Polar: Agentic RL on Any Harness at Scale
Abstract: Reinforcement learning for language agents increasingly depends on custom harnesses that manage long-running context, multi-turn tool use and multi-agent orchestration. However, porting these harnesses into RL environment interfaces remains difficult and often loses important training signals. We bridge this gap with polar, a rollout framework for scalable asynchronous RL over arbitrary agent harnesses. Polar treats the agent harness as a black box: it proxies LLM API calls, records token-level model interactions, and reconstructs token-faithful trajectories for training. Each rollout node efficiently manages runtime prewarming, agent execution, trajectory reconstruction, and evaluation in parallel, exposing asynchronous service endpoints that can be consumed by independent trainers at scale. This decoupled design makes Polar agnostic to agent harnesses, training infrastructure, and RL algorithms while improving compute utilization for long-running agent workloads. We validate polar by training agents on software-engineering tasks with popular coding harnesses. Using simple GRPO, polar improves Qwen3.5-4B by 22.6, 4.8, 0.6 and 6.2 points on SWE-Bench Verified with the Codex, Claude Code, Qwen Code and Pi harnesses, respectively. We further demonstrate Polar for offline data generation over custom harnesses and ablate trajectory reconstruction strategies. Polar rewrites its preceding work, Prorl Agent, and has been registered as one of NeMo Gym environments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Polar: Agentic RL on Any Harness at Scale”
What’s this paper about? (Brief overview)
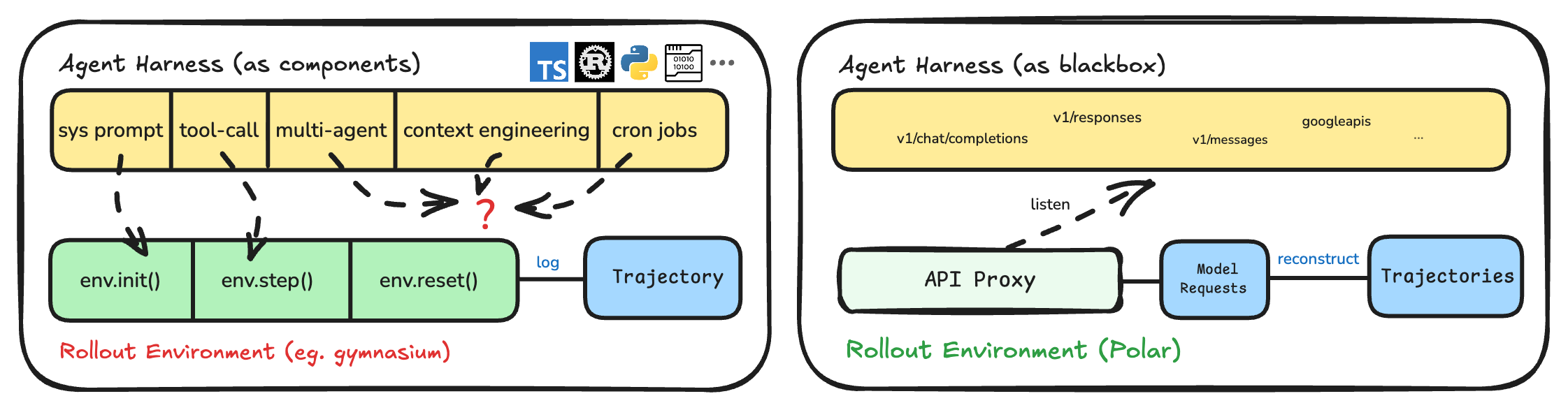
This paper introduces Polar, a system that helps train AI “agents” (like coding assistants) using reinforcement learning (RL) without needing to rewrite the agents’ own software. Instead of digging into each agent’s internal code, Polar listens at the point where the agent talks to the LLM (the model’s API) and turns those conversations into training data. This makes it much easier to train many different kinds of agents, even ones that are complex, closed-source, or written in different languages.
Think of an agent’s “harness” as the house and toolbox the agent lives in—scripts, tools, and rules that guide how it works. Polar trains the agent while keeping that house untouched.
What questions does the paper ask? (Key objectives)
- Can we train agents with RL “without opening the box”—that is, without changing their harness code?
- Can we build a rollout system that plugs into any agent’s model calls and scales to many long, multi-step tasks?
- Can we do this in a way that preserves exact training signals (so we train on exactly what the model actually said)?
- Will this approach improve real-world performance on tough tasks like fixing software bugs?
How does Polar work? (Methods in simple terms)
Polar treats the agent as a black box and stands at the doorway where the agent calls the LLM.
Key ideas, explained simply:
- Agent harness: The software “home” around the agent that manages tools, files, and multi-step workflows.
- Proxy: A smart “listener” placed at the model API boundary (the door). It sees every request to the model and every response back.
- Tokens: Tiny pieces of text (like LEGO bricks) that models read and write. Training must match the exact tokens the model actually produced.
- Trajectory: A “diary” of a full run—everything the agent asked, what the model answered, and what reward (score) it got.
What Polar does:
- It intercepts (proxies) the agent’s calls to the model, records prompts, the exact tokens the model generated, and the model’s confidence (log probabilities).
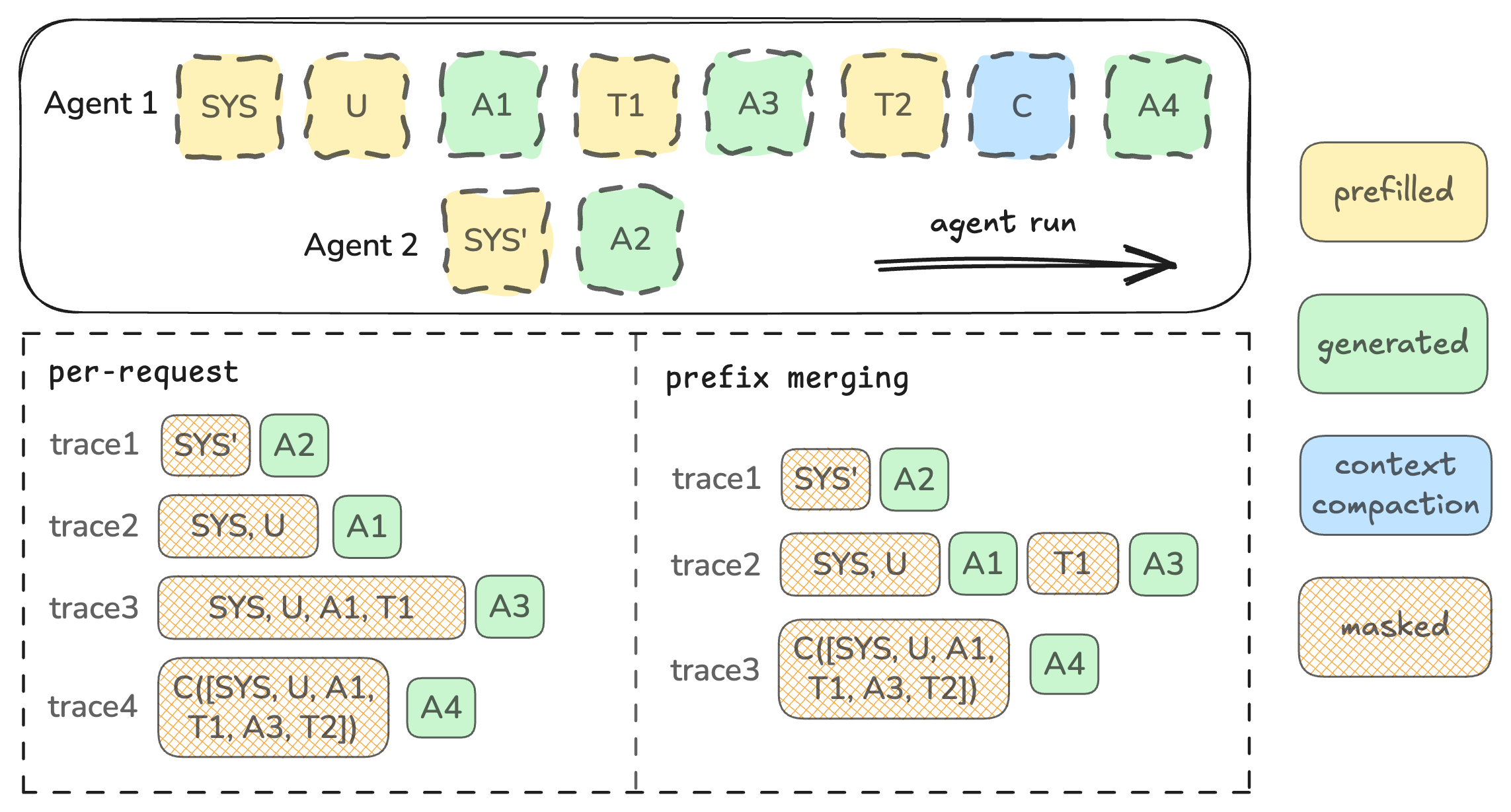
- It then reconstructs “trajectories” from these calls for RL training. There are two strategies:
- Per-request: Treat each model call as its own small training sample.
- Prefix merging: When the agent is having a multi-turn conversation, combine multiple calls into one longer, cleaner training sample—while only training on the exact tokens the model actually generated and masking out everything else (like system-inserted text).
- It separates work into stages so the system runs efficiently:
- Prepare environments (like starting a container),
- Run the agent,
- Build trajectories and evaluate results,
- Send results to the trainer.
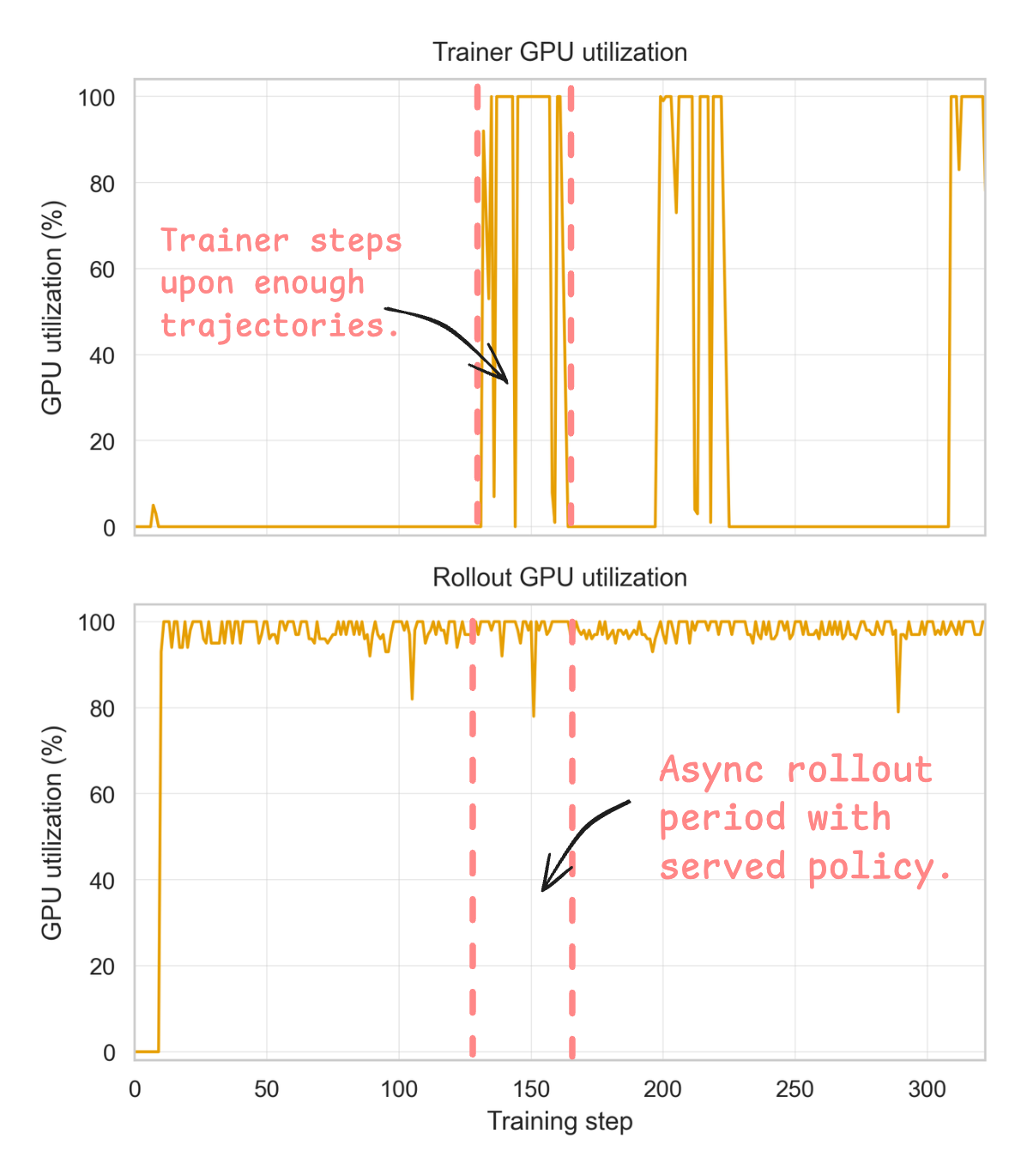
- This “asynchronous” design keeps expensive computers (GPUs) busy instead of waiting around.
Analogy:
- Imagine a coach training a player who lives in a complex gym (the harness). Instead of rearranging the gym, the coach just watches the player’s interactions at the gym door (the API), carefully records each move (tokens), and then uses that diary to give feedback and improve future performance.
What did the researchers find? (Main results and why they matter)
They tested Polar on code-fixing tasks (SWE-Bench Verified), using popular coding agent harnesses (like Codex, Claude Code, Qwen Code, Pi). They trained a 4B-parameter model (Qwen3.5-4B) with a simple RL method (GRPO).
Main outcomes:
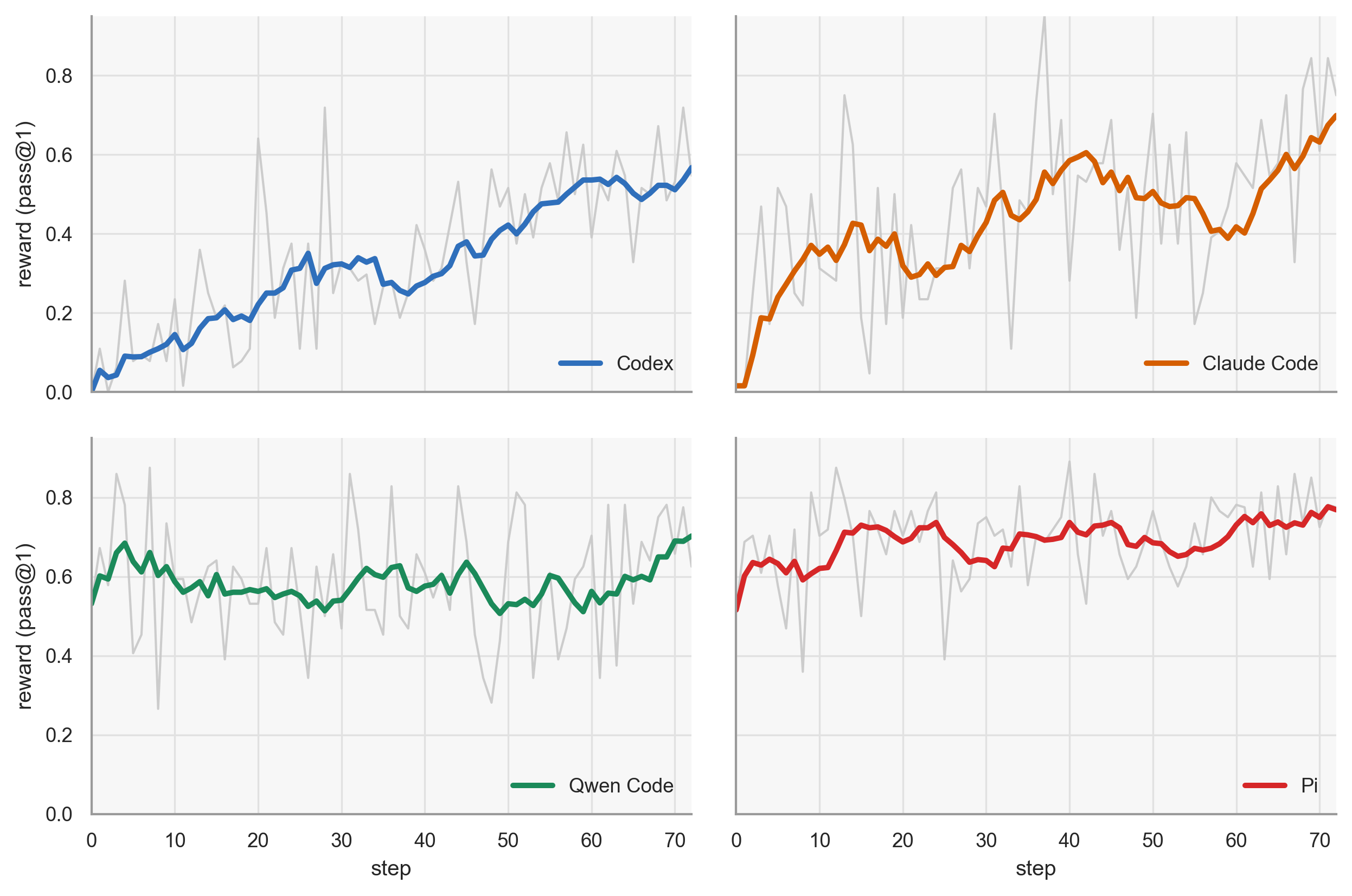
- Performance improved across all harnesses without changing harness code.
- Biggest jump came when the harness style was unfamiliar to the model:
- Codex harness: from 3.8% to 26.4% pass@1 (a +22.6 point gain).
- Claude Code: from 29.8% to 34.6% (+4.8).
- Qwen Code: from 34.6% to 35.2% (+0.6).
- Pi: from 34.2% to 40.4% (+6.2).
Why this matters:
- Training “in the native environment” helps the model learn the exact behaviors needed at evaluation time—because training uses the same harness and the same token-level outputs the model actually generated.
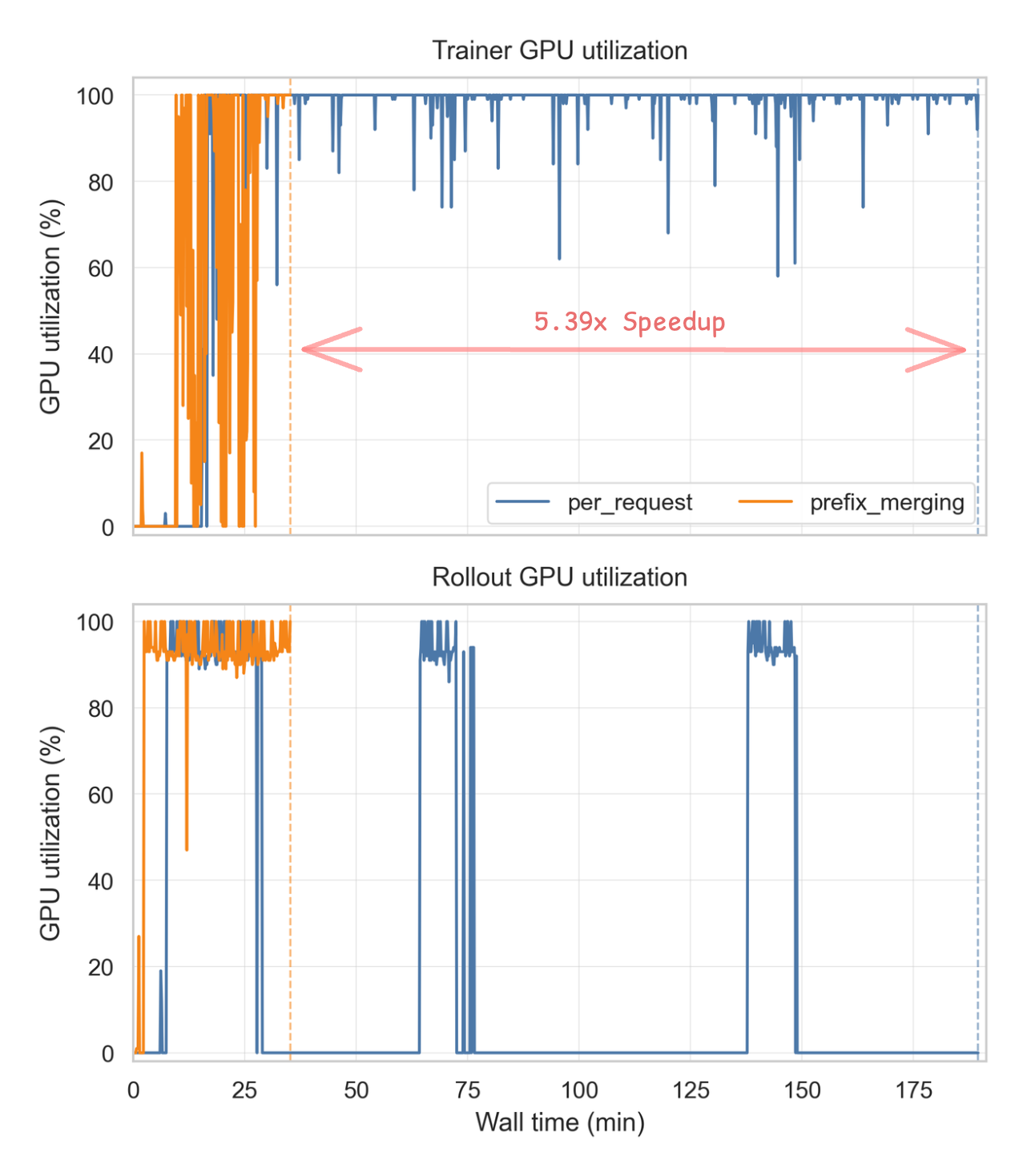
- The prefix-merge strategy made training much more efficient (fewer, better-formed training samples), keeping GPUs busier and reducing time per training step by over 5× in their setup.
Bonus result (offline data generation):
- Polar was also used to generate a supervised dataset without RL—just by running many agent sessions and keeping the successful ones.
- In one run on coding tasks, it produced 504 high-quality accepted trajectories out of 1,638 attempts (about 31% acceptance). This creates valuable training data for future models.
Why is this important? (Implications and potential impact)
- Lower barrier to training: Teams can train agents without rewriting their existing, often complex harnesses—great for real-world systems that are messy or closed-source.
- More faithful learning: By recording exact tokens and confidence scores, Polar avoids “drift” between what was generated and what’s trained on. That makes the training signal more accurate.
- Scales to long, multi-step tasks: The asynchronous, service-style design helps keep expensive hardware utilized and handles slow, tool-heavy runs.
- Works across domains: Although tested on coding agents, the same idea applies to web browsing, OS automation, and other multi-tool agents.
- Faster iteration: With offline data generation and easy plug-in, teams can collect datasets and improve models steadily, without fiddly integrations.
In short, Polar’s “train without opening the box” approach makes it far easier to bring reinforcement learning to real agents as they’re actually used—speeding up progress and making AI agents more capable in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide concrete follow-up research and engineering work:
- Scope beyond coding harnesses
- No evaluation on non-coding agent settings (web browsing, OS-level computer use, enterprise workflows, multi-agent orchestration, long-running planning); unclear how well proxy capture and trajectory reconstruction generalize to these domains.
- No multimodal support demonstrated (images, audio, screen/video streams); how to capture IDs/logprobs for non-text modalities and mixed tool-call content is unspecified.
- Provider and streaming edge cases
- Proxy currently normalizes to OpenAI Chat Completions and synthesizes streams from non-streaming upstream; impact on agents that rely on true incremental token streaming, tool-call streaming, or partial-function-calling feedback loops is unmeasured.
- Compatibility with provider/version drift (e.g., Anthropic, OpenAI, Google schema changes) and custom/unknown provider protocols is not analyzed; no strategy for schema evolution or automatic conformance testing is provided.
- Handling cases where the upstream model cannot return logprobs (or returns provider-tokenized IDs only) is unclear—how to maintain token fidelity and trainability in such scenarios remains open.
- Token-fidelity guarantees and reconstruction robustness
- Prefix-merging assumes availability/consistency of an end-of-turn token and strict prompt-prefix checks; failure modes when tokenizers differ, end-of-turn is implicit/missing, or harnesses inject/rewrite context are not quantified.
- No empirical audit of reconstruction correctness (rate of mis-merges, missing turns, or drift) across diverse harnesses; no automated validation tools or metrics for token-fidelity errors are provided.
- Treatment of structured outputs (function/tool JSON, code blocks with fenced metadata, constrained decoding) and tool-result insertions in the canonical “interstitial” regions is underspecified; correctness of loss masks in these cases is not validated.
- Credit assignment and reward modeling
- Process rewards, PRM-based credit assignment, and session normalization are acknowledged but not implemented; concrete algorithms, interfaces, and benchmarks for per-trace credit allocation within merged traces are missing.
- Reward hacking observed when broadcasting outcome rewards to per-request traces is noted but not systematically studied; no mitigation strategies (e.g., normalization, causal credit assignment, trajectory decomposition) are evaluated.
- Algorithmic breadth and off-policy usage
- Only GRPO is demonstrated; interoperability and performance with PPO, A2C, off-policy RL (e.g., replay buffers), preference optimization (DPO/RLAIF), and verifier-regularized methods remain untested.
- Stale-policy/asynchrony effects (policy lag across decoupled rollout and training) are not characterized; no analysis of stability/variance or KL control under Polar’s rollout-as-a-service.
- System scalability and performance characterization
- Lack of end-to-end system benchmarks (throughput, latency, cost per accepted trajectory, queueing dynamics under contention, fault tolerance) across cluster sizes and heterogeneous hardware.
- Proxy overhead (latency, CPU/memory footprint, storage bandwidth for traces) and its effect on harness behavior and throughput are not measured.
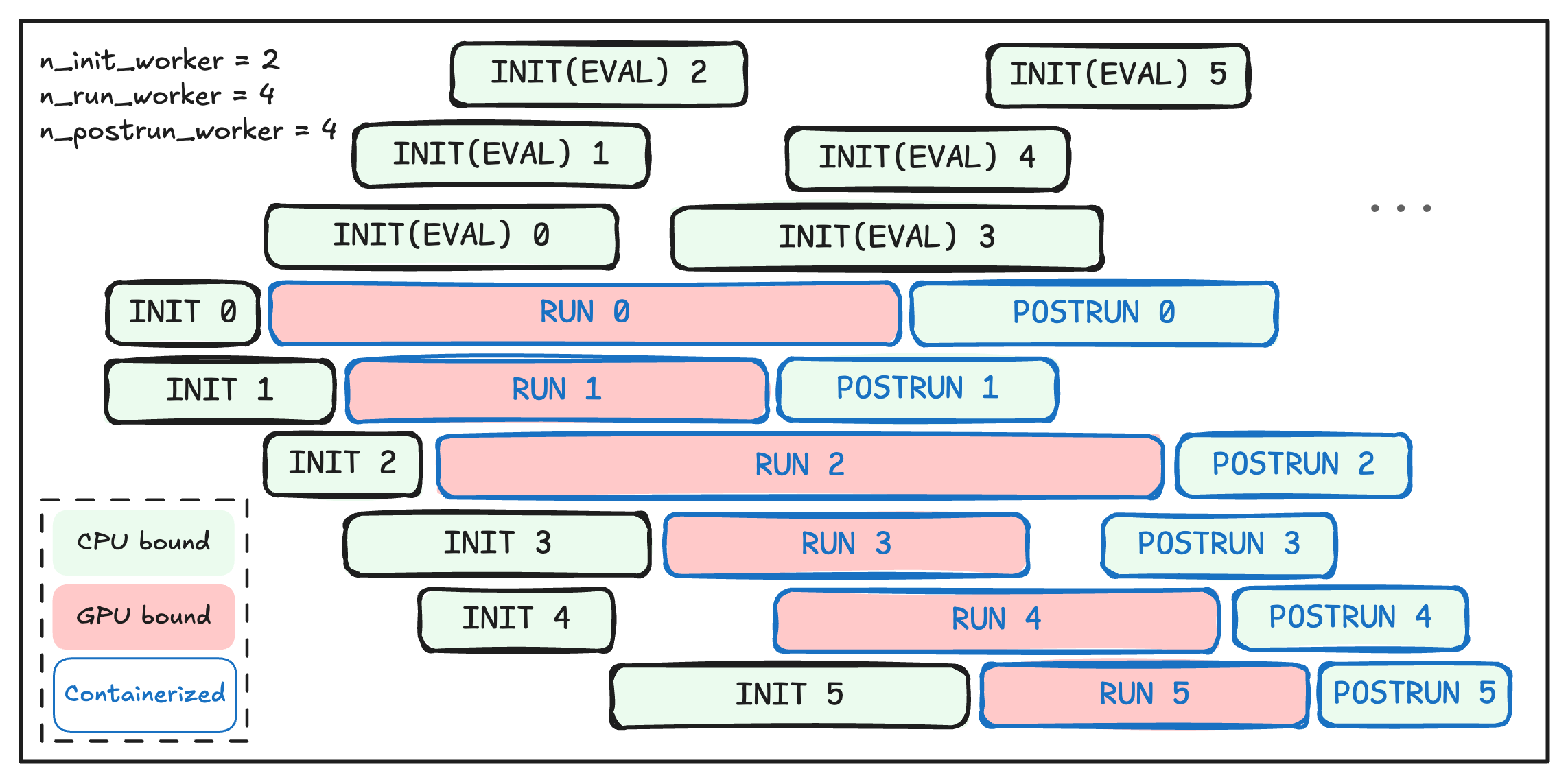
- Scheduling policies for INIT/READY/RUNNING/POSTRUN pools (buffer sizing, fairness across tasks/harnesses, prewarm policies) are not evaluated or tuned empirically.
- Security, privacy, and compliance
- Executing untrusted agent code: sandbox hardening, network egress controls, filesystem isolation, secrets handling, and supply-chain integrity (images, MCP servers) are not detailed or verified.
- Privacy/compliance for proxy-captured payloads (PII, enterprise source code, credentials) lacks redaction policies, encryption-at-rest, retention/expiration strategies, and auditability guarantees.
- Legal/ToS implications of intercepting provider traffic (especially for closed-source harnesses and commercial APIs) are not addressed.
- Compatibility and operability in the wild
- Integration constraints for closed-source harnesses that pin certificates, require native SDKs, or cannot change base URLs are not discussed; procedures for TLS termination, auth passthrough, or sidecar insertion are absent.
- Robustness to frequent harness updates (prompt schemas, tool registries, context policies) is untested; no contract tests or “golden traces” to detect integration regressions.
- Only Docker and Apptainer runtimes are supported; requirements and trade-offs for Kubernetes, serverless, or Windows/macOS environments are not explored.
- Evaluation breadth and reproducibility
- Results limited to SWE-Gym training and SWE-Bench Verified evaluation with one base model (Qwen3.5-4B) and a single large-teacher run (Qwen3.5-122B-A10B); cross-model generalization, sensitivity to model size, and ablations on sampling/decoding parameters are missing.
- Lack of multi-run variance, seed sensitivity, and statistical significance reporting for RL improvements; hyperparameters and full system configs (infrastructure, trainer cadence, inference settings) are only partially specified.
- No head-to-head comparison against alternative low-intrusion systems (e.g., Agent Lightning, rLLM, Harbor) on developer effort, integration time, token-fidelity, and training efficacy.
- Handling partial, failed, and long-tail episodes
- While timeouts yield partial traces, policies for training on truncated trajectories (termination handling, off-policy corrections, bias from long-tail failures) are not analyzed.
- Strategies for deduplication, curriculum, and prioritization of “hard” instances in long-tail distributions are not provided.
- Offline data generation quality and governance
- The released SFT corpus is filtered only by binary verifier pass; no analysis of diversity, duplication, repository/issue bias, code quality, or potential data contamination.
- Token IDs/logprobs are not mentioned in the release; without token-level fidelity, re-tokenization drift may affect downstream training reproducibility.
- Licensing implications of distributing patches/messages tied to third-party repositories (and any embedded content) are not examined.
- Extensibility of trajectory strategies
- Only two reconstruction strategies (per-request, prefix-merging) are provided; criteria for when to choose or switch strategies, and support for hybrid or graph-structured trajectories (branching, parallel subagents) are not explored.
- No APIs or examples for user-defined grouping keys in complex harnesses (e.g., hierarchical planners, speculative decoding, tool pipelines) to ensure correct chain partitioning.
- Tool-use and environment-state fidelity
- State divergence between training and evaluation runtimes (e.g., non-deterministic tools, network resources, flaky tests) is acknowledged as a concern in the literature but not addressed with snapshotting, determinism enforcement, or state-diff verification.
- Attribution of rewards across subagents and tool-mediated branches (and their merge points) is unspecified; principled credit assignment in multi-agent or hierarchical settings is open.
- Monitoring, diagnostics, and safety valves
- No built-in diagnostics for detecting retokenization drift, mis-merges, or proxy misconfigurations in real time; lack of health metrics and alerting around fidelity and data quality.
- No automated rollback/blacklist mechanisms for problematic tasks/harness versions that cause reward hacking or systemic failures.
These gaps suggest concrete next steps: broaden task domains and modalities; add formal token-fidelity audits; implement and evaluate PRM/process rewards; characterize system scalability and security; provide robust streaming and provider-compatibility layers; and release richer, token-faithful datasets with reproducibility artifacts.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the paper’s methods and system components (proxy-based capture, token-faithful trajectory reconstruction, rollout-as-a-service, evaluator integration, and offline data generation).
- Bold title: Harness-native RL for coding agents in software engineering
- Sectors: Software, Developer Tools
- What: Improve existing code agents (e.g., Codex CLI, Claude Code, Qwen Code, Pi) without rewriting their harnesses by routing model calls through Polar’s proxy and training with GRPO. The paper reports sizable gains (e.g., +22.6 points on SWE-Bench Verified for Codex with Qwen3.5-4B).
- Tools/workflows: Polar rollout server + gateway nodes; prefix_merging trajectory builder; verifiers (SWE-Bench/SWE-Gym); trainers (e.g., Slime) with GRPO; containerized runtimes (Docker/Apptainer).
- Assumptions/dependencies: Ability to point the harness model base URL at the proxy; inference backend must expose token IDs and logprobs; a verifier or outcome signal; compatible provider schemas (OpenAI/Anthropic/Google-like) and consistent tokenization to preserve fidelity.
- Bold title: Model endpoint swap for cost, latency, or privacy while preserving behavior
- Sectors: Enterprise IT, Software, Finance (internal tooling)
- What: Direct third-party or closed-source harness traffic to an in-house inference server (e.g., SGLang/vLLM) via Polar’s provider-compatible proxy, enabling immediate model substitution with token-faithful logging.
- Tools/workflows: Provider-shape normalization (Anthropic/OpenAI/Google → OpenAI Chat Completions); synthetic streaming; proxy observability.
- Assumptions/dependencies: Legal/contractual permission to interpose on API calls; near-API parity for tool-calls/stop conditions; tokenizer alignment to avoid drift; production observability and rate-limiting controls.
- Bold title: RL-as-a-service decoupled from training for better GPU utilization
- Sectors: ML Infrastructure/Platforms
- What: Use Polar’s asynchronous rollout service to keep rollout/inference saturated while trainers consume trajectories asynchronously; leverage prefix_merging to reduce trainer updates and eliminate fragmentation.
- Tools/workflows: INIT/READY/RUNNING/POSTRUN worker pools; evaluator prewarm; session deadlines; trainer callbacks.
- Assumptions/dependencies: Stable cluster scheduling; shared storage or callback buses; trainer accepting externally produced trajectories; monitoring for tail latencies and stragglers.
- Bold title: “Data factory” for high-quality offline corpora (SFT/PRM/Verifier training)
- Sectors: ML Engineering, Academia
- What: Generate and filter multi-turn agent trajectories at scale using verifiers; release or reuse accepted traces for SFT, preference, or verifier training (demonstrated 504 accepted SWE-Gym trajectories out of 1,638).
- Tools/workflows: Polar session journaling, acceptance filters via task verifiers, stratified dataset packaging (e.g., HuggingFace), rejection sampling by multiple completions per prompt.
- Assumptions/dependencies: Strong verifiers for acceptance; sufficient compute to fan out sessions; consistent harness behavior across clean runtimes.
- Bold title: Token-faithful telemetry for auditability and reproducibility
- Sectors: Finance, Healthcare (internal R&D), Policy/Compliance, Critical Infrastructure
- What: Capture exact sampled tokens, loss masks, and logprobs to enable precise provenance, reproducible experiments, and forensic analysis of agent decisions.
- Tools/workflows: Proxy-side logging; per-trace loss masks; trajectory metadata with session provenance.
- Assumptions/dependencies: Data governance for token-level logs; privacy-safe storage and retention policies; deterministic inference configurations (seeds, sampling params) for replayability.
- Bold title: Multi-harness evaluation lab without re-instrumenting agents
- Sectors: Academia, Benchmarking Orgs, Developer Tools
- What: Compare agent behavior across heterogeneous harnesses (CLI tools, binaries, SDK agents) by standardizing at the model API boundary and reconstructing trainer-ready traces consistently.
- Tools/workflows: Minimal harness adapters; unified evaluator registry; shared trajectory schema.
- Assumptions/dependencies: Harnesses expose LLM calls; evaluator availability; consistent tool schemas or adapter shims.
- Bold title: Enterprise agentops: runtime prewarming and controlled rollouts
- Sectors: Platform/DevOps, Internal AI Platforms
- What: Operationalize complex agent rollouts with runtime prewarm, clean evaluator contexts, timeout handling, and post-run teardown for reliable CI-like agent testing and experimentation.
- Tools/workflows: Gateway worker pools; runtime interfaces (Docker/Apptainer); standardized session lifecycle hooks.
- Assumptions/dependencies: Container support in target environment; artifact storage; clean seed environments for verifiers.
- Bold title: Personal/dev-team productivity with custom workflow adaptation
- Sectors: Daily Life (advanced users), Small Dev Teams
- What: Improve a team’s existing coding or web-automation harness by training a small local model with Polar against their own tasks/tests and substituting the endpoint via the proxy.
- Tools/workflows: Local inference backend; minimal harness adapter; simple pass/fail evaluator (unit/integration tests).
- Assumptions/dependencies: Local GPU/CPU budget; tests/verifiers to define reward; permitted use of data and tools.
- Bold title: Tool vendor compatibility layer
- Sectors: Software, ISVs, Integrators
- What: Offer a compatibility proxy that translates among provider APIs and adds token-logging for downstream training/evaluation pipelines, easing vendor/model swaps for agent products.
- Tools/workflows: Provider transformers; streaming synthesis; token/logprob alignment; metrics dashboards.
- Assumptions/dependencies: Maintenance of evolving provider specs; tokenizer/version pinning; robust error handling.
- Bold title: Credit assignment experiments with safe baselines
- Sectors: Academia, Applied Research
- What: Run ablations on trajectory reconstruction (per_request vs prefix_merging), outcome vs process rewards, and session normalization to study reward hacking and efficiency trade-offs.
- Tools/workflows: Polar trajectory builders; evaluator registry; trainer hooks; logging for PRM development.
- Assumptions/dependencies: Availability of process rewards or PRMs; careful normalization; reproducible harness behaviors.
Long-Term Applications
These use cases need further research, domain verifiers, safety cases, or integration work (e.g., process rewards, regulatory approvals, or scaling).
- Bold title: Healthcare agents trained in-place within EHR/LIS/RIS harnesses
- Sectors: Healthcare/MedTech
- What: Adapt clinical agents to hospital-specific workflows by interposing at the model boundary while leaving proprietary EHR harnesses untouched; log token-faithful interactions for audit.
- Tools/products: Proxy adapters for healthcare systems; HIPAA-compliant logging; clinical verifiers (e.g., order checks, guideline adherence).
- Assumptions/dependencies: Robust healthcare-grade verifiers; de-identification; security certifications; strict access controls; buy-in from EHR vendors.
- Bold title: Finance/compliance copilots with provable provenance
- Sectors: Finance, Legal/Compliance
- What: Train domain copilots inside existing compliance tooling (KYC/AML review harnesses) with token-level provenance for audit trails, while using outcome/process rewards derived from policy checks.
- Tools/products: Compliance adapters; policy-verifier pipelines; secure proxying; attestation dashboards.
- Assumptions/dependencies: Strong, auditable verifiers; regulator-approved logging/storage; human-in-the-loop signoff.
- Bold title: Safe computer-use/OS agents with verifier-driven RL
- Sectors: Enterprise IT, Cybersecurity, IT Operations
- What: Train agents to operate full OS environments (e.g., OSWorld) using rigorous verifiers for safety, security posture, and success; leverage Polar’s isolation and token fidelity to tie rewards to behavior-policy tokens.
- Tools/products: OS harness adapters; sandbox policies; safety verifiers (file/system/network constraints); PRMs for process rewards.
- Assumptions/dependencies: Mature verifiers beyond simple pass/fail; defense-in-depth sandboxes; incident response integration.
- Bold title: Robotics and industrial control assistants via black-box HMIs
- Sectors: Robotics, Manufacturing, Energy
- What: Interpose at LLM API boundaries of UI/HMI agents that operate robots or SCADA-like systems; train via simulated/verifier-backed tasks, then gate to limited real execution.
- Tools/products: Sim-to-real evaluators; safety layers; trace alignment across sim/hardware; task verifiers for procedures.
- Assumptions/dependencies: High-quality simulators and digital twins; formal safety constraints; certification and governance.
- Bold title: Multi-agent orchestration learning with process rewards
- Sectors: Software, Platform, Research
- What: Train coordination strategies across sub-agents/tools using PRMs for intermediate steps, reducing reward hacking noted with naive outcome broadcasting.
- Tools/products: PRM training with Polar-generated data (accepted/rejected pairs); trajectory-level normalization; credit assignment research.
- Assumptions/dependencies: Reliable process reward models; robust grouping/partitioning for multi-branch traces; scalable evaluators.
- Bold title: Standardization of token-fidelity logging for regulation and interop
- Sectors: Policy/Standards, Cross-industry Consortia
- What: Establish ecosystem standards for logging token IDs, loss masks, and sampling params so agent decisions are reproducible and auditable across vendors.
- Tools/products: Open schemas; reference proxies; compliance test suites; certification programs.
- Assumptions/dependencies: Multi-vendor agreement; privacy-safe defaults; consistent tokenizer/version pinning.
- Bold title: Autonomous enterprise web agents with real-world evaluators
- Sectors: Enterprise Operations, Customer Support
- What: Train web agents (WebArena/Mind2Web-like) against enterprise portals with verifiers that check task completion, compliance, and data integrity; keep agent harnesses unchanged.
- Tools/products: Web harness adapters; DOM/action verifiers; red-team evaluators; staged rollout flows.
- Assumptions/dependencies: Robust verifiers beyond heuristics; secure credential handling; drift monitoring.
- Bold title: Agent “app store” with Bring-Your-Own-Harness RL adaptation
- Sectors: Software Marketplaces, ISVs
- What: Offer a managed service that adapts any customer-supplied harness to a chosen model via Polar, returning improved checkpoints and reproducible logs.
- Tools/products: Managed Polar rollout clusters; compliance-grade logging; evaluator marketplace; cost controls.
- Assumptions/dependencies: IP and data-use agreements; sandbox isolation at scale; billing and quota fairness.
- Bold title: Procedure automation in critical infrastructure with strict verifiers
- Sectors: Energy, Transportation, Utilities
- What: Train agents to execute strict SOPs with long horizons using domain verifiers and staged deployment (simulation → shadow mode → supervised execution).
- Tools/products: Digital twins; formal procedure verifiers; safety-case documentation pipelines.
- Assumptions/dependencies: Highly reliable verifiers; regulatory approval; extensive scenario coverage before live use.
Notes on cross-cutting dependencies
- Token fidelity: Success depends on using the same tokenizer and returning token IDs/logprobs from the inference backend; Polar’s prefix_merging assumes append-only segments for safe merging, otherwise falls back to per_request.
- Verifiers: Outcome/process rewards require robust, domain-appropriate verifiers; weak verifiers risk reward hacking or mis-optimization.
- Governance: Interposing on model calls introduces logging and routing responsibilities; ensure compliance with contracts, privacy laws, and data retention policies.
- Infrastructure: Container isolation (Docker/Apptainer), artifact storage, and callback mechanisms are required; performance hinges on scheduling prewarm and handling long-tail runtimes.
Glossary
- Agent harness: An application-specific framework that drives an agent’s interactions, tools, and context policy during execution. "Polar runs an existing agent harness inside an isolated runtime"
- Agentic RL: Reinforcement learning focused on multi-step, tool-using agents interacting with complex environments and long contexts. "This shift makes the training target itself a central systems challenge for agentic RL."
- Apptainer: A container runtime (not requiring root privileges) commonly used on HPC systems for isolated execution. "Our first release supports Docker and rootless Apptainer for HPC setup."
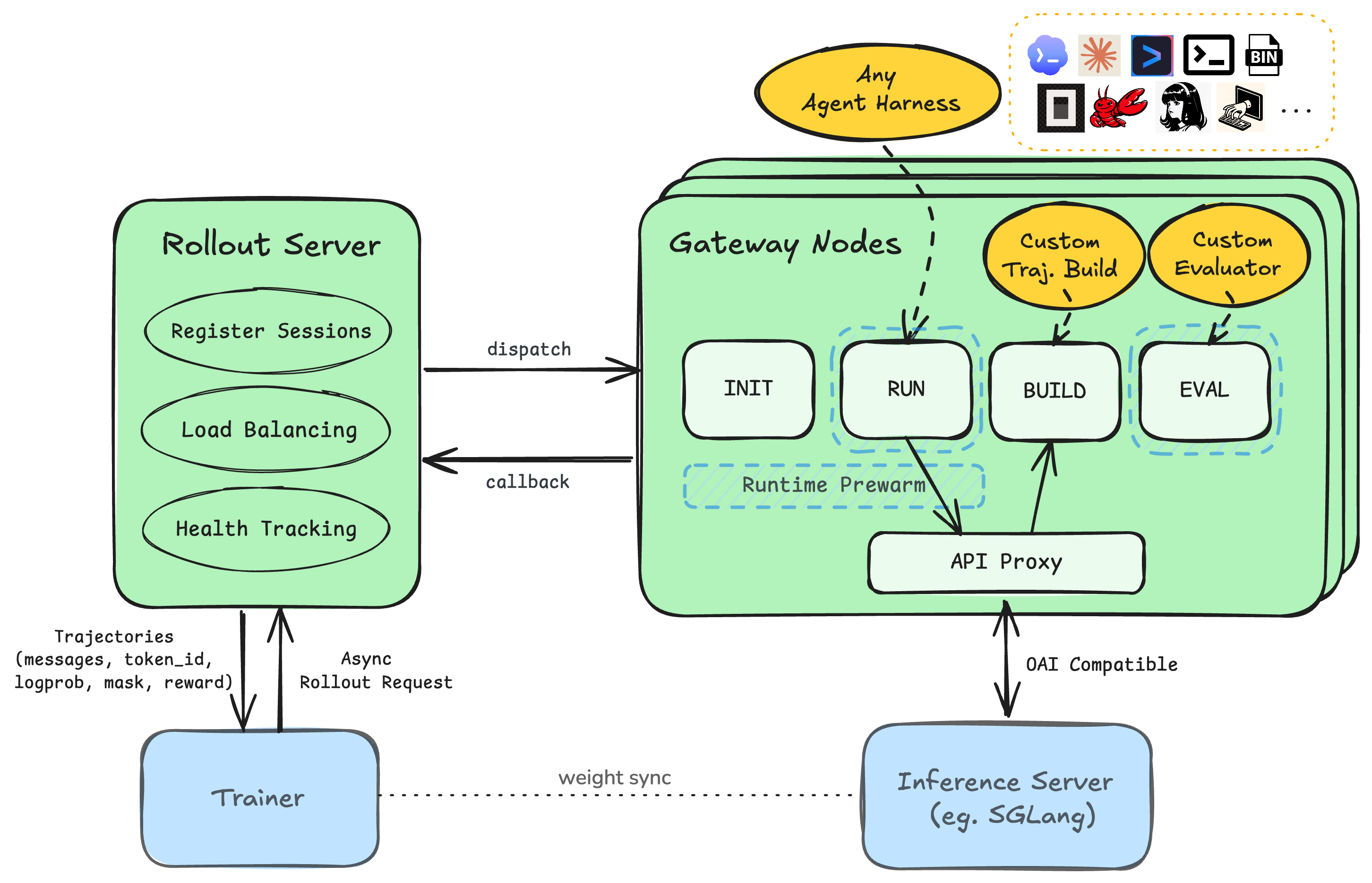
- Behavior policy: The policy that actually generated the observed actions/tokens during rollout, to which training signals must align. "Every trainable token matches the behavior policy during rollout, and any non-generated tokens are masked out."
- Canonical server rendering: A standardized, provider-side reconstruction of messages (e.g., previous turns) used to form the next prompt. "The main challenge is that p_{m+1} contains a canonical server rendering of the previous assistant turn plus the interstitial context inserted by the harness before the next generation prompt."
- Credit assignment: The RL problem of attributing overall outcomes to specific steps or decisions within a trajectory. "The issue is noisy credit assignment: request-level traces can receive session-level credit without proper session normalization or an advanced process reward model."
- End-of-turn token: A special token that marks the boundary between turns in chat-like generations. "Let denote the end-of-turn token ID."
- Evaluator: A post-run component that assigns rewards or outcomes to traces or sessions based on task-specific criteria. "After execution, an evaluator assigns an outcome or trace-level reward."
- GRPO: A reinforcement learning objective/method used for preference/outcome-optimized post-training of LLMs. "Using simple GRPO, Polar improves Qwen3.5-4B by 22.6, 4.8, 0.6 and 6.2 points on SWE-Bench Verified with the Codex, Claude Code, Qwen Code and Pi harnesses, respectively."
- Gymnasium-style interface: A standardized RL environment API pattern (inspired by OpenAI Gym/Gymnasium) that agents interact with. "SkyRL-Gym providing tool-use environments through a Gymnasium-style interface."
- Inference backends: The model-serving systems that perform actual token generation and return token IDs and log probabilities. "log probabilities from inference backends."
- Interstitial tokens: Non-generated context tokens inserted between agent turns (e.g., system wrappers or tool-return formatting) that should be masked during training. "generated assistant tokens are copied from inference responses, non-generated interstitial tokens are taken from canonical prompt tokenization"
- Loss mask: A per-token mask indicating which tokens should contribute to the training loss (typically only behavior-policy tokens). "the loss mask marks only behavior-policy tokens as trainable."
- MCP servers: Model Context Protocol servers that expose tools/skills to agents via a standardized interface. "It may install configuration, register MCP servers or skills, write provider settings, and return the shell commands that run the agent."
- Model API proxy: A gateway that intercepts and normalizes model API calls, captures token-level data, and forwards requests to inference servers. "places a model API proxy between the harness and the inference server."
- pass@1: An evaluation metric measuring the fraction of tasks solved in a single attempt. "Scores are pass@1 over the full benchmark, running on corresponding harnesses."
- Prefix merging: A trajectory-reconstruction strategy that merges calls into longer traces when prompts form strict token prefixes, masking only interstitial tokens. "Polar prefix merging algorithm copies only sampled assistant tokens as trainable tokens and masks canonical interstitial tokens"
- PRM-style credit assignment: A process reward model (PRM) approach that assigns finer-grained rewards across steps within a trajectory. "Those mechanisms are outside the scope of this work, but providing examples and tools for session normalization and PRM-style credit assignment is on our roadmap."
- Retokenization drift: Mismatch in tokenization when text is decoded and re-encoded, causing token IDs to differ from those used during generation. "The vLLM and Agent Lightning discussion of retokenization drift emphasizes that decoding and re-encoding a transcript can produce different token IDs from the original generation"
- Rollout-as-a-service: A system design that decouples rollout generation from training via asynchronous service boundaries. "Rollout-as-a-service architecture for scaling RL infrastructures."
- Runtime prewarming: Proactively initializing execution environments to reduce latency before agent runs. "Each rollout node efficiently manages runtime prewarming, agent execution, trajectory reconstruction, and evaluation in parallel"
- Server-sent events: A streaming mechanism where the server pushes events to the client over HTTP, often used for token streams. "preserving compatibility with harnesses that expect server-sent events."
- SGLang: An efficient LLM serving/execution engine used for scalable rollout or data-generation pipelines. "Slime similarly connects Megatron training with SGLang rollout engines and exposes customizable data-generation interfaces."
- Stale-policy step semantics: An async-training pattern where rollouts may be generated by older (stale) policy versions to increase throughput. "PRIME-RL focuses on large-scale asynchronous RL with trainer-inference separation, stale-policy step semantics, and support for verifiers environments."
- SWE-Bench Verified: A benchmark/evaluator for software-engineering tasks that checks patches against test suites for correctness. "Using simple GRPO, Polar improves Qwen3.5-4B by 22.6, 4.8, 0.6 and 6.2 points on SWE-Bench Verified with the Codex, Claude Code, Qwen Code and Pi harnesses, respectively."
- SWE-Gym: A software-engineering environment suite and dataset for training and evaluating agents on code tasks. "SWE-Gym GRPO training curves."
- Token fidelity: The requirement that training targets align exactly to the tokens actually sampled by the behavior policy. "Token Fidelity and Retokenization Drift"
- Tool schemas: Structured formats (e.g., JSON definitions) specifying tool inputs/outputs that agents must follow. "unfamiliar tool schemas"
- Trajectory builder: The component that converts captured model calls into trainable traces with token IDs, masks, and metadata. "The trajectory builder interface converts an ordered CompletionSession into a Trajectory."
- Trajectory reconstruction: The process of turning raw, captured LLM interactions into coherent training samples. "Trajectory reconstruction example."
- Trainer-agnostic: Designed to work with any training framework without requiring framework-specific coupling. "exposing a trainer-agnostic rollout-as-a-service interface for scaling efficient RL infrastructures"
- vLLM: A high-performance LLM inference library that returns token IDs/logprobs and is central to discussions of token fidelity. "The vLLM and Agent Lightning discussion of retokenization drift emphasizes that decoding and re-encoding a transcript can produce different token IDs from the original generation"
- Verifier: An automated checker that validates agent outputs (e.g., patches) against tests or rules to produce rewards. "We deliberately kept the filter narrow—a single binary verifier from the existing SWE-Bench harness"
Collections
Sign up for free to add this paper to one or more collections.

