ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Abstract: Humanoid whole-body loco-manipulation promises transformative capabilities for daily service and warehouse tasks. While recent advances in general motion tracking (GMT) have enabled humanoids to reproduce diverse human motions, these policies lack the precision and object awareness required for loco-manipulation. To this end, we introduce ResMimic, a two-stage residual learning framework for precise and expressive humanoid control from human motion data. First, a GMT policy, trained on large-scale human-only motion, serves as a task-agnostic base for generating human-like whole-body movements. An efficient but precise residual policy is then learned to refine the GMT outputs to improve locomotion and incorporate object interaction. To further facilitate efficient training, we design (i) a point-cloud-based object tracking reward for smoother optimization, (ii) a contact reward that encourages accurate humanoid body-object interactions, and (iii) a curriculum-based virtual object controller to stabilize early training. We evaluate ResMimic in both simulation and on a real Unitree G1 humanoid. Results show substantial gains in task success, training efficiency, and robustness over strong baselines. Videos are available at https://resmimic.github.io/ .


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What the paper is about (in simple terms)
This paper is about teaching a human-shaped robot (a humanoid) to do tasks that involve both moving around and handling objects at the same time—like walking over to a box, picking it up, carrying it on its back, or lifting a chair using its whole body. The authors introduce a method called ResMimic that first learns how to move like a human in general, and then adds small, smart corrections so the robot can interact with objects precisely and safely.
Humans naturally use their whole body to handle heavy or awkward things (arms, torso, legs, balance). Getting a robot to do that reliably is hard. ResMimic makes it easier and faster.
The main questions the paper asks
- Can a robot that already learned to copy human movement be upgraded to handle objects well without retraining everything from scratch?
- Is it better to add small corrections on top of a general “move-like-a-human” skill, or to fine-tune the whole skill directly?
- Will this approach work not only in simulation but also on a real robot?
How the method works
Think of ResMimic like this: you start with a good dancer (the robot learned to copy human moves), then a coach gives small, targeted notes to improve tricky parts (like gripping and lifting a box) without changing the whole routine.
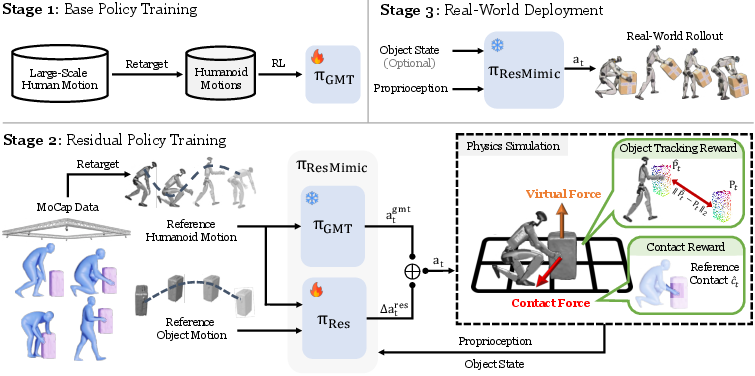
Stage 1: Learn to move like a human (the base skill)
- The robot learns “general motion tracking” (GMT): copying lots of human movements from big motion-capture datasets (things like walking, reaching, bending).
- This stage does not include objects. It’s just about moving smoothly and in balance, like a human would.
- This gives the robot a strong, flexible base: it can stand, step, reach, and coordinate its whole body.
Stage 2: Add small corrections for object handling (the “residual”)
- Now the robot learns a “residual” policy—think of it as tiny tweaks added on top of the base movements.
- These tweaks use object information (where the box or chair is, how it’s moving) to adjust hands, arms, torso, and balance just enough to grip, lift, carry, or press.
- The final action = base move + small correction. Because the base is already good, learning the corrections is faster and more stable.
Simple explanations of the technical ideas they add
- Reinforcement learning: The robot learns by trial and error, like playing a game where it gets points for doing things right (staying balanced, matching motions, moving the object correctly).
- Point-cloud object reward: Instead of comparing the object’s position and rotation separately, they cover the object with lots of tiny dots and compare where the dots end up. If the dots match the goal, the robot gets a higher score. This is smoother and makes learning easier.
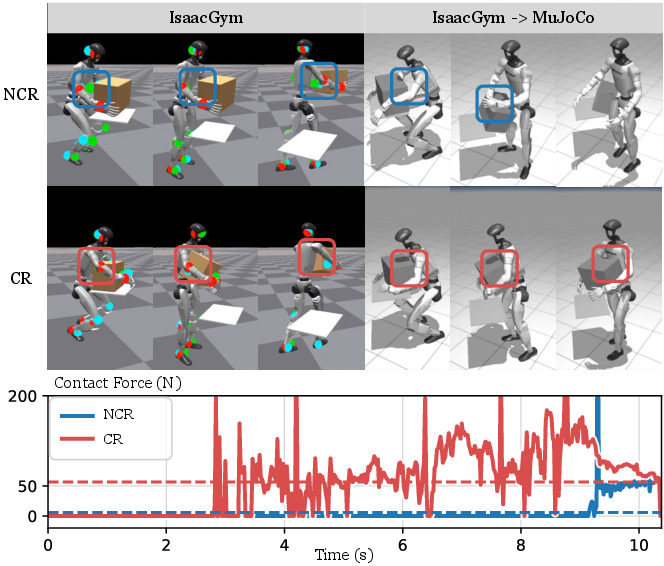
- Contact reward: The robot gets extra points for making the right kind of contact with the object (for example, using its torso and arms together), not just touching it anywhere. This encourages realistic, whole-body strategies that work better in the real world.
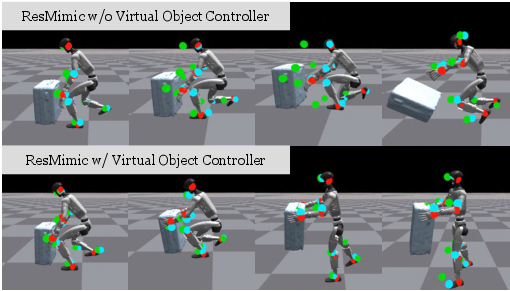
- Virtual object controller (a training helper): At the start of learning, the object gets gentle “invisible hands” (small virtual pushes) that guide it toward where it’s supposed to go. This prevents early chaos—like the robot accidentally knocking the box over—so the robot can learn good habits first. These invisible helps fade out over time.
- Domain randomization: During training, they vary things like object positions and small physics details so the robot becomes more robust and can handle differences between simulation and the real world.
What they found and why it matters
In simulations and on a real Unitree G1 humanoid robot, ResMimic:
- Worked on several hard, whole-body tasks:
- Kneel on one knee and lift a box
- Carry a box on the back
- Squat and lift a box using arms and torso
- Lift and carry a chair (irregular shape, heavier)
- Beat strong alternatives:
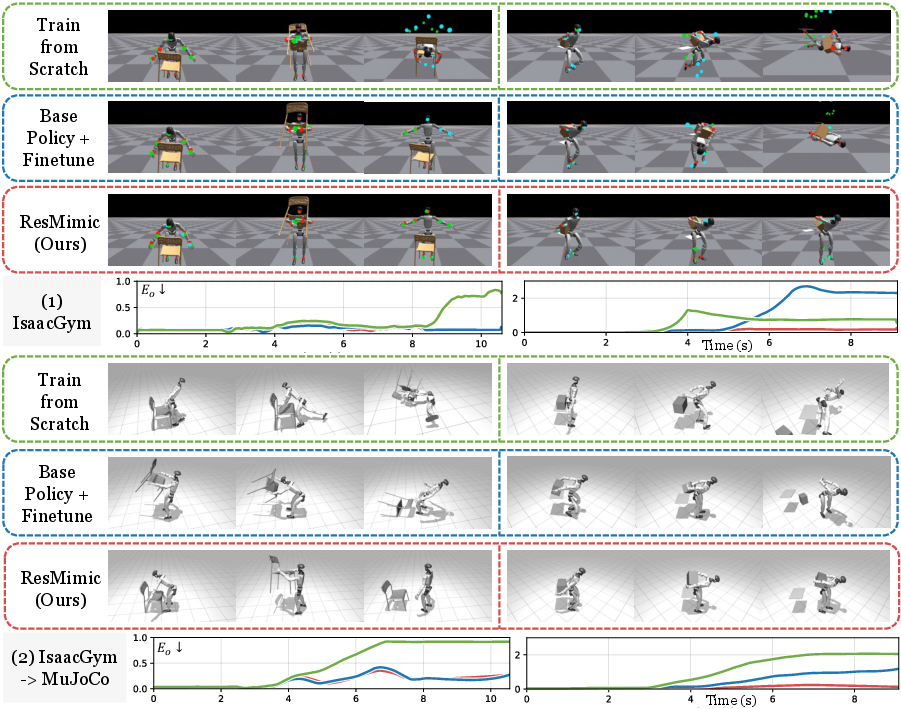
- Just using the base “copy humans” skill wasn’t enough—only about 10% success on tasks that involve objects.
- Training from scratch was slow and often failed to transfer to a different simulator (a tougher test) or the real world.
- Fine-tuning the base skill directly (without adding object inputs and residuals) helped a little but still fell short.
- ResMimic reached about 92% success on average across tasks in the tougher simulator, with faster training and better object accuracy.
- Worked in the real world:
- The robot carried heavy loads (around 4.5 kg) safely by using its torso and arms together—not just its wrists.
- It handled different shapes (like multiple chairs), not just one specific object.
- It could also react to bumps and start from random object positions when given object tracking from motion capture.
Why this matters: The robot didn’t just move like a human—it could actually handle real objects precisely and robustly, which is essential for useful jobs in homes and warehouses.
What this could mean for the future
- A reusable recipe: First learn broad, human-like movement from lots of data. Then, add small, task-specific corrections to handle objects. This is efficient, general, and avoids building a brand-new controller for every task.
- Better real-world robots: Using whole-body contact (not just hands) lets robots handle heavier, awkward items more safely, much like people do.
- Faster progress: Because the approach separates “moving like a human” from “fine-tuning for objects,” new tasks and objects can be added with less data and less time.
- A path to more capable humanoids: This strategy—pretrain broadly, then refine with residuals—could apply beyond carrying and lifting, toward more complex everyday chores and warehouse work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps and unresolved questions that future work could address:
- Onboard perception: The real-world non-blind setup uses MoCap for object state; there is no evaluation with onboard sensing (vision, depth, tactile/force) and no perception pipeline for object pose/state estimation under noise and occlusion.
- Blind deployment mismatch: The paper claims blind deployment without object input, but the residual policy is trained with object states. Clarify training/deployment regimes and quantify performance degradation when training and testing are both blind; develop methods to make residuals robust without object inputs.
- Data dependence on human–object MoCap: Residual training requires object reference trajectories from MoCap. Explore learning residuals from sparse supervision, weak labels, self-supervision, or purely RL without object references; assess how much MoCap data is actually needed.
- Limited task diversity: Only four tasks (kneel/carry/squat/chair) are evaluated; extend to broader loco-manipulation (e.g., pushing, pulling, lifting with feet, opening articulated objects, tool use, bimanual manipulation) and quantify generality.
- Object diversity and materials: Experiments focus on boxes and chairs (rigid, simple shapes). Test articulated, deformable, slippery, soft, and high-friction objects; vary mass distribution and center of mass; characterize failure modes.
- Heavy payload limits: Real-world payloads up to 4.5–5.5 kg are shown. Systematically benchmark payload robustness across heavier objects, different mass distributions, and dynamic load changes; include safety limits and recovery strategies.
- Environment diversity: Real-world trials are on flat floors; evaluate uneven terrain, slopes, stairs, cluttered environments, and varying ground friction; assess stability and contact robustness.
- Long-horizon autonomy: Loco-manipulation sequences appear pre-scripted via reference trajectories. Investigate online re-planning, closed-loop goal updates without pre-recorded future motion windows, and multi-step task chaining with failure recovery.
- Residual policy generality: Residuals are trained per task. Develop a single goal-conditioned multi-task residual policy that generalizes across tasks and objects; quantify cross-task transfer and sample efficiency.
- Architectural baseline fairness: Fine-tuning baseline cannot ingest object observations due to architecture constraints. Evaluate stronger baselines that modify the GMT architecture to include object inputs and compare against residual learning under identical observation spaces.
- Contact reward safety: The contact reward formulation rc encourages larger contact forces (exp(-λ/f)); assess risks of excessive forces, propose force-limited or impedance-aware rewards, and add safety constraints (force/pressure limits, joint load thresholds).
- Contact discretization: Contacts are discretized over a few links (torso, hip, arms), excluding feet. Explore continuous contact modeling, foot–object contacts, and nuanced contact surfaces; measure impact on tasks requiring leg involvement.
- Virtual object controller (VOC) realism: VOC provides non-physical assistance during training. Quantify potential bias, develop adaptive/learned assistance schedules, and test training without VOC; ablate gain schedules and termination of assistance.
- Point-cloud reward sensitivity: The object tracking reward relies on mesh-based point sampling. Analyze sensitivity to point count, mesh quality/scale, occlusions, and sensor noise; compare against alternative metrics (Chamfer/EMD, SE(3) pose errors) and differentiable pose estimators.
- Reward weighting claims: Although decoupling avoids motion–object weight tuning, λ parameters still exist (e.g., λ_o, λ in contact). Systematically study reward hyperparameter sensitivity and automate tuning (e.g., meta-optimization, population-based training).
- Future reference windows: Inputs include future frames (t−10:t+10), implying access to lookahead trajectories. Evaluate performance when only current/short-horizon goals are available; integrate predictive models for future motion and object trajectories.
- Control modality: Actions are joint targets with PD control. Compare torque/impedance/admittance control, analyze compliance and impact safety, and assess effects on sim-to-real transfer and contact stability.
- Sim-to-real metrics and rigor: Real-world evaluation is largely qualitative. Provide quantitative real-world metrics (success rates, contact forces, energy, cycle time, recovery rates) over many trials with statistical significance; include failure taxonomy.
- Disturbance robustness: Reactive behavior to perturbations is shown qualitatively. Design systematic perturbation benchmarks (magnitudes, directions, timings) and measure recovery performance and stability margins.
- Safety in human-centric spaces: No assessment of collision avoidance, safe contact thresholds, or risk-aware control around humans. Integrate safety monitors, certified constraints, and formal verification for deployment in shared spaces.
- Transfer across morphologies: Results are on Unitree G1; evaluate portability to other humanoids (different DoF, sizes, actuation, compliance) and quantify retargeting and policy adaptation needs.
- Retargeting imperfections: Penetrations/floating contacts remain in retargeted data. Develop methods to detect and correct retargeting errors (e.g., contact-aware retargeting, differentiable constraints) and quantify their effect on learning and transfer.
- Expressiveness measurement: “Expressive” motions are not quantitatively evaluated. Define and measure expressiveness/style fidelity (e.g., style classifiers, motion descriptors), and analyze trade-offs with task success and safety.
- Success criteria standardization: Task success thresholds (E_o) are not specified. Standardize success/failure criteria per task and report sensitivity to thresholds.
- Computational footprint: Real-time performance, latency, and compute requirements on the robot are not reported. Measure inference latency, CPU/GPU usage, and scalability to embedded hardware.
- Multi-skill sequencing and policy composition: There is no mechanism for sequencing multiple residual-corrected skills or switching contacts/modes. Investigate hierarchical control, skill libraries, and policy composition for long tasks.
- Integration with planning/foundation models: Explore coupling ResMimic with high-level planners or vision-language-action models for goal specification, task selection, and on-the-fly reference generation.
- Instance-level generalization quantification: Claims of instance-level generalization (chairs) are qualitative. Quantify across large sets of novel instances with varying geometry/material, and report performance distributions.
- Benchmarking against state-of-the-art loco-manipulation: Compare with recent modular RL or trajectory-optimization-based methods on identical tasks and metrics to contextualize gains.
- Release and reproducibility: Planned releases mention simulation infrastructure and data, but details are sparse. Ensure full reproducibility (code, hyperparameters, trained checkpoints, evaluation scripts, object meshes, and real-world protocols).
Practical Applications
Practical Applications of ResMimic: From Findings to Real-World Impact
Below are actionable applications derived from the paper’s residual learning framework, training strategies, and sim-to-real results. Each item is labeled with sector(s), potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
These applications can be piloted or deployed now, especially in instrumented environments (e.g., with MoCap or fiducials) and with commercially available humanoids like Unitree G1.
- Whole-body box handling in warehouses (lift, carry, stow)
- Sectors: robotics, logistics/warehousing, retail
- Tools/products/workflows: “ResMimic Skill Pack” for Unitree G1; residual policy trained on site-specific box geometries; workflow to instrument object pose via MoCap/AprilTags; ROS-based job scheduler for pick-carry tasks; safety gating using early termination criteria
- Assumptions/dependencies: reliable object-state estimation (MoCap, markers, or robust vision); box meshes or dimensions; floor-level safety perimeters; humanoid wrist payload limits offset by torso/arm contact; battery life sufficient for carrying tasks
- Furniture moving and event setup (chairs, lightweight tables)
- Sectors: facilities management, hospitality/events, building services
- Tools/products/workflows: residual policies specialized for chair/table geometries; contact reward shaping to ensure torso/arm support; object-agnostic point-cloud reward to handle varied shapes; “Expressive Motion Library” for safe kneeling and lifting motions
- Assumptions/dependencies: simple geometric models or scanned meshes; instrumented venue for object state; human-in-the-loop supervisor for exceptions; robust balance control during uneven loads
- Hospital and clinic logistics (supply tote handling, room reconfiguration)
- Sectors: healthcare, robotics
- Tools/products/workflows: sterile-safe locomotion and lifting routines; MOI (motion-object interaction) skill library; integration with hospital scheduling systems and safety protocols; residual policy tuned for corridor navigation and contact-safe lifting
- Assumptions/dependencies: strict safety/cleanliness compliance; perception for dynamic obstacles; payload limits and ergonomics; clear SOPs for shared spaces with humans
- Back-of-store retail restocking and returns handling
- Sectors: retail, robotics
- Tools/products/workflows: ResMimic policy bundle for box/tote handling; workflows for scanning and pose estimation; sim-to-sim verification (IsaacGym→MuJoCo) before store deployment; unit tests using the released evaluation prototype
- Assumptions/dependencies: visible labels or markers for object pose; training on store-specific object sets; predictable aisle geometry and floor conditions
- Research and education: standardized pipeline for whole-body loco-manipulation
- Sectors: academia, software
- Tools/products/workflows: adoption of the released GPU-accelerated simulation infrastructure, sim-to-sim evaluation prototype, and curated motion data; curriculum-based virtual object controller module; point-cloud object tracking reward as a plug-in for PPO pipelines
- Assumptions/dependencies: access to IsaacGym/MuJoCo; MoCap or high-quality retargeting (GMR) for references; reproducible domain randomization settings
- Safer training workflows via virtual object force curricula
- Sectors: robotics research, software
- Tools/products/workflows: drop-in “Virtual Object Controller” to stabilize early RL; preconfigured gain schedules; regression tests documenting avoidance of local minima in contact-rich tasks
- Assumptions/dependencies: accurate object dynamics in simulation; ability to decay controller gains; verification in sim before real deployment
- General motion tracking for expressive service demonstrations
- Sectors: marketing, education, entertainment
- Tools/products/workflows: GMT-base policy for human-like motion reproduction; residual policy for object-aware gestures (e.g., carrying props); “Expressive Motion Packs” curated from AMASS/OMOMO
- Assumptions/dependencies: well-retargeted motion references; safety-aware contact constraints; predictable ground contact modeling
- Training-as-a-service for site-specific residual adaptation
- Sectors: robotics services, software
- Tools/products/workflows: cloud-based ResMimic training pipeline; client uploads human-object demos for residual finetuning; automated sim-to-sim sanity checks; on-site calibration for perception
- Assumptions/dependencies: data-sharing agreements; compute availability; privacy/auth compliance for human MoCap data; acceptable turnaround times
Long-Term Applications
These require further research, scaling, perception robustness, safety certification, or broader ecosystem development.
- Fully autonomous humanoid warehouse worker
- Sectors: robotics, logistics
- Tools/products/workflows: perception-driven object state (RGB-D/LiDAR) replacing MoCap; closed-loop residual policies conditioned on real-time point clouds; multi-task skill libraries (lift, carry, stack, palletize); digital twin for continual sim-to-real validation
- Assumptions/dependencies: reliable vision-based object-state estimation under occlusion; robust contact sensing; scalable safety certification; advanced fall-prevention and recovery policies
- Home service robots for daily heavy tasks (moving furniture, assisting with lifting)
- Sectors: consumer robotics, eldercare
- Tools/products/workflows: “Household Loco-Manipulation Suite” with guided instruction following; safe, compliant contact behaviors; adaptive residuals for diverse home geometries; integration with voice/VLA models for task planning
- Assumptions/dependencies: affordable, safe humanoids; high-quality perception in clutter; strong safety enforcement (children/pets); standards for in-home robot operation
- Collaborative humanoid co-workers alongside humans
- Sectors: manufacturing, construction, warehousing
- Tools/products/workflows: shared load carrying (co-manipulation) with vision-language-action models; intent inference from human motion; contact-aware residual corrections for safe co-lifting; automatic task orchestration with human supervisors
- Assumptions/dependencies: reliable human intent recognition; mutual safety protocols; standards for force limits and contact; regulatory approval for close-proximity collaboration
- Foundation models for whole-body loco-manipulation
- Sectors: software, robotics
- Tools/products/workflows: pre-trained GMT + residual adapters as “Humanoid Control Foundation Model”; open-world generalization with multimodal inputs (video, language, scene graphs); skill composition via residual stacks
- Assumptions/dependencies: large-scale human-object datasets; scalable retargeting across diverse embodiments; data governance for demonstrations; compute and benchmarking infrastructure
- Insurance, ergonomics, and workforce policy frameworks for humanoid deployment
- Sectors: policy, finance, labor
- Tools/products/workflows: risk models quantifying incident probability for contact-rich tasks; ergonomic benefit analysis (injury reduction for heavy lifting); guidelines for robot-human task allocation; auditing workflows for dataset provenance and safety validation
- Assumptions/dependencies: standardized incident reporting for robots; agreement on acceptable risk thresholds; clarity on labor impacts and retraining programs; privacy standards for MoCap and on-site video
- Hospital-grade certified humanoid logistics
- Sectors: healthcare, policy
- Tools/products/workflows: IEC/ISO-compliant safety certification for loco-manipulation; sterile-safe materials and cleaning workflows; redundancies (force/skin sensors) for contact monitoring; automated compliance logs
- Assumptions/dependencies: rigorous validation across scenarios (wet floors, narrow corridors); standardized test suites; regulator acceptance of sim-to-real evidence; clear SOPs for caregivers
- Extended contact-rich skill catalog (non-planar tasks like stairs, ladders, vehicle loading)
- Sectors: construction, logistics, emergency response
- Tools/products/workflows: residual modules for multi-contact stability (feet, torso, arms) under complex geometries; generalized point-cloud reward for non-convex objects; terrain-aware perception and footstep planning
- Assumptions/dependencies: expanded motion datasets including non-planar movements; improved locomotion priors; advanced fall recovery; high-fidelity simulation of edge cases
- Standardized academic benchmarks for whole-body loco-manipulation
- Sectors: academia
- Tools/products/workflows: publicly available task suites (kneel-lift, back-carry, irregular-object lift) with simulation configs; evaluation metrics (E_o, E_m, E_j, SR) as a community standard; leaderboards with sim-to-sim and sim-to-real protocols
- Assumptions/dependencies: sustained maintenance of datasets/tooling; community buy-in; reproducibility across hardware
- Residual learning extensions to other platforms (mobile manipulators, exoskeletons)
- Sectors: robotics, assistive tech
- Tools/products/workflows: GMT-like priors for human-exoskeleton control; residuals for task-specific load sharing; contact-aware lifting assistance; rehab workflows with clinician supervision
- Assumptions/dependencies: safe torque limits; accurate human-robot intent alignment; medical device certification; robust sensing of human joint states
Notes on Cross-Cutting Assumptions and Dependencies
- Perception: While the paper demonstrates blind and MoCap-assisted deployments, robust perception (RGB-D/LiDAR, pose trackers) is pivotal for fully autonomous object-aware control.
- Retargeting quality: Kinematic retargeting (e.g., GMR) must minimize penetrations/floating contacts; residual learning plus contact rewards helps, but upstream data quality remains critical.
- Safety and compliance: Contact-rich manipulation requires strict thresholds, early termination, and human-aware policies; sector-specific standards (IEC/ISO) will govern deployment.
- Hardware: Capability of the humanoid (DoF, payload, torque, force sensing, compliance) constrains feasible tasks; whole-body contact can offset wrist limits but demands careful balance control.
- Compute and simulation: IsaacGym-scale training and MuJoCo validation are valuable; sim-to-real success depends on domain randomization and physics fidelity.
- Data governance: Use of human MoCap/object trajectories entails privacy, consent, and licensing considerations; sharing motion datasets requires clear terms.
- Workforce integration: Pilots should include job design, training, and ergonomics analyses to complement automation with human oversight.
Glossary
- Contact reward: A reward term that incentivizes correct physical contacts between the robot’s body and objects during manipulation. "The contact reward provides explicit guidance on leveraging whole-body strategies."
- Curriculum-based virtual object controller: A staged assistance mechanism that applies decreasing virtual forces/torques to stabilize objects early in training and fade out later. "a curriculum-based virtual object controller to stabilize early training."
- Domain randomization: Training-time randomization of dynamics and observations to improve robustness and transfer to new environments. "we further apply domain randomization during training."
- Early termination: An RL mechanism that ends episodes when invalid or unsafe states occur to prevent learning degenerate behaviors. "early termination ends an episode if a body part makes unintended ground contact or deviates substantially from the reference"
- Embodiment gap: Mismatch between human demonstrations and robot morphology/physics that makes direct imitation unreliable. "introduces significant embodiment gap: contact locations and relative object pose in human demonstrations often fail to translate"
- Fine-tuning: Continuing training from a pre-trained model on a downstream task, potentially sacrificing generality if not done carefully. "fine-tuning tends to overwrite the generalization capability of the GMT policy"
- Foundation models: Large-scale pre-trained models whose representations can be adapted for downstream tasks. "breakthroughs in foundation models have demonstrated the power of pre-training on large-scale data followed by post-training."
- General Motion Retargeting (GMR): A kinematic mapping method to transfer human motion to a robot’s joint space. "The human motion is retargeted to the humanoid robot using GMR"
- General Motion Tracking (GMT): Policies that replicate diverse human motions on humanoid robots without task-specific object awareness. "general motion tracking (GMT) policies"
- Goal-conditioned RL: Reinforcement learning where policies are conditioned on explicit task or trajectory goals. "We formulate our whole-body loco-manipulation task as a goal-conditioned RL problem"
- IsaacGym: A massively parallel GPU-based physics simulator for fast RL training. "All policies are trained in IsaacGym"
- Kinematics-based motion retargeting: Transferring motion by matching kinematic poses/joints, ignoring dynamics. "we apply kinematics-based motion retargeting (e.g. GMR)"
- Loco-manipulation: Coordinated whole-body control that combines locomotion and manipulation. "Humanoid whole-body loco-manipulation promises transformative capabilities for daily service and warehouse tasks."
- Markov Decision Process (MDP): A formalism for sequential decision-making with states, actions, transitions, and rewards. "within a Markov Decision Process (MDP)"
- MoCap (Motion Capture): Systems that record precise motion trajectories of humans and objects. "We obtain reference trajectories using a MoCap system"
- MuJoCo: A high-fidelity physics simulator often used for evaluation and transfer studies. "we perform sim-to-sim transfer into MuJoCo"
- Object tracking reward: A reward term that encourages the manipulated object to follow a target trajectory. "the object tracking reward ro_t, which encourages task completion"
- PD controller: Proportional-derivative controller mapping target joint commands to torques for tracking. "which are executed on the robot through a PD controller."
- Point cloud: A set of 3D points sampled from an object’s surface used for geometric comparisons. "compute the point-cloud difference between the current and reference states"
- PPO: Proximal Policy Optimization, a policy-gradient RL algorithm for stable on-policy learning. "Both stages are trained using PPO"
- Privileged information: Simulation-only observations or signals not available at deployment time. "without access to privileged information."
- Proprioception: Internal sensing of the robot’s own state (e.g., joint angles/velocities, base pose). "Given robot proprioception sr_t and reference motion "
- Residual learning: Learning corrective outputs added to a base policy/controller to adapt behavior to new tasks. "a two-stage residual learning framework"
- Residual policy: The learned module that outputs additive corrections to a base policy’s actions. "we introduce a residual policy $\pi_{\text{Res}$ to refine the coarse actions predicted by the base policy"
- Sim-to-real transfer: Bridging performance from simulation to the physical robot. "To improve training efficiency and sim-to-real transfer, we propose"
- Sim-to-sim transfer: Evaluating policies by moving from one simulator to another to test robustness. "we perform sim-to-sim transfer into MuJoCo"
- Teleoperation: Human-operated control of a robot, often used for data collection or demonstration. "Recent work has demonstrated promising results by leveraging teleoperation"
- Virtual object controller: A controller that applies virtual forces/torques to guide an object toward its reference during training. "we introduce a virtual object controller curriculum that stabilizes training by driving the object toward its reference trajectory."
- Xavier uniform initialization: A weight initialization scheme designed to stabilize signal variance in deep networks. "using Xavier uniform initialization with a small gain factor"
Collections
Sign up for free to add this paper to one or more collections.