Self-Distilled Policy Gradient
Abstract: On-policy self-distillation, where a LLM conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning. Actually, it can be instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss. We therefore propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, as well as reference-policy KL regularization. Empirically, SDPG improves stability and performance over RLVR and self-distillation baselines. The code is available at https://github.com/lauyikfung/SDPG.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Self-Distilled Policy Gradient” in simple terms
What is this paper about? (Overview)
This paper is about teaching a LLM (like a smart chatbot) to solve tough reasoning problems (such as math) more reliably. It mixes two ideas:
- Learning from a clear, simple checker that says “right” or “wrong” at the end of an answer.
- Learning step by step from itself, as if one copy of the model can secretly peek at hints and teach another copy that can’t.
The method is called SDPG (Self-Distilled Policy Gradient). It makes training steadier and helps the model improve faster on math benchmarks.
What questions does the paper try to answer? (Objectives)
In plain terms, the paper asks:
- How can we give the model better guidance at every step of its reasoning, not just a final “pass/fail”?
- Can we avoid using a huge, separate teacher model and instead let the model teach itself with extra context?
- How do we keep training stable so the model learns faster without getting confused or “collapsing” to bad habits?
How does it work? (Methods, with simple analogies)
Think of two twins doing homework:
- Student twin: solves the problem normally, without hints.
- Teacher twin: is the same person but is allowed to peek at the answer and a solution outline (the “privileged context”).
Now, how do they train?
- Two kinds of feedback
- Verifier (like an automatic answer checker): It only says “correct” (1) or “incorrect” (0) for the whole solution.
- Teacher guidance: At every step, the teacher twin whispers “these next words are more likely to lead to a good solution,” based on the hints it can see.
- Learning from your own paths (on-policy)
- The student writes several solutions for the same problem.
- The model learns from the exact steps it actually took, not from some other model’s steps. This reduces mismatch between training and how it will be used later.
- Full-vocabulary self-distillation (dense, step-by-step guidance)
- At every position in the solution, the student has a probability list over all next possible words.
- The teacher (same model, but with hints) has its own probability list.
- The student tries to make its list closer to the teacher’s list. This closeness is measured by KL divergence (think “how different are two guess lists?”). They use a particular direction called “reverse KL,” but the idea is simply: make the student’s guesses more like the teacher’s.
- Only listen to the teacher when you’re on the right track (gating)
- If the verifier says a student’s attempt is worse than the group’s average, the model ignores the teacher’s whispers for that attempt. This avoids copying “locally nice-sounding” steps on an overall wrong path.
- Don’t overdo the teacher’s voice (scheduling)
- Early on, the teacher’s influence starts small and grows (“warmup”), so it doesn’t overwhelm exploration.
- Near the end, the teacher’s influence shrinks (“decay”), so the student can stand on its own without relying on hidden hints.
- Stay near a safe reference style (regularization)
- The model also stays close to a fixed “reference” model so it doesn’t drift too far or develop strange habits. You can think of this like a seatbelt that prevents wild changes in behavior. The paper explores two versions of this safety term.
In short:
- SDPG = outcome learning (final checker) + full, token-by-token self-distillation (teacher with hints) + a safety belt (stay near a reference model), with smart controls (gating + schedule) to keep training stable.
What did they find? (Main results and why they matter)
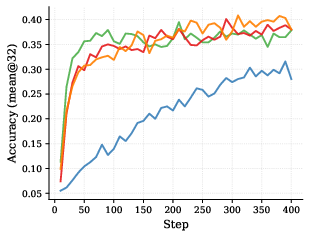
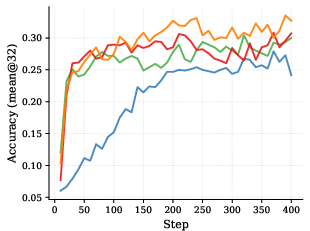
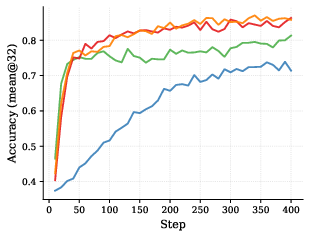
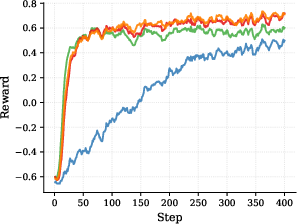
On tough math benchmarks (AIME 2024/2025 and AMC 2023), SDPG:
- Reaches higher accuracy than strong baselines that use only the checker (GRPO) or only self-distillation (RLSD).
- Learns faster: it hits good-reward regions earlier during training.
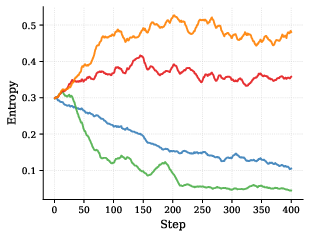
- Stays stable: it keeps higher “entropy” (meaning it continues exploring sensible word choices instead of collapsing to a narrow pattern). Models that collapse often stop improving or become repetitive.
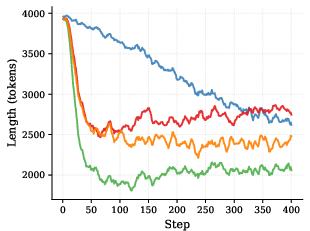
- Produces solutions of reasonable length (not too short or overly long), which is good for clear reasoning.
Why this matters:
- The model gets detailed, step-by-step guidance without needing a huge external teacher model, saving memory and cost.
- Training is smoother and less risky, so it can handle complex reasoning better.
What does this mean going forward? (Impact and implications)
- Better reasoning models with fewer expensive labels: The verifier needs only a final answer to check, not human-written step-by-step grades.
- Less hardware needed: The teacher is just the same model with extra hints, so no massive teacher model is required.
- General idea applies beyond math: Any task with a trusted checker (code tests, logic puzzles, data transformations) could benefit.
- Safer, steadier training: The “gate,” “schedule,” and “seatbelt” keep the model from going off track or overfitting to hidden hints.
In everyday words: SDPG teaches a model to think more clearly by letting it learn from a smarter version of itself that can peek at hints—while also making sure it doesn’t copy bad habits, doesn’t rely on hints forever, and doesn’t wander too far from safe behavior.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is framed to suggest actionable directions for future work.
- Theory: No convergence guarantees or sample-complexity analysis for SDPG’s combined objective (outcome PG + OPD + reference KL) under realistic assumptions.
- OPD gradient identity: Conditions beyond “q_t(a)>0 whenever p_t(a)>0” are not analyzed (e.g., numerical stability, smoothing); no bounds on bias/variance when approximating gradients vs exact full-vocabulary KL.
- Divergence choices: Lack of principled guidance on when reverse-vs-forward KL is preferable for OPD; no comparison to other f-divergences (JS, α-divergences) or temperature-scaled KL for improved stability.
- Unnormalized KL (UKL): No formal analysis of bias, convergence properties, or stability vs normalized KL in the on-policy setting; unclear when UFKL vs URKL is preferable.
- Reference policy: Criteria for choosing the reference model, its strength/staleness, and update strategy (fixed vs periodically refreshed) are not studied; no sensitivity analysis of α to avoid over-anchoring or under-regularization.
- Gating granularity: OPD is gated at the sequence level via binary m_i; no exploration of soft/continuous gating (e.g., weighting by advantage magnitude) or token-level gating to avoid discarding informative partial-credit tokens.
- Noisy/misleading privileged context: Robustness to incorrect or low-quality privileged signals (e.g., wrong solution paths) is untested; no teacher-signal calibration (confidence weighting, temperature, filtering) or verifier–teacher consistency checks.
- Mutual-information gap: The paper notes an irreducible I(Y_t; C | X, Y_<t) but does not quantify it or adapt β to data-driven MI estimates; no diagnostics for residual reliance on privileged-only information.
- Early-stage instability: While β warmup is used, there is no principled schedule selection or adaptive controller (e.g., based on reward/entropy/MI signals) to prevent premature over-constraining by OPD.
- Late-stage over-constraint: β decay is heuristic; no criteria for when to phase out distillation or for conflict detection between OPD and outcome signals.
- Exploration: Entropy preservation is observed empirically but not systematically studied; no comparison to explicit entropy bonuses or temperature schedules; no exploration metrics beyond entropy.
- Value baselines: The approach forgoes PPO-style clipping and value baselines; no comparison against value-critic methods (e.g., VinePPO) for variance reduction and improved credit assignment.
- Group-relative design: Sensitivity to group size G and to ε_std is not reported; effects on variance, learning stability, and gating activation remain unclear.
- Verifier dependence: Only binary, sequence-level verifiers are considered; no experiments with graded outcome rewards, process reward models, or step-level checkers to mitigate credit-assignment errors.
- Failure cases: If all group rewards are identical, OPD is fully gated off; no mechanism (e.g., curriculum sampling, difficulty adaptation) to ensure the distillation signal activates early enough.
- Computational cost: Full-vocabulary OPD at every sampled prefix is expensive; no profiling or analysis of compute/memory overhead, nor study of approximations (top-k support, importance-sampled vocab, low-rank softmax).
- Scaling: Results are limited to Qwen3-4B (with brief mention of 1.7B in the appendix) and math datasets; no tests on larger models, longer contexts, or broader domains (code, scientific QA, multi-modal reasoning).
- Generalization: No evaluation on non-English, out-of-distribution reasoning tasks, or settings without reliable verifiers; robustness to domain shift is untested.
- Baselines: Comparisons exclude several strong RLVR variants (e.g., DAPO, GSPO, Dr.GRPO, VinePPO) on the main 4B experiments; limited visibility into where gains come from relative to the current SOTA.
- Ablations: The main text lacks systematic ablations for α, β_base, T_warm, T_decay, gating on/off, and OPD vs KL anchor contributions; no hyperparameter sensitivity or interaction studies.
- Statistical rigor: Variance across seeds, confidence intervals, and significance tests are not reported; stability and reproducibility remain uncertain.
- Teacher temperature and calibration: No study of temperature tuning or label smoothing for the privileged teacher to prevent overconfident targets and reduce KL-induced collapse.
- Conflict resolution: No mechanism to detect and resolve conflicts when OPD promotes tokens counter to verifier-driven gradients (beyond coarse sequence gating).
- Leveraging “wrong” rollouts: The method discards OPD on negative-advantage rollouts; does not explore using teacher signals for corrective guidance (e.g., counterfactual reweighting, hindsight shaping) to fix near-miss trajectories.
- Safety and capability balance: No measurement of effects on general language capabilities, safety, or honesty; potential trade-offs from strong distillation and KL anchoring are not assessed.
- Data provenance: Privileged context is generated by Gemini 2.5 Pro; risks of data leakage or benchmark contamination are not examined; reproducibility of privileged data is unclear.
Practical Applications
Below is a concise mapping from the paper’s SDPG framework (self-distilled policy gradient with full-vocabulary on-policy self-distillation, verifier-grounded outcome rewards, and reference-policy KL regularization with UKL variants) to practical, real-world applications. Each item highlights the sector, suggested tools/workflows/products, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Fine-tuning math reasoning models with automatic answer checkers
- Sector: education, edtech, scientific computing
- Tools/workflows/products: SDPG-based “verified reasoning” finetuning kit; problem sets with rule-based graders; privileged-context builder that injects answers/solutions for training; advantage gating and β-scheduler defaults; monitoring of entropy/response length to avoid collapse
- Assumptions/dependencies: reliable verifiers (exact-answer checkers); availability of correct answers/solution paths (from curated datasets or external LLMs); compute to run RL-style post-training
- Code generation models trained to pass unit tests (test-driven RLFT)
- Sector: software engineering, DevOps
- Tools/workflows/products: CI-integrated SDPG training loop; unit-test harness as binary verifier; privileged context that includes target behavior or reference implementation snippets; KL anchor to maintain coding style/guardrails
- Assumptions/dependencies: high-quality unit tests with good coverage; secure sandboxing for test execution; policy KL anchor tuned to avoid over-regularization
- SQL/query synthesis and data wrangling with result verifiers
- Sector: data/analytics, BI, enterprise software
- Tools/workflows/products: database sandbox with gold result tables; SDPG finetuning that gates distillation on queries that pass verification; “Verified SQL assistant” productization
- Assumptions/dependencies: deterministic verifiers via test tables; careful dataset construction to avoid leakage of evaluation data; representative workloads
- Spreadsheet formula and transformation assistants verified on sample rows
- Sector: productivity tools, office software
- Tools/workflows/products: sample-row-based validators; privileged-context generator providing correct outputs or hints during training; lightweight SDPG pipeline that runs on mid-size models
- Assumptions/dependencies: representative sample rows; coverage and precision of validation rules; privacy constraints around user data
- Formal-math microdomains with proof checkers
- Sector: formal methods, education
- Tools/workflows/products: Lean/Coq/Isabelle proof checkers as verifiers; privileged training contexts that include known proofs/lemmas; SDPG to internalize proof tactics while anchoring to a reference policy
- Assumptions/dependencies: availability of machine-checkable goals and proofs; stable tokenization/formatting for proof languages
- Safer enterprise post-training with policy anchoring
- Sector: enterprise AI, platform teams
- Tools/workflows/products: URKL/UFKL anchoring to a trusted reference policy to maintain style, safety, and tone while learning new capabilities; “Policy-anchor finetuning” service
- Assumptions/dependencies: strong baseline/reference policy; correct selection of unnormalized KL variant and strength; governance on domain drift
- Reduced-cost post-training without external teachers
- Sector: ML infrastructure, startups, SMEs
- Tools/workflows/products: single-model self-distillation with privileged prompts (answers/solutions) instead of a larger external teacher; memory-efficient RLFT stacks (FSDP, vLLM)
- Assumptions/dependencies: quality privileged contexts; careful schedule/gating to avoid mode collapse; reproducible training infra
- Automated grading and step-by-step feedback generation
- Sector: education, assessment platforms
- Tools/workflows/products: SDPG to train models to generate verified solution steps and final answers; teacher prompts that inject solutions for training but not deployment; dashboards that track pass@k and verifier-aligned rubric metrics
- Assumptions/dependencies: reliable answer keys/verifiers; rubric design for partial credit (if used); mitigation to prevent revealing privileged info in outputs
- Verified planning for puzzles and logic games
- Sector: gaming, edtech
- Tools/workflows/products: environment simulators/verifiers (puzzle solved/unsolved); self-distilled teacher with privileged hints; gating to prevent imitation on failed rollouts
- Assumptions/dependencies: faithful simulators and reward definitions; careful selection of privileged hints that generalize
- Research tooling for credit assignment studies in LLMs
- Sector: academia, AI labs
- Tools/workflows/products: SDPG implementations to study token-level advantages and stability; ablation frameworks for gates/schedulers/UKL variants
- Assumptions/dependencies: experimental compute; availability of well-defined verifiers to isolate effects
Long-Term Applications
- Clinical decision support trained with guideline/constraint verifiers
- Sector: healthcare
- Tools/workflows/products: rule/checklist engines as verifiers (e.g., dosage bounds, contraindications); privileged contexts comprising gold-standard rationales; anchored SDPG to preserve safety profile
- Assumptions/dependencies: extremely reliable verifiers; rigorous evaluation and regulatory approval; privacy/PHI constraints; risk management for distribution shift
- Legal and compliance drafting with formalized rule verifiers
- Sector: legal tech, compliance, governance
- Tools/workflows/products: rule-based compliance checkers (policy conformity, clause presence/format); privileged contexts with expert-crafted exemplars; anchoring to corporate style guides
- Assumptions/dependencies: codification of complex legal rules into verifiers; accountability frameworks; updates with changing regulations
- Financial report and model generation with constraint checking
- Sector: finance, accounting
- Tools/workflows/products: arithmetic/consistency/veracity checks (e.g., cross-sheet reconciliation); privileged rationales for training; KL-anchored style and risk controls
- Assumptions/dependencies: high-fidelity verifiers; auditability; robust data lineage; strict governance
- Robotics and embodied planning with simulator verifiers
- Sector: robotics, logistics, manufacturing
- Tools/workflows/products: physics/simulator-based binary success checks; privileged contexts providing global maps or future states during training; deployment without privileged sensors
- Assumptions/dependencies: sim-to-real transfer; bridging text-token policy updates to control policies; multimodal integration
- Safety-critical code synthesis with formal verification
- Sector: avionics/auto/medical software, cybersecurity
- Tools/workflows/products: model checking and proof-based verifiers as rewards; privileged training contexts with specifications and correct implementations; strong KL anchors for safety invariants
- Assumptions/dependencies: scalable formal verification; coverage of properties; long training cycles and certification requirements
- Scientific workflow planning with simulation-backed verifiers
- Sector: R&D, materials science, drug discovery
- Tools/workflows/products: simulation pipelines (e.g., docking, CFD, DFT) providing binary success/failure; privileged contexts with “oracle” findings in training; SDPG to internalize strategies while maintaining exploration
- Assumptions/dependencies: accurate, efficient simulators; budget for compute; robust dataset curation
- Knowledge-grounded QA with retriever/validator combinations
- Sector: search, enterprise knowledge management
- Tools/workflows/products: retrieval-augmented verifiers (source match, citation integrity); privileged training with gold passages and answers; gate distillation only when citations pass automated checks
- Assumptions/dependencies: high-precision validation; defenses against hallucinations; content licensing
- Multi-agent systems and operations research with solver feedback
- Sector: logistics, supply chain, energy markets
- Tools/workflows/products: ILP/LP/MIP solvers as verifiers; privileged contexts with near-optimal or optimal solutions at training; anchored policies that generalize to new constraints
- Assumptions/dependencies: solver availability and speed; encoding real constraints; evaluation at realistic scales
- Digital agents that call verified APIs and tools
- Sector: productivity, enterprise automation
- Tools/workflows/products: task verifiers based on API response schemas and expected outcomes; privileged contexts with ground-truth workflows during training; SDPG to learn robust multi-step plans
- Assumptions/dependencies: comprehensive tool schemas and checkers; secure sandboxes; drift monitoring across tool versions
- Energy grid planning and control with rule/event verifiers
- Sector: energy, utilities
- Tools/workflows/products: safety and constraint checks (e.g., N-1 security) as verifiers; privileged contexts with optimal redispatch plans in training; anchored policies for stability
- Assumptions/dependencies: detailed simulators; secure data access; regulatory oversight and testing
Notes on cross-cutting assumptions and dependencies
- Verifier availability and quality: SDPG depends on consistent, high-precision verifiers that align with end goals; weak or misaligned verifiers can mis-train policies.
- Privileged context generation: Requires access to high-quality gold answers/rationales or external models to synthesize them; must prevent leakage at inference time.
- Stability controls: Positive-advantage gating and warmup–decay of β are important to avoid mode collapse and over-constraining (especially when privileged signals are noisy early or overly prescriptive late).
- Compute and infrastructure: RL-style post-training needs nontrivial compute and orchestration (sampling, verifiers, KL anchors); memory benefits arise from avoiding a separate large teacher.
- Governance and safety: Anchoring to a reference policy helps preserve safety/branding/guardrails, but requires careful selection of anchor strength and monitoring for drift.
- Generalization limits: Distillation may internalize context-specific cues; curriculum design and dataset diversity matter.
- Legal/ethical constraints: Use of external LLMs for generating privileged data must satisfy licensing, privacy, and provenance requirements.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization in deep learning. "All experiments use the AdamW optimizer"
- Actor entropy: A measure of randomness in the policy’s action distribution; higher values indicate more exploration. "SDPG-UFKL maintains substantially higher actor entropy throughout training"
- bfloat16 mixed precision: A reduced-precision floating-point format used to speed up training and reduce memory without large accuracy loss. "We use FSDP with bfloat16 mixed precision"
- Binary verifier rewards: A reward signal that is 1 for a correct final answer and 0 otherwise, provided by an automatic checker. "Obtain binary verifier rewards"
- Centered log teacher/student ratio: A token-level advantage signal formed by centering the log ratio between student and teacher probabilities. "centered log teacher/student ratio"
- Clipped importance ratio: Limiting the magnitude of the importance-sampling ratio to stabilize policy updates. "incorporates self-distillation in the clipped importance ratio of GRPO loss function"
- Clipped surrogate objective: A PPO-inspired objective that clips policy updates to prevent excessively large changes. "The policy is then optimized using a PPO-style ... clipped surrogate objective:"
- Conditional mutual-information gap: The residual information between outputs and privileged context given the observable state, indicating irreducible teacher–student differences. "an irreducible conditional mutual-information gap"
- Detached-sampling policy-gradient surrogate: A gradient estimator that samples from a distribution treated with stop-gradient to avoid backpropagating through it. "detached-sampling policy-gradient surrogate"
- FSDP (Fully Sharded Data Parallel): A parallel training technique that shards model parameters across devices to scale large models efficiently. "We use FSDP with bfloat16 mixed precision"
- Full-vocabulary OPD: Distillation that matches the entire next-token probability distribution (not just sampled tokens) under on-policy prefixes. "exact full-vocabulary OPD"
- Group Relative Policy Optimization (GRPO): An RL algorithm that uses group-normalized, sequence-level advantages and PPO-style updates for verifier-based rewards. "Group Relative Policy Optimization (GRPO)"
- Importance ratio: The ratio between current and behavior policy probabilities for an action, used for off-policy correction. "where r_{i,t} is the importance ratio defined as follows:"
- Importance sampling ratio: The same quantity emphasized as an estimator for reweighting sampled data under distribution shift. "is the importance sampling ratio."
- KL divergence (Kullback–Leibler divergence): A measure of dissimilarity between probability distributions used for distillation and regularization. "Normalized Kullback-Leibler (KL) divergence"
- Mass correction term: An additive term in UKL that adjusts for unnormalized distributions’ total mass differences. "UKL introduces a mass correction term"
- Mode collapse: A failure mode where the model produces low-diversity outputs by collapsing to a few modes. "a known signature of mode collapse in pure self-distillation"
- On-policy self-distillation: Using the same model as student and teacher, with the teacher conditioned on extra information, evaluated on the student’s own rollouts. "On-policy self-distillation"
- Positive-advantage gating: Enabling distillation updates only on trajectories with positive verifier-based advantage to avoid reinforcing bad rollouts. "positive-advantage gating"
- Privileged context: Additional information (e.g., solutions, hints) available to the teacher during training but not at deployment. "conditions on privileged context to supervise its own generations"
- Privileged teacher: The teacher distribution induced by conditioning the same model on privileged context. "the privileged teacher can still assign high probability"
- Proximal Policy Optimization (PPO): A policy gradient method that constrains updates via clipping to ensure stable learning. "PPO-style ... clipped surrogate objective"
- Reference policy: A fixed policy used as an anchor via KL regularization to stabilize updates and prevent drift. "a fixed reference policy"
- Reference-policy anchor: The stabilizing effect of constraining the learned policy toward a fixed reference. "but without a reference-policy anchor."
- Reference-policy KL regularization: A penalty encouraging the current policy to stay close to a fixed reference policy. "reference-policy KL regularization"
- Reinforcement Learning with Verifiable Rewards (RLVR): An approach that uses automatic verifiers rather than human preferences to reward correct outcomes. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reverse KL: The KL divergence D_KL(p||q) in the student-to-teacher direction, often sharper and mode-seeking. "student-to-teacher reverse KL"
- Rollout policy: The (often frozen) behavior policy used to sample trajectories for training. "a frozen rollout policy"
- Sequence-level advantage: A scalar advantage applied uniformly across all tokens in a generated sequence. "sequence-level advantage"
- Stop-gradient operator: An operator that prevents gradients from flowing through a variable during backpropagation. "where SG is the stop-gradient operator."
- Trust regions: Constraints that limit policy updates within a neighborhood to maintain stability. "incorporates trust regions in distillation."
- Unnormalized KL (UKL) divergence: A KL variant defined for unnormalized distributions, including a mass correction term. "we employ the Unnormalized KL (UKL) divergence"
- Unnormalized forward KL regularization: Using UKL with the forward direction as a regularizer to a reference policy. "the objective using unnormalized forward KL regularization"
- Unnormalized reverse KL regularization: Using UKL with the reverse direction as a regularizer to a reference policy. "we can also apply the unnormalized reverse KL regularization"
- Verifier: A rule-based component that checks final answers and assigns outcome rewards. "A rule-based verifier assigns a scalar reward"
- Warmup–decay schedule: A schedule that increases a coefficient early and decreases it later to balance stability and flexibility. "a warmup-decay schedule"
Collections
Sign up for free to add this paper to one or more collections.

