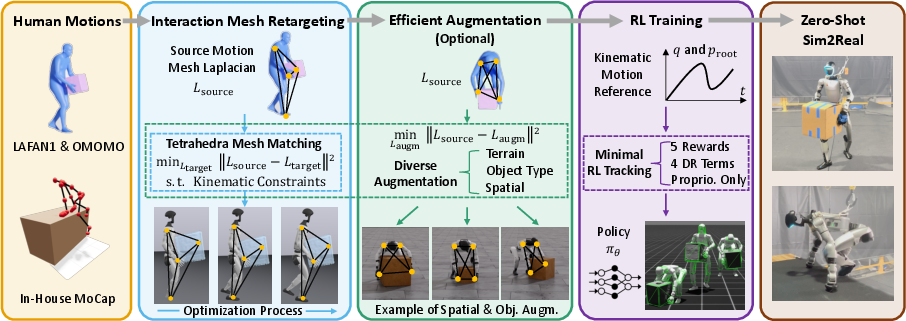
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Abstract: A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OmniRetarget, a tool that helps humanoid robots learn complex, full-body skills that involve touching and using objects and moving across tricky terrain. The key idea is to take motion captured from humans and carefully “retarget” it to a robot so the robot does the same kind of interactions—like keeping its hands on a box or its feet planted on a step—without weird glitches like sliding feet or arms going through objects. With these clean, realistic reference motions, the team trains robot control using reinforcement learning (RL) and shows it can transfer straight from simulation to a real robot without extra tweaking.
Key Questions the Paper Answers
- How can we turn human motion data into robot-friendly training examples that still keep the important contacts and interactions with objects and the environment?
- How do we avoid common mistakes (like foot sliding or body parts clipping through things) when retargeting human motions to robots with very different body shapes?
- Can we create lots of useful training data from just one human demonstration by changing the scene (like object position or terrain height)?
- With better motion data, can we train RL robot controllers using simple rewards and minimal information, and still make them work on a real robot right away?
How It Works (Methods, Explained Simply)
Think of retargeting as translating a dance move from one person to another who has a different body. For robots, this is extra hard: their limbs may be longer/shorter, joints bend differently, and their balance works differently. OmniRetarget solves this with three main ideas:
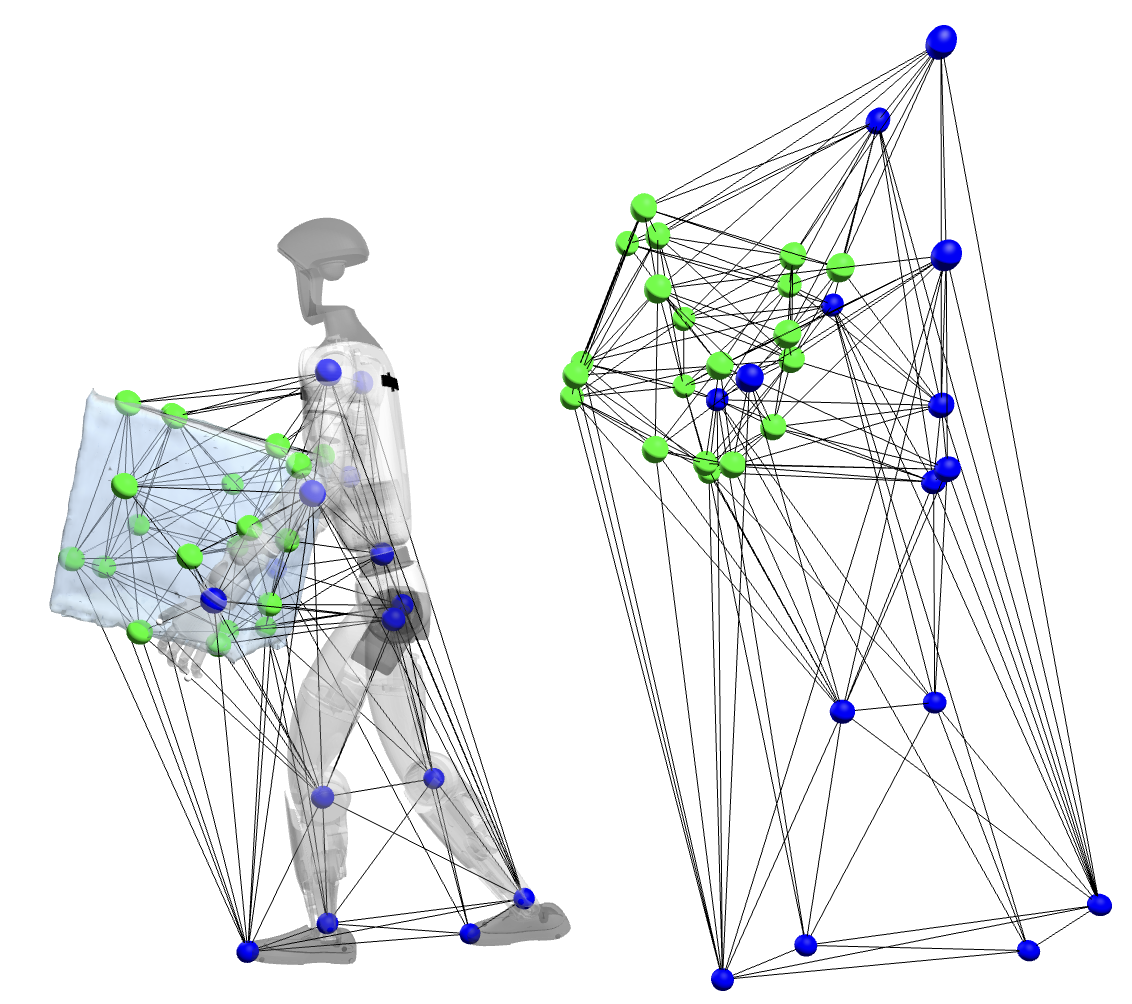
- Interaction mesh:
- Imagine a stretchy 3D spiderweb covering the human, the object they interact with (like a box), and the ground/terrain. The web connects important points: joints on the body, points on the object, and points on the environment.
- Retargeting is like gently warping this web from the human’s shape to the robot’s shape while keeping the “neighbors” in the web close to each other. This preserves contacts and distances, so hands stay on the box and feet stay on the step.
- Deformation energy (keeping the web’s shape consistent):
- Each point in the web should stay close to the average of its neighbors, like friends staying together in a group photo even if the photo gets stretched a bit.
- The system tries to minimize changes to these neighbor relationships. This helps the robot move in a way that matches how the human interacted with the scene.
- Hard physical constraints (rules the robot must obey):
- No collisions or “ghosting” through objects or terrain.
- Joint limits and speed limits (so the robot doesn’t move in impossible ways).
- Foot sticking: when a foot is supposed to be planted, it doesn’t slide.
- The software solves the motion frame-by-frame with an optimization algorithm (you can think of it as making small, careful adjustments at each moment), and it uses tools that handle robot rotations and geometry correctly.
Data augmentation (making more training from one demo):
- From a single human demonstration, they create many variations:
- Move or rotate the object, change its size/shape.
- Change terrain height (like a taller platform).
- Retarget to different robot bodies.
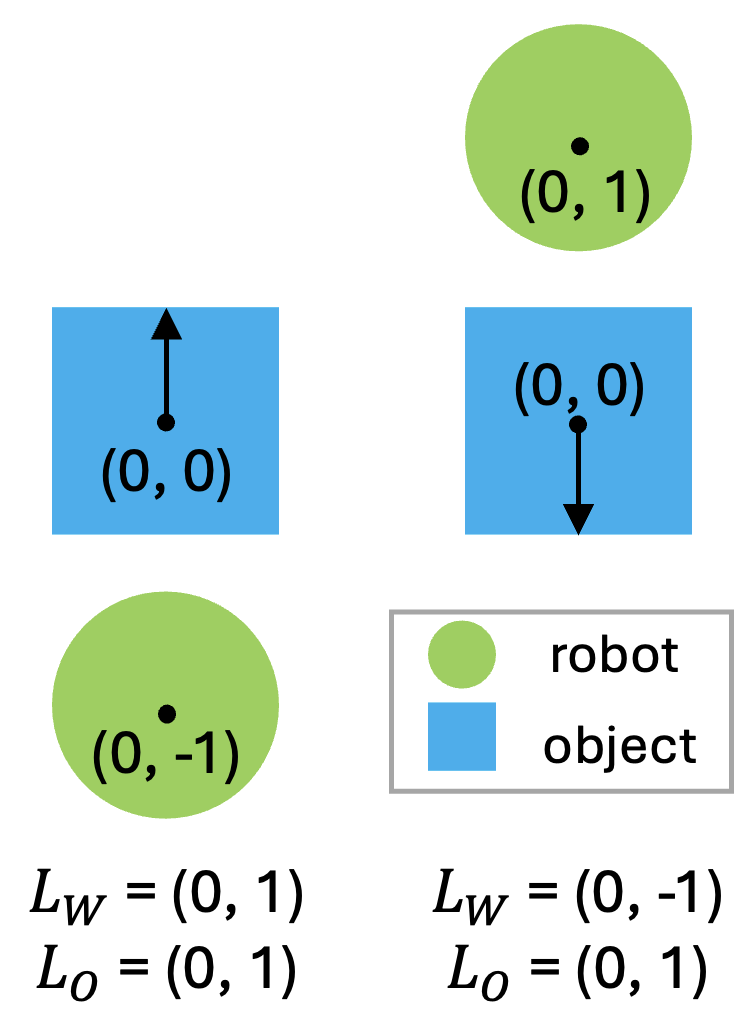
- The interaction mesh stays anchored in the object’s local frame, so when the object changes, the robot’s hands follow realistically.
- They add extra costs to avoid trivial solutions (like just moving the whole robot together with the object) and instead force the robot to discover new useful upper-body motions while keeping feet or other parts stable.
Training the robot with minimal RL:
- Observations: The policy mostly “feels” its own body (proprioception) and compares itself to the reference motion. It doesn’t get extra info about the scene or objects.
- Rewards: Only five simple terms (track the body pose and speed, track the object if needed, avoid rapid action changes, respect joint limits softly, and penalize self-collisions). No complicated reward hacks.
- Domain randomization: Just a few simple randomizations (like slight changes in robot center of mass or small pushes) to make the policy more robust.
- Result: The policy learns to follow the clean reference motions and works on the real robot without extra fine-tuning.
Main Findings and Why They Matter
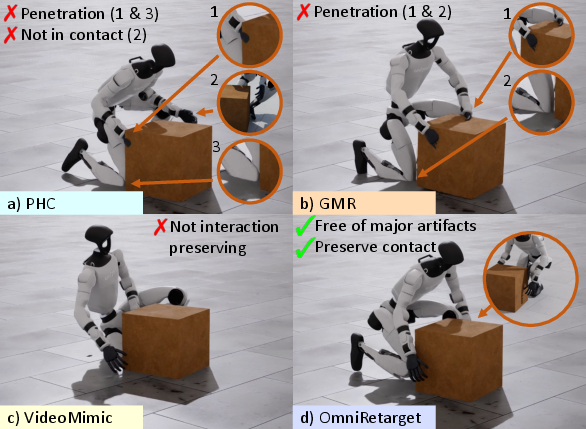
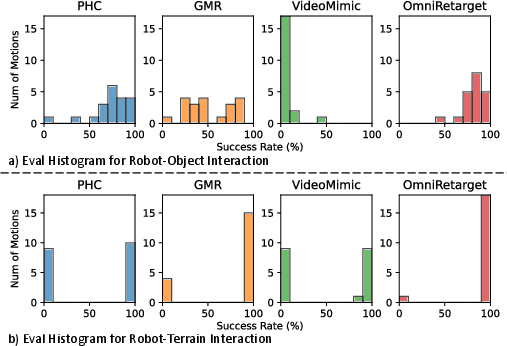
- Cleaner retargeting than popular baselines:
- Compared to other tools (PHC, GMR, VideoMimic), OmniRetarget creates motions with far fewer artifacts:
- Almost no “penetration” (robot body or object clipping through surfaces).
- Feet don’t skate when they should be planted.
- Contacts (like hands on the box or feet on steps) are preserved more consistently.
- This quality directly leads to better RL training outcomes and higher success rates.
- Big, diverse dataset from few demos:
- By changing object pose/shape and terrain settings, OmniRetarget turns a single human demo into many valid robot training trajectories. This saves time and effort and covers more situations.
- Minimal RL setup still succeeds:
- With just five simple rewards and basic observations, the robot learns complex skills. No fragile “reward hacking” needed.
- Policies trained in simulation transfer “zero-shot” to a real Unitree G1 humanoid. That means no extra training or tuning on the real robot.
- Impressive real-world behaviors:
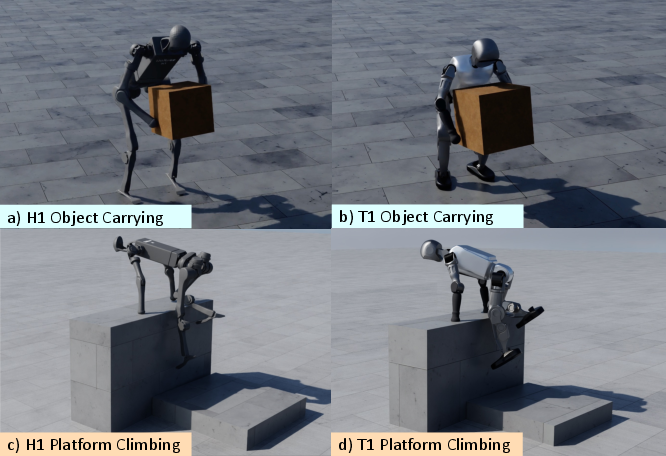
- The robot performs a 30-second “parkour” sequence: carrying a chair, using it to climb onto a platform, vaulting, jumping, and rolling to absorb impact.
- It also handles box transportation, crawling on slopes, and fast platform climbing and sitting—skills that require accurate, coordinated whole-body interactions.
- Augmentation improves coverage:
- Training on the augmented data leads to strong performance not only on the original scenes but also on new variations (like different box positions and platform heights), with high success rates in simulation and on hardware.
What This Means Going Forward
- Better data beats complicated tricks: OmniRetarget shows that if you fix the root problem—poor-quality reference motions—you can train powerful robot controllers with simple, stable RL setups. You don’t need to guess dozens of reward tweaks to patch over bad data.
- Faster progress for humanoid robots: Because the system is open-source and produces lots of clean, interaction-aware robot motions quickly, other researchers can build on it. This could speed up progress in teaching humanoids to handle more agile, human-like tasks in the real world.
- Future directions: The authors suggest improving the optimization by considering the whole motion at once (not just frame-by-frame) to handle noisier sources like video even better, and eventually moving toward end-to-end visuomotor policies that can see and act directly.
In short, OmniRetarget is a powerful way to turn human demonstrations into robot-ready training data that keeps all the important scene interactions, leading to more natural, capable humanoid behaviors in both simulation and the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete follow-up research:
- Dynamic feasibility not enforced during retargeting: no constraints on contact wrench cones, centroidal dynamics, momentum, ZMP, or torque/actuator limits; references may be kinematically valid but dynamically infeasible.
- Frame-by-frame optimization limits temporal coherence: absence of whole-trajectory optimization (e.g., collocation) prevents enforcing acceleration/jerk limits and global consistency across contacts and timing.
- Linearized collision constraints yield residual penetrations: no guarantees of non-penetration; need more robust nonconvex collision handling or convexification with certified bounds.
- Contact schedule is not discovered or optimized: stance/hand contacts are inferred via velocity thresholds and preserved, but changing, inserting, or retiming contacts to remain feasible under large augmentations is not addressed.
- Sensitivity to interaction-mesh design: selection/density of body/scene keypoints, uniform Laplacian weights, and Delaunay tetrahedralization choices are not ablated; no method to learn or adapt importance weights per contact/region.
- Manual correspondence mapping across embodiments: semantically consistent human–robot keypoint correspondences are needed; no automatic discovery/alignment of correspondences or part-to-part mappings across very different morphologies.
- Initialization and convergence behavior unreported: lack of analysis on solver initialization for the first frame, failure modes, convergence rates, and strategies to escape poor local minima.
- Runtime and scalability not quantified: per-sequence retargeting time, scaling to very long trajectories, and compute requirements for generating “8+ hours” of data are not reported; unclear feasibility for large-scale continual data generation.
- Limited augmentation scope: supports object pose/size and terrain scaling, but not articulated objects, deformable objects, nonrigid/compliant terrains, or dynamic/moving environments.
- No augmentation-aware contact recalibration: when objects/terrains change significantly, the approach does not synthesize new grasps, footholds, or hand placements beyond preserving the original mesh relations.
- Physical property variation underexplored in retargeting: augmentation does not consider friction coefficients, surface compliance, or contact damping; mass/inertia variation is deferred to RL via randomization, not enforced in kinematics.
- Handling heavy payloads not systematically studied: object mass randomization (0.1–2 kg) does not match heavier real demos (e.g., 4.6 kg chair); robustness across payload ranges is not quantified.
- Proprioceptive-only policies limit generalization: policies track references without perception of scene/object state; they cannot adapt to unseen layouts, occlusions, or perturbations beyond the provided reference trajectories.
- Reference dependence creates brittleness: termination conditions based on deviation from reference indicate lack of robustness to distribution shift (e.g., unexpected object displacement), raising the need for goal-conditioned or perception-conditioned policies.
- Cross-embodiment policy transfer is not demonstrated: while motions are retargeted to multiple robot models in simulation, trained policies are only shown on Unitree G1; zero-shot cross-robot policy transfer remains open.
- No vision-based or visuomotor learning: the method does not integrate exteroception; how to leverage retargeted data to train perception-conditioned loco-manipulation remains unanswered.
- Limited evaluation metrics: kinematic benchmarks omit measures of dynamic stability margins, frictional feasibility, energy usage, effort/comfort, and perceived naturalness/human-likeness.
- No user studies or preference evaluations: the naturalness and task appropriateness of motions are not evaluated via human preference or expert assessment.
- Limited task diversity analysis: success is reported for selected tasks; coverage across broader manipulation taxonomies (tool use, fine dexterity, bimanual regrasping, nonprehensile actions) is unclear.
- Safety and failure characterization on hardware are not reported: absence of systematic analysis of failure modes, near-misses, or safety mitigations during aggressive behaviors (e.g., jumps/rolls).
- Robustness to noisy demonstrations not validated: performance with low-fidelity sources (e.g., monocular video reconstructions with pose errors) is identified as future work but remains untested.
- No ablations on augmentation ranges: lack of systematic study on how far object/terrain variations can be pushed before failure and how to detect unsafe augmentation automatically.
- Contact modeling fidelity: contact points are limited (hands/toes/heels); rich contact behaviors (forearms, knees, torso bracing) and multi-point friction modeling are not explicitly supported or evaluated.
- Solver formulation clarity: described as “Sequential SOCP” and “SQP-style” with linearizations; precise cone structure, constraint classes, and implementation details for reproducibility are insufficiently specified.
- Lack of theoretical guarantees: no bounds on deformation error vs. contact preservation trade-offs, nor conditions guaranteeing feasibility under augmentation.
- Policy learning scale and efficiency: sample efficiency, training time, and scaling behavior with increasing numbers of references/tasks are not quantified; multi-task policy generalization is only partially explored.
- Limited disturbance robustness: beyond small random pushes, robustness to significant perturbations (slips, unexpected collisions, object compliance) is not evaluated.
- Skill composition and reusability: sequencing or blending skills beyond a curated 30 s demo lacks a formal framework; how to modularize retargeted skills for planning remains open.
- No tactile/force objectives: grasp force regulation, slip avoidance, and compliant manipulation are not considered in retargeting or RL rewards; object interaction is evaluated mainly via pose tracking.
- Meshing robustness for complex scenes: Delaunay tetrahedralization on cluttered or highly nonconvex environments may be brittle; no strategies for mesh repair or adaptive sampling are discussed.
- Dataset bias and coverage: reliance on OMOMO, LAFAN1, and in-house MoCap may limit scene/object diversity; coverage across daily living tasks and real-world clutter is not analyzed.
- Licensing and reproducibility risks: while open-sourcing is promised, constraints on third-party data (e.g., OMOMO) and hardware-specific details may limit out-of-the-box replication.
These gaps suggest concrete next steps: integrate trajectory-level dynamic constraints, automate correspondence/mesh design, expand augmentation to articulated/deformable settings with contact schedule optimization, incorporate perception to reduce reference dependence, evaluate robustness and safety at scale, and systematize solver/runtime reporting and theoretical guarantees.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, leveraging the paper’s released/announced methods and evidence of zero-shot transfer to hardware.
- Robotics R&D: High-fidelity reference generation for loco-manipulation
- Sector: Robotics (humanoids, legged manipulators)
- What: Use OmniRetarget to turn a few human demonstrations into clean, interaction-preserving kinematic references (no foot-skating, minimal penetration), then train proprioceptive RL trackers with only 5 reward terms.
- Tools/Workflows:
- Retarget human demo → enforce hard constraints via interaction mesh optimization → auto-augment (object pose/shape, terrain) → RL training → sim-to-real deployment.
- Integrate with Drake/MuJoCo pipelines; use the quantitative QA metrics (penetration, foot-skating, contact preservation) as gates.
- Assumptions/Dependencies:
- Access to robot URDF and accurate collision meshes; reliable torque/PD control; sufficient compute for retargeting+RL.
- Open-source release availability as stated; existing MoCap or curated demos.
- Data augmentation at scale for interaction tasks (from a single demo)
- Sector: Robotics; Software (simulation tooling)
- What: Systematically generate diverse scenes (object positions/orientations, shapes; terrain height/depth) while preserving human-object-terrain contacts to grow coverage without collecting more demos.
- Tools/Workflows: “Scenario Augmentor” job that sweeps object/terrain parameters; interaction-mesh in object frame to retain grasping/placing consistency; anchoring costs (e.g., lower body) to prevent trivial rigid transforms.
- Assumptions/Dependencies:
- Accurate object and environment geometry; realistic physical ranges for augmentation; sufficient solver convergence.
- Cross-embodiment motion porting (e.g., G1 → H1 → Booster T1)
- Sector: Robotics OEMs; system integrators
- What: Map keypoints between embodiments to reuse skill libraries across platforms with minimal re-engineering.
- Tools/Workflows: “Keypoint Correspondence Mapper” + retarget + brief re-training of RL trackers if dynamics differ; regression tests with the QA suite.
- Assumptions/Dependencies:
- Semantically consistent keypoint mapping; similar actuation capabilities and joint limits.
- Minimal-reward RL training pipelines for whole-body loco-manipulation
- Sector: Robotics startups, labs
- What: Replace heavy reward engineering with a small, reusable reward set by training trackers on artifact-free references; rapidly prototype new tasks (lifting, carrying, climbing, crawling).
- Tools/Workflows: Adopt BeyondMimic-style minimal rewards; shared domain randomization terms (4 robot terms); batch multi-task training for related motions (e.g., box-moving family).
- Assumptions/Dependencies:
- Proprioceptive state estimation quality matches assumptions; domain randomization covers hardware idiosyncrasies.
- Kinematic QA and benchmarking for retargeting pipelines
- Sector: Robotics; Policy/testing labs; Academia
- What: Use the paper’s metrics (penetration depth/duration, foot-skating duration/velocity, contact preservation) to compare pipelines and gate data quality before RL training.
- Tools/Workflows: “Kinematic QA Suite” integrated into CI for datasets; auto-fix via re-solve or local post-processing; report cards for datasets.
- Assumptions/Dependencies:
- Consistent collision models across simulators; standardized thresholds for pass/fail.
- Character animation and VR prototyping with interaction preservation
- Sector: Software/media (games, VFX), XR/telepresence
- What: Adapt human-object/scene interactions to avatars while enforcing non-penetration and contact sticking (e.g., hands on props, feet on uneven terrain).
- Tools/Workflows: Interaction-mesh–based retargeting as an export step from MoCap to different rigs/scenes; use constrained optimization for reliable contact-aware animation.
- Assumptions/Dependencies:
- Scene/object meshes with correct scales; contact definitions; runtime budgets for offline optimization.
- Education and reproducible benchmarks for loco-manipulation
- Sector: Academia; Education
- What: Course labs and benchmarks on interaction-preserving retargeting and minimal-reward RL, with open datasets and policies.
- Tools/Workflows: Ready-to-run notebooks; ablation studies on augmentation and constraints; standardized task suites (platform heights, box shapes).
- Assumptions/Dependencies:
- Public availability of code/data/policies; stable machine configurations for reproducibility.
Long-Term Applications
Below are forward-looking applications that need further research, integration with perception, scaling, or productization.
- Warehouse and logistics humanoids performing dynamic loco-manipulation
- Sector: Logistics, warehousing, manufacturing
- What: Generalizable skills for pick/carry/place while traversing irregular environments (ramps, steps), robust to varied box shapes/poses, with minimal per-task engineering.
- Tools/Products: “Humanoid Skill Library” preloaded with retargeted+augmented motion families; fleet training-in-simulation with scenario sweeps.
- Assumptions/Dependencies:
- Strong perception (object/terrain reconstruction and tracking), robust safety layers, handling heavier payloads beyond current demonstrations, regulatory compliance.
- Household assistive humanoids (daily-living tasks)
- Sector: Healthcare, consumer robotics
- What: Assistance such as lifting/moving objects, climbing small steps, stable manipulation while walking; learn from a few human demos augmented into many home scenes.
- Tools/Products: “Home Task Packs” (laundry baskets, chairs, drawers) generated via interaction-preserving augmentation; shared autonomy overlays.
- Assumptions/Dependencies:
- Reliable vision and state estimation in clutter; safe contact behavior with humans/fragile objects; long-horizon planning; cost/weight/power constraints.
- Disaster response and field operations (tool-use and terrain negotiation)
- Sector: Public safety, defense, utilities
- What: Complex multi-contact behaviors (e.g., using debris as stepstones) in unstructured terrains; extend from chair-as-stepstone to general tool-use for access and stability.
- Tools/Products: “Tool-Use Augmentor” that parameterizes ad-hoc supports; digital twin rehearsals of response sites.
- Assumptions/Dependencies:
- Perception in harsh conditions; robust hardware; formal safety verification of multi-contact strategies; teleop fallback.
- Foundation models for humanoid control trained on interaction-preserving corpora
- Sector: AI/Robotics
- What: Pretraining large policies on thousands of retargeted+augmented interaction trajectories across embodiments, objects, and terrains; fine-tune for new tasks and robots.
- Tools/Products: Curated “InteractionMesh-1T” dataset; cross-embodiment policy distillation; policy hubs similar to vision/LLM hubs.
- Assumptions/Dependencies:
- Massive, diverse data; compute; scalable training infrastructure; unification of observation/action spaces across robots.
- Video-to-robot learning of loco-manipulation from in-the-wild footage
- Sector: AI/Robotics research
- What: Lift human-object/terrain interactions from video, then adapt via interaction-mesh optimization and minimal RL; reduces dependence on studio MoCap.
- Tools/Products: End-to-end pipeline: video pose/scene reconstruction → interaction mesh creation → trajectory-level constrained optimization → RL tracking.
- Assumptions/Dependencies:
- Reliable 3D reconstruction and contact inference; trajectory-level (not frame-wise) optimization for noisy sources; perception-policy integration.
- Facility digital twins with automatic scenario generation for robot design and operations
- Sector: Industrial software, manufacturing engineering
- What: Use augmentation to sweep layouts, elevations, object catalogs; evaluate policies at scale for throughput, safety, and failure modes before deployment.
- Tools/Products: “Scenario Generator” for digital twins; CI for policy validation using kinematic QA + RL success metrics.
- Assumptions/Dependencies:
- High-fidelity twins; standardized interfaces with simulation; coverage metrics and validation protocols.
- Regulatory test suites and standards for humanoid contact safety and stability
- Sector: Policy, standards bodies
- What: Define measurable criteria (penetration depths, foot-slip thresholds, contact durations) and canonical scene tasks (platform climbs, object carries) for certification.
- Tools/Products: Public test datasets; automated audit tools using the paper’s metrics; reference policies as baselines.
- Assumptions/Dependencies:
- Multi-stakeholder consensus; reproducible measurement procedures; mapping sim metrics to certified lab tests.
- Shared-autonomy teleoperation with retargeted priors
- Sector: Industrial robotics, telepresence
- What: Retargeted motion libraries act as priors for predictive assistance, stabilizing contacts and foot placements while an operator provides high-level guidance.
- Tools/Products: “Autopilot Assist” overlays that snap to feasible interaction meshes; intent inference blended with constrained controllers.
- Assumptions/Dependencies:
- Intuitive HRI interfaces; real-time feasibility projections; robust arbitration between human and autonomy.
- Vendor SDKs for cross-embodiment skill porting and safety pre-checks
- Sector: Robot OEMs
- What: First-party “OmniRetarget SDKs” to import demos, auto-augment, check constraints, and produce deployable skills across model variants.
- Tools/Products: GUI to author keypoint correspondences; batch augmentation; on-device validators.
- Assumptions/Dependencies:
- Vendor adoption; standardized robot descriptions; lifecycle support for updates and regressions.
Notes on key assumptions and dependencies across applications
- Motion source quality: The method thrives with clean demonstrations (MoCap-level). For video or noisy captures, trajectory-level optimization and robust contact inference are needed.
- Accurate models: Reliable URDFs, collision meshes, and environment/object geometry are critical to enforce hard constraints during retargeting.
- Hardware capability: Skills must fit the robot’s actuation limits, joint ranges, and stability margins; heavier payloads and high-impact maneuvers may require hardware advances.
- Perception gap: Current policies are proprioceptive; most real deployments need vision/scene understanding and tight perception-control integration.
- Safety and compliance: Multi-contact behaviors (e.g., tool-use, jumping/rolling) require safety monitors, human-in-the-loop failsafes, and compliance with standards.
- Compute and tooling: Batch optimization and RL training benefit from GPUs/CPUs at scale; integration with simulators (e.g., Drake, MuJoCo) and auto-diff toolchains.
- Open-source availability: Broad adoption depends on release of code, datasets, and trained policies as promised in the paper.
Glossary
- Automatic differentiation: A computational technique that automatically computes derivatives of functions, enabling gradient-based optimization in complex systems. "leverages the automatic differentiation framework in Drake"
- Contact preservation: Maintaining intended physical contacts (e.g., hand–object, foot–terrain) during retargeting so interactions remain realistic. "achieve better kinematic constraint satisfaction and contact preservation than widely used baselines."
- Delaunay tetrahedralization: A meshing method that partitions 3D space into tetrahedra such that no point lies inside the circumsphere of any tetrahedron. "We construct the interaction mesh by applying Delaunay tetrahedralization"
- DeepMimic-style tracking: A reinforcement learning reward formulation that tracks reference motion states (positions, orientations, velocities) to imitate human motion. "Body Tracking: DeepMimic-style tracking term for body position, orientation, linear and angular velocity;"
- Differential geometry: The mathematical study of smooth shapes and spaces; here, applied to handling rotations on manifolds like the 3-sphere. "which correctly handles the differential geometry of rotations on the manifold"
- Domain randomization: Systematically varying parameters of the environment, robot, or objects during training to improve robustness and generalization. "Domain Randomization. To improve generalization across object properties"
- End-effector: The part of a robot that interacts with the environment (e.g., hands), often targeted in motion planning and control. "end-effector targets"
- Floating base: A robot configuration where the base link (e.g., pelvis) is not fixed, allowing free motion with 6-DoF pose. "consisting of the floating base pose (quaternion and translation)"
- Foot skating: An artifact where feet slide during supposed contact phases due to poor constraints or retargeting, reducing physical plausibility. "artifacts such as foot skating and penetration."
- Forward kinematics: The computation of joint-based configurations to obtain the position of robot keypoints in space. "via forward kinematics "
- Heightmap: A representation of terrain using a grid of elevation values, often used for collision or contact modeling. "originally designed for heightmaps,"
- Interaction mesh: A volumetric structure connecting body, object, and environment points to preserve spatial and contact relationships during motion retargeting. "based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects."
- Inverse kinematics: Solving for joint angles that achieve desired end-effector or keypoint positions. "solve inverse kinematics with neural networks"
- Laplacian coordinates: Local differential descriptors of points in a mesh relative to their neighbors, used to measure deformation. "The Laplacian coordinate of the -th keypoint is defined"
- Laplacian deformation energy: A metric quantifying how much a mesh’s local differential structure changes during retargeting. "minimize the Laplacian deformation energy of the interaction meshes"
- Multi-task policy: A single reinforcement learning controller trained to perform multiple related tasks. "All box-moving motions share a single multi-task policy,"
- Non-penetration: A hard constraint enforcing that robot and environment bodies do not interpenetrate during motion. "including foot sticking, non-penetration, and joint and velocity limits,"
- Nonconvex program: An optimization problem with nonconvex objectives or constraints, often requiring iterative solvers and careful initialization. "the following constrained, nonconvex program:"
- Proprioceptive: Pertaining to internal sensing of the robot’s own states (e.g., joint angles, velocities) rather than external perception. "a purely proprioceptive observation space"
- Quaternion: A four-parameter rotation representation used to avoid singularities and facilitate smooth orientation optimization. "quaternion-based floating base orientation"
- Rot6D: A 6D rotation representation used in learning systems to parameterize orientations robustly. "Observation noise: for orientation in Rot6D,"
- Second-Order Cone Programming (SOCP): A convex optimization framework involving second-order (quadratic) cone constraints; here used sequentially for retargeting. "Sequential SOCP"
- Sequential Quadratic Programming (SQP): An iterative optimization method that solves a sequence of quadratic approximations to handle nonlinear constrained problems. "Sequential Quadratic Programming (SQP)-style solver"
- Signed distance function: A scalar function giving the distance to a surface with sign indicating inside/outside, used for collision constraints. "denotes the signed distance function for the -th collision pair,"
- Sim-to-real transfer: Deploying policies trained in simulation directly to physical hardware while retaining performance. "zero-shot sim-to-real transfer to hardware."
- Stance phase: The gait phase where a foot maintains ground contact without sliding. "A foot is considered to be in the stance phase if its horizontal velocity in the source motion (in the xy-plane) falls below a threshold of 1 cm/s."
- Teleoperation: Controlling a robot directly by a human operator, often used to generate demonstrations. "The first one is teleoperation"
- Trajectory optimization: Computing control inputs or configurations over time to satisfy objectives and constraints for motion feasibility. "or trajectory optimization \cite{yang2025physics} in simulation."
- Warm-starting: Initializing an iterative solver with a previous solution to improve convergence speed and consistency. "warm-started with the optimal solution from the previous frame"
Collections
Sign up for free to add this paper to one or more collections.