VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation
Abstract: Humanoid loco-manipulation in unstructured environments demands tight integration of egocentric perception and whole-body control. However, existing approaches either depend on external motion capture systems or fail to generalize across diverse tasks. We introduce VisualMimic, a visual sim-to-real framework that unifies egocentric vision with hierarchical whole-body control for humanoid robots. VisualMimic combines a task-agnostic low-level keypoint tracker -- trained from human motion data via a teacher-student scheme -- with a task-specific high-level policy that generates keypoint commands from visual and proprioceptive input. To ensure stable training, we inject noise into the low-level policy and clip high-level actions using human motion statistics. VisualMimic enables zero-shot transfer of visuomotor policies trained in simulation to real humanoid robots, accomplishing a wide range of loco-manipulation tasks such as box lifting, pushing, football dribbling, and kicking. Beyond controlled laboratory settings, our policies also generalize robustly to outdoor environments. Videos are available at: https://visualmimic.github.io .




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation”
1. What is this paper about?
This paper is about teaching a humanoid robot to use its whole body (hands, feet, head, shoulders, and balance) to interact with objects it sees through its own camera. The robot learns in a computer simulation first and then uses the same skills in the real world. The goal is for the robot to do human-like tasks such as pushing a big box, lifting a smaller box, dribbling a football, and kicking objects—using vision and smart control, not special lab equipment.
2. What questions were they trying to answer?
The researchers wanted to know:
- How can a humanoid robot use what it sees (its own camera view) to guide its whole body during difficult tasks like pushing or kicking?
- Can we train the robot in simulation and then have it work well in the real world without extra sensors or special setups?
- How do we make the robot’s movements look and feel human-like, while also being strong and stable?
- How can we keep training stable and safe, so the robot doesn’t try weird or dangerous actions?
3. How did they do it?
They built a “two-level brain” for the robot and trained it in stages, using simple ideas and common-sense tricks to keep things stable.
- Two-level control (think “manager and worker”):
- Low-level “keypoint tracker” (the worker): This part controls the robot’s body and follows simple target positions for important body points—called “keypoints”—like the root (hips), hands, feet, and head. If you say “move your hands here and your feet there,” the tracker makes the body do it smoothly and in a human-like way.
- High-level “keypoint generator” (the manager): This part looks at the robot’s camera view and its own body sense (proprioception—like knowing where your arms and legs are) and decides what the keypoints should be next to achieve the task (e.g., “move hands to the front of the box,” “aim your foot to the ball”).
- Teacher–student training (like a coach teaching a player), used twice:
- Teacher motion tracker: A powerful controller gets to see “future” motion and full body details, so it can follow human motion perfectly in simulation.
- Student keypoint tracker: A simpler controller learns to copy the teacher using only the keypoint targets and body sensing. The result: a general, reusable, human-like “worker” that can follow keypoint commands across many tasks.
- 2) For the high-level manager:
- Teacher state-based policy: First, train a manager that can see the exact object positions (privileged info) so it learns tasks quickly.
- Student vision policy: Then teach a manager that uses only the robot’s own camera (depth images) and body sensing. This one runs on the real robot.
- Making simulation feel more like the real world:
- Sim-to-real: Train in a virtual world, then use the same policy on the real robot.
- Depth vision only: They use depth images (how far things are) instead of color images to reduce differences between simulation and reality.
- Heavy masking: In simulation, they randomly block parts of the depth image to mimic real camera noise.
- Camera angle randomization: Slightly vary the camera view during training to match real-world wiggles.
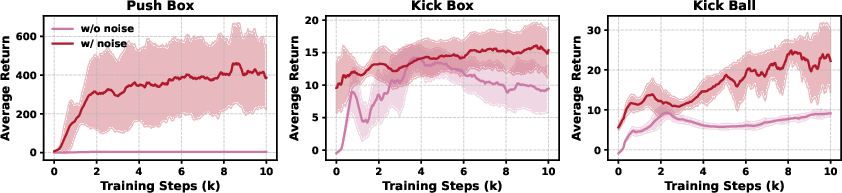
- Keeping training stable and safe:
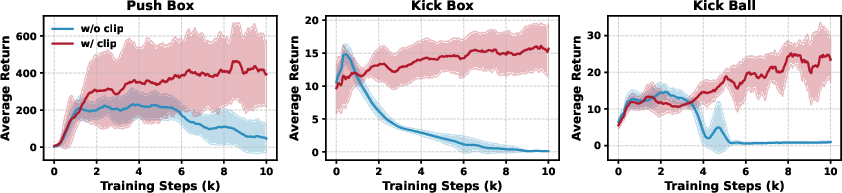
- Action clipping: Limit the manager’s commands to human-like ranges so it doesn’t ask for impossible or unsafe motions.
- Noise injection: Add noise to the worker’s training commands so it becomes robust to imperfect instructions.
- Binary start/pause command: A simple “0 or 1” signal lets the robot safely pause or resume in the real world.
4. What did they find and why is it important?
- Real-world success without extra lab gear:
- The robot could lift a 0.5 kg box to about 1 meter high.
- It pushed a large 3.8 kg box (as tall as the robot) straight and steadily using different parts of its body.
- It dribbled a football smoothly, like an experienced player.
- It kicked boxes forward using alternating feet.
- It worked outdoors too, handling changes in lighting and uneven ground.
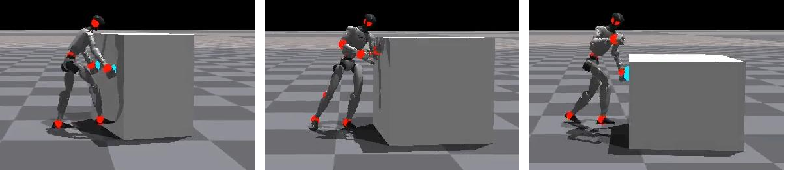
- Whole-body strategies, like humans:
- The robot naturally used hands, feet, shoulders, and posture depending on the situation. For example, it bent down to push with both hands on low-friction ground, and leaned with its shoulder when more force was needed. That’s the “whole-body dexterity” they wanted.
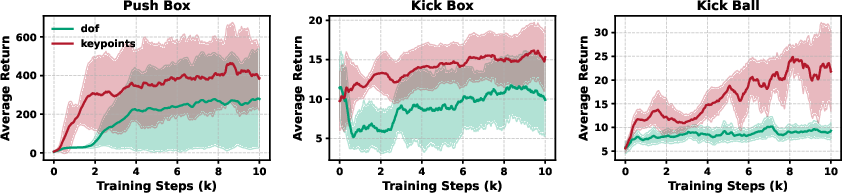
- Vision matters:
- When they trained the manager without vision, performance dropped a lot. With vision, the robot found and interacted with objects more accurately.
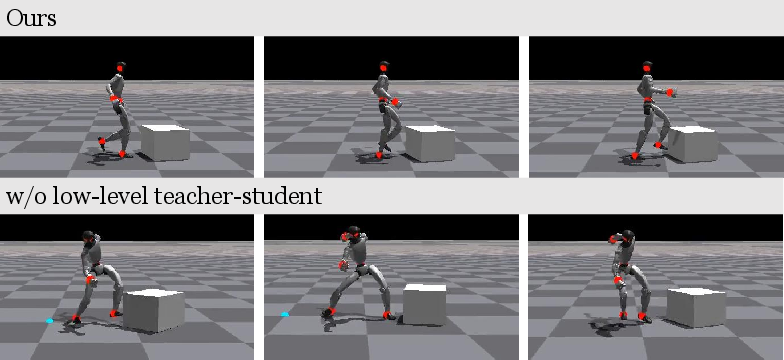
- Stable training and human-like movement:
- The teacher–student approach made movements look human-like and reduced jitter.
- Action clipping and noise injection prevented unstable learning and weird actions.
This is important because it shows that complex robot behavior can be learned and transferred to real machines without relying on motion-capture systems or huge human demonstration datasets. It brings robots closer to practical, everyday abilities.
5. Why does this matter for the future?
VisualMimic suggests a strong recipe for training humanoid robots:
- Use a two-level brain with simple, expressive commands (keypoints).
- Learn from human motion to make behaviors human-like.
- Train with teachers first, then distill to vision-only students.
- Carefully bridge the gap between simulation and reality.
If extended, this could help robots work in homes, warehouses, and outdoors—moving and manipulating objects safely and flexibly. The authors note limits: they didn’t tackle squishy or deformable objects, teamwork with humans, or very long, complex tasks. But their approach is a solid step toward robots that see, move, and interact more like we do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide targeted follow-up research.
- Task generality: The high-level policy is trained per task; there is no evaluation of a single multi-task policy or goal-conditioned policy that can perform varied loco-manipulation behaviors without retraining.
- Object diversity: Real and simulated objects are limited to boxes, a ball, and a tabletop cube; generalization to deformable, articulated, or irregularly shaped objects (and wider mass/inertia ranges) is untested.
- Fine manipulation: The keypoint interface (root, head, hands, feet) uses position-only commands with no end-effector orientation or finger DOFs, leaving grasping, tool-use, and orientation-critical contacts unexplored.
- Multi-contact and contact scheduling: The framework does not study explicit contact sequence planning or scheduling (e.g., switching between hands/feet or multi-limb contacts in cluttered scenes).
- Vision modality constraints: Depth-only perception avoids RGB sim-to-real issues, but the trade-off versus multi-modal inputs (RGB, stereo, LiDAR) for richer semantics and robustness is unquantified.
- Perception robustness: Handling of occlusions, dynamic lighting (e.g., outdoor sun), specular surfaces, multi-path interference, and cluttered multi-object scenes is not systematically evaluated.
- Explicit 3D perception: The student policy does not estimate object pose/velocity; the value of explicit geometric perception (segmentation, tracking, pose estimation, point-cloud registration) is not compared.
- Physics gap alignment: Beyond friction randomization and masking, there is no system identification or physics parameter calibration; the sensitivity of sim-to-real transfer to unmodeled dynamics remains unknown.
- Force and tactile sensing: Real-world deployment uses no object force or tactile feedback, yet tasks (pushing, kicking, lifting) are force-critical; benefits of integrating tactile/force sensors are unstudied.
- Safety and recovery: The binary pause mechanism is minimal; formal safety constraints, reflexes for imminent falls, collision avoidance, and recovery behaviors are not designed or evaluated.
- Long-horizon autonomy: Tasks are short and single-stage; the framework is not assessed on multi-step, long-horizon sequences requiring memory, planning, or explicit subgoal management.
- Adaptation post-deployment: Policies are zero-shot; there is no online adaptation, residual learning, or closed-loop sim-to-real fine-tuning on hardware to correct biases or drift.
- HMS clipping design: Action clipping uses independent Gaussian bounds per command dimension; correlations between keypoints are ignored. Learning a structured HMS manifold (e.g., generative priors, diffusion models) is not explored.
- Exploration outside HMS: The impact of clipping on learning harder tasks that require commands beyond the human motion distribution (e.g., unusual contacts or extreme reaches) remains unquantified.
- Command noise schedule: Low-level multiplicative noise (uniform 0.5–1.5) is fixed; scheduling, task-specific noise shaping, or adversarial command augmentation for robustness is not studied.
- Teacher-student distillation details: DAgger implementation specifics (mixture policy ratios, data aggregation strategy, intervention thresholds) and their effects on covariate shift are not reported or analyzed.
- Privileged teacher assumptions: The low-level teacher uses future motion frames; how distillation behaves when future information is unavailable or partial (more realistic training) is not investigated.
- World vs local frame: World-frame tracking improves drift but may degrade on slopes or uneven terrain; systematic evaluation of frame choices under varied terrains (inclines, stairs) is missing.
- Motion dataset coverage: The low-level tracker is trained on retargeted AMASS/OMOMO motions without paired human–object datasets; how limited contact-rich human-object data affects complex interactions is unaddressed.
- Quantitative real-world metrics: Real deployment is demonstrated qualitatively; consistent quantitative measures (success rates, drift, object displacement, failure/near-fall counts) across environments are not reported.
- Baseline breadth and fairness: There is no apples-to-apples quantitative comparison against strong sim-to-real visuomotor baselines on the same hardware and tasks (e.g., state-of-the-art hierarchical RL or model-based controllers).
- Scalability and compute: Training time, sample complexity, and compute costs (especially for the teacher policies and distillation stages) are not disclosed, limiting reproducibility and practical scaling guidance.
- Hardware generalization: The low-level tracker is trained for one humanoid; transfer across different morphologies and actuation (e.g., other humanoids, exoskeletons) using the same keypoint interface is untested.
- Camera calibration drift: RealSense tilt drift is mitigated via randomization, but online self-calibration and its effect on performance/stability are not studied.
- Failure mode analysis: Systematic categorization of failure cases (e.g., misperception, unstable contacts, controller saturation) and targeted mitigation strategies is missing.
Practical Applications
Overview
Based on the paper’s contributions—a hierarchical sim-to-real framework that fuses egocentric depth perception with a reusable, task-agnostic whole-body keypoint tracker and a task-specific keypoint generator (trained via teacher–student distillation, action clipping to a Human Motion Space, and noise-robust interfaces)—the following are actionable applications across industry, academia, policy, and daily life. Each item lists sectors, potential tools/products/workflows, and feasibility dependencies or assumptions.
Immediate Applications
- Humanoid-assisted light-material handling and re-staging
- Sectors: logistics and warehousing, retail, events, facilities management
- What: Repositioning small/light boxes (≈0.5–4 kg), nudging crates, straight pushing to align items to conveyors, shelves, or staging zones; outdoor re-positioning on uneven ground
- Tools/workflows: Visuomotor policy packs for “push box,” “lift small box,” reusable low-level keypoint tracker SDK; a “task authoring” loop that trains only the high-level policy per new object/task; on-robot pause/execute binary safety command
- Dependencies: Humanoid hardware with comparable morphology/dynamics (e.g., Unitree G1-class), depth camera, environments where rigid objects and friction ranges are close to those randomized in sim; safety perimeter and fall protection
- Last-meter nudging and alignment
- Sectors: parcel logistics, airports, manufacturing kitting cells
- What: Precisely nudging totes/carts into docking positions; line-side material alignment; “final centimeter” adjustments before automated handling
- Tools/workflows: Depth-only perception policies (privacy-preserving) with HMS action clip for stable, repeatable micro-motions; calibration-free deployment via heavy depth masking augmentation
- Dependencies: Fixed camera mounting (small angular drift randomized at train time), predictable rigid geometries; safety interlocks
- Retail facing and floor reset support
- Sectors: retail
- What: Pushing lightweight floor fixtures, repositioning promotional displays, tidying and aligning stock boxes on the floor
- Tools/workflows: Pretrained “push straight with drift penalty” policy; store-specific friction domain randomization profiles
- Dependencies: Box-like rigid items; moderate friction; clear pathways
- Sports and entertainment demos (ball dribbling/kicking)
- Sectors: entertainment, sports tech, public engagement
- What: Dribbling/kicking interactions for halftime shows, exhibitions, visitor attractions
- Tools/workflows: “Kick Ball” policy pack; safety start/pause logic integrated with show control systems
- Dependencies: Flat surfaces, controlled risk zones, fall-safe costuming/equipment
- Privacy-preserving office/home trials
- Sectors: enterprise facilities, smart buildings
- What: Depth-only navigation and interaction for moving light obstacles, clearing pathways, positioning objects in shared spaces while preserving visual privacy
- Tools/workflows: Depth-only perception stack with strong masking augmentation; on-device inference; logging that stores no RGB
- Dependencies: Sufficient depth quality; clear lighting; rigid-object interactions
- Rapid task retargeting with minimal real-world data collection
- Sectors: robotics integrators, OEMs
- What: Use the reusable low-level keypoint tracker and only retrain high-level policies for new rigid-object tasks (kick/push/lift variants)
- Tools/workflows: Teacher–student distillation pipeline; Isaac Gym training templates; motion retargeting pipeline (e.g., AMASS/OMOMO via GMR) for refreshed HMS statistics
- Dependencies: GPU simulation capability; motion library access; process for recording HMS stats used in action clipping
- Research/teaching platform for whole-body loco-manipulation
- Sectors: academia, R&D labs
- What: A reproducible framework for hierarchical visual RL, imitation distillation, HMS-constrained exploration; course/lab modules on sim-to-real
- Tools/workflows: Open-source code, datasets (AMASS/OMOMO retargeting recipes), ablation baselines (noise injection, action clipping, local/global frames)
- Dependencies: Access to a compatible humanoid or sim; depth cameras; curriculum time
- Safety wrapper patterns for humanoid deployment
- Sectors: robotics integrators, compliance teams
- What: Binary start/pause/stop interlocks, stateful “safe posture” fallback, and friction/drift-aware policies as deployable templates
- Tools/workflows: Safety supervisor node; policy-level penalties for drift and foot slippage; checklists for friction/domain randomization coverage
- Dependencies: Organizational safety SOPs; emergency stop integration; floor condition monitoring
- Benchmarking and evaluation workflows for visual loco-manipulation
- Sectors: academia, standards bodies, internal QA
- What: Standardized tasks and metrics (forward progress, drift, force, alive time) for visual loco-manipulation over rigid objects, indoor/outdoor
- Tools/workflows: Reusable Isaac Gym scenes; metric dashboards; cross-robot generalization tests
- Dependencies: Agreement on scene specs; shared data/reporting formats
- Privacy-by-design perception for regulated environments
- Sectors: healthcare facilities, public-sector buildings
- What: Deployment of depth-only policies to reduce privacy risk and ease approvals for trials involving humanoids in semi-public spaces
- Tools/workflows: Camera data governance profiles; evidence of sim-to-real masking; configurable no-RGB build options
- Dependencies: Regulator acceptance; DPIA (data protection impact assessment) processes
Long-Term Applications
- Human-robot collaborative handling and co-manipulation
- Sectors: logistics, manufacturing, construction
- What: Joint pushing/lifting, handover, and co-transport with humans using vision and force adaptation
- Tools/workflows: Extended high-level policies using contact/force sensing; interactive intent estimation; curriculum learning with human-in-the-loop
- Dependencies: Richer sensing (force/torque), safety-rated proximity and contact compliance; new training for deformable and multi-agent scenarios
- Household assistance and eldercare support
- Sectors: healthcare, home robotics
- What: Clearing pathways, moving lightweight furniture/components, fetching small items, opening light doors/drawers
- Tools/workflows: Skill libraries built on keypoint commands (reach, grasp, pull, push); task graph planners to sequence long-horizon chores
- Dependencies: Generalization to diverse homes; deformable object handling; higher payload and stable grasping skills; rigorous safety certification
- Disaster response and public safety clearing
- Sectors: emergency services, defense
- What: Clearing light debris, opening passages, repositioning obstacles in unstructured terrain using whole-body contact
- Tools/workflows: Terrain-robust extensions, multi-modal sensing, active perception; domain randomization for smoke/dust occlusions
- Dependencies: Harsh-environment hardening; teleop fallback; safe failure modes; compliance with response protocols
- Material handling on dynamic or crowded floors
- Sectors: airports, hospitals, retail, warehouses
- What: Threading through people and moving carts/boxes while obeying social navigation constraints
- Tools/workflows: Socially-aware policy layers; human trajectory forecasting; shared autonomy for negotiation behaviors
- Dependencies: Advanced perception of humans; policy verification; liability and insurance frameworks
- Complex manipulation of non-rigid or articulated objects
- Sectors: home, manufacturing, hospitality
- What: Handling bags, flexible packaging, clothing; doors with varying handles; articulated fixtures
- Tools/workflows: Extensions of the low-level tracker to include wrist/hand keypoints and grasp primitives; new simulations for deformables; tactile sensing
- Dependencies: Rich hand hardware; deformable-physics fidelity; large-scale data for object variability
- Standardization of keypoint command interfaces across humanoids
- Sectors: robotics OEMs, standards organizations
- What: Interoperable “keypoint control” API (root/hands/feet/head) enabling policy portability across platforms
- Tools/workflows: Cross-robot retargeting libraries, HMS profilers and action clippers standardized by body size/dynamics
- Dependencies: Industry coordination; benchmarking suites; license and IP alignment
- Certification-ready safety envelopes for whole-body contact
- Sectors: policy, insurance, standards
- What: Codified limits on force, speed, contact regions; audit trails from HMS-based action clipping and noise-invariant training
- Tools/workflows: Test harnesses for contact forces, slip rates, drift; conformance tests for pause/execute interlocks
- Dependencies: Regulator engagement; third-party labs; harmonization with existing industrial robot safety (e.g., ISO/ANSI)
- Autonomous tool use via keypoint-conditioned skills
- Sectors: maintenance, light assembly, construction
- What: Using sticks, bars, or simple tools to lever/push/align beyond bare hands/feet
- Tools/workflows: Skill discovery over extended keypoints; affordance detection in depth; curriculum from “push” to “lever”
- Dependencies: Reliable grasping/tool retention; perception of tool-object interactions; safety of hard contacts
- On-device continual adaptation and personalization
- Sectors: enterprise, consumer robotics
- What: Updating high-level policies on-robot for new surfaces, objects, user preferences (privacy-preserving, depth-only)
- Tools/workflows: Lightweight DAgger or RL fine-tuning on edge; drift monitoring; automated retraining triggers
- Dependencies: Compute on board; safe exploration limits; data governance
- Multi-robot coordination for staging and rearrangement
- Sectors: logistics, events, construction
- What: Teams of humanoids co-pushing/carrying large items with emergent whole-body strategies
- Tools/workflows: Multi-agent HMS-aware coordination; shared task allocators; V2V policy messaging
- Dependencies: Low-latency comms; formation control; collective safety envelopes
- Generalist visuomotor assistants via library composition
- Sectors: cross-industry
- What: Compose push/kick/lift/reach/balance skills into long-horizon workflows (e.g., set up a booth: move crates, align display, tidy floor)
- Tools/workflows: Behavior trees or LLM-planners calling keypoint skills; task monitors for drift/force; environment maps from depth
- Dependencies: Reliable skill arbitration; failure recovery; semantic understanding beyond depth
- Public procurement and pilot program templates for humanoids
- Sectors: policy, municipal services
- What: RFP templates and pilot KPIs centered on depth-only privacy, sim-to-real evidence, safety interlocks, and drift metrics
- Tools/workflows: Procurement checklists, compliance attestations, standardized evaluation scenes and metrics
- Dependencies: Stakeholder alignment; civil liability frameworks; public communication plans
Notes on Feasibility, Assumptions, and Dependencies
- Hardware and morphology: The low-level keypoint tracker and HMS statistics are tuned to a specific humanoid morphology (e.g., Unitree G1). Porting to other platforms requires retargeting and updated HMS stats.
- Sensing: Depth-only perception was chosen for sim-to-real and privacy. Performance depends on depth quality; masking augmentation approximates real noise but may need environment-specific tuning.
- Task scope: Demonstrated tasks involve rigid objects (boxes, balls) and whole-body contact. Deformable, articulated, or heavy payload tasks need additional research and sensing.
- Safety: Real-world deployment should leverage the paper’s safety patterns (binary pause/execute, stable standing posture, drift penalties) and comply with local safety regulations.
- Training compute: The workflows assume access to GPU-based simulation (Isaac Gym) and motion retargeting pipelines (e.g., AMASS/OMOMO via GMR).
- Environment variability: Robustness relies on domain randomization (friction, depth noise, camera angle). New settings may require additional randomization curricula or small-scale fine-tuning.
Glossary
- Action clipping: Constraining high-level policy outputs to a human-motion–feasible range to stabilize training. "apply action clip to constrain the high-level policy output within this range."
- DAgger: An imitation learning algorithm (Dataset Aggregation) that distills a student policy by iteratively querying a teacher during on-policy rollouts. "via DAgger \cite{ross2011reduction}"
- Egocentric vision: First-person visual sensing from the robot’s onboard camera used to condition policy decisions. "conditioning on egocentric vision input."
- GMR: A motion retargeting method used to convert human motion data to humanoid robot motions. "For motion datasets, we use GMR~\cite{ze2025gmr,ze2025twist} to retarget AMASS~\cite{mahmood2019amass} and OMOMO~\cite{li2023omomo} into humanoid motions."
- Human Motion Space (HMS): The feasible range of keypoint commands derived from human motion statistics, used to regularize exploration. "We refer to this feasible space as the Human Motion Space (HMS)."
- IsaacGym: A GPU-accelerated physics simulator for large-scale robot learning. "incorporating vision into IsaacGym further slows down the simulation."
- Keypoint commands: Compact control signals specifying desired positions of root, head, hands, and feet for the tracker to follow. "keypoint commands computed from the reference frame at each time step."
- Keypoint tracker: A low-level policy that tracks keypoint commands to produce human-like whole-body motion. "a low-level task-agnostic keypoint tracking policy $\pi_{\text{tracker}$ that learns whole-body dexterity priors from human motion data"
- Loco-manipulation: Combined locomotion and object manipulation using whole-body strategies. "a visual sim-to-real framework for whole-body humanoid loco-manipulation."
- Privileged object states: Task-relevant object information available during training but not at deployment, used to train teacher policies. "a teacher policy with privileged object states is first trained and then distilled into a visuomotor policy."
- Proprioception: Internal sensing of the robot’s body (e.g., joint positions, velocities, contacts) used as policy input. "rely solely on egocentric vision and robot proprioception"
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that optimizes policies with a clipped objective for stability. "optimize it using PPO~\cite{schulman2017ppo,rudin2022legged_gym}"
- Sim-to-real: Training policies in simulation and deploying them on real robots, ideally without additional fine-tuning. "a visual sim-to-real framework"
- Teacher–student training: A two-stage pipeline where a privileged teacher is trained first and then distilled into a deployable student policy. "We adopt a teacherâstudent training scheme"
- Visuomotor policy: A control policy that maps visual and proprioceptive inputs to motor actions. "visuomotor policies trained in simulation to real humanoid robots"
Collections
Sign up for free to add this paper to one or more collections.