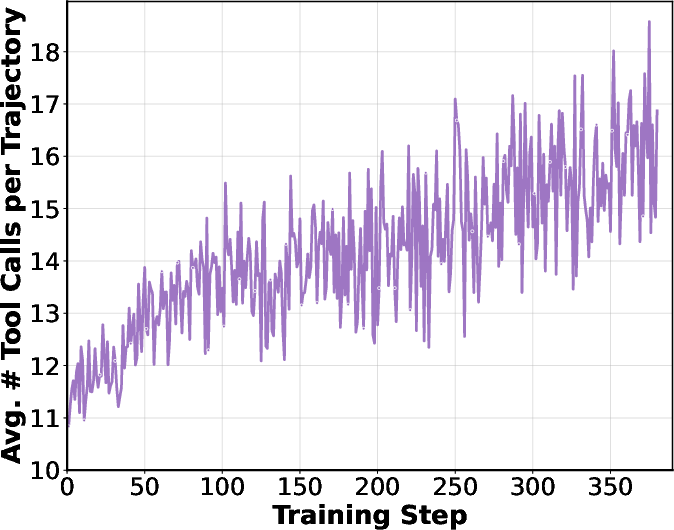
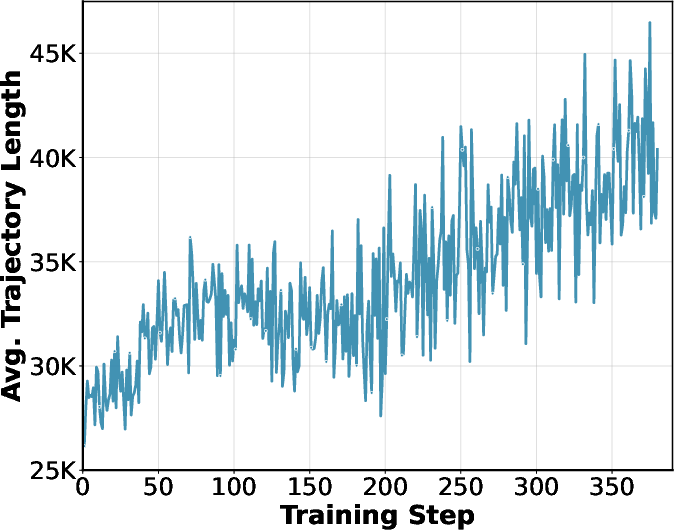
> During RL, the model learns to execute more sophisticated multi-step reasoning strategies, as evidenced by a steady increase in average tool calls per trajectory and trajectory length.
>
 >
>
>
>  >
>
>
> 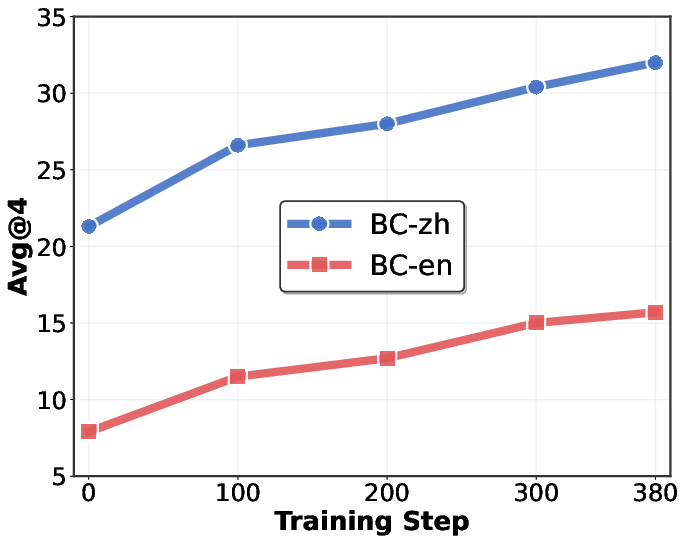 >
> Figure 3: RL training dynamics: left—average tool calls per trajectory; middle—average trajectory length; right—BrowseComp-en/zh scores during RL.
>
> ## Experimental Results
>
> WebExplorer-8B achieves state-of-the-art performance among open-source models up to 100B parameters on a suite of information-seeking benchmarks, including BrowseComp-en, BrowseComp-zh, GAIA, WebWalkerQA, FRAMES, and XBench-DeepSearch. Notably, as an 8B-parameter model, it outperforms WebSailor-72B and other much larger models on several benchmarks.
> 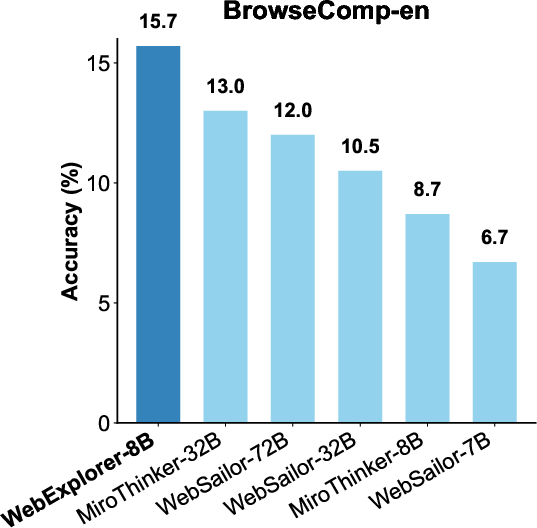 >
>
>
> 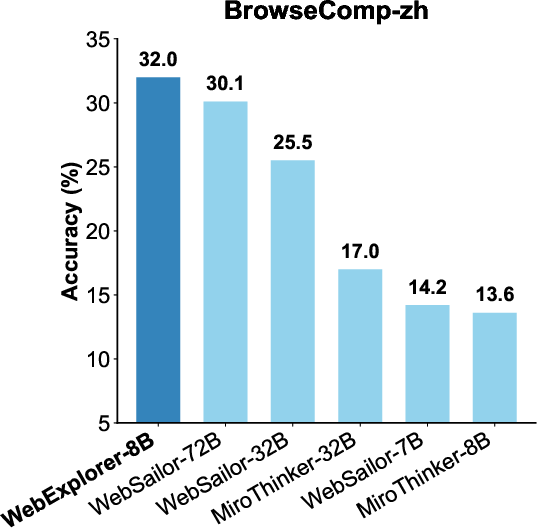 >
>
>
> 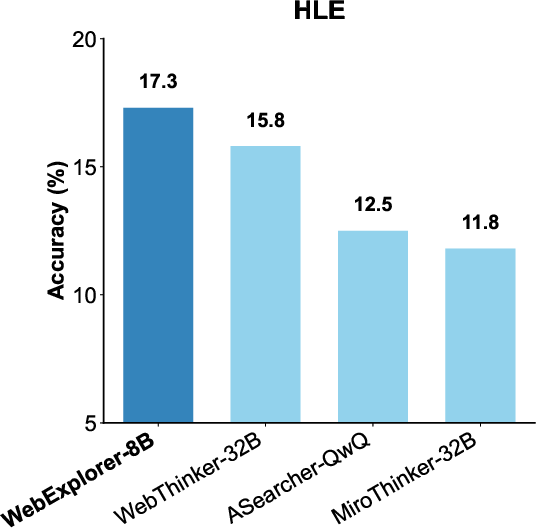 >
> Figure 4: Performance comparison on BrowseComp-en, BrowseComp-zh, and HLE benchmarks across different models.
>
> Key results include:
>
> - BrowseComp-en: 15.7% (vs. 12.0% for WebSailor-72B)
>
> - BrowseComp-zh: 32.0% (vs. 30.1% for WebSailor-72B)
>
> - WebWalkerQA: 62.7% (best among models <100B)
>
> - FRAMES: 75.7% (best among models <100B)
>
> - HLE: 17.3% (outperforming WebThinker-32B by 1.5 points)
>
> The model demonstrates strong generalization, achieving competitive results on the HLE academic benchmark despite being trained only on knowledge-intensive QA data.
>
> ## Implications and Future Directions
>
> WebExplorer demonstrates that high-quality, challenging QA data can be synthesized autonomously via model-based exploration and iterative query evolution, obviating the need for costly manual curation or complex rule-based graph construction. The approach enables the training of parameter-efficient web agents capable of long-horizon reasoning and complex information-seeking tasks.
>
> The results suggest several future research directions:
>
> - Scaling to Larger Models: Applying the WebExplorer data synthesis and training pipeline to larger base models may further close the gap with proprietary systems.
>
> - Automated Difficulty Calibration: Integrating automated difficulty estimation and adaptive evolution could yield even more effective training curricula.
>
> - Generalization Beyond Web Navigation: The demonstrated transfer to academic QA tasks indicates potential for broader applications in multi-hop reasoning and tool-augmented LLMs.
>
> - Open-Source Agentic Frameworks: The transparent, reproducible methodology provides a foundation for further research on agentic LLMs and tool-augmented reasoning.
>
> ## Conclusion
>
> WebExplorer provides a systematic approach for synthesizing challenging, high-quality QA data and training long-horizon web agents. By combining model-based exploration with iterative query evolution, the framework produces data that drives significant improvements in agentic reasoning and information-seeking performance. The resulting WebExplorer-8B model establishes new state-of-the-art results at its scale, outperforming much larger models and demonstrating strong generalization. This work highlights the importance of data-centric approaches and RL-based training for advancing the capabilities of web agents and tool-augmented LLMs.