Reinforcement Learning via Self-Distillation
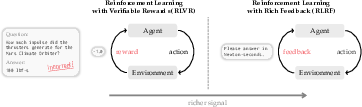
Abstract: LLMs are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train LLMs, especially for tasks where answers can be checked automatically—like coding problems or math questions. The method is called Self-Distillation Policy Optimization (SDPO). It helps the model learn not just from a simple “right/wrong” score, but also from detailed feedback (like error messages). SDPO uses the model itself as a “teacher” that looks back at its own mistakes and guides its improvements.
What problem is the paper trying to solve?
Many training methods for LLMs use Reinforcement Learning (RL). In RL with verifiable rewards (RLVR), the model tries an answer and gets a reward (often just 1 or 0 for pass/fail). This creates a big problem: credit assignment. That means it’s hard to figure out which exact parts of the answer were good or bad, because the model only knows the final outcome. If the reward is just “fail,” it doesn’t say where things went wrong.
But in many real tasks—like coding—we get rich feedback: runtime errors, failed unit tests, or judge comments. These explain what went wrong. The paper asks: How can we use this rich feedback to teach the model better, without needing a stronger external teacher model?
How does SDPO work? (Methods explained simply)
Think of the model like a student doing homework:
- The student tries to solve a problem and submits an answer.
- The environment (like a code runner) gives feedback: “Error: division by zero on line 73.”
- Now, instead of asking a stronger teacher, the student becomes its own teacher. It reads the feedback and re-evaluates its original answer with that context.
Here’s the key idea:
- The same model is used in two roles:
- Student: writes the original answer.
- Self-teacher: re-reads the problem plus the feedback and judges the student’s answer token-by-token (word-by-word).
- The self-teacher gives a dense learning signal: it can agree or disagree with the student’s choices at each token, not just the final score. This turns feedback into detailed guidance.
- The model then “distills” (copies) what the self-teacher believes should happen next into the student policy. That’s why it’s called self-distillation.
In practice:
- SDPO samples several answers to a question.
- It collects feedback for each answer.
- It runs the model again, but this time with the feedback included, to compute how likely each next token should be.
- It adjusts the student to match the self-teacher’s token-by-token preferences.
Analogy: It’s like grading your own essay after reading the teacher’s notes, then rewriting the essay while paying attention to specific words and sentences the notes flagged.
To keep training efficient:
- SDPO focuses on the top likely next tokens (“top-K”) instead of every possible token to save memory and time.
- It uses small stability tricks (like averaging parameters over time) so the self-teacher stays helpful and doesn’t drift too fast.
What did the researchers test?
They ran SDPO in three kinds of situations:
- Tasks without rich feedback (only pass/fail), like science Q&A and tool-use tasks. SDPO cleverly uses successful answers in the same batch as “implicit feedback” to help failed answers improve.
- Tasks with rich feedback, especially coding (LiveCodeBench v6), where the environment gives error messages and test results.
- Test-time training on very hard coding problems: using SDPO on a single test question to speed up discovery of a working solution.
Main findings and why they matter
Here are the most important results:
- Better accuracy in coding with feedback:
- On LiveCodeBench v6, SDPO reached 48.8% accuracy versus 41.2% for a strong baseline method (GRPO).
- SDPO achieved the baseline’s final accuracy with about 4× fewer generations (faster learning).
- Works even when feedback is limited:
- On science reasoning and tool-use tasks with only pass/fail rewards, SDPO still outperformed GRPO on aggregate (68.8% vs. 64.1%).
- It does this by using successful answers in the same batch as “implicit feedback” for failed ones.
- More concise reasoning:
- SDPO’s answers were often 3× to 7× shorter than GRPO’s while being more accurate.
- This suggests SDPO learns to focus on truly useful steps, rather than verbose or repetitive “thinking,” which saves time and makes outputs clearer.
- Scales with model strength:
- The benefits of SDPO increase with larger, stronger models (better in-context learners).
- On smaller models, SDPO’s advantage shrinks and can even reverse, meaning the self-teacher needs to be good enough to provide reliable guidance.
- Faster discovery at test time:
- For very hard problems where the base model almost never finds a solution, SDPO can boost the chance of discovering a correct answer using about 3× fewer attempts compared to methods like best-of-k sampling or multi-turn dialogues.
- This makes SDPO useful not just during training, but also when tackling tough new tasks.
Why this matters:
- Turning detailed feedback (like error messages) into precise learning signals helps models improve faster and with fewer tries.
- Not needing an external teacher makes the approach more practical: you don’t need a bigger, better model to guide learning.
- Shorter, clearer answers mean faster inference and potentially lower costs.
Implications and potential impact
- Smarter training from everyday feedback: Many real-world systems include rich feedback—logs, errors, or judge notes. SDPO shows how to convert that into effective learning without human labeling or stronger teacher models.
- Better coding agents and problem solvers: Because coding provides clear feedback, SDPO can help build more capable, efficient code-generation models.
- Efficient reasoning at scale: Learning to be concise without losing accuracy could reduce computation costs for large deployments.
- Stronger test-time adaptation: SDPO can help models specialize to tough, one-off questions on the fly, improving reliability in high-stakes settings.
In short, SDPO teaches models to learn from their own mistakes using the feedback they already get, leading to faster, clearer, and more reliable improvements—especially in tasks where we can verify correctness and get informative error signals.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps and open questions that the paper leaves unresolved. Each item highlights an area where further research could be immediately actionable.
- Objective/theory: Lack of a formal objective for SDPO beyond minimizing a distillation divergence and no convergence or improvement guarantees linking SDPO updates to increases in expected task return; unclear conditions under which post hoc feedback–conditioned advantages yield policy-improvement guarantees.
- Use of future information: The self-teacher conditions on feedback that was unavailable at action time; the theoretical status of SDPO as a valid policy-gradient estimator (e.g., in an augmented MDP with extra state variables) is not formally established.
- Off-policy SDPO: While a PPO-style extension is mentioned, there is no empirical validation of off-policy SDPO, no ablation of clipped importance sampling, replay, or multi-step updates, and no comparison of stability/sample-efficiency to off-policy GRPO.
- Bootstrap under extreme sparsity: SDPO relies on successful rollouts within a group to serve as implicit feedback in RLVR; it is unclear how SDPO assigns credit when no successes occur (cold-start) and what curricula or heuristics are needed to escape all-fail regimes.
- Feedback quality robustness: No study of robustness to noisy, partial, or adversarial feedback (e.g., incorrect unit tests, misleading LLM-judge critiques); mechanisms for detecting, weighting, or denoising unreliable feedback are not provided.
- Small-model regime: SDPO underperforms GRPO on weaker models (e.g., Qwen2.5-1.5B); the threshold at which SDPO becomes beneficial, and strategies to make SDPO effective for small models (auxiliary losses, teacher warming, better prompts), are open.
- Exploration vs. mode collapse: Self-distillation may reduce exploration by pushing the student toward its own hindsight distribution; the impact on diversity, premature convergence, and long-horizon discovery remains unquantified and unmitigated.
- Diversity and pass@k: The effect of SDPO on sampling diversity and best-of-k metrics is not evaluated; using successful group rollouts as feedback may encourage homogenization and reduce coverage of the solution space.
- Conciseness trade-offs: SDPO yields markedly shorter responses; whether this harms tasks that benefit from longer chain-of-thought or multi-step deliberation is not studied, nor are mechanisms to control length-performance trade-offs.
- Granularity vs. compute: Top-K logit distillation is used to limit memory, but there is no systematic analysis of K’s effect on performance, stability, bias, and compute; the accuracy-compute frontier of logit- vs. token- vs. sequence-level credit assignment is not characterized.
- Prompt/template sensitivity: The method depends on a specific teacher prompt that interleaves the original attempt, environment feedback, and a successful rollout; the sensitivity to prompt wording, ordering, and formatting is not ablated.
- Feedback component attribution: The relative benefit of different feedback components (e.g., runtime errors vs. failing test cases vs. successful examples) is not disentangled; guidelines for constructing effective feedback are absent.
- Multi-turn agentic settings: SDPO is not evaluated in multi-step tool use or long-horizon settings where feedback arrives after intermediate steps; how to propagate dense credit across steps and prevent inconsistent retro-corrections is open.
- Stability mechanisms: EMA and trust-region teacher regularization improve stability, but there is no principled analysis of why/when they work, how to set hyperparameters, and which failure modes they prevent (e.g., collapse, oscillation).
- Divergence choice and bias: JS vs. KL for distillation is chosen empirically; the optimization and calibration implications of this choice (and of top-K approximations) are not analyzed theoretically or across tasks.
- Compute profile at scale: Although per-step overhead is reported as small, a thorough FLOP, memory, and throughput analysis across batch sizes and larger models (e.g., 70B+) is missing; scaling limits and engineering bottlenecks are unclear.
- Breadth of evaluation: Experiments focus on SciKnowEval subsets, ToolAlpaca, and LCBv6; generality to other domains (math competitions, APPS, MBPP/HumanEval, multilingual tasks, reasoning benchmarks) remains to be demonstrated.
- Comparisons to alternative dense-signal methods: No head-to-head evaluations against token-level reward-model methods (e.g., learned token advantages), RLAIF/RM-driven RL, or on-/off-policy distillation from external teachers under matched budgets.
- Public/private test overfitting: While private tests are used for validation in coding, the risk of overfitting to public tests is not measured (e.g., by test-shift analyses or cross-benchmark validation).
- Ambiguity and solution multiplicity: SDPO may penalize alternative-but-correct solutions by pushing toward one successful trajectory; methods to accommodate sets of valid solutions or multi-modal target distributions are not explored.
- External teacher integration: Combining self-teaching with stronger external teachers (when available), and scheduling or weighting their contributions over training, is left unexplored.
- Bias and safety: Self-distillation can amplify pre-existing model biases or harmful patterns present in feedback; no bias, toxicity, or safety analysis is presented, nor mitigation strategies.
- Test-time self-distillation (TTT) side effects: The persistence of per-question specialization, its impact on subsequent tasks, and risks of overfitting or memorization at test-time are not examined.
- Formal RLRF link: While RLRF is defined informally, a precise MDP/POMDP formalization (states, observations, feedback channels, and optimality criteria) and the positioning of SDPO within it are not provided.
- Group size and decoding: The effect of rollout group size G, sampling temperature, and decoding strategies on SDPO’s performance and stability is not ablated; guidelines for exploration settings are missing.
- Early-stage curricula: Strategies (e.g., curriculum design, feedback shaping, synthetic hints) to help SDPO in early training when successes and useful feedback are rare are not addressed.
- Continual learning/forgetting: The impact of SDPO on retention of general instruction-following and unrelated capabilities is not measured; catastrophic forgetting risks and remedies (e.g., regularizers) are open.
- Privacy/security of feedback: Using raw environment logs or inputs as feedback may leak sensitive information; methods for feedback sanitization and privacy-preserving SDPO are not discussed.
Practical Applications
Overview
The paper introduces Self-Distillation Policy Optimization (SDPO), an on‑policy reinforcement learning method for LLMs that converts rich textual feedback (e.g., runtime errors, judge critiques, failing unit tests) into dense, token‑level credit assignment. SDPO leverages a “self‑teacher” (the same model conditioned on feedback) to provide logit‑level guidance, improving sample efficiency, final accuracy, and conciseness across code generation, scientific reasoning, tool use, and hard binary‑reward tasks. It can be implemented by swapping standard RLVR (e.g., GRPO) advantages with SDPO’s feedback‑conditioned advantages and incurs modest compute overhead.
Below are practical, real‑world applications derived from the paper’s findings, methods, and innovations.
Immediate Applications
The following applications are deployable now with existing models and infrastructure, especially in settings that provide verifiable or tokenized feedback.
- Software engineering and DevOps (software sector)
- SDPO‑enhanced code assistants in IDEs (e.g., VS Code, JetBrains) that use unit test failures, stack traces, and lint errors to self‑correct code with fewer attempts and shorter outputs.
- Potential tools/products: “Fix with SDPO” IDE extension; GitHub Action that runs unit tests and triggers SDPO updates on failing PRs; CI plugin that uses error logs as feedback.
- Assumptions/dependencies: Access to unit tests or reproducible failing cases; logging of runtime errors; sufficient base model in‑context reasoning; minimal infra to compute self‑teacher log‑probs (top‑K distillation).
- Continuous integration pipelines that learn from failing builds by distilling feedback (compilation errors, static analysis warnings) back into internal codegen policies, reducing flakiness and rework.
- Assumptions/dependencies: Reliable test suites; guardrails to prevent overfitting to public tests; teacher regularization (EMA/trust‑region) for stability.
- Data engineering and analytics (software/data sector)
- ETL/script generation agents that adapt to schema validation errors, DB constraint violations, and parser exceptions to improve data pipeline reliability.
- Potential tools/products: “SDPO‑aware” data workflow generator; Airflow/Prefect operator that re‑tries with self‑distilled fixes.
- Assumptions/dependencies: Structured error messages; access to validation feedback; safe rollback/retry mechanisms.
- Tool‑using AI agents in enterprise workflows (operations and RPA)
- Customer support/chatbots that learn from API/tool errors (HTTP status codes, malformed payloads, rate‑limit messages) to improve tool selection and call formatting with fewer retries.
- Potential tools/products: SDPO‑enabled tool orchestration middleware; error‑aware prompt templates for self‑teacher conditioning.
- Assumptions/dependencies: Tokenized, machine‑readable feedback from tools; robust logging/observability; base model capable of in‑context retrospection.
- LLM post‑training teams (MLOps/AI engineering)
- Swap GRPO advantages for SDPO’s logit‑level advantages in existing RLVR pipelines to get more dense credit assignment and better sample efficiency, even when only scalar rewards exist (use successful rollouts as implicit feedback).
- Potential tools/products: SDPO training library/head (extension to TRL/verl); PPO‑style off‑policy variant with clipped importance sampling.
- Assumptions/dependencies: Ability to re‑score original attempts under the feedback‑conditioned context; memory‑aware top‑K distillation; teacher regularization for stability.
- Test‑time specialization for hard tasks (software/education)
- Test‑Time Self‑Distillation (TTSD) to solve difficult coding/math problems with 3× fewer attempts than best‑of‑k sampling or multi‑turn conversations.
- Potential tools/products: “TTSD mode” in coding challenge platforms (e.g., LiveCodeBench, LeetCode) and math tutoring systems; workflow toggle for cost‑sensitive inference.
- Assumptions/dependencies: Availability of per‑question feedback (failing test cases, correctness checks); small budget for re‑scoring logits per attempt.
- Scientific and technical tutoring (education sector)
- Concise reasoning tutors that learn from auto‑grader feedback (chemistry/physics/biology questions, tool‑call requirements) to produce shorter, higher‑accuracy responses and avoid circular reasoning.
- Potential tools/products: SDPO‑powered homework helpers with error‑driven self‑correction; classroom auto‑grader integrations.
- Assumptions/dependencies: Verifiable questions with structured feedback; base model with sufficient scale (benefits increase with model size).
- Cost and latency optimization in production LLMs (software/business operations)
- Deploy SDPO‑trained models for reasoning tasks to reduce token usage and response length while maintaining or improving accuracy (observed 3–7× reductions in output length).
- Potential tools/products: A/B tests of “concise reasoning” models; inference policies that trigger TTSD on failure.
- Assumptions/dependencies: Task domains where conciseness doesn’t harm user comprehension; monitoring for hallucination and failure modes.
Long‑Term Applications
The following applications are promising but require further research, scaling, safety validation, or sector‑specific adaptation.
- Continual learning and self‑healing systems (software/DevOps)
- Autonomous code agents that continuously distill production errors (incident reports, canary failures, SLO violations) into policy updates and propose patches with human review.
- Potential tools/products: “Self‑healing SDPO” platform integrated with observability (logging/tracing) and change management.
- Assumptions/dependencies: Strong governance, audit trails, human‑in‑the‑loop; robust safety checks to prevent regressions; scalable model sizes (SDPO benefits grow with stronger models).
- Scientific discovery workflows (research/chemistry/materials/biology)
- SDPO‑enhanced agents that use simulation/verification feedback (e.g., docking scores, stability checks, theorem prover outputs) for dense credit assignment, accelerating hypothesis testing and optimization under binary or sparse outcomes.
- Potential tools/products: TTSD for hard search problems (e.g., pass@k < 3% tasks) in computational chemistry/materials discovery; integration with verifiers (proof assistants, simulators).
- Assumptions/dependencies: Tokenization of rich feedback from simulators/verifiers; domain‑specific safety and reproducibility; compute budgets for larger models.
- Robust tool‑use orchestration and agent ecosystems (software/AI platforms)
- Multi‑agent systems that share successful rollouts as implicit feedback, allowing failed agents to learn from peers; dense advantage signals at logit‑level improve tool selection and error recovery.
- Potential tools/products: SDPO‑native agent frameworks; shared feedback caches across services.
- Assumptions/dependencies: Standardized, tokenized feedback across tools; coordination protocols; safeguards against “teaching to the test.”
- High‑stakes sectors (healthcare, finance, energy) with verifiable constraints
- Claims coding, prior authorization, compliance form filling, and pre‑trade checks that leverage validator feedback (rejection reasons, regulatory constraints) for self‑distillation.
- Potential tools/products: SDPO‑enabled compliance assistants that learn from structured rejections; TTSD for rare, complex cases.
- Assumptions/dependencies: Rigorous validation, certification, and bias/safety assessments; policy/legal approval; robust guardrails and auditability before deployment.
- Robotics and embodied AI (robotics sector)
- Adapting SDPO to tokenized summaries of continuous feedback (safety violations, failure modes, simulator diagnostics) for dense credit assignment in action policies.
- Potential tools/products: “Textual feedback adapters” that convert continuous signals to structured tokens for SDPO; hybrid RL pipelines.
- Assumptions/dependencies: Reliable tokenization of rich feedback; mapping non‑text sensors to interpretable feedback; extensive safety testing.
- API and platform standards for rich feedback (policy/standards)
- Encourage machine‑readable, structured error and evaluation feedback in developer platforms (e.g., standardized JSON error schemas), enabling widespread adoption of RLRF/SDPO.
- Potential tools/products: Government/industry guidelines for RL‑friendly APIs; procurement requirements for verifiable feedback.
- Assumptions/dependencies: Multi‑stakeholder coordination; privacy/security considerations; avoiding leakage of private test cases; monitoring for overfitting.
- Open datasets and benchmarking for RLRF (academia/open‑source)
- Creation of public corpora and leaderboards where tasks include tokenized, high‑quality feedback (beyond scalar rewards), fostering methods like SDPO and fair evaluation of dense credit assignment.
- Potential tools/products: Expanded LiveCodeBench with standardized feedback types; RLRF benchmark suites across domains.
- Assumptions/dependencies: Community curation; reproducible environments; anti‑leakage protocols between public and private tests.
Cross‑cutting assumptions and dependencies
- Availability and quality of rich, tokenized feedback (environment/tool errors, judge critiques, validation failures).
- Base model scale and in‑context learning strength (SDPO’s gains increase with larger models; small models may underperform).
- Stability mechanisms (teacher regularization via EMA or trust‑region; Jensen‑Shannon loss; top‑K logit distillation to manage memory).
- Robust evaluation and safety (guard against overfitting to public tests; separate train/validation; audit trails; human oversight in high‑stakes domains).
- Infrastructure to recompute log‑probs under feedback‑conditioned contexts with modest compute overhead; MLOps integration for on‑policy updates and logging.
Glossary
- Advantage (policy gradient): A per-timestep signal indicating how good an action was relative to a baseline in policy gradient methods. Example: "estimate advantages from these sparse outcome rewards."
- Asymmetric clipping: A PPO-style modification that clips policy ratios asymmetrically to improve stability. Example: "such as asymmetric clipping"
- Best-of-k sampling: Generating k candidates and selecting the best according to a criterion. Example: "best-of- sampling"
- Biased normalization: A normalization procedure (e.g., of advantages) that introduces bias into estimates or updates. Example: "avoiding biased normalization"
- Binary reward: A reward that takes only two values, typically success/failure (1/0). Example: "binary-reward tasks"
- Clipped importance sampling: Importance sampling with clipped ratios to reduce variance and stabilize updates (as in PPO). Example: "PPO-style clipped importance sampling"
- Credit assignment: The problem of attributing overall outcomes to specific actions or tokens in a sequence. Example: "credit-assignment bottleneck"
- Dense credit assignment: Providing fine-grained, token/logit-level feedback instead of a single scalar per sequence. Example: "dense, logit-level credit assignment."
- Distillation loss: A loss that aligns a student model’s output distribution with a teacher’s. Example: "we adopt the symmetric Jensen-Shannon divergence for the distillation loss"
- Exponential moving average (EMA): A running average of parameters that emphasizes recent values to stabilize training. Example: "exponential moving average~(EMA) of the student parameters"
- Group Relative Policy Optimization (GRPO): A policy optimization method that uses group-relative rewards to compute advantages. Example: "Group Relative Policy Optimization~(GRPO)"
- In-context learning: A model’s ability to adapt behavior based on information provided in the prompt without parameter updates. Example: "in-context learning"
- Jensen–Shannon divergence: A symmetric measure of divergence between two probability distributions. Example: "symmetric Jensen-Shannon divergence"
- KL divergence: The Kullback–Leibler divergence measuring how one probability distribution diverges from another. Example: "We then use the KL-divergence"
- LiveCodeBench (LCB): A benchmark suite for code generation and competitive programming evaluation. Example: "LiveCodeBench v6"
- Logit (logit-level): The pre-softmax scores; logit-level refers to operations or supervision applied directly to logits. Example: "logit-level"
- Micro batch size: The number of samples processed per gradient accumulation step before an optimizer update. Example: "micro batch size of 2;"
- Off-policy: Learning from data generated by a different policy than the one currently being optimized. Example: "off-policy data"
- On-policy: Learning from data generated by the current policy being optimized. Example: "an on-policy algorithm"
- Pass@k: The probability that at least one of k sampled solutions succeeds (e.g., passes tests). Example: "pass@$64$"
- Policy gradient: A family of RL methods that directly optimize the expected return by differentiating through the policy. Example: "policy gradient algorithm"
- Proximal Policy Optimization (PPO): An RL algorithm stabilizing policy updates using clipped objectives or ratios. Example: "PPO's clipped importance weighting"
- Regularized self-teacher: A self-teaching mechanism stabilized via techniques like EMA or interpolation with an initial teacher. Example: "regularized self-teacher"
- Reinforcement Learning with Rich Feedback (RLRF): An RL setting where environments provide tokenized feedback beyond scalar rewards. Example: "Reinforcement Learning with Rich Feedback (RLRF)"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setting where outcomes are judged by verifiable scalar rewards (often binary). Example: "reinforcement learning with verifiable rewards (RLVR)"
- Rollout: A sampled attempt or trajectory produced by the policy in response to a prompt or state. Example: "sample rollouts from the current policy"
- Rollout group: A set of simultaneous attempts for the same prompt used to compute group-relative signals. Example: "a rollout group contains multiple simultaneous attempts"
- Sample efficiency: How much performance improves per unit of data or environment interaction. Example: "improves sample efficiency"
- Self-distillation: Training a model to learn from its own feedback-conditioned predictions as a teacher. Example: "RL via Self-Distillation"
- Self-teacher: The current model conditioned on feedback acting as a teacher to itself. Example: "as a self-teacher"
- Stopgrad operator: An operation that prevents gradients from flowing through part of the computation graph. Example: "the stopgrad operator blocks gradients"
- Test-Time Self-Distillation: Applying self-distillation during inference to specialize on a specific test instance. Example: "Test-Time Self-Distillation"
- Test-time training: Updating model parameters at inference time using the test instance and available signals. Example: "test-time training"
- Top-K distillation: Distilling using only the top-K logits (with a tail probability correction) to reduce memory. Example: "top- distillation"
- Trust-region: A constraint or regularization that limits how far updates or teacher distributions can deviate. Example: "trust-region and EMA teachers outperform"
- Unit tests (public/private): Tests used to verify code; public tests are available during training, private ones for validation. Example: "public and private unit tests"
- Verifiable environments: Domains where outputs can be automatically checked (e.g., via unit tests or judges). Example: "verifiable environments"
- Wall-clock training time: The real elapsed time spent training, as opposed to steps or samples. Example: "wall-clock training time"
Collections
Sign up for free to add this paper to one or more collections.

