Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
Abstract: Computing has long served as a cornerstone of scientific discovery. Recently, a paradigm shift has emerged with the rise of LLMs, introducing autonomous systems, referred to as agents, that accelerate discovery across varying levels of autonomy. These language agents provide a flexible and versatile framework that orchestrates interactions with human scientists, natural language, computer language and code, and physics. This paper presents our view and vision of LLM-based scientific agents and their growing role in transforming the scientific discovery lifecycle, from hypothesis discovery, experimental design and execution, to result analysis and refinement. We critically examine current methodologies, emphasizing key innovations, practical achievements, and outstanding limitations. Additionally, we identify open research challenges and outline promising directions for building more robust, generalizable, and adaptive scientific agents. Our analysis highlights the transformative potential of autonomous agents to accelerate scientific discovery across diverse domains.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief Overview
This paper is about using smart computer programs, called “autonomous agents,” to help scientists make discoveries faster and more reliably. These agents are powered by LLMs—the same kind of AI that can understand and write text—but they do much more: they read research papers, write code, run simulations, analyze data, and work with human scientists. The authors explain how these agents can guide the whole scientific process, from coming up with ideas, to designing and running experiments, to understanding results and improving them.
Key Objectives and Questions
The paper asks simple but important questions:
- How can AI agents help scientists find new ideas and test them?
- What do these agents need to plan and run experiments on their own?
- How do agents learn from results and get better over time?
- What works well today, what doesn’t, and what should we build next?
The goal is to create AI systems that can safely and effectively speed up science across many fields, like medicine, chemistry, physics, and materials.
Research Methods and Approach
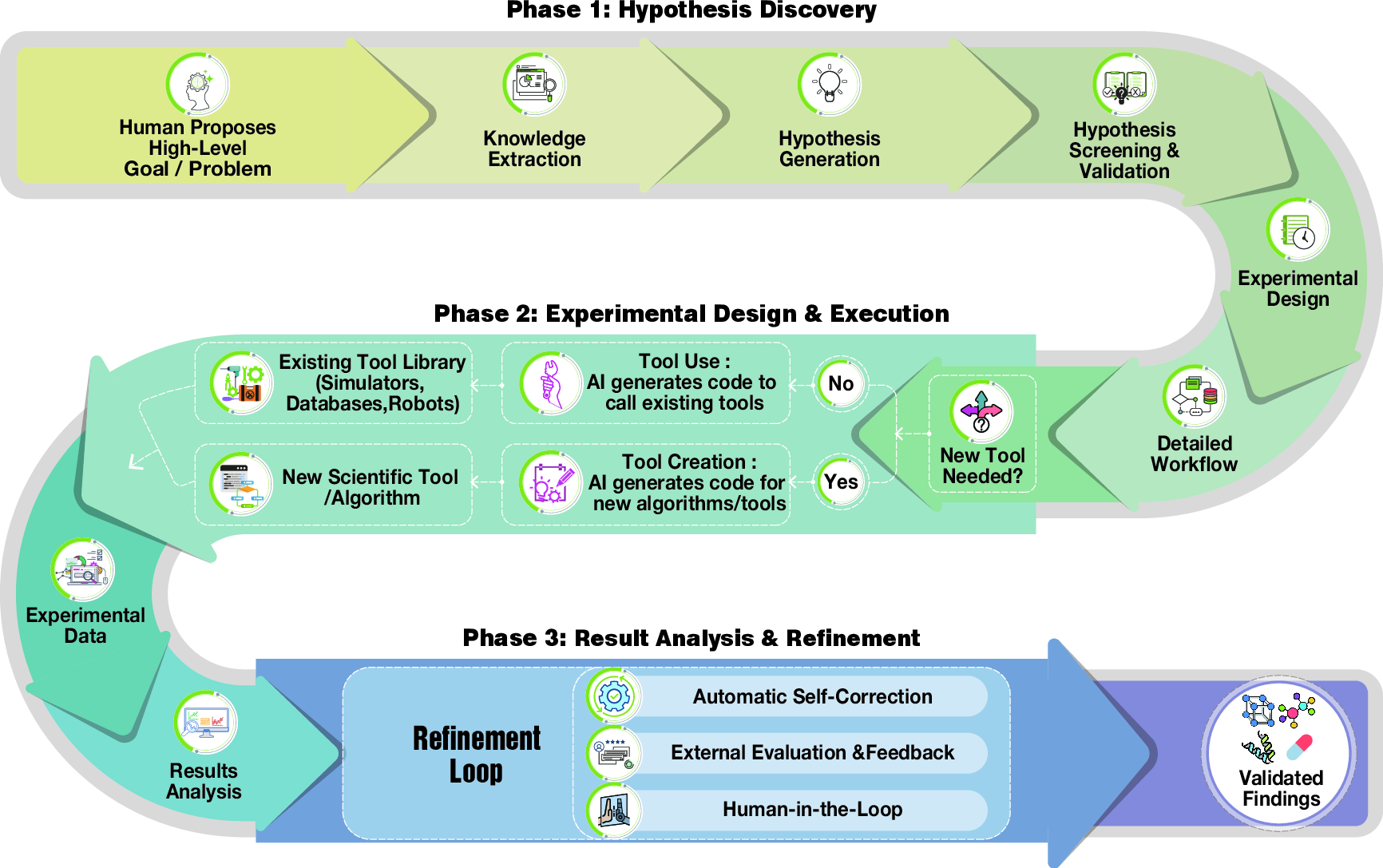
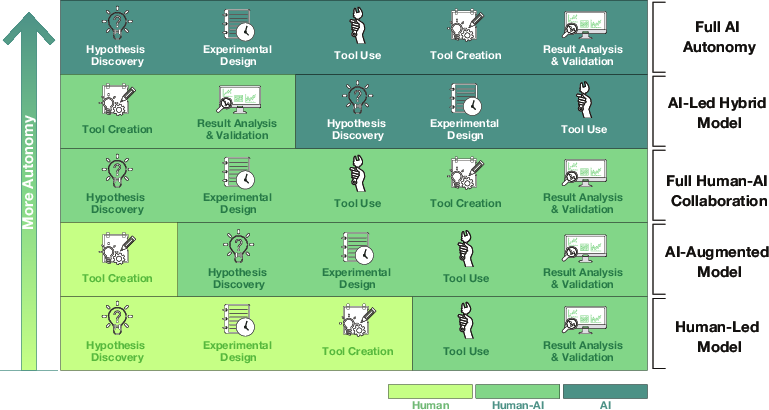
The authors look at many recent projects and organize them into a clear “lifecycle” of scientific discovery with three main phases. Think of it like a detective solving a mystery:
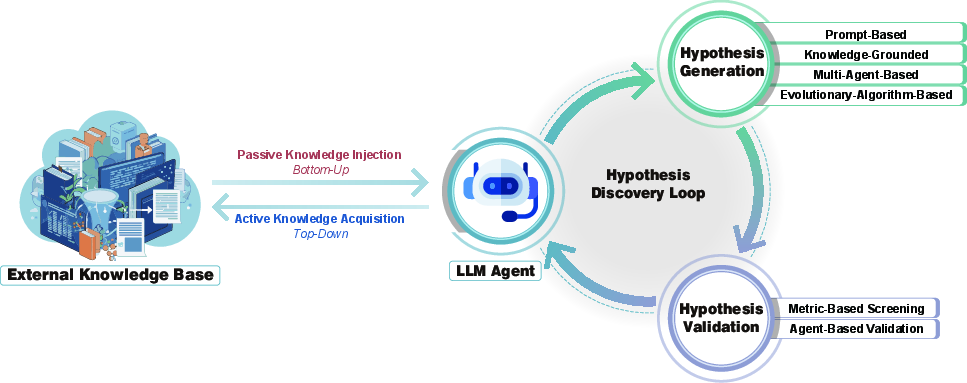
Hypothesis Discovery (coming up with testable ideas)
- Agents read huge amounts of scientific text and data (like a very fast reader taking notes).
- They extract useful facts, connect ideas, and suggest new, testable hypotheses.
- They use different strategies:
- Knowledge extraction: pulling facts from text, images, and charts.
- Hypothesis generation: proposing ideas using prompts, knowledge graphs, multiple cooperating agents, or evolution-like search.
- Screening and validation: checking if ideas are sensible using metrics or agent-driven tests.
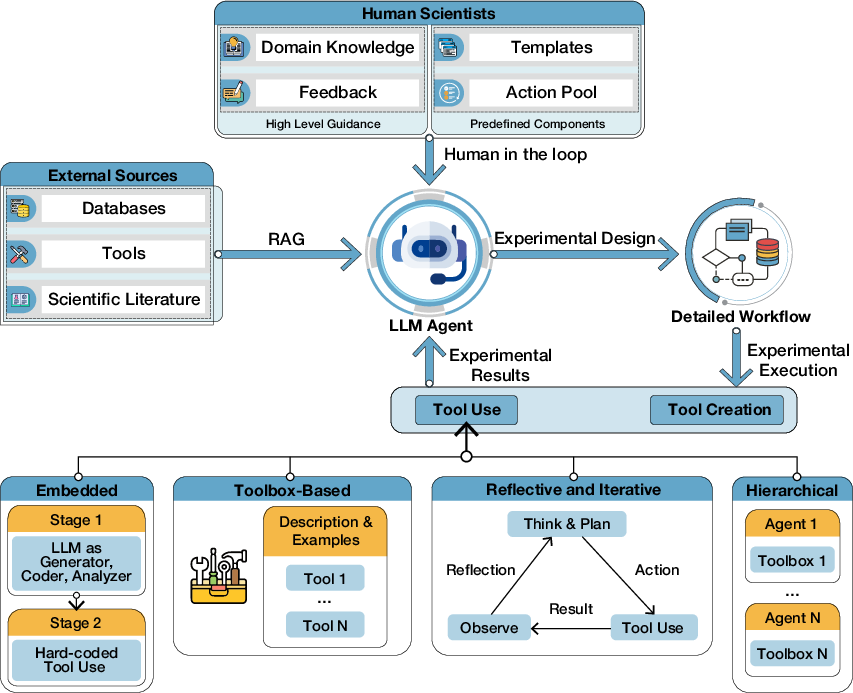
Experimental Design and Execution (building and running the plan)
- Agents turn big goals into step-by-step workflows (like writing a recipe for an experiment).
- They plan using:
- Retrieval of relevant knowledge (RAG), human guidance, templates, and feedback loops.
- Tool use and tool creation:
- Tool use: calling software libraries, simulators, databases, or even lab robots.
- Tool creation: writing new code or making new scientific tools when needed.
Result Analysis and Refinement (understanding outcomes and improving)
- Agents analyze data using:
- Modality-driven methods (e.g., reading charts, images).
- Tool-augmented analysis (calling statistics or visualization tools).
- Computation-native methods (doing math or simulations directly).
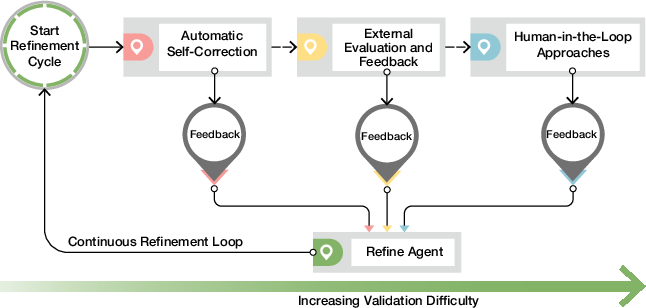
- Iterative refinement:
- Self-correction (fixing their own mistakes).
- External feedback (getting scores or evaluations).
- Human-in-the-loop (scientists guide and review).
- This loop repeats until the results are strong and trustworthy.
A simple way to understand the technical ideas
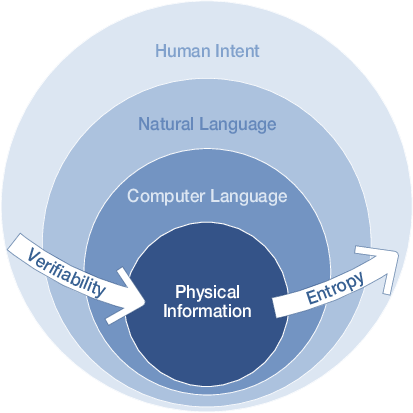
- Entropy: Imagine a messy room full of possible ideas. “Entropy” is how messy and uncertain things are. Agents reduce entropy by turning fuzzy ideas into clear plans and testable code.
- Verifiability: This means “can we test it?” The agent moves from vague human goals to precise code and real data—each step makes things easier to test.
- Dissipation: Some work is wasted while exploring wrong paths. That’s normal in science. Agents try to minimize this by planning better and learning from mistakes.
Main Findings and Why They Matter
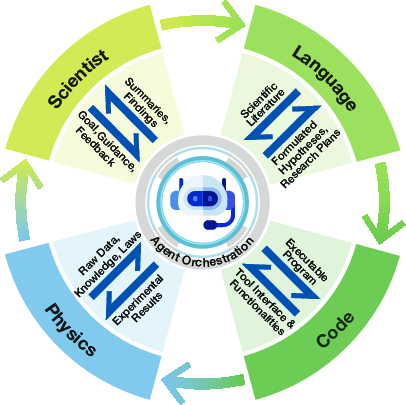
- LLM-based agents can coordinate four key parts of science: scientists (human goals and feedback), language (reading and writing research), code (making and running programs), and physics (collecting and interpreting real-world or simulated data).
- A clear taxonomy: The paper maps out methods used in each phase—how agents find ideas, plan experiments, use and create tools, analyze results, and improve.
- Growing achievements: Many domain-specific agents now help in genomics, protein design, medicine, chemistry, materials, physics, and more.
- Limits and challenges:
- Reliability and trust: Agents can make mistakes or be overconfident.
- Generalization: Doing well across very different scientific fields is hard.
- Data quality: Bad or biased data can mislead agents.
- Real-world integration: Connecting AI plans to physical labs safely is tough.
- Evaluation: We need better benchmarks to measure success in science, not just good text answers.
This matters because better scientific agents could speed up discoveries—like designing new medicines, finding better materials for batteries, or improving climate models—while saving time and money.
Implications and Potential Impact
If we build robust, careful, and well-evaluated scientific agents:
- Scientists could explore more ideas quickly and test them efficiently.
- Research teams could use agents as helpful co-workers: reading, planning, coding, and analyzing at scale.
- Fields like healthcare, clean energy, and environmental science could benefit sooner from new breakthroughs.
But to get there, we need:
- Strong guardrails and safety checks, especially when agents interact with real labs.
- Human oversight and clear accountability.
- Better tests focused on scientific accuracy and reproducibility.
- Continued work on memory, reasoning, and tool creation so agents can learn across projects.
In short, the paper paints a hopeful, realistic picture: AI agents won’t replace scientists, but they can be powerful partners—speeding up the path from “interesting idea” to “proven result.”
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions that future research could address:
- Operationalization of the proposed information-theoretic framework: concrete, computable proxies for entropy, verifiability, and dissipation at each stage (human intent, natural language, code, physical data), with validated estimators and calibration procedures.
- Algorithmic linkage between entropy reduction and planning: planners that explicitly optimize rate of entropy decrease and value-of-information under uncertainty, with empirical comparisons to existing planning heuristics.
- Standardized end-to-end benchmarks simulating the full discovery lifecycle (hypothesis → design → execution → analysis → refinement) with ground truth, budget constraints, and rigorous scoring for novelty, reproducibility, and impact.
- Bridging sim-to-real for wet-lab automation: robust APIs to instruments, calibration protocols, latency/throughput management, and validated sim2real transfer methods beyond purely computational demonstrations.
- Hypothesis novelty assessment: automated metrics to detect rediscovery vs genuine novelty (e.g., citation/knowledge-graph distance, time-aware embeddings) and blinded expert-review protocols.
- Statistical rigor in hypothesis screening: built-in multiple testing correction, preregistration of analysis plans, power/sample-size calculations, and safeguards against p-hacking by autonomous agents.
- Uncertainty quantification across the pipeline: methods to propagate epistemic/aleatoric uncertainty from LLM reasoning, tool outputs, and simulations to decision policies and stopping rules.
- Causal hypothesis generation vs correlation: integration of causal discovery/interventional design and counterfactual reasoning into agentic workflows; evaluation on causal ground-truth benchmarks.
- Reliable multimodal knowledge extraction: datasets and methods to quantify the impact of OCR/diagram/structure-parsing errors on downstream hypotheses and plans; robust extraction under domain-specific notation.
- Literature-grounding robustness in RAG: detection of retractions/conflicts, quality filtering, source provenance, trust calibration, and distribution shift handling for dynamic literature corpora.
- Tool-use orchestration policies: principled selection, sequencing, and fallback strategies; reconciliation of conflicting tool outputs; standardized telemetry and error taxonomies for diagnostics.
- Safety and verification for tool creation: formal specifications, type/unit/dimensionality checks, static/dynamic analysis, property-based testing, sandboxing, and red-teaming for agent-authored tools.
- Lifecycle management of agent-created tools: versioning, provenance, reproducible builds, documentation standards, deprecation criteria, and automated regression testing.
- Physics-grounded code generation: enforcement of conservation laws, boundary/initial conditions, and dimensional consistency; automatic unit checking and symbolic constraints in generated simulations.
- Real-time, closed-loop experimental design: safe Bayesian optimization/multi-fidelity strategies under safety, ethical, and resource constraints; handling delayed/partial feedback and nonstationarity.
- Cost- and carbon-aware planning: explicit compute/reagent/instrument budgets, carbon accounting, and optimization under multi-objective trade-offs (cost, risk, novelty, time).
- Memory at scale: architectures and policies for long-term memory retrieval accuracy, contamination control (self-referential loops), forgetting, privacy/IP protection, and auditability.
- Human-in-the-loop protocols: principled escalation criteria, uncertainty/explanation presentation, oversight interfaces, and controlled user studies to quantify when and how human guidance improves outcomes.
- Multi-agent collaboration mechanisms: role specialization, communication/argumentation protocols, consensus formation, prevention of groupthink/echoing, and benchmarks for emergent team behaviors.
- Provenance and reproducibility: standardized machine-readable lab notebooks, workflow capture (parameters, environments, seeds), data lineage, and minimal information standards for autonomous studies.
- Cross-domain and cross-lab generalization: tool-agnostic protocol representations, shared ontologies (materials/biol/chem), and domain adaptation methods for heterogeneous instruments and settings.
- Adversarial and spurious input robustness: defenses against prompt injection, malicious datasets/APIs, jailbreaks in hardware control, and integrity checks for third-party tools.
- Governance and safety for physical control: formal safety envelopes, hazard models, fail-safe stop conditions, interlocks, and incident reporting for bio/chem/engineering domains.
- Ethical, legal, and regulatory compliance: automated checks for IRB/animal-use, biosafety levels, export controls, clinical regulations (HIPAA/GDPR), and compliant audit trails.
- Bias, equity, and representativeness: measurement and mitigation of biases in scientific foundation models and literature sources that skew hypothesis generation and screening.
- Exploration–exploitation control and stopping criteria: principled halting rules, experiment prioritization under uncertainty, and value-of-information-aware scheduling.
- Systematic capture of negative results: standardized repositories and incentives to reduce dissipation via reuse of failed trials and avoidance of redundant exploration.
- Comparative evaluations of design strategies (RAG vs templates vs human-guided): ablations clarifying when each approach excels, typical failure modes, and hybrid strategies.
- Success metrics for scientific agents: beyond task completion to novelty, reproducibility, real-world impact, and time-to-insight; longitudinal studies of agent-enabled discoveries.
- Interoperability standards: secure, unified schemas/APIs for simulators, lab instruments, analysis tools, and knowledge bases; capability discovery and access control.
- Data licensing and IP attribution: mechanisms to track contributions of humans vs agents, licensing of generated artifacts, credit assignment, and citation of agent-created tools/protocols.
- Handling nonstationarity: methods for continual learning with safety guarantees under changing tools, instrument drift, and evolving literature.
- Reconciling with established theory: mechanisms to detect and justify departures from well-validated laws vs proposing paradigm shifts; structured argumentation and evidence grading.
- Explainability and scientific traceability: end-to-end, human-auditable chains from intent to code to data to conclusions; counterfactual and ablation-based explanations.
- Measuring and minimizing dissipation: empirical metrics of wasted compute/experiments; cross-agent sharing of failed paths; policies to reduce redundant trials.
- Hybrid wet-lab/simulation evaluation: benchmarks and protocols to quantify sim2real gaps, transfer strategies, and calibration of simulated insights with physical experiments.
- Secure software supply chain for agent-generated code: dependency vetting, SBOMs, reproducible builds, and runtime isolation in lab control environments.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today using the paper’s surveyed methods and orchestration framework (scientists–language–code–physics), with sector links, likely tools/products/workflows, and feasibility notes.
- Strongly grounded literature copilots for hypothesis ideation (academia, biotech/pharma)
- What it does: Retrieve, synthesize, and contrast evidence to propose testable, well-scoped hypotheses and identify research gaps.
- Tools/workflows: RAG and knowledge-grounded prompting over domain corpora; entity/relationship extraction into scientific knowledge graphs; multimodal extraction from charts/figures.
- Representative stack: BioGPT/BioBERT/Galactica + RAG pipelines (e.g., CLADD, CASSIA) + multimodal extractors (ChartAssistant, ChartLlama).
- Assumptions/dependencies: Access to up-to-date literature and licenses; citation-grounding and hallucination mitigation; domain ontologies/IDs; provenance tracking.
- Multimodal knowledge mining from papers and data repositories (chemistry, materials, biology)
- What it does: Converts PDFs, figures, spectra, and tables into structured, queryable knowledge bases to power downstream discovery.
- Tools/workflows: OCR + table/figure parsers; chemical/materials entity/linking; automated schema population for KGs.
- Representative stack: ChartAssistant/PlotGen, ChemMiner, MatViX; KG population workflows.
- Assumptions/dependencies: Parsing accuracy and template variability; data licensing and FAIR compliance; benchmarked extraction quality.
- Experimental design planners with templates and predefined actions (academia, CROs)
- What it does: Turn high-level goals into stepwise protocols with parameters, controls, and measurement plans; surface relevant prior art.
- Tools/workflows: Prompt-based or RAG planning; curated protocol templates and action libraries; human high-level guidance.
- Representative stack: Template- and RAG-based planners (e.g., CRISPR-GPT-style planning), tool-augmented checks (TxAgent).
- Assumptions/dependencies: Domain ontologies for actions and units; human-in-the-loop sign-off; institutional SOPs.
- Agentic code generation and execution for simulations and analysis (physics/engineering/materials)
- What it does: Generate, run, and validate simulation or analysis scripts; automate configuration sweeps and unit checks.
- Tools/workflows: CodePDE, OpenFOAMGPT/MetaOpenFOAM; containerized environments; auto-validation against specs.
- Assumptions/dependencies: Reproducible compute (containers/HPC), test harnesses, data versioning; simulator licenses.
- Toolbox-based bio/chem informatics orchestration (software, life sciences)
- What it does: Chain specialized tools (BLAST, RDKit, AlphaFold, docking) via LLM agents to produce end-to-end results with rationale.
- Tools/workflows: ChemCrow/ChemToolAgent, Bioinformatics Agents, SciToolAgent; tool catalogs (ToolUniverse) and API connectors.
- Assumptions/dependencies: Tool/API availability and rate limits; parameter validation; security sandboxing.
- Automated result analysis and scientific reporting (academia, education, industry R&D)
- What it does: Clean data, perform standard stats, generate plots, interpret findings, and draft method/results sections.
- Tools/workflows: Modality-driven analysis (Data Interpreter, PlotGen); tool-augmented statistical checks; reproducible notebooks.
- Assumptions/dependencies: Data quality/metadata; statistical guardrails and p-hacking prevention; versioned outputs.
- Iterative refinement with external evaluators and human-in-the-loop (all sectors)
- What it does: Apply self-refine, critic models, or expert feedback to improve hypotheses, code, and experimental plans across iterations.
- Tools/workflows: Self-Refine/CRITIC; review loops; structured feedback forms; agent memory for cumulative learning.
- Assumptions/dependencies: Reviewer availability; clear acceptance criteria; memory persistence and provenance.
- Domain copilots for practitioners (healthcare, geospatial, medicine)
- What it does: Task-specific assistance for clinical Q&A (AgentMD/ClinicalGPT), GIS analysis (GIS Copilot), or therapeutics curation (TxAgent).
- Tools/workflows: Secure RAG over guidelines/registries; code execution for geospatial processing; explanation layers for trust.
- Assumptions/dependencies: Privacy (HIPAA/GDPR), access controls, regulatory boundaries; bias auditing; audit trails.
- Reproducibility and protocol compliance checkers (journals, CROs, institutional QA)
- What it does: Cross-check reported methods and results against standards; verify code–data congruence and re-run pipelines.
- Tools/workflows: Computation-native validation; containerized re-execution; checklist generation for reviewers.
- Assumptions/dependencies: Access to raw data/code; compatible environments; community-agreed checklists.
- Materials/chemistry candidate triage via metric-based screening (materials, energy, catalysis)
- What it does: Rank candidates using pre-trained property predictors and rule-based filters to reduce the hypothesis space.
- Tools/workflows: Metric-based screening (e.g., POPPER-like), domain property models; batch evaluation orchestrated by agents.
- Assumptions/dependencies: Predictor calibration; domain-valid ranges; dataset shift monitoring.
- Research portfolio scouting and funding triage (policy, finance, corporate R&D)
- What it does: Map literature trends, identify white spaces and high-potential directions; align with strategic priorities.
- Tools/workflows: Multi-agent synthesis (ResearchAgent-like), bibliometrics, knowledge graphs; dashboards for program officers.
- Assumptions/dependencies: Database access (Scopus/PubMed/ArXiv); robust novelty/impact scoring; expert oversight.
- Education and training assistants for the scientific method (education, workforce upskilling)
- What it does: Coach on hypothesis formation, protocol critique, data interpretation; grade lab reports with rubrics.
- Tools/workflows: Domain-aligned prompting; sandboxed data; rubric-anchored evaluation.
- Assumptions/dependencies: Academic policy alignment; minimizing leakage/plagiarism; calibrated feedback.
Long-Term Applications
These use cases require additional research, integration with physical systems, rigorous validation, or regulatory/scaling work before broad deployment.
- Fully autonomous closed-loop labs for discovery (biotech/pharma/materials/energy)
- What it does: AI plans, operates robotic instruments, analyzes results, and iterates to optimize targets (e.g., catalysts, battery materials, leads).
- Tools/workflows: Multi-agent planners; robotic lab orchestration; active learning; digital twins.
- Assumptions/dependencies: Standardized instrument APIs; lab safety and fail-safes; reliability under distribution shift; regulatory and biosafety compliance.
- AI co-scientist teams with collective intelligence (academia, industry R&D)
- What it does: Multi-agent systems emulate research groups (PI/postdoc/student roles) to propose, debate, and execute research programs.
- Tools/workflows: Role-specialized agents; debate/consensus protocols; credit assignment and accountability frameworks.
- Assumptions/dependencies: Governance and authorship norms; alignment and conflict resolution; reproducibility guarantees.
- On-the-fly scientific tool creation and evolution (software, all sciences)
- What it does: Agents invent, test, and maintain new domain tools/solvers automatically (e.g., PDE solvers, analysis modules).
- Tools/workflows: TOOLMAKER/ToolUniverse/ShinkaEvolve; automated benchmarking; sandboxed execution and security vetting.
- Assumptions/dependencies: Strong verification harnesses; formal specs; supply-chain security and licensing.
- Autonomous clinical discovery and decision support (healthcare, public health)
- What it does: Generate cohort-specific hypotheses, propose stratified interventions, simulate outcomes, and design pragmatic trials.
- Tools/workflows: Privacy-preserving RAG over EHRs/registries; causal inference engines; trial simulation and protocol drafting.
- Assumptions/dependencies: Regulatory clearance (FDA/EMA), bias and safety monitoring, patient consent frameworks, rigorous prospective validation.
- Persistent scientific memory and communal knowledge graphs (infrastructure, academia)
- What it does: Cross-project, cross-institution memory that captures hypotheses, failures, protocols, and outcomes for cumulative learning.
- Tools/workflows: Long-term agent memory; FAIR-compliant KGs; provenance/lineage tracking; interop standards.
- Assumptions/dependencies: Data stewardship, privacy/IP agreements, community ontologies and schemas.
- Physics-grounded reasoning and automated theory generation (physics, engineering)
- What it does: Couple symbolic/axiomatic physics with executable code to derive, test, and refine candidate laws or governing equations.
- Tools/workflows: Neuro-symbolic stacks; proof assistants; differentiable simulators; code generation with formal verification.
- Assumptions/dependencies: Benchmark suites; proof-checking at scale; managing model–reality gaps.
- Autonomous peer review and reproducibility auditing at scale (publishing, funders)
- What it does: Pre-screen manuscripts/grants for methodological rigor, statistical validity, code/data reproducibility, and ethical compliance.
- Tools/workflows: Re-execution pipelines; statistical audit agents; structured review generation.
- Assumptions/dependencies: Community acceptance; legal/liability considerations; standardized artifacts from authors.
- Science–policy simulation and funding optimization (government, philanthropy)
- What it does: Forecast research trajectories, simulate policy/scenario impacts (e.g., incentives, safety rules) and optimize portfolio allocations.
- Tools/workflows: Causal models; agent-based simulations; multi-objective optimization tied to societal outcomes.
- Assumptions/dependencies: Reliable socio-technical data; transparency; stakeholder governance.
- Massively scalable “lab-in-the-cloud” education with remote/virtual labs (education, workforce)
- What it does: Provide learners with autonomous experimentation via high-fidelity simulators and shared robotic instruments.
- Tools/workflows: Virtual Lab platforms; booking/orchestration systems; assessment agents.
- Assumptions/dependencies: Infrastructure costs; equitable access; safety and device wear management.
- Autonomous energy and environmental discovery loops (energy, climate, geospatial)
- What it does: Discover catalysts, membranes, and materials; orchestrate satellite/GIS and sensor networks for monitoring and causal attribution.
- Tools/workflows: DFT/MD + robotics loops; GIS agents with field sensor feedback; active sampling strategies.
- Assumptions/dependencies: HPC capacity; sensor/robot APIs; model robustness to non-stationarity.
- IP generation, prior-art search, and patent drafting grounded in evidence (legal, industry R&D)
- What it does: Draft patent claims and specifications linked to verifiable data; quantify novelty vs. prior art.
- Tools/workflows: Patent corpora RAG; claim consistency checkers; evidence linking.
- Assumptions/dependencies: Legal acceptance; hallucination control; conflict-of-interest and disclosure management.
- Embedded safety, ethics, and compliance overseers for autonomous labs (all regulated domains)
- What it does: Real-time risk assessment, containment policies, and compliance checks during agent-driven experiments.
- Tools/workflows: Safety policies as code; anomaly detection; kill-switch governance.
- Assumptions/dependencies: Standardized safety ontologies; regulator-auditable logs; explainability.
- Open marketplaces for scientific tools, datasets, and workflows (software ecosystems)
- What it does: Curated exchanges (à la ToolUniverse) where agents discover, evaluate, and compose tools/datasets with trust signals.
- Tools/workflows: Reputation/verification systems; semantic search; automated benchmarking.
- Assumptions/dependencies: Interoperability standards, licenses, IP models; security and quality assurance.
Cross-cutting feasibility notes
- Data access and quality: Many applications hinge on licensed, up-to-date literature, well-annotated datasets, and FAIR repositories.
- Tool and instrument integration: Stable APIs, standardized schemas, and containerized/hardened runtimes are pivotal for reliable orchestration.
- Grounding and verifiability: Citation grounding, unit/constraint checks, statistical rigor, and formal verification are needed to counter hallucination.
- Governance and compliance: Human oversight, audit trails, and sector-specific regulations (e.g., FDA, biosafety, privacy) determine deployment scope.
- Cost and scaling: Compute budgets (HPC/GPUs), benchmarking culture, and MLOps for agents (memory, provenance, drift monitoring) impact sustainability.
Glossary
- Agent-Based Validation: A validation strategy where autonomous agents test, critique, or replicate hypotheses/results to assess reliability. "Agent-Based Validation"
- Computation-Native: Approaches that rely primarily on in-model or programmatic computation (rather than external tool augmentation) to analyze and reason over results. "Computation-Native"
- Dissipation: The unavoidable cost (time, energy, computation) expended on unproductive explorations during scientific search, tied to irreversible information operations. "Dissipation refers to the unavoidable computational cost and effort expended on unproductive paths during the exploration of a problem space."
- Dissipative process: A process in which useful energy or informational order is irreversibly lost; here, the intrinsic trial-and-error nature of discovery. "an inherently dissipative process"
- Evolutionary Algorithm-Based: Methods that generate or refine hypotheses/solutions via evolutionary algorithms (e.g., mutation, selection). "Evolutionary Algorithm-Based"
- Human-in-the-Loop: Systems that explicitly incorporate human oversight, feedback, or decisions within autonomous workflows. "Human-in-the-Loop"
- Hypothesis space: The set of all possible hypotheses/solutions under consideration for a problem. "the size of the hypothesis space of a given problem."
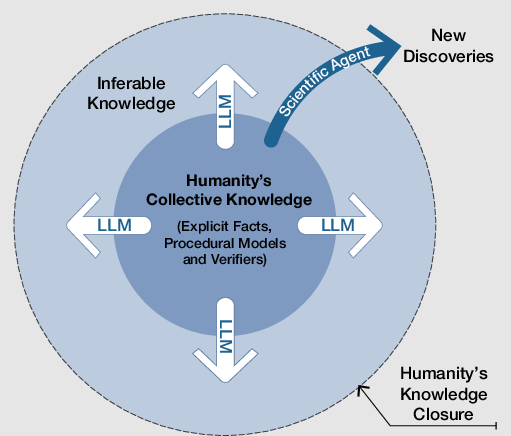
- Information Entropy: A quantitative measure of uncertainty or hypothesis space size used to characterize and reduce ambiguity in discovery. "Information Entropy is a mathematical measure from information theory that quantifies the uncertainty or the size of the hypothesis space of a given problem."
- Information-theoretic framework: An analytic perspective that models discovery in terms of entropy, verifiability, and their transformations across stages. "An information-theoretic framework for autonomous scientific discovery, illustrating the inverse relationship between Information Entropy and Verifiability."
- Isolated system: A thermodynamic system that exchanges neither energy nor matter with its surroundings; its entropy cannot decrease. "the total entropy of an isolated system can never decrease"
- Knowledge graph: A structured graph of entities and relations used to encode and query domain knowledge. "knowledge graph construction"
- Knowledge-Grounded: Methods that anchor generation and reasoning to explicit external knowledge sources (e.g., databases, KGs). "Knowledge-Grounded"
- Landauer's Principle: A physical principle stating that irreversible information operations require a minimum amount of energy dissipation. "The Landauer's Principle dictates that any irreversible information operation must be accompanied by a minimum energy dissipation."
- Metric-Based Screening: Filtering candidate hypotheses or plans using predefined quantitative metrics before deeper evaluation. "Metric-Based Screening"
- Modality-Driven: Analysis or workflows centered on specific data modalities (e.g., plots, text, code) to interpret results. "Modality-Driven"
- Multi-agent systems: Collections of interacting agents whose coordinated behaviors can yield capabilities beyond a single agent. "multi-agent systems can achieve a collective intelligence that surpasses the capabilities of a single agent"
- Open system: A system that exchanges energy, matter, or information with its environment; necessary for entropy reduction in discovery. "an open system"
- Physical Information: Empirical data directly obtained from the physical world (or faithful simulations) used to verify hypotheses. "Physical Information is the raw, empirical data gathered directly from the physical world."
- Physics of Information: The study of how information processing is governed by physical laws, linking computation and thermodynamics. "the Physics of Information."
- Prompt-Based: Techniques that rely on careful prompt design to guide LLMs for hypothesis generation or planning. "Prompt-Based"
- RAG (Retrieval-Augmented Generation): A method where generation is conditioned on retrieved external documents to ground outputs in evidence. "RAG-based Planning"
- Scientific Foundation Models: Foundation models specifically trained or adapted for scientific domains and tasks. "Scientific Foundation Models"
- Second Law of Thermodynamics: The law stating that entropy of an isolated system cannot decrease, framing limits on entropy reduction. "the Second Law of Thermodynamics"
- Tool-Augmented: Approaches that enhance LLMs with external tools (e.g., calculators, simulators) for analysis and execution. "Tool-Augmented"
- Verifiability: The extent to which information can be objectively tested against formal, logical, or empirical standards. "Verifiability is a property of a specific information object that measures its ability to be objectively tested against a formal, logical, or empirical standard"
Collections
Sign up for free to add this paper to one or more collections.

