ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Abstract: Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ProRL Agent, a system that helps train “multi-turn” AI agents—chatty AI models that solve tasks by taking many steps, like fixing code, doing math, browsing the web, or using a computer. The big idea is “rollout-as-a-service”: instead of mixing the messy, step-by-step practice runs (called rollouts) into the training program itself, ProRL Agent runs those practice runs as a separate, easy-to-use online service. This makes training faster, more reliable, and easier to manage at large scale.
What questions did the researchers ask?
The authors focused on a few simple questions:
- How can we make it simpler and faster to run lots of multi-step practice runs for AI agents during training?
- Can we separate (decouple) the parts that “do” the task from the parts that “learn” from it, so each can be improved independently?
- Can we support many different kinds of tasks (coding, math, STEM, web) in a safe, isolated way—even on shared computers where you don’t have admin rights?
- Will this setup actually improve agent performance and scale well to many machines?
How did they build it? (In everyday terms)
Think of training an agent like coaching a team:
- The “rollout” is the practice session: the agent tries a task step-by-step, using tools (like a shell, a Python interpreter, or a web search), and we record everything it did and how well it did.
- The “trainer” is the coach: it looks at many practice sessions and adjusts the agent so it gets better over time.
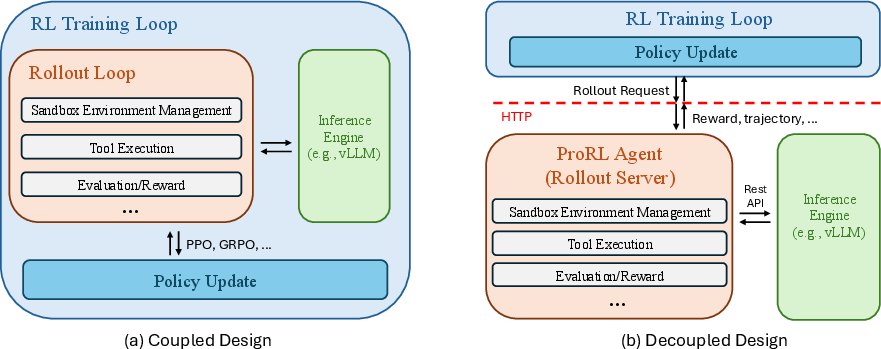
Most systems mix coaching and practice into one big process, which can get messy. ProRL Agent separates them:
- The trainer (coach) sends a task to a separate rollout server.
- The rollout server runs the practice session inside a safe “sandbox,” collects results, and sends back the full transcript and a score.
- The trainer uses that feedback to improve the agent—and never has to worry about how the practice session was run.
Key pieces of the system
- Rollout-as-a-Service (via HTTP): The rollout server is like a dedicated “practice facility.” The trainer sends tasks over a simple web API and gets back the step-by-step transcript and reward. This keeps training (GPU-heavy math) separate from rollouts (tool- and I/O-heavy work).
- Sandboxed environments (safe, portable workspaces): Agents run inside containers (think: a clean, disposable computer-in-a-box) using a tool called Singularity. It doesn’t need admin permissions, so it works on shared clusters (like a school lab or HPC) where you can’t install system software. This keeps tasks isolated, repeatable, and secure.
- Token-in/Token-out (no “mistranslations”): AI models read and write in tiny pieces called tokens. If you convert text to tokens in different ways at different steps, you can break learning. ProRL Agent passes around the exact token IDs produced by the model, so the trainer learns from exactly what the agent generated—no accidental changes.
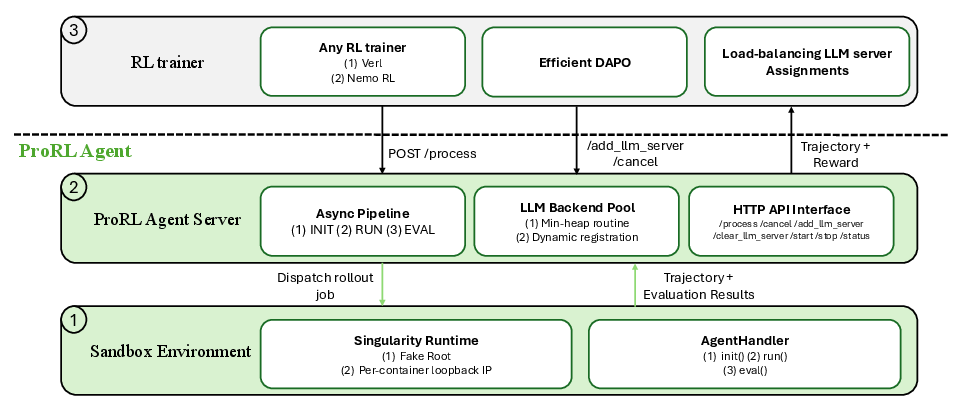
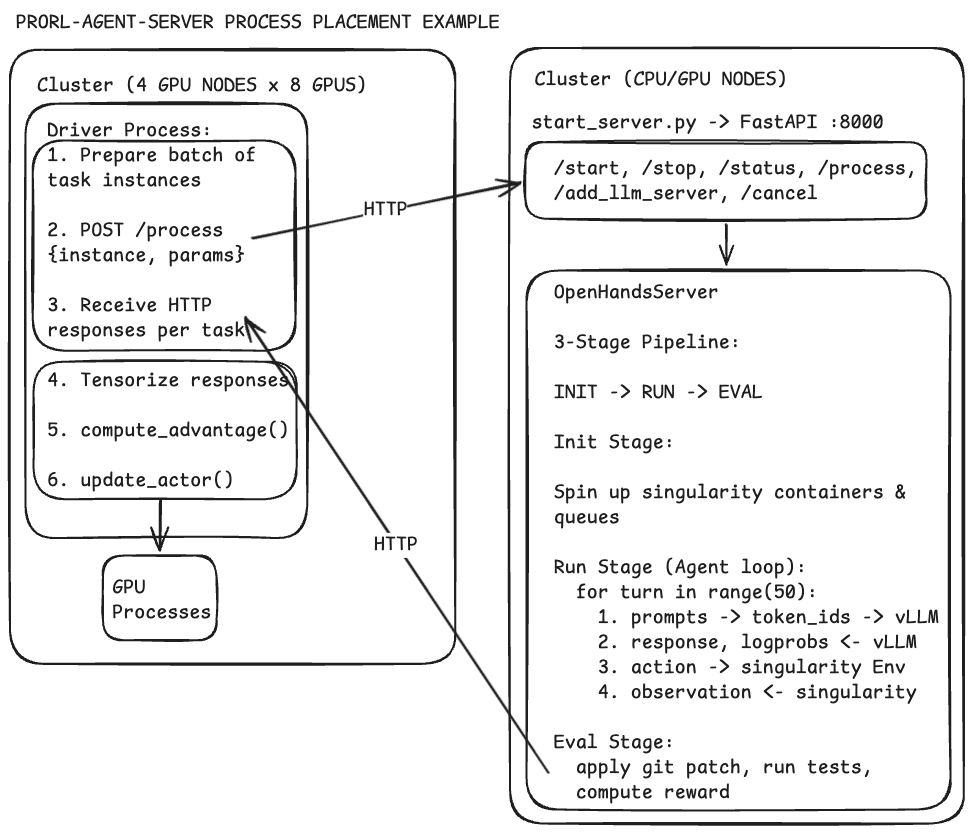
- Three-stage “assembly line”: init → run → eval: Rollouts are split into three phases:
- init: set up the sandbox and tools,
- run: the agent acts step-by-step,
- eval: grade the result.
- Different worker teams handle each phase, like stations on an assembly line, so the whole system runs faster and doesn’t get stuck behind the slowest step.
- Smart model load balancing: When lots of agents need model responses at once, ProRL Agent keeps a pool of model servers and always picks the least-busy one (like joining the shortest checkout line). It keeps all steps of a single task on the same server to reuse context and save time. You can also swap model checkpoints on the fly without restarting everything.
- Faster tools inside the sandbox: They sped up common actions:
- Shell commands run through a lightweight terminal (no extra tmux overhead).
- Python runs in a persistent IPython session without going through a networked Jupyter gateway.
- Actions communicate using Unix domain sockets (fast local messaging) instead of TCP, cutting latency.
- Job control and timeouts: Trainers can cancel tasks that aren’t needed anymore, set fair timeouts, and shut down cleanly—so resources aren’t wasted.
What did they find, and why is it important?
- Better results on real tasks: Using ProRL Agent to train models for software engineering improved scores on a standard benchmark (SWE-Bench Verified) across different model sizes (4B, 8B, 14B parameters). In some cases, gains were big compared to other systems.
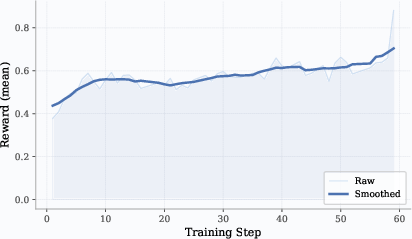
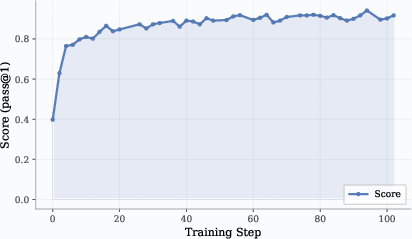
- Works across domains: They trained agents for STEM questions (with web search), math (with Python for checking and solving), and coding (editing files, running tests). In all three, performance steadily improved during training.
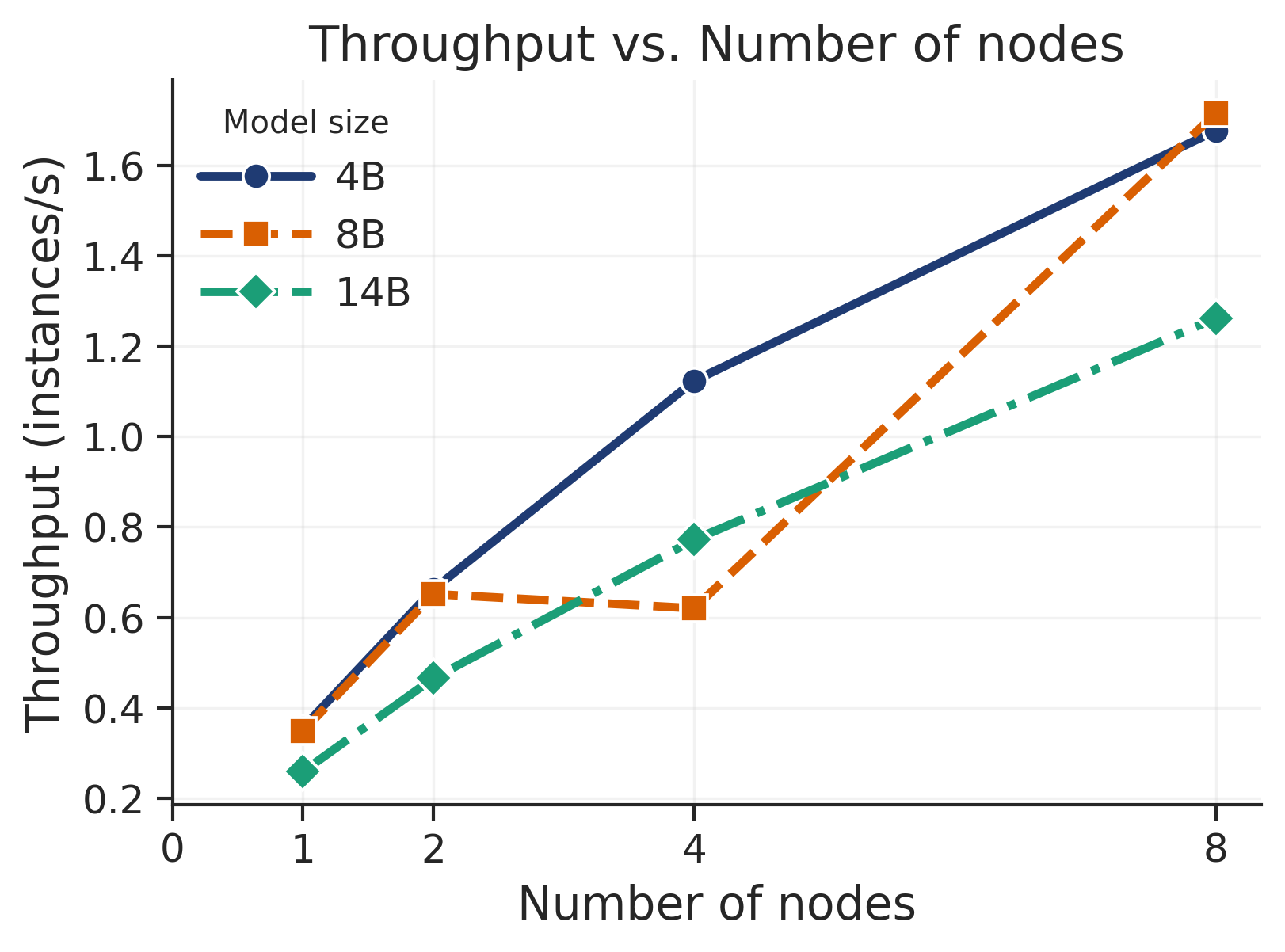
- Scales well: When they added more machines, the number of rollouts per second went up almost linearly—meaning the system can handle lots more practice runs efficiently.
- Each part helps: Ablation tests (turning features on/off) showed that load balancing, faster shell/Python tools, and cleaning up stale jobs each boosted throughput and GPU use—evidence the design choices matter.
These results show that separating rollouts from training, speeding up tool use, and managing resources carefully can make training long, multi-step agents both faster and more reliable.
Why does this matter? (Impact)
- Faster progress: Researchers and developers can train smarter agents more quickly because the rollout “practice” is handled by a dedicated, scalable service.
- Easier to maintain and extend: You can add new task types by writing small plugins, swap models without rewiring the system, and mix and match different training frameworks.
- Works in real-world computing setups: Because it runs “rootless,” teams can use shared clusters without special permissions, making large-scale experiments practical.
- Better agents for complex tasks: As agents get better at using tools over many steps, they can take on more realistic jobs—like fixing software, verifying math with code, or combining browsing with reasoning—reliably and at scale.
In short, ProRL Agent is like building a dedicated, efficient practice facility for AI agents. It keeps practice runs organized, fast, and safe—so the coaching (training) can focus on making the agent smarter, not on juggling logistics.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concrete, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to help future researchers design follow-up experiments, system extensions, or analyses.
Evaluation Scope and Rigor
- Insufficient head-to-head system benchmarks against coupled trainers: no quantitative comparison of throughput, latency, cost, or utilization when rollout is decoupled vs. embedded in the trainer across identical workloads.
- Limited ablation coverage: the ablation table is truncated and only partially assesses “Load Balancing,” “Efficient Bash,” and “Stale Job Cleanup.” Missing microbenchmarks for UDS vs. TCP loopback, IPython in-process vs. Jupyter kernel gateway, and stage-wise worker pool sizing strategies.
- Lack of scalability stress tests: no characterization of bottlenecks and failure modes at high concurrency (e.g., 1k+ concurrent rollouts), long-horizon tasks (100+ turns), or multi-node pooling of hundreds of LLM backends.
- No statistical rigor for reported gains: missing variance across seeds, confidence intervals, and significance tests; unclear reproducibility of SWE-Bench, AMC, and Codeforces gains under repeated runs.
- Unclear apples-to-apples comparisons: training data splits, reward definitions, and compute budgets differ or are not fully specified relative to baselines (e.g., SkyRL-v0), hindering fair comparisons.
- Absent cross-domain standardized benchmarks: while examples include SWE, math, STEM, and coding, there is no evaluation on widely-used multi-turn agent suites (e.g., WebArena, OSWorld) with standardized, reproducible protocols.
RL Algorithmic Questions (DAPO and On-Policy Training)
- Bias from zero-variance filtering: no analysis of how DAPO’s filtering affects gradient bias, distribution shift across iterations, or long-term stability in multi-turn settings.
- On-policy lag and policy staleness: despite backend swapping and cancellation, there is no quantitative study of policy lag introduced by the pipeline (e.g., how “old” the policy is for in-flight jobs) and its impact on learning dynamics.
- No comparisons to alternative RL algorithms: missing empirical head-to-head with GRPO, PPO, RPO, and off-policy methods on identical rollouts to understand where DAPO is preferable or insufficient.
- Credit assignment with delayed/sparse rewards: no investigation of reward shaping strategies or credit assignment improvements (e.g., per-step rewards, hindsight relabeling) for long-horizon agent tasks.
Token-In/Token-Out Assumptions and Limits
- Cross-backend tokenizer compatibility: token-in/out relies on consistent tokenization; no guidance or tooling for mixed tokenizer regimes (e.g., different model families) or checkpoint swaps that change tokenizers.
- External observation tokenization drift: while assistant turns preserve IDs, environment observations are re-tokenized; no quantification of residual drift or its training impact.
- Logprob availability and fidelity: assumes LLM backends expose per-token logprobs reliably; no evaluation across engines with differing logprob semantics or precision.
LLM Backend Pooling and Scheduling
- Latency- and size-aware routing: current min-heap by assignment count ignores heterogeneous server latency, capacity, quantization, or cache state; no adaptive policy that accounts for stragglers or hardware heterogeneity.
- Health checks and fault recovery: no proactive liveness/health probing of LLM servers, nor policies for mid-rollout backend failures or automatic re-routing with cache warm-up strategies.
- Sticky assignment trade-offs: sticking an entire task to one backend improves cache reuse but may amplify tail latency; no analysis of when to break stickiness or split long rollouts.
Sandbox Security, Isolation, and Determinism
- Security hardening: no threat model or analysis of container breakout risks, side channels, filesystem leaks between jobs, or misuse of fakeroot in Singularity.
- Network policy and provenance: incomplete specification of egress controls (e.g., for web search tools), content provenance, and snapshotting/caching strategies for reproducible web-dependent tasks.
- Determinism and flakiness: no systematic handling of nondeterministic tests (e.g., timeouts, network variance), or reproducibility guarantees for evaluation scripts and OS-level tools.
- Multi-tenant isolation in HPC: missing resource quota policies (CPU, memory, disk, network) per container and enforcement to prevent noisy-neighbor effects.
HPC Deployment Practicalities
- Image distribution bottlenecks: no analysis of SIF image size, distribution time on shared filesystems, or incremental update strategies under frequent template changes.
- GPU access and scheduler integration: limited detail on Slurm integration for GPU scheduling, MIG/partitioning, and coordination between rollout and training queues across nodes.
- Rootless constraints across HPC variants: broader validation across different Singularity/Apptainer versions, network interconnects, and cluster security policies is absent.
System Reliability, Control, and Observability
- Job lifecycle guarantees: no formal semantics for exactly-once processing, idempotent retries, or persistent recovery (checkpoint/resume) for partially completed multi-turn rollouts.
- Backpressure and queue control: no explicit mechanisms for prioritization, fairness, or backpressure when trainers overproduce jobs or LLM pools become saturated.
- Monitoring, tracing, and debugging: missing built-in telemetry standards (metrics, logs, spans) for end-to-end tracing of agent actions, tool latencies, and reward evaluation; no guidance on diagnosing long-tail failures.
- HTTP transport limitations: no comparison to streaming or binary RPC (e.g., gRPC), TLS/auth for multi-tenant deployments, or overhead measurements for large token payloads.
Reward Design and Evaluation Integrity
- Reward hacking and leakage: tests-as-rewards can be gamed (e.g., overfitting to public tests, artifact leakage); no safeguards like sandboxed validators, randomized hidden tests, or mutation testing.
- Partial credit and shaping: sparse pass/fail rewards dominate; no exploration of graded rewards (e.g., fraction of tests passed, tool-correctness signals) to improve learning signal density.
- Cross-domain reward standardization: no reusable reward schemas for common agent tasks (browser, OS control), slowing reproducibility.
Breadth of Tasks and Tools
- Browser/GUI/OS tasks underrepresented: while QEMU-based VMs are mentioned, no empirical validation on GUI-heavy tasks or OSWorld-like settings with stateful desktop interactions.
- Tool coverage and performance: optimization focused on bash/IPython/UDS; missing evaluation for editors, debuggers, browsers, databases, and networked tools under high concurrency.
- Multi-agent or collaborative tasks: no support or benchmarks for multi-agent coordination, tool sharing, or communication protocols between agents.
Cost, Efficiency, and Environmental Impact
- Compute and cost accounting: missing reporting of token throughput, wall-clock training time, energy use, and dollar costs per performance gain for different model sizes and domains.
- Data efficiency vs. throughput trade-offs: no analysis of how infrastructure choices (decoupling, caching, UDS) affect sample efficiency and total training steps to target performance.
API, Extensibility, and Community Standards
- Handler API stability and versioning: no specification of semantic versioning, compatibility guarantees, or migration guides for AgentHandler and runtime interfaces.
- Interoperability with third-party trainers: beyond NeMo RL and VeRL, there is no demonstration of integration with other RL stacks, nor a neutral schema for trajectories and rewards.
- Dataset and artifact management: unspecified storage formats for token-level trajectories, compression, privacy filtering, and deduplication; no guidance on releasing generated datasets.
Theoretical and Methodological Foundations
- Convergence and stability of asynchronous DAPO: no theoretical treatment or empirical stress tests for convergence under long-horizon, delayed-evaluation, and cancellation-heavy regimes.
- Effect of phase-aware timeouts: no study of bias introduced by timeouts, especially if longer/complex tasks are systematically truncated more often.
Documentation and Reproducibility
- Reproducibility kits: missing detailed runbooks with exact config files, seeds, image hashes, and LLM checkpoints to reproduce each reported curve and table.
- Licensing and data governance: unclear licensing for integrated tools (e.g., Tavily), and compliance considerations for training logs and web-scraped content.
These gaps suggest concrete next steps: build standardized system and RL baselines; add reliability and security layers; extend routing, observability, and HPC policies; diversify domains and tools; formalize API/versioning; and rigorously analyze DAPO and token-in/out assumptions under real-world constraints.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by leveraging ProRL Agent’s rollout-as-a-service architecture, rootless sandboxing, token-in/token-out trajectory handling, optimized tool backends, and management APIs.
- Enterprise RL training for code agents (software engineering)
- Use case: Train and continuously improve bug-fixing, refactoring, and repo-maintenance agents against verifiable test suites (e.g., SWE-Bench Verified), integrated with CI/CD.
- Tools/workflows: Implement task-specific AgentHandler; run sandboxes with SingularityRuntime; manage LLM inference via /add_llm_server and checkpoint swap with /clear_llm_server; use DAPO filtering to prioritize informative tickets.
- Sector(s): Software, DevTools.
- Dependencies/assumptions: Availability of verifiable tests; vLLM or similar LLM servers; Slurm/Apptainer/Singularity on-prem or cloud; policy for safe tool permissions (networking, file access).
- Rootless, HPC-friendly agent training and evaluation (academia and enterprise R&D)
- Use case: Run large-scale multi-turn rollouts on shared clusters without Docker daemon privileges, enabling reproducible agent experiments at lab or enterprise scale.
- Tools/workflows: SingularityRuntime with --fakeroot and optional --network none; per-job lifecycle (init → run → eval); pipeline stage worker pools; min-heap LLM backend balancing.
- Sector(s): Academia, Public research labs, Enterprise R&D.
- Dependencies/assumptions: Slurm and shared filesystems; security posture allowing unprivileged containers; cluster admins endorsing Apptainer/Singularity.
- MLOps-ready rollout service for decoupled RL pipelines
- Use case: Treat agent rollouts as a shared internal service used by multiple training teams; standardize rollout orchestration and resource isolation separate from GPU training clusters.
- Tools/workflows: HTTP management endpoints (/process, /cancel, /start, /stop); three-stage pipeline; per-job cancellation and phase-aware timeouts; centralized observability.
- Sector(s): Software, Platform engineering.
- Dependencies/assumptions: Organizational buy-in for service-oriented training; service discovery and auth; inference autoscaling.
- Cost and throughput optimization for tool-using agents
- Use case: Cut latency and cost of long-horizon rollouts by adopting ptyprocess-based Bash, in-process IPython kernels, and Unix domain sockets (UDS) for intra-container IPC.
- Tools/workflows: Swap tmux for ptyprocess; direct IPython API; UDS between agent and execution server.
- Sector(s): Software, Data/ML engineering.
- Dependencies/assumptions: Compatible host OS; robust sandbox isolation to mitigate shell/code execution risks.
- Token-in/token-out training data logging and auditability
- Use case: Produce token-aligned, logprob-carrying trajectories to avoid re-tokenization drift and enable faithful replay, analysis, and debugging of agent behavior.
- Tools/workflows: Preserve input_ids/output_ids/logprobs end-to-end; train RL models directly from token IDs produced during rollout.
- Sector(s): Software, AI safety, Compliance.
- Dependencies/assumptions: Consistent tokenizer across inference and training; secure storage for token-level logs; PII/secret handling.
- STEM, math, and programming tutors (education and upskilling)
- Use case: Train tool-using tutoring agents (web search, IPython) for problem-solving and verification on STEM datasets (e.g., SCP-116K, AMC, competitive programming).
- Tools/workflows: AgentHandlers for STEM/math/code; Tavily search; IPython execution kernels; DAPO to emphasize informative problems.
- Sector(s): Education, EdTech.
- Dependencies/assumptions: Dataset licensing; content filtering for web search; GPU capacity for RL; clear reward functions and graders.
- Secure AIOps sandbox for incident-response agents
- Use case: Develop and validate agents that execute shell commands to diagnose or remediate incidents in a locked-down environment before promoting playbooks to production.
- Tools/workflows: Network-restricted containers; per-stage exception callbacks; early termination via /cancel for stale rollouts; audit logs.
- Sector(s): IT operations, SRE/DevOps.
- Dependencies/assumptions: Accurate simulators and safe command whitelists; separation from production systems; security review of sandbox configs.
- Benchmarking and evaluation harness for agentic tasks
- Use case: Standardize agent evaluation for internal or public benchmarks (SWE-Bench-style, OSWorld-like) with reproducible sandboxes and test runners.
- Tools/workflows: Handler plugins per benchmark; run/eval lifecycle; standardized final_result serialization for metrics ingestion.
- Sector(s): Software, Academia.
- Dependencies/assumptions: Benchmark artifacts and harnesses packaged into .sif images; repeatable environment seeds and pinned dependencies.
- Campus-scale teaching infrastructure for tool-using agents
- Use case: Enable students to train and evaluate agents on shared HPC clusters without needing Docker access, suitable for courses on RL, systems, and agentic AI.
- Tools/workflows: SingularityRuntimeBuilder with template caching; per-student HTTP quotas; example handlers for coding/REPL tasks.
- Sector(s): Education.
- Dependencies/assumptions: Instructor-provided images; fair-share scheduling; minimal per-student privileges; course IT support.
- Internal “rollout-as-a-service” platform offering
- Use case: Central platform team provides rollout capacity to multiple product groups (e.g., fraud bots, analytics agents) with dynamic scaling of LLM backends and policies.
- Tools/workflows: Multi-tenant queueing; min-heap LLM server pool; dynamic checkpoint registration; SLOs on latency/throughput.
- Sector(s): Finance, E-commerce, SaaS.
- Dependencies/assumptions: Access control and tenancy isolation; chargeback/showback model; governance for data and tool access.
Long-Term Applications
These applications are feasible with further research, scaling, productization, or tighter integration with domain systems and policies.
- Self-improving enterprise developer assistants
- Vision: Agents continuously learn from real repositories/issues via verifiable tests, with automated curriculum and drift control.
- Tools/workflows: Closed-loop CI gate integrating rollout service, DAPO-informed sampling, checkpoint swapping, and guardrails.
- Sector(s): Software, Platform engineering.
- Dependencies/assumptions: High-quality reward functions across repos; automated safety filters; change-management signoff; robust rollback.
- Autonomous data engineering and analytics agents
- Vision: Agents that create/repair ETL pipelines, validate with synthetic tests, and propose PRs, trained with verifiable rewards in sandboxed data mirrors.
- Tools/workflows: Sandboxed data simulators; IPython and shell tools; test-suite evaluators; staged promotion workflows.
- Sector(s): Data platforms, Analytics.
- Dependencies/assumptions: Accurate data simulators; governance for data access; reproducible test cases; audit trails.
- Scientific-discovery notebooks with RL-trained tool use
- Vision: Agents that plan experiments in computational notebooks, run simulations, and verify hypotheses with domain-specific graders.
- Tools/workflows: Domain-specific handlers (chemistry/physics/biology); GPU/CPU hybrid runtimes; evaluation harnesses for scientific validity.
- Sector(s): Pharma, Materials, Academia.
- Dependencies/assumptions: Reliable simulators and metrics; IP/licensing of tools and datasets; reproducibility standards.
- Standardized “token-in/token-out” traceability for AI oversight
- Vision: Regulatory-grade trace packaging of token-level trajectories, rewards, and environment provenance to support audits and reproducibility.
- Tools/workflows: Trace schemas; cryptographic signing; retention policies; lineage dashboards.
- Sector(s): Policy, Compliance, AI governance.
- Dependencies/assumptions: Industry acceptance of trace standards; privacy-preserving logging; regulator guidance.
- Marketplace of verifiable rollout datasets
- Vision: Exchange of token-aligned, reward-labeled trajectories for agent RL in coding, STEM, and web tasks.
- Tools/workflows: Dataset packaging from final_result; provenance metadata; license-aware distribution.
- Sector(s): AI tooling ecosystem, Academia.
- Dependencies/assumptions: Legal clarity on code/data licenses; privacy and security; standardized handlers and graders.
- Cloud-native, multi-tenant rollout services
- Vision: Cloud providers offer managed rollout-as-a-service co-scheduled with inference clusters, supporting autoscaling and secure tenancy.
- Tools/workflows: Serverless handler plugins; autoscaled LLM backend pools; per-tenant quotas and isolation.
- Sector(s): Cloud, PaaS.
- Dependencies/assumptions: Strong multi-tenancy isolation; usage-based billing; integration with cloud networking policies.
- GUI/OS-level autonomous assistants in hardened VMs
- Vision: Agents that operate full desktops (browsers, apps) for RPA-like tasks, trained via RL with OSWorld-style sandboxes.
- Tools/workflows: QEMU/VM-based Singularity images; GUI brokers; human-in-the-loop safety gates; verifiable task scripts.
- Sector(s): RPA, Enterprise IT.
- Dependencies/assumptions: Robust GUI sandboxing; safe clipboard/file channels; realistic OS task graders.
- Healthcare document and coding assistants trained with verifiable tasks
- Vision: Agents that draft notes, extract structured fields, and perform medical coding with synthetic/verifiable benchmarks before limited deployment.
- Tools/workflows: PHI-safe sandboxes; token-level trace storage; domain graders (coding accuracy, consistency).
- Sector(s): Healthcare IT.
- Dependencies/assumptions: HIPAA/GDPR compliance; de-identification; clinically validated reward functions; rigorous evaluation.
- Finance research and backtesting agents
- Vision: Agents that write, test, and validate strategies in isolated sandboxes with verifiable backtests and policy constraints.
- Tools/workflows: Time-frozen market simulators; test harnesses; change-control workflows.
- Sector(s): Finance.
- Dependencies/assumptions: High-fidelity simulators; regulatory guardrails; strict isolation from live trading.
- Adversarial red-teaming and safety RL
- Vision: Train agents to probe systems under strict containment, with penalties/rewards shaping safer model behavior and robust defenses.
- Tools/workflows: Network-restricted sandboxes; exploit detectors; safety reward shaping; traceable token logs.
- Sector(s): Cybersecurity, AI safety.
- Dependencies/assumptions: Secure sandbox configs; curated exploit corpora; ethical and legal controls; robust scoring of unsafe behavior.
Glossary
- AgentHandler: A pluggable interface that encapsulates task-specific rollout logic via init, run, and eval lifecycle methods. "we encapsulate all task-specific logic in an abstract interface called AgentHandler"
- AMC: A mathematics benchmark (American Mathematics Competitions) used to evaluate math agents (e.g., Pass@1). "the Pass@1 performance on AMC improves steadily during RL training"
- asynchronous three-stage pipeline (INIT→RUN→EVAL): A rollout architecture that separates initialization, execution, and evaluation into independent worker pools to maximize throughput. "manages rollouts through a three-stage asynchronous pipeline (INIT~~RUN~~EVAL) with independent worker pools"
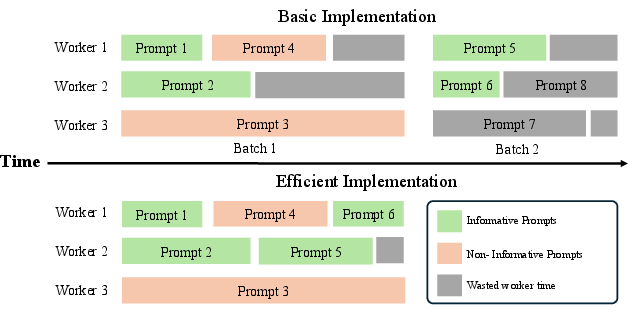
- DAPO (Dynamic Sampling Policy Optimization): An RL algorithm that improves data efficiency by filtering non-informative prompts and dynamically replenishing samples. "We adopt Dynamic Sampling Policy Optimization (DAPO)~\citep{yu2025dapoopensourcellmreinforcement} as our core reinforcement learning algorithm."
- DeepScaleR: A dataset for training math agents to improve problem-solving performance with tool use. "we use DeepScaleR~\citep{deepscaler2025} data for training"
- Docker: A container runtime commonly used for sandboxing that typically requires daemon/root access, which is problematic on HPC clusters. "but they deeply rely on Docker for agent execution."
- Eurus-2-RL-Data: A program synthesis dataset used for training code agents. "we use Eurus-2-RL-Data~\citep{yuan2024implicitprm} as the training data"
- fakeroot: A container mode that simulates root privileges inside the container without host-side root requirements. "Two flags address common HPC constraints: --fakeroot grants the container simulated root access"
- HPC (High-Performance Computing): Cluster environments with strict privilege controls and schedulers, requiring rootless, portable rollouts. "rootless HPC settings"
- HTTP service: A networked interface (via HTTP) that exposes rollout orchestration as an independent service decoupled from training. "an HTTP service that manages rollouts"
- Informative Prompts: Prompts whose rollouts produce non-uniform rewards and thus useful gradients for policy updates. "until Informative Prompts are collected"
- IPython kernel: A persistent interactive Python process that retains state across tool calls for efficient iterative computation. "A persistent IPython kernel makes this natural"
- Jinja2 templates: Templating system used to define and build reproducible container images for sandbox environments. "constructed from Jinja2 templates and supports three caching modes"
- Jupyter kernel gateway: A network-based interface to Jupyter kernels; avoided here to reduce local IPC overhead. "through the Jupyter kernel gateway"
- KL coefficient: The scalar weight on KL-divergence regularization used during RL training to constrain policy updates. "The KL coefficient is set to "
- LLM backends: A pool of model-serving endpoints used by the rollout server to distribute inference load dynamically. "LLM backends are registered and deregistered through the management API"
- loopback IP address: Localhost addresses (127.x.x.x) assigned per container to avoid port conflicts in concurrent rollouts. "each container instance is assigned a unique loopback IP address within the 127.x.x.x range"
- min-heap: A priority data structure used to load-balance LLM servers by assigning tasks to the least-burdened backend. "maintains a min-heap LLM backend pool supporting dynamic registration and checkpoint swapping."
- NeMo Gym: NVIDIA’s platform integrating tools and environments, into which ProRL Agent is incorporated. "integrated as part of NVIDIA NeMo Gym."
- NeMo RL: An RL training framework supported by the rollout server’s decoupled interface. "we support both VeRL~\cite{sheng2025verl} and NeMo RL~\cite{nemo-rl}."
- PausableTimer: A timer that only accumulates time during active pipeline phases, enabling phase-aware timeouts. "Each job is associated with a PausableTimer"
- Pass@1: A metric measuring the fraction of tasks solved by the first attempt. "the Pass@1 performance on Codeforces improves steadily"
- POMDP: A formalism (Partially Observable Markov Decision Process) for modeling multi-turn agent-environment interactions. "a multi-turn agent is naturally formulated as a POMDP"
- prefix cache reuse: Reusing cached prefix states in LLM serving to speed up successive generations within the same task. "to maximize prefix cache reuse."
- ptyprocess: A Python library for pseudo-terminal control used to provide direct shell access with lower latency than tmux. "We replace this with a ptyprocess-based direct pseudo-terminal"
- QEMU-based virtual machines: Emulator-backed VMs used for GUI-centric tasks within sandboxed environments. "For example, QEMU-based virtual machines used in GUI-centric tasks can provide custom definition files"
- re-tokenization drift: Mismatch introduced when re-tokenizing text, avoided by passing token IDs end-to-end. "to avoid re-tokenization drift"
- rootless deployment: Running containers without elevated privileges, critical for shared HPC clusters. "is designed for rootless deployment in shared cluster environments."
- rollout-as-a-service: Decoupling rollout generation from training by exposing it as a standalone service. "we adopt rollout-as-a-service as the core design principle"
- SCP-116K dataset: A STEM problem set used to train agents with web search and computation tools. "use the SCP-116K dataset~\citep{lu2025scp116khighqualityproblemsolutiondataset}."
- SIGKILL: A POSIX signal that forcefully terminates a process when graceful shutdown fails. "before escalating to SIGKILL if necessary."
- SIGTERM: A POSIX signal for requesting graceful process termination. "shutdown proceeds gracefully via SIGTERM"
- Singularity: An HPC-oriented container runtime that supports rootless execution and scheduler integration. "by building its sandbox infrastructure on Singularity"
- Singularity Image Files (.sif): Portable, single-file container images suitable for HPC filesystems and schedulers. "Container images are packaged as Singularity Image Files (.sif)"
- SingularityRuntime: The paper’s rootless container execution layer for sandboxed rollouts. "we implement SingularityRuntime, a container system"
- Slurm: A workload manager commonly used on HPC clusters that restricts daemon/root access. "shared Slurm-managed HPC clusters."
- str_replace_editor: A file-editing tool enabling controlled source-code modifications during code-agent rollouts. "via str_replace_editor, which enables precise modification of source code"
- SWE-Bench Verified: A benchmark for evaluating software engineering agents on real-world bug-fixing tasks. "strong gains on SWE-Bench Verified."
- SWE-Gym: A software engineering task suite used for training/evaluation in the experiments. "on the 293-instance subset of SWE-Gym used in SkyRL-v0"
- Tavily: A web search backend used to supply external knowledge for STEM agents. "For the web search backend, we use Tavily."
- test-suite: A set of automated tests for validating agent outputs, sometimes long-running in evaluation. "full test-suite execution."
- token IDs: Integer token identifiers used to represent prompts and responses exactly during training. "using token IDs as the canonical representation"
- token-in/token-out: An interface convention passing tokenized inputs/outputs end-to-end to prevent drift. "it adopts token-in/token-out communication"
- tmux: A terminal multiplexer whose overhead is avoided by using direct pseudo-terminals. "Conventional implementations route bash commands through a tmux session"
- UDS (Unix domain sockets): Kernel-mediated IPC used instead of TCP loopback for lower-latency intra-container communication. "We replace it with Unix domain sockets (UDS)"
- vLLM server: A high-throughput LLM inference server; multiple instances are load-balanced by the rollout server. "A single LLM server (e.g., vLLM server) quickly becomes a bottleneck"
- VeRL: An RL framework supported by the rollout server’s management API. "we support both VeRL~\cite{sheng2025verl} and NeMo RL"
- Zero-Variance Prompts: Prompts whose rollouts yield identical rewards (all correct/incorrect), providing no learning signal. "DAPO enhances training stability and data efficiency by filtering out Zero-Variance Promptsâthose whose rollouts yield uniform rewards"
Collections
Sign up for free to add this paper to one or more collections.