Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence
Abstract: Scientific discovery is not only answer generation but revision of the representational regime in which evidence, artifacts, operations, and verifiers are typed. We develop a category-theoretic account of agentic discovery for materials science. In a fixed regime b with schema category S_b, the system state is a copresheaf I_t: S_b -> Set, and provenance is the category of elements \int_{S_b} I_t. Fixed-regime operation is an update on such states, endofunctorial only when provenance-preserving refinements are specified and preserved. Discovery is instead a verified regime transition u: S_b -> S_b': old artifacts are preserved, transported by the left Kan extension Lan_u I_t, and compared with the post-transition state to identify residual content beyond functorial transport. This separates retrieval, search, and discovery without subjective novelty. We instantiate the framework in two systems. In Builder/Breaker, a protein-mechanics world model is revised under a Minimum Description Length gate; the accepted law expresses within-chain flexibility as all-mode elastic compliance conditioned by slow collective-mode participation, or mode-conditioned compliance. In CategoryScienceClaw, typed skills, artifacts, open needs, workflow mutation, gates, stress tests, and public discourse become a proof-carrying knowledge-computation graph. A fiber-network example records candidate models, rejected alternatives, an AIC gate, perturbation tests, and an accepted orientation-tensor anisotropic stiffness surrogate over an isotropic fiber-count descriptor. Together, the cases show how category theory can be both a mathematical language for discovery and an engineering specification for self-revising AI discovery systems.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Self‑Revising Discovery Systems for Science” in Simple Terms
Overview: What is this paper about?
This paper shows how to build AI “scientists” that don’t just look up facts or tweak models, but can also change the way they think when the evidence demands it. The authors use a math language called category theory to design AI systems that:
- keep very careful records of how every result was produced,
- know when they’re just searching within the current rules,
- and know when it’s time to change the rules themselves (that’s real discovery).
They demonstrate the idea with two examples from materials science: one about how proteins flex, and another about how to organize and audit scientific work across many tools and people.
Goals: What questions are they answering?
In everyday terms, the paper asks:
- How can an AI tell the difference between: 1) retrieving a known fact, 2) searching for a better solution using the same rules, 3) and discovering something new that requires changing the rules?
- How can an AI record and justify the exact moment it changed its “vocabulary” (the types of things it talks about) so other people can trust and reuse that change?
- How can we update models without breaking or erasing past results and their history?
- How can we measure whether a proposed change is worth it (for example, whether it explains more with fewer assumptions)?
Approach: How does the system work? (With everyday analogies)
Think of science here as a workshop with:
- labeled boxes for different kinds of things (data, models, code, figures),
- tools that can turn one kind of thing into another,
- and a family tree that remembers which tools created which results.
In the paper’s terms:
- The “schema” is the rulebook that says what kinds of things exist (types) and what tools (operations) are allowed to transform them.
- The system’s “state” is like a set of shelves with labeled boxes; each box holds all current items of a certain type. Mathematicians call this a copresheaf, but you can think of it as “for each label, a list of items.”
- The “provenance graph” is the family tree of artifacts: every result records which parents and which tool produced it.
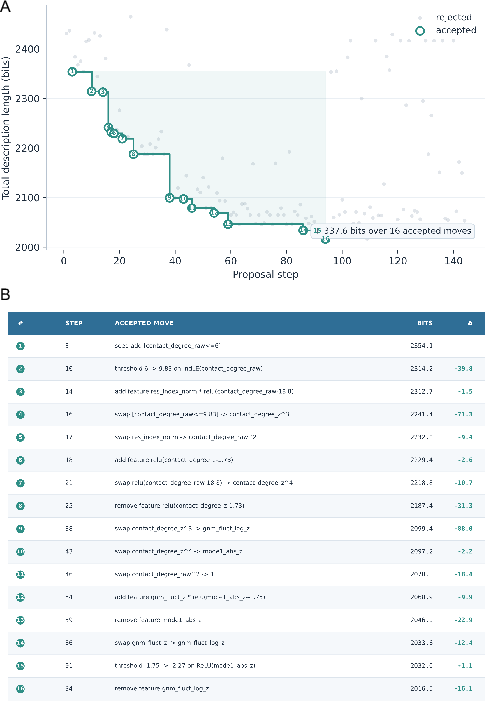
- A “gate” or “verifier” is a referee that decides whether a new result is accepted, rejected, or replaced. One important gate they use is Minimum Description Length (MDL): pick the explanation that compresses the data best (like choosing the smallest file that still has all the information).
- A “regime change” is when the workshop rulebook itself changes: you add a new box type, a new tool, or a new test. That’s discovery.
There are three modes of progress:
- Retrieval: grabbing something that already fits in your current boxes.
- Search: trying new paths using your current boxes and tools.
- Discovery: adding new boxes/tools/tests because the old ones can’t explain the new evidence.
One technical step worth simplifying:
- When the rulebook changes, you need to move old items into the new shelf layout. The paper uses a standard math method (called a left Kan extension) that acts like “the best systematic way to re-file old items into the new boxes.” If a brand‑new box had no connection to the old shelf plan, it stays empty until you create truly new content. This cleanly separates what’s just re-filed from what’s genuinely new.
To keep updates safe and trustworthy, the system:
- preserves past results and their IDs,
- records parents and tools for every result,
- never silently deletes accepted results,
- and applies the same rules consistently, so you can audit what happened.
For practical deployment, the authors lift these ideas into CategoryScienceClaw, which turns skills, artifacts, open problems, workflow changes, tests, and even public discussion into a single, proof‑carrying, auditable “knowledge–computation graph.”
Main findings: What did they discover and why does it matter?
Case study 1: Builder/Breaker discovers a new protein flexibility rule
- Problem: Predict patterns of how much each part of a protein wiggles (flexibility), using only the 3D structure.
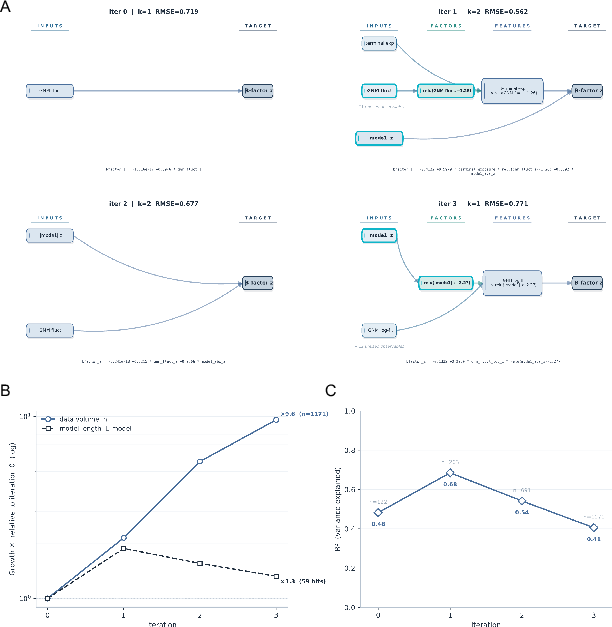
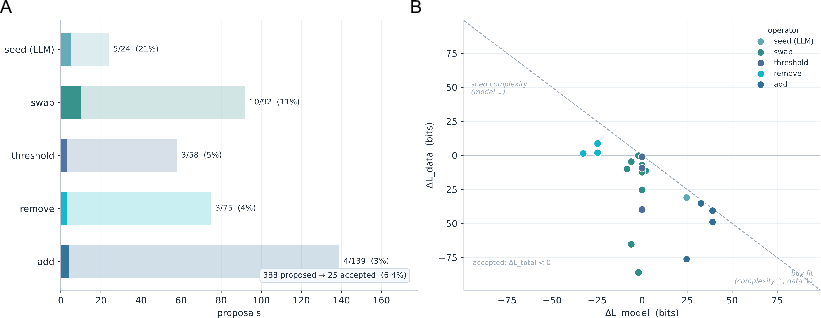
- Method: The Breaker selects proteins that expose weaknesses in the current model (like trying to break a bridge to learn its weak points). The Builder proposes model changes. A gate (MDL) only accepts a change if it explains more with fewer bits of description.
- Discovery: The accepted rule says that a residue’s flexibility is best explained by: 1) how “locally soft” it is according to the protein’s contact network, times 2) how much it participates in the protein’s slow, whole‑protein movement. In short: local softness matters most when it lines up with slow global motions. This is called “mode‑conditioned compliance.”
Why this is important: - It’s not just adding another term to a formula. The system changed its “vocabulary” to allow a new kind of interaction (a meaningful product of two factors), and that led to a simpler, better explanation according to the MDL gate. - Mechanically, it makes sense: flexibility is not just local; it’s local behavior expressed through big, collective motions.
Case study 2: CategoryScienceClaw makes science auditable end‑to‑end
- What it is: A platform that treats everything—skills, artifacts, open needs, workflow edits, tests (“stress tests”), acceptance gates, and public discussion—as typed, linked objects with proofs and lineages.
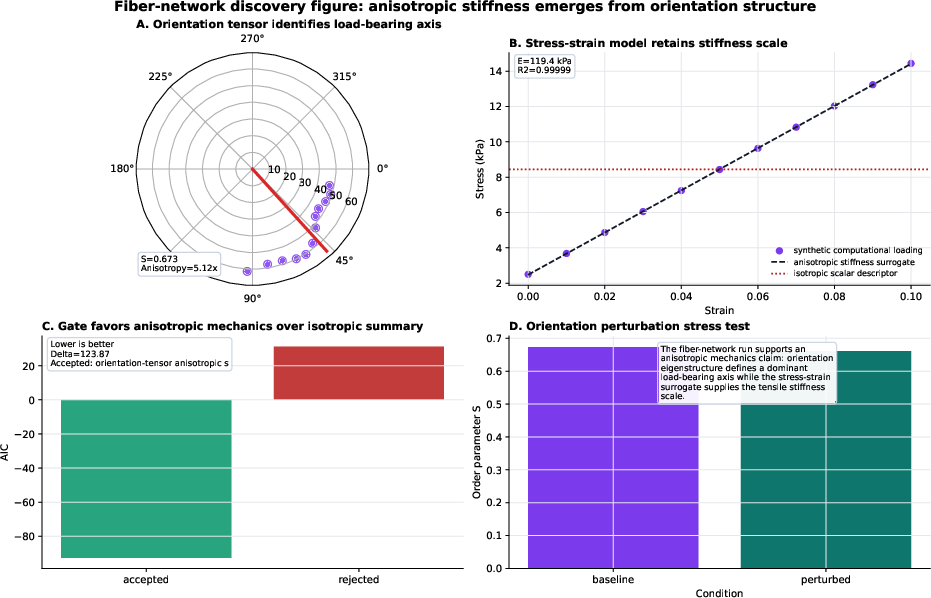
- Example: In a fiber‑network mechanics problem, the system recorded:
- candidate models,
- rejected alternatives,
- the gate used (AIC, another model‑selection score),
- stress tests,
- and the final accepted model: an orientation‑tensor anisotropic stiffness surrogate (it acknowledges direction‑dependent stiffness) chosen over a simpler “just count fibers” model.
- Why this matters:
- The entire reasoning process is transparent and replayable.
- The system captures not only what was accepted, but also what was tried and rejected, and why.
Implications: Why does this research matter?
- It draws a clean line between retrieving facts, searching within current rules, and discovering new rules. That helps us measure real scientific progress.
- It shows how to build AI scientists that can safely and transparently revise their own “vocabulary” when evidence demands it—without breaking past work or losing the audit trail.
- It provides a math‑backed, engineering‑ready blueprint for trustworthy scientific AI: every result is typed, every step is recorded, every acceptance is justified, and every regime change is documented.
- It bridges mechanics and AI: ideas like load, response, failure, and multiscale structure inspire how the AI organizes and tests its own scientific claims.
- Beyond materials science, this approach can help any field that needs AI systems to do more than predict—systems that must explain, justify, and sometimes change the way problems are represented.
A short summary to remember
- Retrieval = add known stuff.
- Search = find better paths with the same rules.
- Discovery = change the rules (new types, tools, or tests), but keep and re‑file the old evidence.
- Use gates like MDL/AIC to accept only changes that earn their keep.
- Record everything so science is verifiable, reusable, and self‑improving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a categorical framework for self-revising discovery systems and demonstrates two case studies. The following unresolved issues identify what is missing, uncertain, or left unexplored, to guide future research:
- Formal conditions for valid regime transitions: How to algorithmically propose, select, and validate schema maps (including non-fully-faithful changes such as type-splitting, added morphisms, or verifier extensions) while guaranteeing preservation of intended semantics.
- Transport fidelity under schema mismatch: When changes meanings of types or operations, what constraints ensure that is a faithful reinterpretation (not a semantic distortion) of prior artifacts; what coherence or commutativity conditions are required for safe “data migration” beyond pure category-theoretic existence.
- Quantifying discovery via residual content: The paper proposes using the comparison map and a relative description-length to measure discovery. How to instantiate, compute, and validate this quantitatively across domains, and how sensitive is it to the choice of coding scheme, priors, and schema granularity.
- Uniqueness and minimality of regime changes: Given an anomaly, when do minimal (in a categorical or MDL sense) regime transitions exist, are they unique, and how can one search for minimal and post-transition states efficiently.
- Trade-offs between left and right Kan extensions: The framework adopts left Kan extension for transport. When are right Kan extensions or other adjoint constructions more appropriate (e.g., for restriction/refinement regimes), and how do choices affect what counts as “residual content.”
- Practical computation of Kan extensions at scale: Algorithmic strategies, complexity bounds, and data structures needed to compute for large schemas and artifact populations (including incremental maintenance and streaming settings).
- Refinement-preserving endofunctoriality in practice: Concrete protocols, APIs, and conformance tests to guarantee that real systems maintain stable identifiers, explicit supersession, and injective natural transformations so that acts functorially on refinements in .
- Stochasticity and uncertainty: A full development of as a stochastic kernel (Kleisli morphism) including uncertainty propagation, calibration of verifiers, and probabilistic guarantees on acceptance/rejection under noisy or partial evidence.
- Multicategorical provenance at scale: Formal and computational treatment of multi-parent artifacts (hyperedges), including colored-operad or multicategory realizations of with efficient query, visualization, and audit support.
- Gates and verifiers as first-class structures: Formal semantics, compositionality, and interoperability of gates (MDL, AIC, pressure scoring, peer review). How to combine gates, calibrate thresholds, avoid circularity, and reason about Type I/II errors in regime transition decisions.
- Preventing regime overgrowth and overfitting: Mechanisms (MDL penalties, regularized gate design, structural priors) that prevent unbounded schema expansion that trivially lowers description length but harms generalization or interpretability.
- Benchmarking “discovery” vs “search”: Community benchmarks, ablation protocols, and stress-test suites that can discriminate fixed-regime search improvements from genuine regime changes using the proposed residual-content metric.
- Interoperability and merge of scientific states: How to compute limits/colimits (e.g., pushouts, unions) of categorical knowledge–computation graphs from different labs, resolve conflicts, and track credit while preserving provenance and gate decisions.
- Human–AI governance and safety: Policies and technical controls to prevent dangerous regime transitions (e.g., adding harmful tool types or operations), including authorization, capability gating, and audit trails for high-risk schema changes.
- Social verifiers and discourse integration: Formalizing public discourse objects () and publication maps —their trust models, adversarial robustness, moderation, and how social signals feed back into gates without introducing bias.
- Robustness to adversarial artifacts: Threat models and defenses against poisoning of artifact populations, gaming of gates, or manipulations of provenance to induce spurious regime transitions.
- Cost models and resource-aware scheduling: Methods to prioritize which regime mutations to test under limited compute/experiment budgets, balancing MDL gains against execution cost and wall-clock time.
- Sensitivity to schema design: Systematic studies of how initial schema choices and granularity affect transport, residual content, and the probability of discovering useful transitions; methods for schema auto-tuning.
- Formal connections to alternative formalisms: Comparative analysis and integration with program synthesis, probabilistic programming, theorem proving, or abstract interpretation to leverage complementary strengths in verification and search.
- Learning-to-propose regime transitions: Algorithms that learn proposal distributions over and post-transition candidates from historical anomalies and successful transitions, with off-policy evaluation under gates.
- Provenance of failures and retractions: Formal representation of rejected artifacts, supersession chains, and retractions so that negative results are reusable and can prevent future redundant search.
- Case-study external validity (protein mechanics): Generalization of the mode-conditioned compliance law beyond the selected proteins; sensitivity to contact cutoff , log floor , ReLU shift , and per-chain normalization; robustness to crystal packing, disorder, and multichain assemblies; comparisons to state-of-the-art predictors and independent test sets.
- Mechanistic interpretability tests: Stress tests to confirm that the multiplicative interaction is mechanistically causal (e.g., perturbation of mode structure by targeted mutations or graph edits) rather than a coincidental proxy.
- Alternative spectral structures: Exploration of whether additional modes, mode subspaces, or nonlinear spectral functionals further improve compression without overfitting; principled selection of spectral features under an MDL budget.
- Domain transfer beyond materials science: Validation of the categorical discovery framework in other sciences (e.g., systems biology, climate, economics), including domain-specific gate design and transport semantics.
- Realizing proof-carrying knowledge: Concrete certificate formats, checkers, and scalability results for “proof-carrying” artifacts in CategoryScienceClaw, including formal guarantees of reproducibility and trust.
- Usability and developer ergonomics: Tools, schema DSLs, and debugging support that make it practical for researchers to define types, morphisms, gates, and transition candidates without deep category-theory expertise.
- Evaluation of discourse impact: Empirical measurement of how public discourse signals (votes, critiques, replications) influence gate quality and discovery rates, and how to mitigate popularity or network effects.
- Legal/ethical/IP considerations: Attribution, licensing, and credit assignment when knowledge–computation graphs are merged, branched, or partially privatized, and how such constraints interact with transport and gate decisions.
Practical Applications
Immediate Applications
The following use cases can be deployed with today’s tools and the codebases referenced in the paper (ScienceClaw, Infinite, CategoryScienceClaw, BreakingTheWorld), or with modest integration effort:
- Typed, audit-ready knowledge–computation graphs for research workflows
- Sectors: academia, corporate R&D, software/MLOps
- What: Represent datasets, models, code, hypotheses, and reports as typed artifacts with explicit parent lineage; unify workflow provenance, gate decisions, and public discourse into one executable, verifiable state (copresheaf + category of elements).
- Tools/workflows: CategoryScienceClaw/ScienceClaw for typed skills and immutable artifacts; integration with MLflow/DVC or lab notebooks for artifact storage; “gate” endpoints to record accept/reject/supersede decisions.
- Assumptions/dependencies: Teams must define a domain schema S_b (artifact types and allowed operations), issue stable artifact IDs, and adopt append-only or explicit supersession semantics.
- Gate-based model selection (MDL/AIC) with explicit recording of rejected alternatives
- Sectors: materials science, bioinformatics, applied ML, model governance
- What: Enforce acceptance via description-length or information criteria; pairwise refit of competing models on the same evidence set; record both accepted and rejected models as provenance.
- Tools/workflows: MDL/AIC wrappers around scikit-learn/PyTorch workflows; CategoryScienceClaw gate objects; “paired refit” pipelines.
- Assumptions/dependencies: Clear coding scheme for model and data lengths (MDL); curated evidence sets; versioned data and code; acceptance of non-monotonic scores across iterations.
- Builder/Breaker pattern for stress-testing hypotheses
- Sectors: R&D labs, ML engineering, QA
- What: Introduce “Breaker” agents that generate targeted counterexamples; accept revisions only if they compress enlarged evidence (MDL gain).
- Tools/workflows: BreakingTheWorld codebase; automated test generation; dashboards tracking MDL gains and retractions.
- Assumptions/dependencies: Capability to synthesize stress tests; compute for iterative refits; clear acceptance budget.
- Protein flexibility analysis via mode-conditioned compliance
- Sectors: healthcare/biotech (structural biology, protein engineering), drug discovery
- What: Use the accepted symbolic law (within-chain flexibility ≈ log all-mode elastic compliance × participation in the slowest collective mode) to interpret normalized B-factor patterns, prioritize flexible regions, and generate hypotheses for mutational design.
- Tools/workflows: Compute contact graphs and GNM spectra; implement the law in structural pipelines; cross-check with crystallography or cryo-EM variability measures.
- Assumptions/dependencies: GNM/elastic-network approximations; per-chain normalization of B-factors; law is a constitutive surrogate (not first-principles or absolute-scale predictor); generality across protein classes should be validated.
- Orientation-tensor anisotropic stiffness surrogate for fiber networks
- Sectors: materials, biomechanics, energy (composites, filtration, tissue surrogates)
- What: Prefer anisotropic orientation-tensor descriptors over isotropic fiber-count descriptors for stiffness prediction, as validated by an AIC gate; use in design loops and FE pre-processing.
- Tools/workflows: Compute orientation tensors; integrate surrogate into optimization/simulation pipelines; record gate decisions and rejected alternatives.
- Assumptions/dependencies: Applicability to the target fiber-network class; retraining on domain-specific datasets; documented AIC thresholds.
- Endofunctorial update contracts for refactor-safe pipelines
- Sectors: MLOps, regulated industries (healthcare, aerospace)
- What: Enforce that pipeline updates preserve refinement morphisms: no silent merges/deletes of accepted artifacts; stable IDs; explicit parentage; deterministic supersession records.
- Tools/workflows: Artifact stores (MLflow/DVC/Weights & Biases) with typed schemas; CI checks for refinement-preserving updates; lineage visualizers.
- Assumptions/dependencies: Organizational commitment to auditability; small overhead for ID and lineage governance.
- Schema migration with Kan-extension “transport”
- Sectors: enterprise data platforms, LIMS/ELNs, knowledge graphs
- What: Safely migrate artifacts to new ontologies while preserving provenance via left Kan extension; report residual content that must be newly generated (i.e., what discovery added beyond transport).
- Tools/workflows: Category-theory libraries (e.g., Catlab/AlgebraicJulia) or custom Lan_u implementations; migration playbooks; “transport vs. residual” dashboards.
- Assumptions/dependencies: Defined schema map u:S_b→S_{b′}; ability to compute colimits; careful handling of isolated new types (Lan_u yields empty fibers there).
- Integrated public discourse with provenance-backed claims
- Sectors: academic publishing, open science communities
- What: Link artifact paths to structured posts, hypotheses, votes, and moderation (Infinite), enabling proof-carrying claims and community feedback.
- Tools/workflows: ScienceClaw × Infinite integration; publication maps from provenance paths to discourse objects.
- Assumptions/dependencies: Community participation and moderation; clear policies for preprints and negative results.
- Governance dashboards for model risk and scientific audit
- Sectors: finance (model risk), healthcare AI governance, pharma QA
- What: Expose gate outcomes, retractions, and lineage of accepted models; show “what changed and why” in regime updates.
- Tools/workflows: Audit dashboards fed by category-of-elements provenance; alerts for regime transitions and supersessions.
- Assumptions/dependencies: Mapping audit views to organizational controls; handling of confidential data.
- Education: teach retrieval vs. search vs. discovery with typed artifacts
- Sectors: higher education, professional training
- What: Course modules where students implement schemas, gates, and regime transitions; evaluate discovery cost and residual content.
- Tools/workflows: CategoryScienceClaw assignments; lightweight schemas for classroom domains.
- Assumptions/dependencies: Instructor familiarity with basic category-theoretic constructs; curated datasets.
Long-Term Applications
These uses require further research, scaling, validation, or ecosystem adoption before broad deployment:
- Autonomous, self-revising AI scientists in autonomous labs
- Sectors: pharma, materials/chemistry, physics
- What: Agents that can not only iterate within a schema but also make verified regime transitions, introduce new artifact types, tools, and verifiers, and run targeted experiments.
- Dependencies: Robust gates and safety checks; tight hardware integration; standardized schemas; human oversight for high-stakes decisions.
- Standards for proof-carrying, interoperable scientific graphs
- Sectors: policy, publishing, funding agencies
- What: Community standards for typed schemas, gate definitions, regime-transition proofs, and artifact lineage; journals/funders require submission of proof-carrying graphs alongside manuscripts.
- Dependencies: Consensus across communities; tooling for validation; incentives and mandates.
- Regulatory-grade auditability of AI-driven science
- Sectors: healthcare/biotech (FDA/EMA), energy, aerospace
- What: Map endofunctoriality, gates, and regime transition audits to compliance frameworks; provide verifiable, append-only provenance of decisions and supersessions.
- Dependencies: Alignment with regulatory guidance; validated verifiers; formal risk models for regime changes.
- Discovery-cost metrics for portfolio and funding decisions
- Sectors: R&D management, funding agencies, corporate strategy
- What: Use MDL-based relative costs (e.g., L_{b′}(I′|im(ρ̄))) to quantify the “bit budget” of new results beyond transported evidence; prioritize projects by expected discovery yield.
- Dependencies: Agreed coding schemes; careful handling of domain and size biases; safeguards against metric gaming.
- “Breaker-as-a-Service” and regime-transition audit products
- Sectors: AI safety, model assurance, software tooling
- What: Services that generate adversarial scientific tests and produce regime-transition reports showing transport vs. residual content; plug-ins for agent frameworks.
- Dependencies: Domain-specific stress-test libraries; scalable generation; trust in gates/verifiers.
- Dynamic ontologies for enterprise data platforms via Kan extensions
- Sectors: cloud data platforms, enterprise knowledge management
- What: First-class support for schema evolution with transport and residual tracking; risk-reduced data migrations with provenance guarantees.
- Dependencies: Categorical tooling integrated into data stacks; developer education; performance at scale.
- Typed-agent frameworks with skill signatures and gate-aware planning
- Sectors: AI platforms, agent ecosystems
- What: Agent runtimes that require typed tool signatures, compose only type-safe workflows, and route outputs through gates/verifiers before commitment.
- Dependencies: API standards for typed tools; libraries for typed composition; cultural shift from ad-hoc chains to typed pipelines.
- Multiscale cross-domain evidence transport
- Sectors: materials/biomechanics (micro→meso→macro), systems biology
- What: Formal u:S_b→S_{b′} maps to transport evidence across scales or subfields (e.g., molecular → coarse-grained → continuum), revealing where new measurements are needed (residual content).
- Dependencies: Validated schema maps between scales; scalable colimit computation; benchmark corpora.
- Negative-result memory and exploration guidance
- Sectors: materials, chemicals, drug discovery
- What: Institutional memory of rejected models as first-class artifacts, preventing rediscovery and steering exploration; mining “why rejected” for hypothesis generation.
- Dependencies: IP and confidentiality management; incentives to record failures; search interfaces over rejection provenance.
- Trustable public discourse linking claims, evidence, and community validation
- Sectors: science communication, policy
- What: Platforms where claims are anchored in machine-verifiable provenance and gates, enabling transparent debate and replication markets.
- Dependencies: Governance models, moderation, identity/reputation systems; engagement incentives.
Cross-cutting assumptions and dependencies
- Well-typed domain schemas (S_b) and maintainable tool registries with explicit signatures.
- Stable artifact identifiers, immutable artifacts or explicit supersession, and complete parent lineage.
- Verifiers/gates calibrated to the domain (MDL, AIC, peer review, pressure scoring); access to high-quality evidence sets.
- Category-theoretic operations (e.g., left Kan extension) implemented or wrapped by accessible libraries; compute resources for colimits and iterative refits.
- Cultural adoption of auditability and willingness to record rejections and supersessions.
- For protein/mechanics applications: validity of GNM/elastic-network assumptions for the target proteins; awareness that B-factors reflect multiple phenomena and that the accepted law targets normalized within-chain patterns, not absolute scales.
Glossary
- AIC gate: A model selection gate based on the Akaike Information Criterion used to decide between competing models. "an AIC gate, perturbation tests, and an accepted orientation-tensor anisotropic stiffness surrogate over an isotropic fiber-count descriptor."
- Adjunction: A pair of functors related by a universal correspondence; here, left Kan extension is left adjoint to restriction along a schema map. "By the adjunction , corresponds uniquely to a comparison map"
- Category of elements: For a functor to Set, the category whose objects are pairs of a type and one of its elements and whose morphisms respect the functor’s action; used to realize typed provenance. "The category of elements is the realized typed artifact DAG."
- Colored-operadic: Pertaining to colored operads (multi-typed operads) that model typed multi-input compositions. "typed multicategory or colored-operadic provenance object"
- Colimit: A universal construction generalizing “gluing” or coalescing diagrams; used to compute left Kan extensions of states. "the value is computed as a colimit over the old artifacts that map toward "
- Comma category: An indexing category of morphisms into (or out of) an object used to define Kan extensions and related constructions. "the comma category indexing the colimit is empty"
- Contact graph: A graph on protein residues with edges for pairs within a distance cutoff, capturing structural proximity. "define the contact graph by"
- Copresheaf: A covariant Set-valued functor from a schema category that assigns to each type its current set of artifacts. "the system state is a copresheaf "
- Endofunctor: A functor from a category to itself; here, a fixed-regime update that also preserves refinement morphisms. "It becomes an endofunctor only when it also preserves refinement morphisms"
- Functor category: The category whose objects are functors and whose morphisms are natural transformations between them. "Write for the functor category of copresheaves on ."
- Gaussian Network Model (GNM): A coarse-grained elastic-network model of proteins that explains collective motions and residue fluctuations from structure. "the elastic-network and Gaussian Network Model tradition"
- Kirchhoff matrix: The graph Laplacian (degree minus adjacency) of a contact graph used in GNM to compute modes and compliances. "The GNM Kirchhoff matrix is"
- Kleisli category: The category associated with a monad that captures computations with effects (e.g., stochasticity). "a morphism in a Kleisli category for an appropriate probability monad"
- Left Kan extension: The canonical way to transport or extend a functor along a functor between schema categories. "The old artifact state is transported into the new schema by left Kan extension:"
- Minimum Description Length (MDL): A principle that selects models minimizing the sum of model complexity and data encoding length; used as an acceptance gate. "a Minimum Description Length (MDL) gate"
- Mode-conditioned compliance: A mechanics relation where local elastic compliance is weighted by participation in a slow collective mode. "a “mode-conditioned compliance” relation that appears as a newly admitted interaction type rather than an additional term."
- Multicategory: A generalization of a category allowing morphisms with multiple inputs; used to represent multi-parent provenance. "a multicategorical provenance analogue"
- Natural transformation: A structure-preserving family of maps between functors that commute with all schema morphisms. "A consistent update is a natural transformation or functorial refinement."
- Orientation-tensor anisotropic stiffness surrogate: A reduced-order mechanics model using orientation tensors to represent direction-dependent stiffness. "an accepted orientation-tensor anisotropic stiffness surrogate over an isotropic fiber-count descriptor."
- Probability monad: A monad encapsulating probabilistic effects, enabling categorical treatment of stochastic processes. "a morphism in a Kleisli category for an appropriate probability monad"
- Pseudoinverse: The Moore–Penrose inverse of a matrix; here, its diagonal encodes all-mode compliance in GNM. "The all-mode compliance of residue is the diagonal of the pseudoinverse,"
- Regime transition: A verified change of the representational schema (types, operations, verifiers) under which artifacts are typed. "Discovery is instead a verified regime transition $u:S_b\to S_{b'}}$"
- Representable copresheaf: A functor of the form that captures all operations outgoing from a given type A. "the representable copresheaf encodes all operations that can be applied to a generic artifact of type ."
- Schema category: The category whose objects are artifact types and whose morphisms are allowed operations in a regime. "in a fixed regime with schema category "
- Set-valued functor: A functor assigning sets to objects and functions to morphisms; used to represent typed artifact states. "A scientific state at time is a covariant Set-valued functor"
- Yoneda lemma: A fundamental result identifying elements of a functor’s value with natural transformations from representables. "by the covariant Yoneda lemma"
Collections
Sign up for free to add this paper to one or more collections.