- The paper introduces guided denoiser self-distillation for RL in diffusion language models, eliminating ELBO-induced approximations and TIM bias.
- It recasts RL as a denoiser self-distillation problem by matching energy-guided logits through token-level logit centralization to achieve stable training.
- Experimental results demonstrate up to +19.6% accuracy improvements across tasks such as reasoning, planning, and code generation.
Guided Denoiser Self-Distillation for Reinforcement Learning in Diffusion LLMs
Introduction
The paper "GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion LLMs" (2605.29398) proposes a novel framework for reinforcement learning (RL) in diffusion LLMs (dLLMs), titled Guided Denoiser Self-Distillation (GDSD). While dLLMs have established themselves as efficient alternatives to autoregressive models (ARMs) for text generation—offering up to an order-of-magnitude inference speedup—they traditionally lag behind in generation quality. Fine-tuning these models via RL is nontrivial, as the policy likelihoods in dLLMs are generally intractable due to non-autoregressive, masked generation procedures.
The prevailing paradigm replaces the intractable likelihood with an evidence lower bound (ELBO), estimated from randomly masked sequences. However, this introduces a significant training-inference mismatch (TIM) bias, resulting in degraded performance and training collapse. GDSD addresses this fundamental mismatch by directly recasting RL as a self-distillation problem for denoiser distributions, eliminating the need for likelihood ratios and the reliance on ELBO-based surrogates.
Motivation: Limitations of ELBO-based RL for dLLMs
Central to dLLM reinforcement learning is the challenge of intractable model likelihoods. Sequence-level RL methods approximate path likelihoods via ELBO, estimated using masked modeling objectives. These methods are both computationally tractable and naturally aligned with dLLM pretraining objectives. Nonetheless, the use of ELBO as a surrogate for likelihood engenders a structural discrepancy between the optimization target in training and the underlying generative process at inference—what the paper precisely defines as the TIM bias.
Key sources of this bias include:
- The non-negligible gap between the ELBO and the actual likelihood.
- The difference between the distribution induced by dLLM re-masking/block-wise sampling and the ELBO-based training distribution.
- The inability of importance-sampling ratio corrections to compensate for this misalignment, leading to substantial objective bias, poor reward propagation, and ultimately training collapse.
This is formalized by showing that the reward-maximizing policy under ELBO-based objectives is systematically inconsistent with the deployment-time policy.
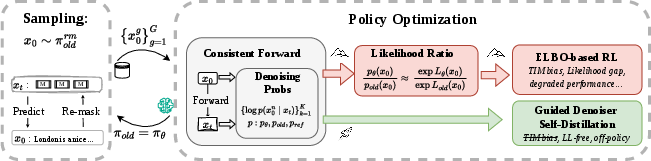
Figure 1: Schematic of RL for dLLMs contrasting ELBO-based approaches (left) with GDSD (right), the latter bypassing likelihood computations and thus TIM bias.
GDSD reformulates RL for dLLMs as a direct distillation problem. Theoretical analysis begins by expressing the reverse KL-regularized RL objective and deriving its closed-form optimal policy. The optimal updated policy is a function of the old policy, reference policy, and an exponentiated advantage term, parameterized as:
π∗(x0)∝πold(x0)1−β⋅πref(x0)β⋅exp(ψA(x0))
For masked diffusion models, this update induces an energy-guided denoiser distribution. GDSD then proceeds to distill this energy-guided denoiser into the parametric model via logit matching using a mean-squared error objective on the denoising logits between the student and teacher.
This yields the following practical, normalization-free loss (after centralization):
E[(logpˉold(x0∣xt)pˉθ(x0∣xt)−ψA(x0))2+β(logpˉref(x0∣xt)pˉθ(x0∣xt))2]
where bar denotes logit centralization over the vocabulary.
The primary architectural and empirical novelty comes from:
- Avoiding intractable normalization constants in the teacher distribution using token-level logit centralization (TLC), exploiting the translation invariance of softmax.
- Framing reinforcement learning as off-policy denoiser self-distillation, removing any need for importance sampling or ELBO-based path likelihood estimation.
Algorithmic Details
GDSD is designed for minimal intervention in standard RL pipelines for dLLMs. It operates in two stages:
- Sample Generation: Generate completions using the old policy (potentially with iterative re-masking), assign rewards and compute advantages group-wise.
- Denoiser Logit Matching: For each completion, sample time steps and apply consistent forward diffusion. For each masked state, compute denoising logits for the student, old, and reference models, perform TLC, and minimize the proposed MSE objective.
Crucially, this procedure enables the model to train on off-policy samples, circumventing both ELBO-induced bias and the model-sampler distribution shift.
Empirical Results
Experimental evaluation is performed with LLaDA-8B-Instruct and Dream-7B-Instruct, across mathematical reasoning (GSM8K, MATH500), logical planning (Countdown, Sudoku), and coding (HumanEval, MBPP). GDSD is compared against several baselines, including:
- ELBO/weighted-ELBO methods: wd1, DMPO
- Importance-sampling-based RL methods: SPG, UniGRPO, ESPO
GDSD demonstrates:
- Superior test accuracy: On Dream-7B, test-accuracy improvements up to +19.6% over the best previous methods; on LLaDA-8B across all domains, consistent accuracy gains between +0.6% and +5%.
- Stabilized training rewards: Training dynamics exhibit increased stability, convergence speed, and avoidance of common RL failure modes.
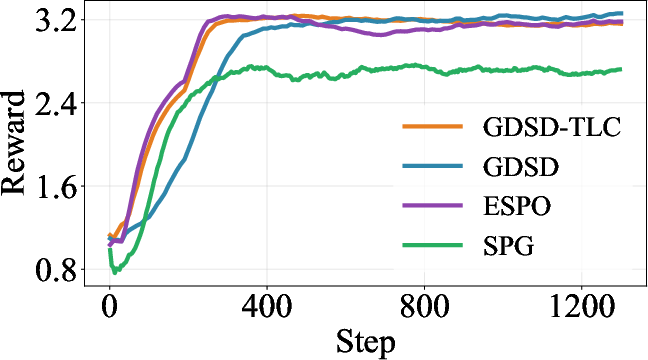
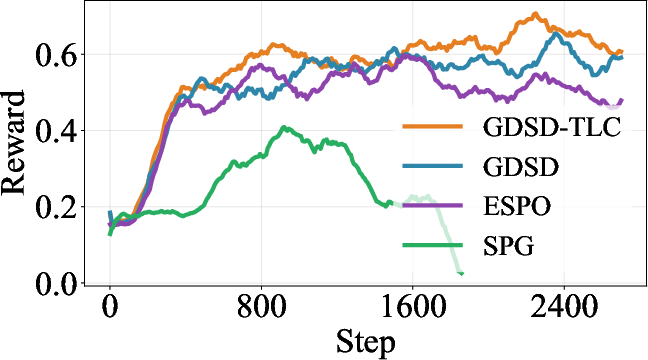
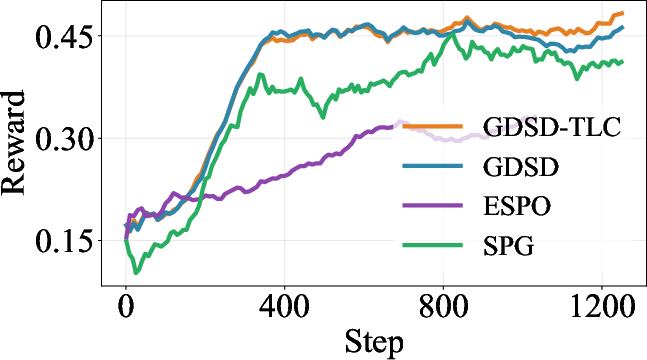
Figure 2: Training reward curves on multiple tasks, showing GDSD's superior stability and reward attainment compared to ELBO-based baselines.
Ablation studies further validate the necessity and stabilizing impact of TLC—yielding greater reward stability and improved accuracy (though some degradation on test performance is observed in rare cases, suggesting potential overfitting or “over-centralization”).
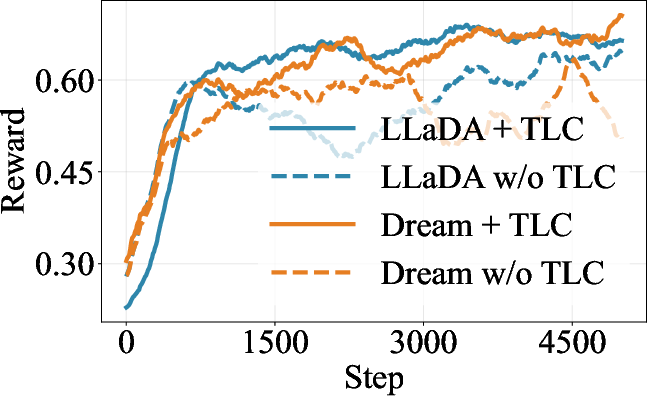
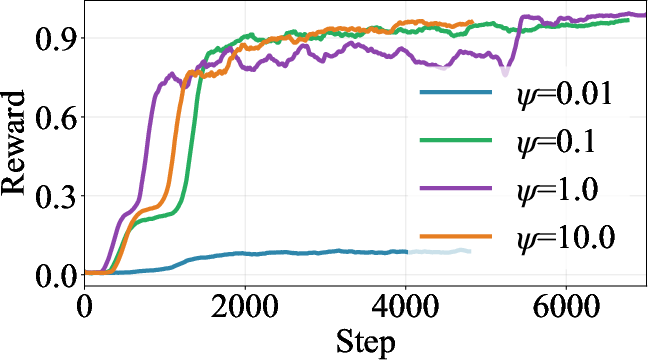
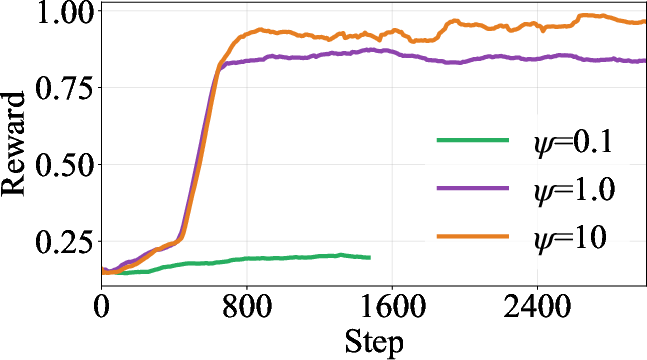
Figure 3: Ablation results demonstrating the contributions of TLC and the energy-guidance coefficient ψ to training dynamics and reward maximization.
Theoretical and Practical Implications
GDSD’s core innovation—recasting RL as denoiser self-distillation—fundamentally resolves TIM bias by construction and exposes new regularization and optimization avenues in diffusion RL:
- Likelihood-free RL: Direct denoiser distillation negates the necessity of tractable likelihood estimates, opening the door to broader RL applications in diffusion models for domains where sequences are highly structured or have large vocabulary spaces.
- Effective use of negative and positive samples: Unlike advantage-weighted ELBO methods that severely downweight negative samples, GDSD incorporates both positive and negative advantage signals directly, resulting in efficient batch utilization and higher data efficiency.
- Basis for generalization: As a general meta-algorithm, logit-matching distillation could subsume or unify several regularized RL or policy-optimization objectives, with normative connections to reverse-KL and score-matching perspectives.
From a practical standpoint, the heightened stability and efficiency of RL for dLLMs provided by GDSD may accelerate the adoption of diffusion-style generative modeling in domains currently dominated by autoregressive models—particularly where large-scale reward modeling or iterative reasoning is required.
Limitations and Future Directions
Despite its advantages, GDSD as presented is focused on discrete-space, masked diffusion models for text. The centralized logit formulation assumes the softmax translation invariance and does not explicitly address generation order or block-structured encoding, which may interact nontrivially with future model architectures (e.g., block or patch diffusion).
Potential future directions include:
- Extending GDSD to mixed or hierarchical diffusion processes, or models with latent variable conditioning beyond masked sequence models.
- Investigating regularization strategies within GDSD to further mitigate potential overfitting induced by logit centralization.
- Applying likelihood-free denoiser distillation in multimodal or non-text diffusion policy domains.
Conclusion
Guided Denoiser Self-Distillation represents a substantial advancement in the RL fine-tuning of diffusion LLMs, providing a theoretically sound, bias-free, and empirically robust alternative to prior ELBO-based and importance-sampling RL methods. The framework’s ability to deliver stable training, improved accuracy, and generalization across reasoning, planning, and code generation benchmarks signals a maturation in the field of diffusion-based generative modeling. The methodology developed has likely implications for both the practical deployment and theoretical grounding of RL in non-autoregressive sequence models.
(2605.29398)