Self-Distilled RLVR
Abstract: On-policy distillation (OPD) has become a popular training paradigm in the LLM community. This paradigm selects a larger model as the teacher to provide dense, fine-grained signals for each sampled trajectory, in contrast to reinforcement learning with verifiable rewards (RLVR), which only obtains sparse signals from verifiable outcomes in the environment. Recently, the community has explored on-policy self-distillation (OPSD), where the same model serves as both teacher and student, with the teacher receiving additional privileged information such as reference answers to enable self-evolution. This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training. Accordingly, we identify the optimal niche for self-distillation and propose \textbf{RLSD} (\textbf{RL}VR with \textbf{S}elf-\textbf{D}istillation). Specifically, we leverage self-distillation to obtain token-level policy differences for determining fine-grained update magnitudes, while continuing to use RLVR to derive reliable update directions from environmental feedback (e.g., response correctness). This enables RLSD to simultaneously harness the strengths of both RLVR and OPSD, achieving a higher convergence ceiling and superior training stability.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching large AI LLMs to reason better. The authors compare two ways of training:
- Reinforcement learning with verifiable rewards (RLVR): the model tries to answer questions and only gets a simple “right” or “wrong” signal at the end.
- Distillation: a “teacher” gives the model detailed hints at every step about which next word is likely.
They show why a popular “self-teaching” style of distillation can go wrong and introduce a new method, RLSD (Reinforcement Learning with Self-Distillation), that keeps the good parts of both worlds to make training faster, more stable, and more accurate.
What questions were the researchers trying to answer?
In simple terms:
- Why does self-distillation sometimes give quick early gains and then make models worse later?
- How can we give a model fine-grained, step-by-step learning signals without making it “cheat” by relying on information it won’t have during real use?
- Can we combine the reliability of “right/wrong” checks with the efficiency of per-token (word-by-word) guidance?
How did they do it?
Think of training a model like coaching a student on math problems.
- RLVR is like giving the student a single grade—pass or fail—after they finish a solution. It’s clear and fair, but not very detailed.
- Regular distillation is like having a smarter teacher who shows, step by step, which words or steps are better. It’s very detailed, but it usually needs a bigger separate teacher model.
- Self-distillation tries to avoid needing a separate teacher: the same model acts as both teacher and student. The “teacher version” of the model is allowed to peek at extra “privileged” information (like the answer key or reasoning trace), while the student version only sees the question. The teacher then guides the student.
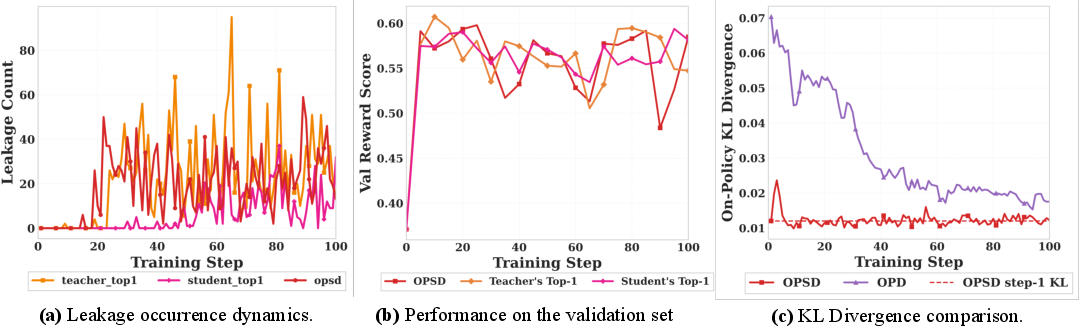
The problem: in self-distillation, the teacher keeps using secret hints (the answer key), but the student is asked to copy that behavior without having those hints at test time. Over time, the student starts to “lean on” those hidden hints—this shows up as the model literally referring to a “reference solution” in its answers. That’s called leakage, and it makes performance collapse later.
The authors’ key idea in RLSD:
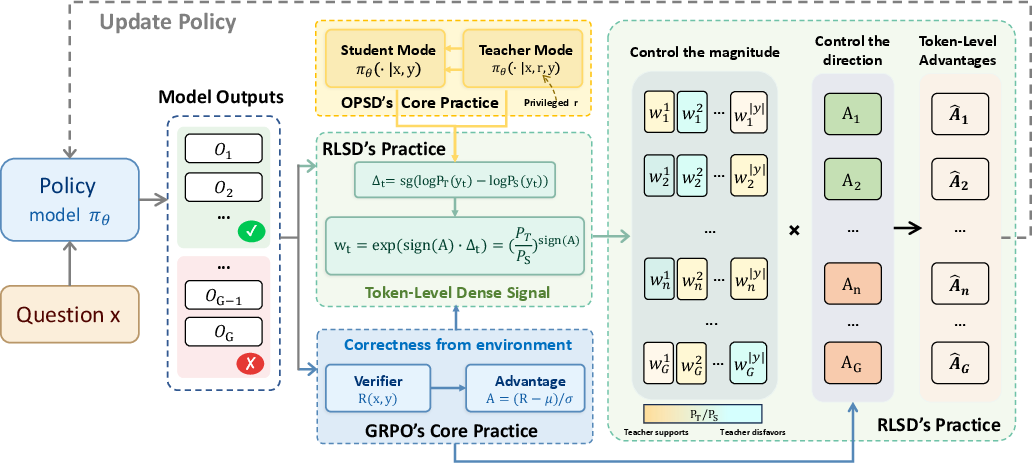
- Use the environment’s right/wrong check to decide the direction of learning: Did this answer deserve a push up (reward) or down (penalty)?
- Use self-distillation only to decide how much credit or blame each token (word) should get, not whether to reward or punish. In other words, the “teacher with hints” sets the size of per-token adjustments, but the “pass/fail” result decides the overall direction.
Analogy: The final grade (pass/fail) decides whether to celebrate or correct. The teacher’s extra insight is used only to figure out which exact steps in the solution mattered most—so you praise or correct the right parts—without changing the final judgment.
This avoids cheating because the secret hints never decide the direction of learning; they only shape the distribution of attention across steps.
What did they find and why is it important?
Main findings:
- Self-distillation (without safeguards) improves fast early on but then degrades and causes leakage: the model starts to act like it can see a hidden “reference solution.”
- The authors explain why this happens: the “teacher” has extra information the “student” will never see at test time. Forcing the student to match the teacher exactly creates a mismatch that can’t be fully fixed; over time, the model tries to encode shortcuts to those hidden hints, which breaks generalization.
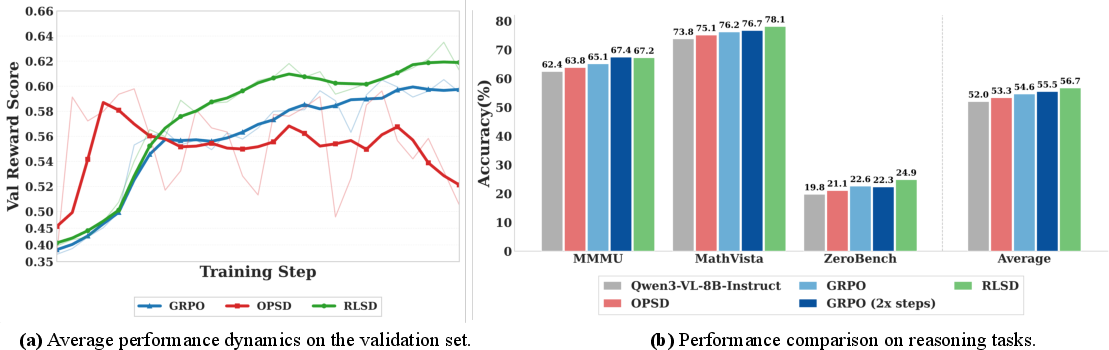
- RLSD avoids this trap. It keeps training stable like RLVR, but learns faster and reaches better performance by using per-token weights from the self-teacher only to allocate credit/blame within an answer.
Experiments (on a vision-LLM called Qwen3-VL-8B-Instruct across several tough reasoning benchmarks):
- RLSD outperformed both plain RLVR and self-distillation on average.
- It reached higher peak performance and stayed stable instead of collapsing late.
- It converged faster than RLVR trained for twice as long.
- It improved especially on harder math/visual reasoning tasks, where careful token-level credit matters most.
Why it matters:
- You can train strong reasoning models without relying on a huge separate teacher.
- You get the detail of token-by-token learning but keep the reliability of “right vs. wrong” supervision.
- Training becomes both efficient and robust, reducing the chance of models “cheating” by relying on hidden information.
What could this mean in the future?
- Better AI tutors, solvers, and assistants: Models can learn complex, step-by-step reasoning more effectively, especially on math or multimodal (text+image) tasks.
- Lower training costs: No need for a large external teacher model, while still getting rich training signals.
- More trustworthy behavior: Decoupling “direction” (from verified correctness) and “magnitude” (from self-teacher hints) reduces leakage and instability, making models more reliable in real-world use.
In short, RLSD shows a practical way to get the best of both: the stability of outcome-based learning and the speed of fine-grained guidance—without teaching the model to rely on information it won’t have when it’s actually used.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future work.
- Lack of generalization evidence across model families and sizes: results are limited to Qwen3-VL-8B-Instruct; it remains unknown whether RLSD’s gains hold for text-only LLMs, larger/smaller models, and other multimodal backbones (e.g., LLaVA, InternVL).
- External validity across tasks: evaluations focus on five multimodal reasoning benchmarks; applicability to text-only reasoning, code generation, long-form writing, multi-step tool use, and safety-critical tasks is untested.
- Sensitivity to hyperparameters: no ablation on key RLSD knobs (ε_w clipping range, λ schedule, group size G, sampling temperature, learning rate); stability and performance under different settings are unclear.
- Teacher staleness and sync cadence: the teacher is synced every 10 steps; the effect of this cadence on bias, variance, stability, and convergence (including faster/slower syncs) is unstudied.
- Computational overhead and scaling: “one extra forward pass” is claimed negligible, but there is no quantification of wall-clock time, throughput, memory footprint, or scaling behavior with long sequences, large G, and larger models.
- Convergence guarantees: RLSD’s objective is presented as a clipped surrogate but lacks theoretical convergence or monotonic improvement guarantees analogous to PPO-style analyses.
- Bias introduced by stop-gradient weighting: the use of stop-gradient in Δ_t yields a biased estimator; the impact on optimization bias/variance and sample efficiency is not analyzed.
- Robustness to reward misspecification: RLSD anchors update directions to environment rewards, but behavior under noisy, sparse, delayed, or mis-specified verifiers (e.g., partial credit, continuous rewards) is not evaluated.
- Robustness to privileged-information noise: RLSD uses the final ground-truth answer as r; tolerance to incorrect, ambiguous, or noisy answers (and their effect on Δ_t and weights) is unknown.
- Empirical leakage assessment for RLSD: while a theoretical argument for leakage immunity is given, there is no quantitative leakage audit for RLSD (e.g., counts of references to hidden answers, prompt-injection style tests, or auxiliary classifiers).
- Comparison to strong OPD teachers: there is no head-to-head with OPD using a larger external teacher (a key alternative paradigm) to assess whether RLSD’s gains persist when OPD has an advantage.
- Interaction with standard regularizers: KL penalties to a reference SFT policy and entropy regularization are omitted; the effect of reintroducing them on stability, entropy, and performance remains unexplored.
- Alternative weighting functions: the choice w_t = exp(sign(A) * Δ_t) is not compared to other mappings (e.g., linear, softplus, bounded/logit transforms) that may reduce sensitivity or improve stability.
- Token-credit fidelity evaluation: beyond qualitative heatmaps, there is no quantitative measure of how well token-level credit aligns with human rationales or known critical steps (e.g., correlation with annotated rationales).
- Long-horizon and very long-context behavior: scalability and stability for longer contexts and trajectories (e.g., 32K tokens, multi-step chains) are not measured; O(T) extra teacher computation could be prohibitive at scale.
- Multi-turn/interactive settings: applicability of RLSD to multi-turn conversations or interactive environments (where r may change across turns) is unaddressed.
- Off-policy or offline applicability: the method is on-policy; whether RLSD can be adapted to offline datasets, replay buffers, or experience relabeling is not discussed.
- Impact of data filtering: training on MMFineReason-123K filtered for failures may induce selection bias; generalization to unfiltered or differently curated datasets is untested.
- Statistical reliability: results appear from single runs without confidence intervals or multiple seeds; variance across runs and statistical significance are not reported.
- Duration of training stability: training is shown for ~200 steps; it is unknown whether RLSD remains stable over much longer horizons or under curriculum scaling.
- Compatibility with richer privileged signals: RLSD is demonstrated with final answers as r; whether adding partial rationales, intermediate verifiable steps, or multiple r sources yields further gains or reintroduces leakage is open.
- Synergy with other credit assignment methods: comparisons or combinations with value-function-based token credit (e.g., token-level V/Q estimates) or per-token verifiers are not explored.
- Safety and alignment effects: how RLSD affects hallucination rates, calibration, or harmful content risks—especially when weighting emphasizes tokens correlated with r—is not investigated.
- Failure modes under class imbalance: GRPO’s group-relative normalization drives the sign of A; how RLSD behaves when reward distributions are highly imbalanced (e.g., very low success rates) is not analyzed.
- Formal link to a principled objective: while RLSD is motivated as reweighting evidence within policy gradients, a clear derivation from a single well-defined expected-return objective (including the role of clipping) is not provided.
- Estimating the mutual-information gap in practice: the theoretical I(Y_t; R | X, Y_{<t}) analysis explains OPSD failure, but empirical estimation of this quantity (across tasks or over training) is not conducted to guide practice.
- Extension to structured or graded verifiers: adaptation of RLSD when verifiers emit token-level, step-level, or soft scores (rather than binary outcomes) is not demonstrated.
- Generality beyond autoregressive tokens: applicability to non-AR policies (e.g., diffusion, non-causal decoders) or continuous actions remains an open question.
Practical Applications
Immediate Applications
The paper introduces RLSD, a training paradigm that combines verifiable, environment-anchored reward signals with self-distilled, token-level credit assignment. This improves stability and convergence over GRPO and avoids privileged-information leakage observed in OPSD, with minimal overhead (one extra forward pass) and no external teacher. The following are actionable, deployable use cases.
- Software engineering: test-driven code assistants and agents (Software)
- Fine-tune code LLMs using unit tests or I/O gold outputs as verifiable rewards; use RLSD to concentrate positive/negative credit on tokens that determine test outcomes (e.g., function signatures, key logic).
- Tools/workflows: CI-integrated RLSD post-training; sandboxed execution to gather pass/fail; token-level credit visualizer for debugging model reasoning.
- Assumptions/dependencies: high-quality, comprehensive tests; deterministic or sufficiently stable execution environment; secure sandboxing; availability of logits and ability to run an extra forward pass.
- Structured data extraction and generation with validators (Software, Enterprise IT)
- Train LLMs to produce JSON, XML, SQL, or schema-constrained outputs with exact-match or schema-validation as rewards; RLSD improves token-level attribution (e.g., correctly formatted keys/values).
- Tools/workflows: schema validators, JSON schema unit tests, exact-match field checkers in labeling pipelines.
- Assumptions/dependencies: robust validators with low false positives/negatives; access to ground-truth labels for critical fields; constrained decoding where needed.
- Math/STEM tutoring and assessment systems (Education)
- Post-train models on problem sets with answer keys; use RLSD to reinforce decisive steps while penalizing erroneous ones, improving solution accuracy and stability over long training runs.
- Tools/workflows: auto-grading pipelines (exact/numeric tolerance matching), curriculum schedulers, math benchmarks.
- Assumptions/dependencies: reliable answer keys; careful prompt design to avoid overfitting to surface patterns; compute for on-policy rollouts.
- Multimodal reasoning for visual QA with answer keys (Software, Retail/E-commerce)
- For counting, chart reading, or attribute identification tasks with verifiable answers, RLSD improves VLMs’ token efficiency and stability (as shown on MathVista/MathVision).
- Tools/workflows: image-caption/QA datasets with answer annotations; automated verifiers (e.g., programmatic counting ground truth, OCR-validated labels).
- Assumptions/dependencies: accurate visual labels; consistent preprocessing; verifiers tolerant to minor formatting differences.
- SQL/analytics query generation with execution checks (Software, Data/Analytics)
- Train models to synthesize queries where the result set is known or can be validated with canonical answers; reward = exact or near-exact result match.
- Tools/workflows: dataset of queries with gold results; execution sandbox; regression tests over representative tables.
- Assumptions/dependencies: stable schemas/data snapshots; deterministic or bounded-variance metrics; safety controls for query execution.
- Enterprise knowledge QA with curated ground truth (Enterprise IT, Customer Support)
- Use RLSD for retrieval-augmented QA where certain answers are objectively verifiable (e.g., policy numbers, phone extensions, SKU attributes); enforce exact-match or rule-based verification.
- Tools/workflows: curated KB with exact answers; verifiers (regex/semantic matches); evaluation dashboards tied to RLSD training metrics.
- Assumptions/dependencies: high-precision KB; clear reward definitions; limited scope to avoid unverifiable queries.
- More stable, lower-cost RL post-training pipelines (MLOps)
- Replace uniform token advantages in GRPO with RLSD’s clipped credit weights to improve convergence speed/ceiling without a larger teacher; reduces compute vs. OPD and avoids vocab constraints.
- Tools/workflows: RLSD as a drop-in module in VERL/EasyR1/TRLX; clip-ratio monitoring; leakage counters.
- Assumptions/dependencies: availability of verifiable rewards; model exposes logits for teacher/student contexts; routine hyperparameter tuning (e.g., εw, λ).
- Governance: leakage-aware training and monitoring (Policy, AI Safety/Compliance)
- Adopt RLSD to avoid privileged-information leakage during self-distillation; establish training monitors (e.g., on-policy KL, leakage counters) and policies for privileged inputs.
- Tools/workflows: training audits, model cards documenting verifiers, leakage detection heuristics from the paper’s diagnostics.
- Assumptions/dependencies: internal processes for logging/verifying training signals; clear definitions of “privileged information” per use case.
- Tokenizer/migration-friendly post-training (Software)
- Because RLSD does not require a separate teacher with shared vocabulary, it simplifies post-training when tokenizers or base models change.
- Tools/workflows: RLSD fine-tuning after tokenizer swaps; compatibility tests across model families.
- Assumptions/dependencies: availability of verifiable tasks in the target domain; reproducible inference environments.
Long-Term Applications
The paper’s method suggests broader applications as verifiable reward design, simulators, and scaling mature. These require further development, domain-specific verification, or infrastructure.
- Tool-using agents with simulator-verified goals (Robotics, Logistics, Industrial Ops)
- Train multimodal agent policies to complete tasks in simulated environments (e.g., assembly steps, warehouse routing) with binary verifiers; RLSD provides fine-grained token credit without auxiliary value networks.
- Potential products: “sim-to-LLM” training suites; agentic task libraries with verifiers.
- Assumptions/dependencies: high-fidelity simulators; reliable pass/fail task definitions; safe bridging from language actions to real actuators.
- Healthcare document extraction and coding under strict validators (Healthcare)
- Use RLSD to train models for medical code assignment or structured extraction where validators encode billing/format rules and gold labels are available.
- Potential products: coding assistants with token-level error attribution; audit tools.
- Assumptions/dependencies: rigorous compliance/regulatory approval; privacy-preserving training; comprehensive, accurate labels; cautious deployment with human oversight.
- Financial report parsing and compliance checking (Finance, RegTech)
- Train models to extract and reconcile figures from filings against audited values; verifiers encode accounting rules and acceptable tolerances.
- Potential products: disclosure consistency checkers; automated footnote parsers.
- Assumptions/dependencies: robust rule/verifier design; risk controls for false positives; secure data handling.
- Continual online improvement from verifiable user feedback (Cross-industry)
- Convert subsets of user interactions into verifiable outcomes (e.g., workflow success, form validation) and update models with RLSD in near-real-time.
- Potential products: adaptive helpdesks, self-improving form-fill agents.
- Assumptions/dependencies: careful reward shaping to avoid gaming; A/B safeguards; data drift monitoring; privacy/consent mechanisms.
- Safety and alignment training with verifier-anchored objectives (Policy, AI Safety)
- Use RLSD to anchor optimization directions to conservative, policy-compliant rewards (e.g., red-teaming with deterministic rule checks); self-distillation supplies dense credit without teacher models.
- Potential products: policy-guarded fine-tuning suites; red-team simulators with pass/fail verifiers.
- Assumptions/dependencies: high-precision safety verifiers; strong coverage of edge cases; continuous auditing.
- Domain-general reasoning labs using richly verifiable micro-tasks (Academia/Research)
- Build catalogs of verifiable reasoning primitives (math, logic, program synthesis) and study scaling laws and credit assignment behavior under RLSD.
- Potential outputs: standardized benchmarks; open-source RLSD baselines.
- Assumptions/dependencies: community-maintained verifiers; reproducible training stacks; compute access.
- Agent planning with tool feedback as verifiable signals (Software, Operations)
- Train chain-of-thought planners where tool call returns (e.g., API status, constraint solvers) are used as binary rewards; RLSD assigns credit to steps that improve plan validity.
- Potential products: scheduling/planning assistants with provable constraint satisfaction.
- Assumptions/dependencies: reliable tool feedback; well-defined success criteria; robust interfaces between LLM and tools.
- Enhanced interpretability and debugging via token-level credit maps (Cross-sector)
- Productize RLSD’s token-level advantage as a diagnostic feature for developers and auditors, helping pinpoint which tokens/steps drove success or failure.
- Potential products: training dashboards; compliance-relevant explanation reports.
- Assumptions/dependencies: privacy-aware logging; clear mapping from credit weights to human-understandable tokens; careful UI/UX to avoid misinterpretation.
Notes on Feasibility and Transfer
- RLSD requires verifiable rewards. It is best suited to tasks with deterministic or high-confidence validators (e.g., exact answers, unit tests, structured schemas). Where rewards are noisy or subjective, benefits diminish and classic preference-based RL may be more appropriate.
- RLSD avoids external teachers and vocabulary-sharing constraints, decreasing cost and increasing portability. However, it still assumes access to “privileged” signals at training (often just the final ground-truth answer), and that this information is not leaked at inference—a risk mitigated by RLSD’s direction anchoring and clipping.
- Integration is straightforward in GRPO-like pipelines (VERL/EasyR1), but practitioners need monitoring (clip ratios, entropy, leakage heuristics) and hyperparameter tuning (e.g., εw, λ) for stability across domains.
Glossary
- Adam: An adaptive stochastic optimizer using first and second moment estimates for gradient-based training. "such as SGD and Adam \citep{kingma2017adammethodstochasticoptimization}"
- Advantage: In policy-gradient RL, a baseline-adjusted return indicating how much better a trajectory (or token) is than average. "and computes a sequence-level advantage for each response relative to the group:"
- Autoregressively: Generating each token conditioned on all previously generated tokens. "the model generates a response autoregressively."
- Bayesian interpretation: Viewing updates as Bayesian belief updates from a prior to a posterior. "This formulation admits a natural Bayesian interpretation."
- Clipped surrogate objective: A PPO-style objective that clips policy-ratio terms to bound update size and improve stability. "The policy is then updated via a clipped surrogate objective:"
- Conditional mutual information: Mutual information between two variables given others, measuring dependence after conditioning. "where denotes the conditional mutual information between the current token and the privileged information under the teacher distribution."
- Distribution matching: Training a model to match a target distribution (e.g., student matching teacher). "We formalize the structural deficiency of the distribution matching paradigm underlying OPSD and related methods."
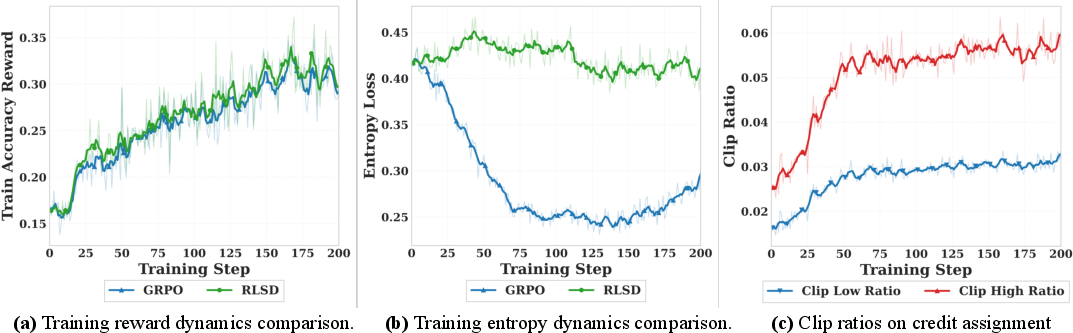
- Entropy collapse: A reduction in output entropy leading to overconfident, less diverse predictions. "GRPO suffers from rapid entropy collapse due to its uniform sequence-level reward,"
- Entropy regularization: A loss term encouraging higher entropy to prevent premature collapse and improve exploration. "omit both the KL penalty loss and entropy regularization loss from the objective function."
- Evidence ratio: The ratio quantifying how privileged information changes a token’s probability. "the evidence ratio also carries a useful signal"
- Evidence reweighting: Reweighting token-level credit by the evidence ratio while keeping the update direction from the environment reward. "Direction-aware evidence reweighting."
- GRPO (Group Relative Policy Optimization): An RLVR algorithm using group-based, normalized advantages with clipped updates. "Group Relative Policy Optimization (GRPO)~\citep{grpo} samples a group of responses"
- Importance ratios: Ratios (e.g., or ) used to reweight gradients for stability or credit correction. "Both are importance ratios operating within the same policy gradient framework"
- Importance sampling ratio: The ratio between current and behavior policies for correcting distribution shift in updates. "is the importance sampling ratio between the current and old policies."
- Jensen-Shannon divergence: A symmetric divergence measure between distributions, often used for distillation objectives. "such as the generalized Jensen-Shannon divergence."
- KL divergence: Kullback–Leibler divergence; measures how one probability distribution differs from another. "Under OPD, the KL divergence decreases steadily throughout training,"
- Law of total probability: Expresses a marginal probability as an expectation over a latent variable. "via the law of total probability:"
- Leakage bandwidth: The effective number of positions where privileged information influences gradient direction. "the concept of leakage bandwidth, which we define as the effective number of token positions at which -specific information enters the gradient direction."
- Log-derivative trick: Rewriting gradients of expectations using for policy gradient estimators. "minimizing the reverse KL $D_{\mathrm{KL}(P_S \| P_T)$ via the log-derivative trick yields ."
- Logits: Pre-softmax scores emitted by a neural model, often used for token-level supervision. "provide dense, token-level logits as learning signals"
- Marginal teacher distribution: The teacher’s distribution averaged over the latent privileged information. "recover the marginal teacher distribution via the law of total probability:"
- Mutual information gap: An irreducible loss term due to dependence on unobserved privileged information. "an irreducible mutual information gap "
- On-Policy Distillation (OPD): Distillation using the student’s own trajectories, with a separate teacher providing dense token targets. "On-policy distillation (OPD) has become a popular training paradigm in the LLM community."
- On-Policy Self-Distillation (OPSD): OPD variant where the same model, conditioned on privileged information, acts as the teacher. "On-policy self-distillation (OPSD)~\citep{zhao2026opsd,hbotter2026reinforcementlearningselfdistillation_sdpo} offers an appealing alternative:"
- Per-sample gradient: The gradient computed on an individual training instance, which can deviate from the expectation. "the per-sample gradients carry an -specific deviation"
- Policy gradient: RL methods optimizing expected return via gradients of log action probabilities weighted by advantages. "within the same policy gradient framework"
- Posterior: The updated belief after observing evidence. "P_T(y_t) represents the posterior assessment after observing the privileged information ."
- PPO (Proximal Policy Optimization): A policy-gradient RL algorithm using clipped objectives and implicit trust regions. "value-function estimation in PPO~\citep{schulman2017proximalpolicyoptimizationalgorithmsppo}"
- Prior: The initial belief before observing evidence. "P_S(y_t) represents the model's prior assessment of token "
- Privileged information: Additional information available to the teacher but not to the student at inference time. "the teacher is the same model conditioned on privileged information "
- Privileged information leakage: Model behavior that relies on or reveals inaccessible privileged information. "accompanied by systematic privileged information leakage,"
- Reverse KL: The divergence used for matching the student to the teacher. "minimizing the reverse KL $D_{\mathrm{KL}(P_S \| P_T)$"
- RLSD (RLVR with Self-Distillation): The proposed method that anchors update direction to rewards and modulates magnitude via self-distillation. "We propose RLVR with Self-Distillation (RLSD),"
- RLVR (Reinforcement Learning with Verifiable Rewards): RL framework using environment-checked outcomes as rewards. "Reinforcement learning with verifiable rewards (RLVR) methods such as GRPO"
- Self-distillation: A technique where a model uses its own (context-augmented) predictions to guide training. "self-distillation provides a natural and virtually cost-free source of per-token credit information,"
- Stop-gradient operator: An operation that prevents gradients from flowing through a term used as a weight or signal. "where denotes the stop-gradient operator."
- Token efficiency: Efficiency measured by the amount of useful learning signal per token. "OPSD achieves several-fold improvements in token efficiency over GRPO"
- Token-level credit assignment: Assigning credit/blame to individual tokens based on their contribution to outcomes. "prior approaches to token-level credit assignment,"
- Trust-region constraints: Bounds limiting update magnitudes to stabilize training. "Both mechanisms act as trust-region constraints that stabilize training."
- Verifier: A procedure that checks correctness and emits a (binary) reward signal. "a verifier provides a binary reward "
- Value-function estimation: Learning a baseline to reduce variance in policy gradients. "such as value-function estimation in PPO~\citep{schulman2017proximalpolicyoptimizationalgorithmsppo}"
Collections
Sign up for free to add this paper to one or more collections.