- The paper demonstrates that skill-conditioned self-distillation efficiently assigns token-level credit, enhancing stability in multi-turn LLM agents.
- It interleaves GRPO-based RL with an auxiliary, importance-weighted self-distillation loss to enable dynamic co-evolution of student and teacher policies.
- Experimental results on AppWorld and Sokoban show significant gains, including a 14.0% accuracy improvement over vanilla methods.
Skill-SD: Skill-Conditioned Self-Distillation for Long-Horizon Multi-Turn LLM Agents
Skill-SD addresses the principal limitations of reinforcement learning (RL) applied to multi-turn LLM agents: sample inefficiency due to sparse rewards, high variance in long-horizon tasks, and instability in combining RL with self-distillation. Traditional approaches such as Group Relative Policy Optimization (GRPO) have shown competitive results but are bottlenecked by sparse, delayed reward feedback and the absence of token-level credit assignment. Existing on-policy self-distillation frameworks, including Self-Distilled Reasoner (SDR) and SDPO, rely on privileged ground truth available in single-turn or well-posed tasks (e.g., math proofs), but fail to scale to domains where diverse valid strategies exist and no canonical solution can condition a teacher.
Skill-SD proposes a self-distillation regime in which the agent's own successful (and failed) trajectories are summarized into compact, structured "skills"—task-local, natural language advice capturing success patterns, error analyses, and canonical workflows. These skills condition the teacher branch during training but do not leak into the student prompt used for policy deployment, enforcing a clean separation between augmented teacher supervision and student inference-time autonomy.
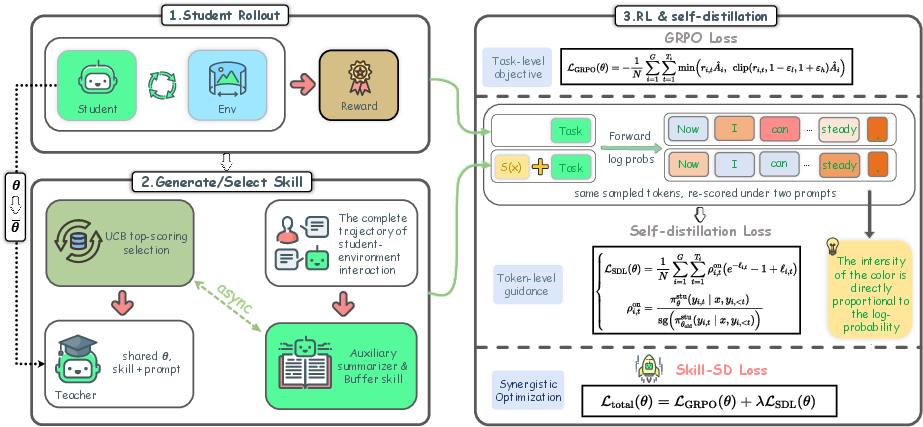
Figure 1: Skill-SD overview: (1) the student generates on-policy rollouts and receives task-level rewards; (2) completed trajectories are asynchronously summarized into compact skills and stored in a UCB-indexed buffer; (3) the same token sequence is re-scored under both the student prompt and skill-augmented teacher prompt, with GRPO and importance-weighted SDL loss applied.
Methodology: Teacher-Conditioned Self-Distillation with Skill Synthesis
The Skill-SD algorithm interleaves GRPO-based RL optimization with an auxiliary self-distillation loss (SDL) anchored on a skill-conditioned teacher. Trajectory execution proceeds as follows: the student generates on-policy rollouts, receiving dense, fine-grained rewards when applicable. Completed trajectories are asynchronously summarized by an auxiliary LLM into structured skills (success analysis, error analysis, golden workflow), which are accumulated in a per-task buffer with a UCB bandit criterion to balance exploitation of high-reward skills and exploration of less-visited ones.
At each optimization step, the student sequence is re-forwarded using: (a) the unmodified prompt (student branch); (b) the prompt augmented by the top-ranked skill for the task (teacher branch). The teacher prompt is updated dynamically by synchronizing teacher parameters from the latest student checkpoint, ensuring co-evolution of student and teacher distributions.
Crucially, the distillation loss is formulated as an importance-weighted reverse-KL, correcting for the distribution mismatch between student-sampled and teacher-augmented log-probabilities. This corrects the bias previously identified in gradient estimation of k3 KL estimators for RL, as shown in Tang & Munos [tang2025pitfalls], and guarantees per-token unbiased gradient updates. The on-policy importance ratio and trust-region mechanisms are decoupled, following the recommendations of DAPO and recent KL regularization literature [yu2025dapo, zhang2025rpg].
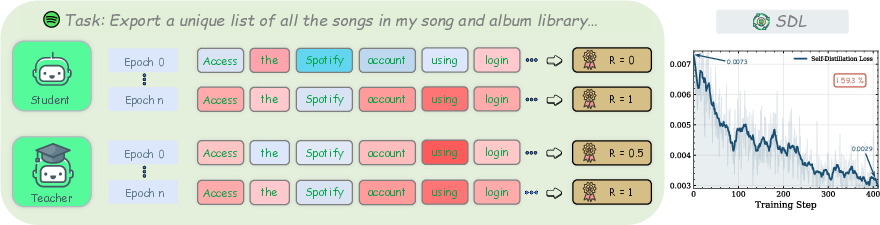
Figure 2: Token-level self-distillation dynamics on an AppWorld task; after convergence, student and teacher token distributions align and the SDL loss falls by 59.3\%.
Experimental Results: Agentic Benchmarking and Ablation
Evaluation is conducted on AppWorld (multi-app tool-use over APIs) and Sokoban (spatial planning with irreversible state transitions). The base model is Qwen3-4B-Instruct-2507, finetuned with Skill-SD and compared against vanilla GRPO, skill-augmented (student-prompted) GRPO, and vanilla on-policy distillation (OPD) without reward grounding.
Skill-SD advances the SOTA for small-model agents on both domains. On AppWorld, Skill-SD yields 64.9% accuracy and an 84.9% completion rate, outperforming vanilla GRPO by +14.0% accuracy. On Sokoban, Skill-SD reaches 62.5% accuracy, a +10.9% gain over GRPO. Skill-augmented GRPO (i.e., skills fed to the student prompt) underperforms vanilla GRPO on both benchmarks, and vanilla OPD fails to match any RL-based approach. These results directly support the claim that skill injection should be used for privileged teacher conditioning but not for student prompting, as student-side skill conditioning induces overfitting and domain discrepancy.
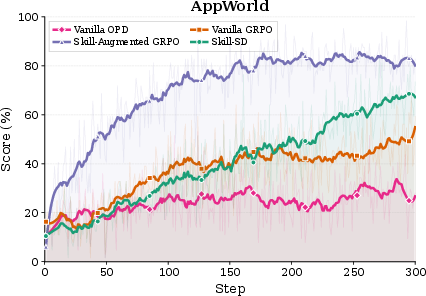
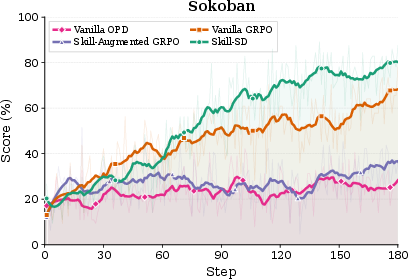
Figure 3: Training curves on AppWorld and Sokoban; Skill-SD overtakes vanilla GRPO and avoids overfitting observed in skill-augmented GRPO.
Ablation across four teacher–student configurations (on-policy/off-policy rollout × frozen/dynamic teacher) demonstrates that only student-owned rollout with dynamic teacher synchronization yields stable training and superior generalization. Off-policy or frozen teacher variants collapse or plateau at suboptimal scores, particularly pronounced in high-irreversibility settings like Sokoban.
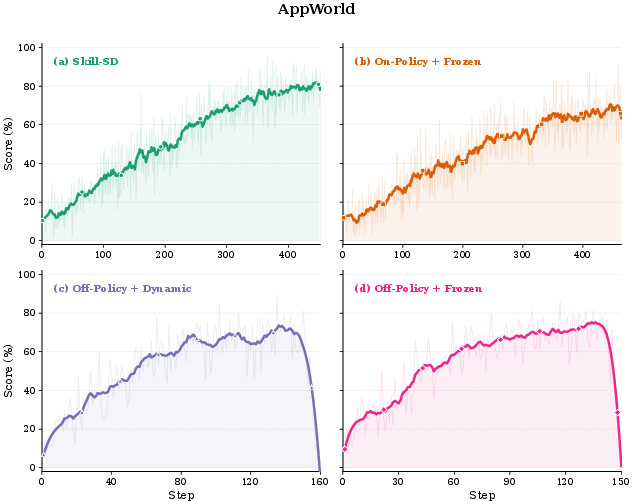
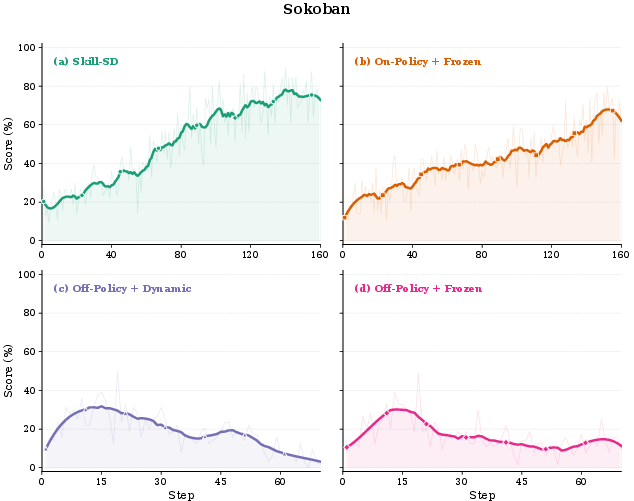
Figure 4: Training stability under four teacher–student configurations. Skill-SD (on-policy + dynamic) trains stably; off-policy configurations collapse mid-training.
The sensitivity of the main results to the SDL loss coefficient λ is also examined. The optimal regime combines a shaping effect from the teacher with enough weight on reward-driven exploration; λ=0.001 gives best validation/generalization, while larger values suppress exploration and smaller values dilute the distillation signal.
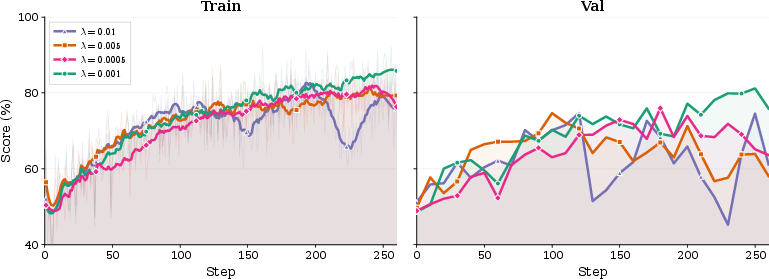
Figure 5: Effect of SDL coefficient λ on AppWorld training/validation. λ=0.001 provides optimal trade-off between exploration and skill distillation.
Theoretical and Practical Implications
Skill-SD formalizes skill-conditioned self-distillation as a reliable mechanism for dense credit assignment in agentic LLMs where gold action sequences are unavailable or non-unique. This framework addresses the open question of privileged information design in agent domains, proposing natural language skill synthesis as a medium for conveying structured, reusable knowledge across evolving student–teacher pairs. The derived importance-weighted SDL loss provides a theoretically sound estimator for reverse-KL under cross-prompt configurations, a scenario rarely handled in policy gradient literature except in recent works focused on explicit off-policy corrections [zhang2025rpg, tang2025pitfalls, liu2025rethinking].
Practically, Skill-SD demonstrates high sample efficiency and robustness even with small task pools (90 AppWorld, 96 Sokoban tasks), leveraging asynchronous skill summarization to avoid RL's bottleneck on reward sparsity. The method scales without introducing inference-time retrieval dependence—the agent is always evaluated on the plain prompt, ensuring alignment between training and deployment conditions.
Impact and Future Directions
Skill-SD’s principle—that skills should guide the teacher but never the student directly—clarifies how to utilize learned or induced task structure for efficient RL agent training, avoiding the overfitting and distribution mismatch seen in prompt-based retrieval during both prior work and ablation studies. Its compatibility with any RL-compatible LLM architecture and modular skill summarization via black-box LLMs allows integration with larger models and more complex multi-agent or open-ended environments.
Several theoretical questions remain. The extension to richer, embedding-based retrieval over growing skill banks invites exploration of meta-learning and memory mechanisms. Trajectory-level KL bounds and self-evolution dynamics in the presence of non-stationary teachers suggest further opportunities for rigorous analysis. Partial-vocabulary or curriculum-based self-distillation could further improve long-horizon performance.
Conclusion
Skill-SD establishes skill-conditioned, on-policy self-distillation as an efficient and robust mechanism for token-level credit assignment in RL-finetuned LLM agents, resolving the mismatches in prior teacher-student and skill-prompting paradigms. Dynamic co-evolution of student and teacher, together with importance-weighted SDL loss, ensures stable, performant learning without reward sparsity bottlenecks. These insights directly inform best practices for multi-turn LLM agent training pipelines, with implications for both current systems and the design of future adaptive, skill-accumulating lifelong agents.
(2604.10674)