- The paper introduces OPSDL, using on-policy self-distillation with token-level reverse KL divergence to align long-context outputs with short-context performance.
- It significantly improves long-context benchmarks by up to 48.70 points while maintaining minimal short-context degradation and high sample efficiency.
- The method eliminates external supervision, offering a scalable, self-teaching framework applicable across various LLM scales and architectures.
OPSDL: On-Policy Self-Distillation for Long-Context LLMs
Introduction
LLMs have achieved remarkable performance when processing short contexts, but their effectiveness degrades significantly as context windows extend to hundreds of thousands of tokens. This gap between the architectural maximum and effective contextual capacity restricts LLMs in applications requiring long document comprehension, repository-level code analysis, and multi-hop reasoning. The primary obstacles in bridging this gap are the inefficiency of current training paradigms—most notably supervised fine-tuning (SFT) and preference optimization—which either rely on costly high-quality data, sparse reward signals, or auxiliary reward models, all exacerbating optimization instability and impeding sample efficiency.
This paper introduces OPSDL: an On-Policy Self-Distillation paradigm that systematically exploits a model's internal asymmetry, using its robust short-context generation as a self-teacher to align its long-context behavior via token-level reverse KL divergence. OPSDL's distinguishing design is the elimination of external supervision—instead, the model supervises itself, providing stable and dense training signals focusing the optimization directly on the loci of context-induced degradation.
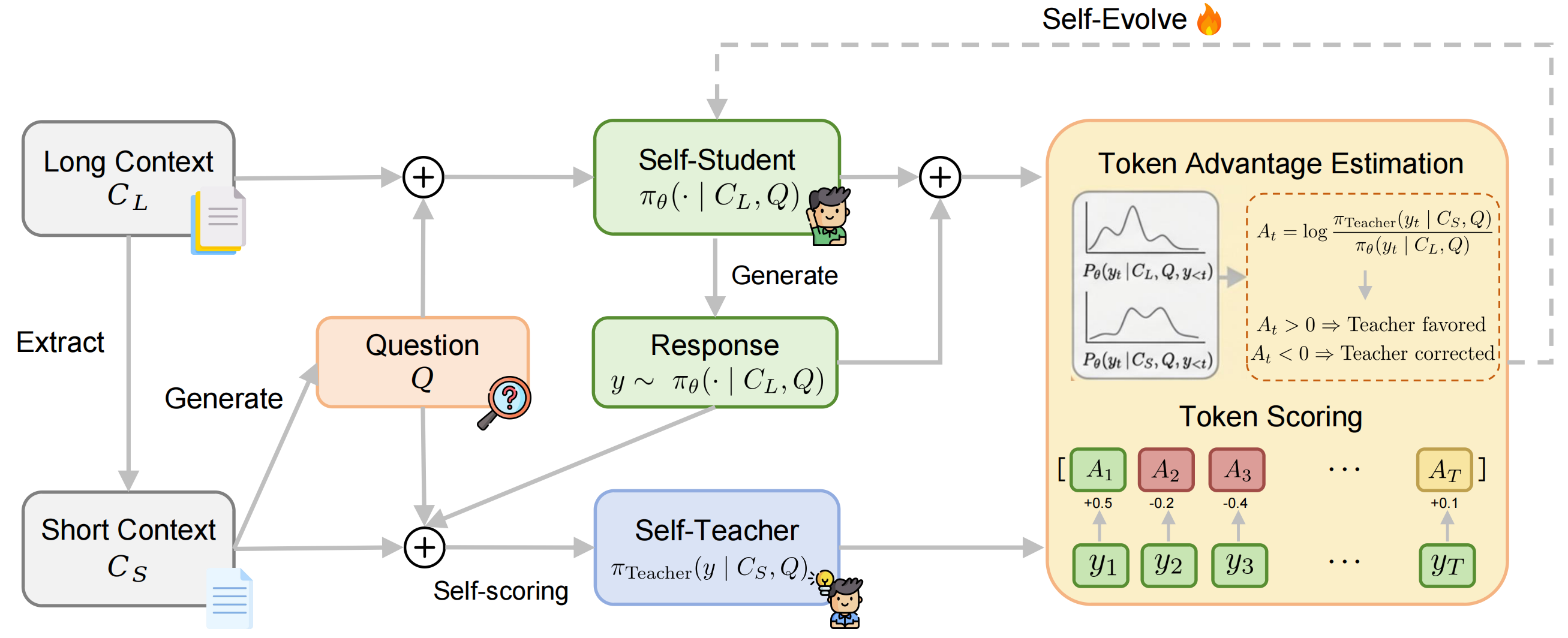
Figure 1: Overview of the OPSDL framework where the model generates responses on-policy under a long context, then supervises itself via token-level reverse KL divergence against its own outputs conditioned on the short context.
Method
OPSDL addresses the long-context alignment problem through short-to-long self-distillation. For a sampled long context CL, a core-preserving short context CS is extracted. The model generates an instruction or query Q based on CS. The training triplet (CL,CS,Q) enables direct comparison: the model generates a response under both long and short contexts, and per-token distributions are compared.
Rather than introducing privilege via teacher models or human annotations, OPSDL utilizes the same policy under CS as a dynamic teacher. The central training signal is the token-level advantage
At(yt)=logπθ(yt∣CL,Q,y<t)πTeacher(yt∣CS,Q,y<t),
which is integrated into a policy gradient objective targeting reverse KL divergence minimization between short- and long-context policies. Importantly, only non-trivial deviations between short- and long-context token probabilities elicit gradient updates, effectively focusing optimization and mitigating noise.
The training pipeline is characterized by:
Empirical Results
Extensive evaluation was performed using Qwen2.5-Instruct models at 7B, 14B, and 32B scales on RULER and LongBench V2—benchmarks designed to probe both synthetic and realistic long-context reasoning. OPSDL was compared with Long-SFT and LongPO, as well as dedicated long-context variants (Qwen2.5-Instruct-1M).
The major findings are:
- Superior Performance Stability: OPSDL consistently delivers the largest improvements over base instruction-tuned models across all model sizes and context lengths, both on synthetic (RULER) and natural (LongBench V2) benchmarks. For instance, at 128K tokens on RULER, OPSDL yields a +48.70, +34.25, and +30.29 point improvement over the base models for 7B, 14B, and 32B respectively.
- Token-Level Training Efficiency: By providing dense, token-level signals rather than sparse sequence-level rewards, OPSDL achieves greater sample efficiency and training stability. This is particularly apparent as LongPO failed to converge at higher scales, whereas OPSDL remained robust.
- Minimal Short-Context Degradation: OPSDL preserves general short-context performance (average degradation ≈1.3 points across MMLU, ARC-C, HellaSwag, Winogrande), outperforming Long-SFT which exhibits 3–4 point drops. MT-Bench scores remain virtually unchanged.
- Closes Long-Context Generalization Gap: Without lengthy multi-stage pretraining or external alignment signals, OPSDL narrows the performance gap to specialized, million-token-context models. For the 7B variant on RULER, this gap narrows from 13.10 to 3.94 points.
Theoretical and Practical Implications
OPSDL demonstrates that stable, scalable long-context alignment can be achieved through internal self-supervision by leveraging the model’s intrinsic short-context capabilities. The absence of reliance on reward models, human-annotated preference data, or external teachers removes pipeline complexity and reduces the risk of overfitting to proxy reward signals. OPSDL’s methodologically clean design also suggests theoretical implications:
- Self-Evolving Anchors: Token-level, on-policy self-distillation promotes continual policy self-evolution, enabling adaptive calibration as the model’s generative frontier expands.
- Focused Optimization: The loss strictly penalizes context-induced discrepancies, which avoids unnecessary modification of well-aligned tokens, thus mitigating catastrophic forgetting.
- Model Agnosticism: OPSDL is validated across multiple scales and model families, pointing to generalizability beyond the Qwen2.5-Instruct series.
Practically, OPSDL presents an efficient route for extending LLMs’ effective context window—critical as applications require deeper, multi-hop discourse and document understanding. Moreover, as models and tasks scale, techniques eliminating reliance on external data and supervision become more imperative.
Future Directions
The short-to-long self-distillation framework established by OPSDL opens several avenues:
- Adaptive Context Extraction: Advancing methods for dynamically selecting informative short contexts as anchors may further enhance fidelity.
- Scaling to Million-Token+ Contexts: Incorporating iterative bootstrapping may push effective context windows still further.
- Hybridization with Memory-Augmented Models: OPSDL could complement explicit retrieval or memory systems, providing a robust alignment backbone.
Conclusion
OPSDL marks a significant step in post-training paradigms for long-context LLMs by systematizing on-policy self-distillation using short-context anchors. Dense token-level, reverse KL-based optimization yields consistent, stable, and scalable improvements across context lengths and architectures, eliminating the need for external supervision and maintaining short-context competence. OPSDL thus offers a principled and practical foundation for future advances in long-context language modeling (2604.17535).