From Generated Human Videos to Physically Plausible Robot Trajectories
Abstract: Video generation models are rapidly improving in their ability to synthesize human actions in novel contexts, holding the potential to serve as high-level planners for contextual robot control. To realize this potential, a key research question remains open: how can a humanoid execute the human actions from generated videos in a zero-shot manner? This challenge arises because generated videos are often noisy and exhibit morphological distortions that make direct imitation difficult compared to real video. To address this, we introduce a two-stage pipeline. First, we lift video pixels into a 4D human representation and then retarget to the humanoid morphology. Second, we propose GenMimic-a physics-aware reinforcement learning policy conditioned on 3D keypoints, and trained with symmetry regularization and keypoint-weighted tracking rewards. As a result, GenMimic can mimic human actions from noisy, generated videos. We curate GenMimicBench, a synthetic human-motion dataset generated using two video generation models across a spectrum of actions and contexts, establishing a benchmark for assessing zero-shot generalization and policy robustness. Extensive experiments demonstrate improvements over strong baselines in simulation and confirm coherent, physically stable motion tracking on a Unitree G1 humanoid robot without fine-tuning. This work offers a promising path to realizing the potential of video generation models as high-level policies for robot control.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
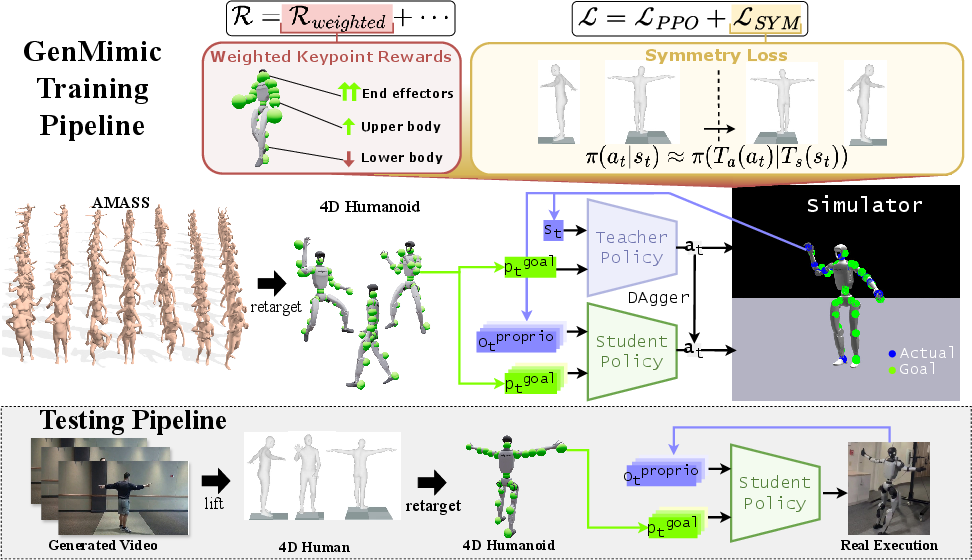
This paper shows how a humanoid robot can watch a video of a person doing something and then do the same thing itself—even if the video was generated by an AI from a text prompt. The authors introduce a system called GenMimic that turns AI-made human videos into safe, realistic robot movements without retraining for each new task (this is called “zero-shot”).
What questions does it try to answer?
In simple terms, the paper asks:
- How can a robot copy human actions from videos that might be fuzzy, imperfect, or “made up” by an AI?
- Can we make a robot follow the important parts of a motion (like hands and feet) even when the video is noisy?
- Will this work not only in simulation, but also on a real humanoid robot?
How did the researchers do it?
They use a two-stage process, plus a special training method to make the robot robust to noisy inputs.
Stage 1: From video pixels to a “4D” human motion
- Think of “4D” as 3D in space plus time. The system takes a video and builds a moving 3D model of a person across frames.
- It uses a digital human body model (called SMPL) to estimate where each body joint is.
- Because humans and robots have different “body shapes” and joints (morphology), the human motion is “retargeted” to the robot’s body—like tailoring clothes from one person to fit another. This creates the robot’s version of the motion.
Stage 2: From human motion to robot actions
- The robot doesn’t copy raw joint angles directly. Instead, it focuses on “keypoints,” which are important 3D dots on the body (like hands, elbows, knees, feet).
- The robot’s control policy (GenMimic) is trained to move so its keypoints match the target keypoints. This is more robust to noise and weird shapes in generated videos.
- The policy outputs desired joint angles, and a PD controller (a standard robotics tool that acts like springs and dampers) converts those into smooth, stable torques for the robot’s motors.
What makes GenMimic robust?
- Weighted keypoints: Some body parts matter more than others. For example, hands and feet (end effectors) are crucial to make actions look right. The system gives these more “attention” and cares less about noisier parts (like lower body in certain videos).
- Symmetry learning: Human bodies are roughly symmetric (left and right sides). The policy learns this mirror pattern. If one side is noisy (say the left arm is unclear), it can infer from the right side—like using a mirror to check your form.
How was it trained?
- The policy trains in simulation using reinforcement learning (RL). There’s a “teacher” policy with extra internal information and a “student” policy that learns from the teacher to work with real-world observations. This is called a student–teacher setup.
- Training uses a large dataset of recorded human motions (AMASS), then retargets them to the robot’s body.
- Domain randomization adds varied physics and noise during training so the policy is prepared for real-world messiness.
How is it evaluated?
- The authors built a new dataset, GenMimicBench, with 428 AI-generated videos of humans doing different actions in simple and realistic scenes. These were made using two modern video generators (Wan2.1 and Cosmos-Predict2).
- They test GenMimic in both simulation and on a real Unitree G1 humanoid robot.
What did they find, and why is it important?
- In simulation, GenMimic tracked motions more successfully and more stably than strong baselines, especially when the input videos were noisy or distorted. The added keypoint weighting and symmetry loss made a clear difference.
- In real-world tests on the Unitree G1 robot, the system reproduced many upper-body actions (like waving, pointing, reaching, and simple sequences) without task-specific retraining. Actions that require stepping or turning were harder—it could often orient correctly but sometimes stumbled—highlighting the challenge of imperfect video cues.
- Overall, the results show it’s possible to use AI-generated videos as high-level “plans” for robots and execute them physically in a zero-shot way.
Why does this matter?
- It moves robots closer to “watch and do” behavior: you describe an action in text, an AI makes a video, and the robot performs it—no custom coding needed.
- It opens a path to flexible, general-purpose robot control where videos become easy-to-create instructions.
- It shows that combining video generation with physics-aware imitation can handle imperfect inputs, a key step toward robust real-world robots.
Limitations and future impact
- The system depends on the quality of the generated video and the 4D reconstruction. Better video generators and reconstruction models should improve performance.
- It was trained mostly on one motion dataset (AMASS); adding more diverse data could help with complex or dynamic actions.
- Harder tasks like fast, athletic, or object-heavy motions remain challenging. The authors suggest learning a shared “motion language” (latent representations) that connects simple, complex, real, and generated motions.
In the big picture, this work hints at a future where robots can learn new tasks from videos they’ve never seen before—potentially making robots more adaptable in homes, workplaces, and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or left unexplored in the paper, phrased to guide concrete next steps for future research:
- End-to-end, real-time operation: The pipeline appears to reconstruct full 4D trajectories offline and then execute; latency budgets and feasibility of streaming video-to-action with low delay are not analyzed or demonstrated.
- Scale and frame alignment from monocular video: The method assumes reliable global pose and scale from 4D reconstruction; there is no analysis of monocular scale ambiguity, camera motion, or world-frame registration and their impact on global tracking (e.g., walking/turns).
- Uncertainty-aware conditioning: Fixed keypoint weights are used; the policy does not incorporate per-keypoint confidence from the 4D reconstructor or a learned uncertainty model to adaptively down-weight unreliable joints over time.
- Contact and footstep inference: No explicit extraction or use of contact schedules (e.g., foot-ground contacts) from generated videos; stepping and turning failures suggest a need for contact-aware tracking and footstep planning integrated with the policy.
- Object-interaction grounding: Generated videos include object interactions, but the controller does not model objects, contact constraints, grasping, or object state estimation; how to translate generated object motions into feasible robot-object interactions is open.
- Robustness to occlusion, multi-person scenes, and moving cameras: Benchmarks do not systematically evaluate partial observability, multiple people, or severe viewpoint changes; robustness in these settings is unknown.
- Multi-view exploitation: Multi-view videos exist in a subset (Wan2.1), yet the pipeline does not fuse views to reduce ambiguity and improve 4D reconstruction quality.
- Retargeting fidelity and constraints: The PHC-based retargeting is treated as a black box; there is no quantitative study of kinematic consistency, joint-limit handling, contact preservation, or how retargeting errors propagate to control performance.
- Failure attribution: There is no decomposition of errors across stages (video generation vs 4D reconstruction vs retargeting vs policy); a diagnostic dataset with per-stage error labels is missing.
- Symmetry loss side effects: While symmetry regularization improves robustness, its effect on inherently asymmetric motions (e.g., one-handed tasks, sport-like swings) is not evaluated; criteria for when symmetry hurts vs helps are unclear.
- Dynamic weighting strategies: Fixed end-effector weighting improves robustness but is task-agnostic; learning context- and time-varying weights (e.g., from video semantics, action phase, or estimated noise) is unexplored.
- Temporal alignment and timing: The approach does not address time-warping or tempo differences between generated videos and robot execution; sensitivity to the goal horizon length and temporal misalignment is not studied.
- Long-horizon memory: The policy is a feed-forward MLP with short lookahead; whether recurrent or transformer architectures improve long sequences, turning, and composite actions is untested.
- Safety and feasibility filters: There is no upstream feasibility check or safety layer (e.g., control barrier functions, MPC overlays) to reject or reshape infeasible goals from noisy videos before execution on hardware.
- Sim-to-real gaps and identification: While domain randomization is used, no systematic sensitivity analysis identifies which randomizations are most impactful; online system identification or adaptive gain tuning is not explored.
- Metrics tied to noisy ground truth: MPKPE/LMPKPE are computed against noisy reconstructions; task-oriented metrics (e.g., contact stability, foot-slip, energy use, CoM margins, human ratings) and physically grounded success measures are underdeveloped.
- Dataset scale and diversity: GenMimicBench has 428 clips with limited subjects and action diversity, and sparse dynamic motions; lack of ground-truth 3D, contact labels, and quality annotations makes benchmarking and fair comparison difficult.
- Baseline comparability: Baselines differ in training data, privileges, and inputs; a standardized evaluation protocol with matched observation spaces, training sets, and retraining would enable fairer comparisons.
- Generalization across embodiments: The policy is trained and evaluated on Unitree G1; portability to other humanoid morphologies, and how much retargeting vs policy retraining is required, remains untested.
- Integration with high-level planners: The work treats generated video as a planner, but does not close the loop among language, scene constraints, and action duration/ordering; how to couple LLM/VLM task planning with video synthesis and control is open.
- Streaming visual feedback during execution: The robot does not use onboard perception to correct drift or re-align with the intended motion; integrating visual servoing or online 3D goal updates is left unexplored.
- Training data limitations: Training only on AMASS (filtered to non-interaction, low-retarget-error sequences) may bias away from contact-rich and dynamic behaviors; incorporating interaction-rich datasets or synthetic-but-regularized motions is an open path.
- Learning from synthetic videos: The policy deliberately avoids training on generated videos; whether co-training with denoised/refined synthetic trajectories, or joint training of the reconstructor and policy, can improve robustness is unanswered.
- Hardware limits and wear: Real-world trials report only visual success; measurements of joint torque utilization, thermal limits, and long-duration stability on hardware are missing.
- Compute and deployment costs: Throughput and latency for TRAM+PHC+policy on embedded hardware are not quantified; feasibility for interactive control or onboard-only processing is unclear.
- Hand and fine manipulation: The approach ignores hand articulation and grasp planning; representing and executing fine-scale, dexterous motions from generated videos remains an open challenge.
- Contact-consistent trajectory reconstruction: Foot-skate removal, contact-consistent IK, or physics-based trajectory correction for reconstructed motions are not applied; their effect on stepping and turning success is unknown.
Practical Applications
Overview
This paper introduces GenMimic, a two-stage pipeline that converts text-prompted, generated human videos into physically plausible humanoid robot motions without task-specific fine-tuning. It leverages 4D human reconstruction and morphology retargeting, followed by a physics-aware RL tracking policy trained with symmetry regularization and keypoint-weighted rewards. The authors also release GenMimicBench, a synthetic dataset of human motions produced by two video generation models. Below are practical applications derived from these findings, methods, and innovations.
Immediate Applications
The following applications can be deployed now with current capabilities (noting upper-body motions are most reliable and stepping/turning remain challenging).
- Prompt-driven humanoid demonstrations and telepresence (Robotics, Entertainment)
- Use case: Trigger expressive upper-body gestures—waving, pointing, arm folding, thumbs-up—on robots during demos, showroom interactions, conferences, and telepresence sessions.
- Tools/workflows: “Video-to-Action” pipeline (text prompt → generated video → 4D reconstruction → retargeting → GenMimic policy on Unitree G1 or similar humanoids); ROS integration as a node consuming 3D keypoint goals.
- Assumptions/dependencies: Stable 4D reconstruction of upper-body motions; safe operation areas; adequate PD controller tuning; compute for real-time inference.
- Gesture repertoire expansion for social HRI (Retail, Hospitality, Public Services)
- Use case: Quickly synthesize friendly or culturally appropriate gestures for greeters, museum guides, or reception robots based on text prompts (e.g., “bow slightly then wave right hand”).
- Tools/products: “GenMimic SDK” to define gesture libraries; prompt-based gesture composer; safety guardrails for velocity and joint limits.
- Assumptions/dependencies: Consistent robot-to-human morphology retargeting; controlled environments; operators trained in fail-safe procedures.
- Robotics R&D benchmarking with GenMimicBench (Academia, Robotics)
- Use case: Evaluate robustness of tracking policies under realistic noise and morphological distortions; compare privileged vs. unprivileged perception setups.
- Tools/workflows: GenMimicBench as a standard evaluation suite; IsaacGym-based training; ablation protocols for weighted keypoint rewards and symmetry losses.
- Assumptions/dependencies: Access to dataset and simulation stack; reproducibility of baselines; adherence to standardized SR/MPKPE metrics.
- Visual programming-by-demonstration for simple motions (Software, Robotics)
- Use case: Replace scripting for simple motions with prompt-based generation (e.g., “raise right arm, point forward”). Useful for rapid prototyping and teaching sequences without mocap.
- Tools/products: “Prompt-to-Action” IDE plugin; 3D keypoint goal editor; workflow templates for video generation models (Wan2.1, Cosmos-Predict2).
- Assumptions/dependencies: Reliable video generation of target motion; acceptable 4D lifting accuracy; operators validate the final motion in simulation before deployment.
- Stage and installation choreography for robots (Entertainment, Arts)
- Use case: Design show programs where robot ensembles perform synchronized upper-body gestures derived from generated videos; live art installations reacting to audience prompts.
- Tools/products: “Action Composer” that sequences multiple generated clips; on-robot synchronization via sub-stepping PD control and time alignment.
- Assumptions/dependencies: Tight timing control; safety cordons; motion verification; stable footing (limited stepping/turning in current capability).
- Safety stress-testing of controllers with noisy inputs (Policy, Safety Engineering)
- Use case: Use GenMimicBench to deliberately probe failure modes (e.g., stumbling on turning) and audit controllers before field use; calibrate safety envelopes for humanoids.
- Tools/workflows: Audit harness that logs SR/VSR, MPKPE-NT, and contact violations; automatic test generation with domain randomization.
- Assumptions/dependencies: Access to closed-loop telemetry; clearly defined success/failure criteria; supervisory kill switch procedures.
- Curriculum and lab modules in robotics courses (Academia, Education)
- Use case: Teach students simulation-to-real pipelines, motion retargeting, and robust RL policy design (weighted keypoints, symmetry loss).
- Tools/workflows: Course kits containing GenMimic code/checkpoints, IsaacGym scripts, and simplified ROS deployment.
- Assumptions/dependencies: GPU resources; compatible humanoid hardware or simulators; adherence to campus safety protocols.
- Digital twin prototyping for motion feasibility (Manufacturing, Robotics)
- Use case: Validate that a planned gesture sequence for human–robot collaboration is physically realizable by a humanoid in a digital twin before onsite trials.
- Tools/workflows: 4D reconstruction from planned videos; retargeting to factory humanoid model; physics simulation in IsaacGym.
- Assumptions/dependencies: Accurate factory environment model; calibrated robot dynamics; limited to non-contact upper-body motions in current version.
- Reusable control building blocks (Software, Robotics)
- Use case: Adopt symmetry regularization and keypoint-weighted reward design in other tracking/imitation controllers to improve robustness.
- Tools/workflows: Drop-in RL modules; reward design libraries; evaluation scripts using NT metrics for unbiased comparison.
- Assumptions/dependencies: Access to training data (AMASS or internal); alignment of keypoint schemas across embodiments.
Long-Term Applications
These require further research, scaling, or integration (e.g., reliable locomotion, object interaction, scene awareness, safety certification).
- Household assistance via generative video planning (Robotics, Daily Life)
- Use case: Text/video prompts generate multistep behaviors (walk to table, pick up cup, place on counter) executed zero-shot by home humanoids.
- Tools/products: Unified VLA+GenMimic stack where LLM/VLM plans tasks and GenMimic handles motion-level execution; on-robot 4D reconstruction modules.
- Assumptions/dependencies: Robust lower-body locomotion; reliable object interaction; scene/context grounding; strong safety systems and certification.
- Industrial assembly and human-robot collaboration (Manufacturing, Robotics)
- Use case: Prompt-driven generation of assembly motions from SOPs; robots learn nuanced manipulation sequences and body positioning from synthesized videos.
- Tools/workflows: Integration with scene-aware controllers (VideoMimic/ResMimic-like); task graphs linking prompts to multi-stage motions; digital twin validation.
- Assumptions/dependencies: High-fidelity 4D lifting in clutter; force/torque control; standards for safe co-working; liability frameworks.
- Rehabilitation and physical therapy instruction (Healthcare)
- Use case: Robots demonstrate personalized exercise routines synthesized from clinician-provided text/video prompts; adapt difficulty in real time.
- Tools/products: Clinical “Prompt-to-Exercise” planner; motion safety verifiers; patient monitoring sensors.
- Assumptions/dependencies: Medical-grade reliability; precise kinematics for complex movements; regulatory approval; clinician oversight.
- Sports coaching and embodied education (Education, Sports Tech)
- Use case: Robots demonstrate technique drills (dance, martial arts) generated from curated prompts; learners compare their motion to the robot exemplar.
- Tools/workflows: Latent motion representations for dynamic actions; on-robot feedback via vision sensors; scorecards and analytics.
- Assumptions/dependencies: Accurate and safe dynamic motion tracking; low latency sensing; robust evaluation metrics beyond keypoint error.
- Generalist policy pretraining on large synthetic motion corpora (Academia, Software)
- Use case: Train universal humanoid controllers using vast synthetic motion datasets; bridge simple, complex, real, and generated motions via learned latent spaces.
- Tools/workflows: Scalable motion generators; self-supervised weight learning; curriculum schedules for domain randomization.
- Assumptions/dependencies: Compute scale; diverse, high-quality synthetic data that mirrors real distributions; reliable sim-to-real transfer.
- Emergency response and remote operations (Public Safety, Defense)
- Use case: Rapidly synthesize motion plans (open door, clear obstacle, hand signals) from text prompts during disasters; deploy on field robots.
- Tools/workflows: Offline/edge-capable generative video and 4D lifting; robust locomotion and manipulation; encrypted teleoperation fallback.
- Assumptions/dependencies: Harsh environment resilience; fault tolerance; strong safety overrides; policy governance for mission-critical use.
- Sign language and culturally adaptive gesture synthesis (Accessibility, Public Services)
- Use case: Generate localized gestures/signs that robots can perform to improve accessibility and inclusivity in public spaces.
- Tools/products: Gesture libraries mapped to regional standards; semantic-to-motion translation; compliance checker.
- Assumptions/dependencies: Cultural/linguistic validation; precision in hand/finger articulation; safety in close proximity.
- Productization as a “Prompt-to-Action” platform (Software, Finance/Business)
- Use case: Offer APIs where customers define robot motions via prompts; monetization through motion templates, safety-certified packs, and analytics.
- Tools/products: SaaS with versioned motion catalogs; deployment orchestrators; ROS 2 plugins for multiple hardware vendors.
- Assumptions/dependencies: Vendor-agnostic retargeting; licensing for video generation models; SLAs for reliability; audit trails and governance.
- Standardization and certification for generative-control chains (Policy, Standards)
- Use case: Create regulatory frameworks for end-to-end pipelines—video generation, 4D lifting, retargeting, controller execution—with safety audits and test suites.
- Tools/workflows: Conformance tests based on GenMimicBench-like stressors; reporting protocols for failure modes; watermarking of generative media.
- Assumptions/dependencies: Multi-stakeholder coordination; legal clarity on liability; established benchmarks and independent labs.
- On-device 4D reconstruction and closed-loop scene-aware control (Robotics, Software)
- Use case: Run video lifting, retargeting, and control entirely on robot hardware with dynamic adaptation to obstacles and terrain.
- Tools/workflows: Efficient 4D reconstruction models; multi-sensor fusion; online re-planning; energy-aware scheduling.
- Assumptions/dependencies: Edge compute capabilities; robust sensor suites; safe locomotion; improved sample efficiency in RL.
Cross-cutting dependencies and assumptions
- Motion quality and realism: Applications depend on the fidelity of generated videos and robustness of 4D reconstruction (occlusions, camera motion, clutter).
- Morphology and hardware: Successful retargeting requires humanoid morphology comparable to SMPL-like skeletons; controller gains and motor strength must be calibrated.
- Safety and compliance: Physical interactions (locomotion, manipulation) require safety envelopes, certification, and human supervision until reliability improves.
- Compute and latency: Real-time control needs sufficient GPU/CPU; offline generation may be acceptable for pre-scripted demos but not for interactive tasks.
- Data and licensing: Use of third-party video generation models may involve licensing and governance; synthetic datasets must be audited for bias and edge cases.
- Integration and scalability: For complex tasks, integration with scene-aware policies, VLA models, and perception stacks is necessary; workflows should include simulation-to-real validation.
Glossary
- 3D keypoints: Discrete three-dimensional joint or landmark positions used to represent and track body pose. "conditioned on 3D keypoints"
- 4D human reconstruction: Recovery of time-varying 3D human pose and shape from video (3D plus time). "4D human reconstruction from video"
- AMASS: A large-scale motion capture dataset of human movements used for training and evaluation. "We train GenMimic on human motion trajectories from AMASS \cite{amass},"
- Bilateral symmetry: The property that the left and right sides of the body are mirror images, used as a learning bias. "The human body exhibits inherent bilateral symmetry, where the left and right sides are approximate mirror images."
- DAgger: A dataset aggregation algorithm for policy learning via iterative expert supervision. "using DAgger~\cite{dagger}"
- Degrees of Freedom (DoFs): Independent control variables for joints or actuators defining possible movements. "and is conditioned on DoFs."
- Domain Randomization: A training technique that randomizes simulation parameters to improve sim-to-real transfer. "{Domain Randomization}"
- End effector: The terminal part of a kinematic chain (e.g., hands or feet) crucial for task execution. "Certain keypoints, such as those corresponding to the end effectors, are inherently more critical..."
- Forward kinematics: Computing body or joint positions from known joint angles and link configurations. "calculated using forward kinematics."
- IsaacGym: A GPU-accelerated physics simulation platform for reinforcement learning. "using reinforcement learning (RL) in IsaacGym~\cite{isaacgym}"
- Inductive bias: Assumptions injected into learning to guide generalization and robustness. "This loss introduces an inductive bias for robustness"
- LMPKPE: Local Mean Per-Keypoint Positional Error; pose tracking error measured in local coordinates. "in both global (MPKPE) and local (LMPKPE) coordinates."
- Mixture-of-experts: A model design that combines multiple specialized experts guided by a gating mechanism. "using a mixture-of-experts teacher"
- MPKPE: Mean Per-Keypoint Positional Error; global pose tracking error across keypoints. "in both global (MPKPE) and local (LMPKPE) coordinates."
- MPKPE-NT: MPKPE computed with No Termination; evaluates error over entire trajectories regardless of failures. "we additionally report the unconditional metrics MPKPE-NT and LMPKPE-NT (No Termination)"
- Morphology gap: Differences between human and robot body structures that complicate direct imitation. "To minimize the morphology gap from the first stage, we retarget the human motion trajectory to the robot morphology."
- Partially Observable Markov Decision Process: A sequential decision framework where the agent has incomplete state information. "We formulate tracking humanoid motion as a decision problem modeled by a Partially Observable Markov Decision Process"
- PD controller: Proportional-Derivative controller that converts desired joint angles into torques. "a proportional-derivative (PD) controller which outputs actionable torques to the robot."
- PPO: Proximal Policy Optimization; a popular on-policy reinforcement learning algorithm. "using Proximal Policy Optimization (PPO) \cite{ppo}."
- Proprioceptive: Internal sensing of the robot’s state (e.g., joint positions and velocities). "we assume access to the robot's current proprioceptive state"
- Quaternion: A rotation representation in 3D space that avoids singularities. "quaternion ()"
- Retargeting: Mapping human motion to a robot’s joint-space while respecting its embodiment. "we retarget the SMPL trajectory to the robot morphology."
- Self-supervised: Learning signals derived from the data itself without explicit external labels. "We also consider a data-driven, self-supervised approach to learning these weights."
- Sim-to-real: The transfer of policies learned in simulation to real-world robots. "and sim-to-real differences"
- SMPL: Skinned Multi-Person Linear model; a parametric human body model for pose and shape. "SMPL \cite{smpl} parameters (shape and per-joint angle-axis )."
- Student–teacher framework: A training setup where a student policy imitates a privileged teacher policy. "via a studentâteacher framework."
- Success Rate (SR): The percentage of trajectories completed without falls and with limited deviation from the goal. "We define the Success Rate (SR) as the percentage of rollouts where the robot does not fall and its global position does not deviate by more than 0.5m from the goal."
- Symmetry loss: An auxiliary objective encouraging consistent behavior across mirrored states and actions. "an auxiliary symmetry loss"
- TRAM: A 4D human reconstruction model used to extract motion from video. "utilizes TRAM \cite{tram} for 4D human reconstruction from video"
- Visual Success Rate (VSR): A qualitative metric assessing whether execution visually matches the target motion. "Visual Success Rate (VSR),"
- Weighted keypoint reward: A tracking objective that emphasizes critical keypoints (e.g., hands) over others. "weighted keypoint tracking reward"
- Zero-shot: Performing tasks or generalizing to new inputs without task-specific fine-tuning. "in a zero-shot manner."
Collections
Sign up for free to add this paper to one or more collections.

