- The paper proposes Teacher-Guided Policy Optimization (TGPO) to replace unstable RKL feedback with dense, token-level teacher supervision during on-policy distillation.
- It leverages differentiable regularization and reward shaping to achieve robust convergence even under significant teacher-student divergence.
- Empirical results demonstrate that TGPO outperforms traditional methods in stability, reasoning performance, and scalability in LLM distillation tasks.
Teacher-Guided Policy Optimization for LLM Distillation: An Expert Analysis
Introduction
This work presents a rigorous reformulation of policy distillation for LLMs, addressing the instability and inefficiencies of the conventional Reverse KL (RKL) framework in on-policy LLM policy optimization. By introducing Teacher-Guided Policy Optimization (TGPO), the authors propose a step-wise, dense supervision mechanism, operationalized directly on the student’s own rollouts, which achieves a robust synthesis between imitation and exploration. This essay provides an in-depth summary and analysis of the methodology, theoretical findings, and empirical evaluations presented, with special attention to the implications for scalable and stable LLM distillation.
Analysis of RKL Limitations for On-Policy Distillation
The canonical approach to on-policy LLM distillation relies on RKL divergence, which theoretically offers a bridge between pure RL and teacher-driven imitation. The RKL objective encourages the student distribution πθ to approximate the teacher πT by penalizing deviations according to their density ratios. Crucially, optimization is performed using rollouts sampled from the student—an alignment necessary for on-policy RL algorithms.
When the support mismatch between πθ and πT is minor, RKL converges rapidly, as demonstrated in Figure 1.
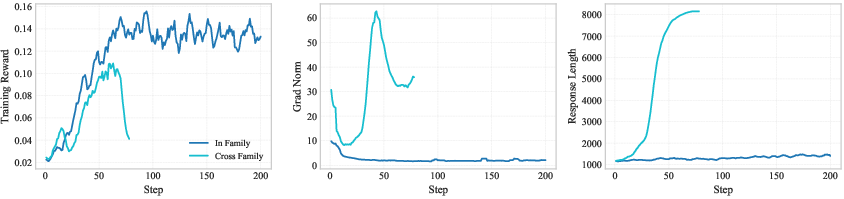
Figure 1: RKL-based distillation is stable under minimal teacher-student divergence but catastrophically unstable with significant teacher-student gaps.
However, the authors rigorously diagnose two interconnected failure modes of RKL:
- Unshaped Negative Feedback: In regions where the student assigns nontrivial probability mass to sequences the teacher assigns near-zero likelihood, RKL provides only a scalar penalty without directional guidance (see Figure 2). This lacks constructive gradient information about which targets to move toward, particularly deleterious for complex reasoning tasks where meaningful gradients are required for effective learning.
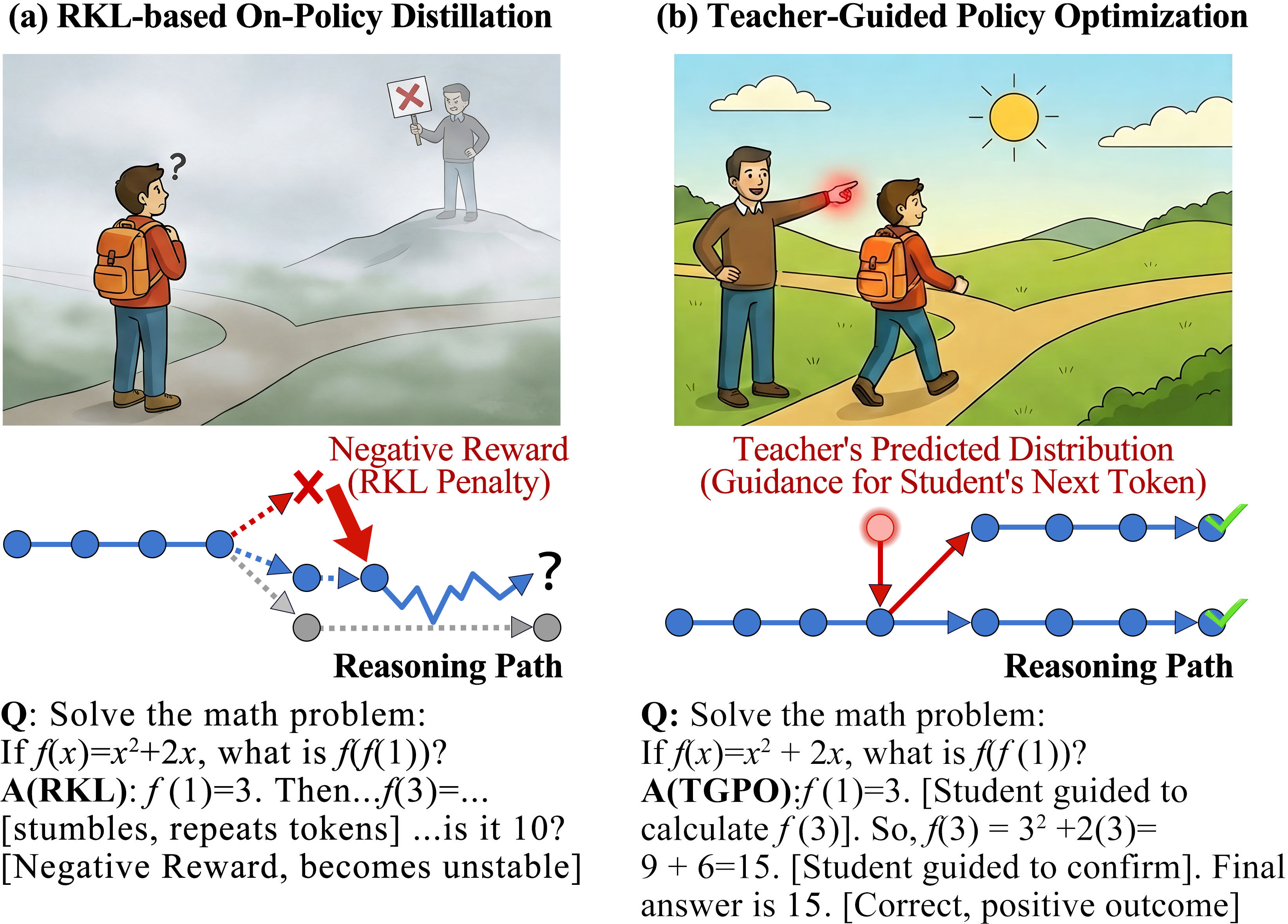
Figure 2: RKL (a) gives only penalty-based signals, while TGPO (b) provides explicit teacher-driven guidance for the next action.
- Gradient Explosion and Instability: Owing to the unboundedness of the log-density ratio as πT(y∣x)→0, the gradient estimator suffers high variance, leading to optimization collapse, uninformative reward signals, and catastrophic phenomena such as output length explosion (see Figure 1 and empirical gradients in training curves).
TGPO remediates the deficiencies of RKL by transforming the role of the teacher from a punitive evaluator to an explicit guide. At each generation step, rather than merely evaluating the probability of the student's output sequence, TGPO queries πT for the optimal token given the student's current state, and enforces maximal likelihood over these teacher-provided targets. This allows for dense, directionally informative supervision injected into the on-policy training process without reverting to off-policy teacher-forcing (thus preserving exposure to the student’s own error modes).
The core training loop is encapsulated in Figure 3.
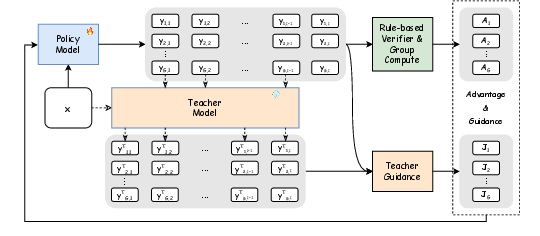
Figure 3: TGPO framework—student generates rollouts, and the teacher provides dynamic, token-level targets at each timestep for policy optimization.
TGPO is integrated with the GRPO framework. Two strategies for coupling teacher signals are analyzed:
- Reward Shaping: Teacher-guided feedback is added to the scalar reward. This does not offer a differentiable path and modifies only the advantage estimator.
- Differentiable Regularization: The guidance enters as an auxiliary regularization term in the loss, allowing direct gradient flow toward the teacher targets.
Empirical comparison in the paper consistently favors the differentiable regularization variant, which provides superior convergence and final performance.
Empirical Validation
Robustness to Teacher-Student Divergence
TGPO's main empirical advantage is robust convergence and scalability even in cross-family (i.e., large capability gap) teacher-student distillation. Unlike RKL or KDRL (which rapidly collapse due to the theoretical instabilities analyzed above), TGPO maintains stable gradient norms, balanced response lengths, and monotonically increasing training rewards.
Training dynamics are summarized in Figure 4.
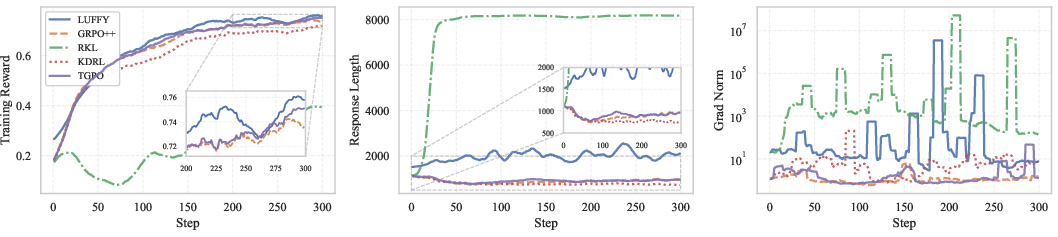
Figure 4: TGPO exhibits smooth reward growth, stable response length, and low-variance gradients compared to pathological dynamics in RKL/KDRL/LUFFY.
Scheduling of Teacher Guidance
A detailed ablation (Figure 5) examines annealing the weight of the teacher-guided loss. The optimal strategy is to begin with a nonzero guidance weight and linearly decay it to zero before the end of training. This enables effective early bootstrapping from dense teacher signals but allows the student to ultimately maximize reward through self-driven exploration, preventing over-regularization.
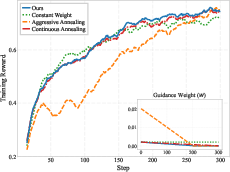
Figure 5: Annealing the guidance weight enables the best transition from imitation to autonomous policy optimization.
Generalization and Teacher Model Agnosticism
TGPO consistently outperforms on-policy, off-policy, and mixed-policy baselines (e.g., SFT, LUFFY, SimpleRL, KDRL) on both in-distribution mathematical reasoning tasks and out-of-distribution general benchmarks. The framework is robust to teacher choice—more capable teacher models yield stronger student performance, but the architectural assumptions of the teacher do not materially alter the algorithm’s stability.
Further training dynamic analyses for smaller student models confirm that instability in RKL/KDRL intensifies as the capability gap grows, while TGPO maintains reliable learning curves.
Theoretical and Practical Implications
TGPO fundamentally reorients the design of on-policy LLM distillation. Theoretically, it demonstrates that dense, step-wise teacher-driven guidance can provide the benefits of both RL-driven outcome optimization and direct imitation, without inheriting the instability or inefficiency of RKL. The granular gradient path induced by teacher token suggestions is especially significant for reasoning tasks with high action space entropy, where non-directional reward signals are ineffective.
Practically, TGPO enables compact student models to reach and generalize high-level capabilities with limited compute and without extensive off-policy data curation. Its design aligns well with scalable RL training pipelines and is compatible with modern RLVR systems.
Future Directions
Possible research avenues include extension to teacher ensembles (exploiting diverse forms of teacher supervision), mechanistic interpretability of guidance trajectories, and the application of TGPO-style supervision in multi-modal and sequence-to-sequence setups beyond text generation.
Conclusion
Teacher-Guided Policy Optimization presents a mathematically coherent and empirically validated solution to the deficiencies of RKL-based on-policy distillation, enabling robust and data-efficient LLM reasoning transfer. By anchoring policy optimization in dense, token-level teacher guidance, TGPO achieves stable training, superior reasoning performance, and enhanced generalization across a broad range of student-teacher configurations (2605.13230).

