OpenClaw-RL: Train Any Agent Simply by Talking
Abstract: Every agent interaction generates a next-state signal, namely the user reply, tool output, terminal or GUI state change that follows each action, yet no existing agentic RL system recovers it as a live, online learning source. We present OpenClaw-RL, a framework built on a simple observation: next-state signals are universal, and policy can learn from all of them simultaneously. Personal conversations, terminal executions, GUI interactions, SWE tasks, and tool-call traces are not separate training problems. They are all interactions that can be used to train the same policy in the same loop. Next-state signals encode two forms of information: evaluative signals, which indicate how well the action performed and are extracted as scalar rewards via a PRM judge; and directive signals, which indicate how the action should have been different and are recovered through Hindsight-Guided On-Policy Distillation (OPD). We extract textual hints from the next state, construct an enhanced teacher context, and provide token-level directional advantage supervision that is richer than any scalar reward. Due to the asynchronous design, the model serves live requests, the PRM judges ongoing interactions, and the trainer updates the policy at the same time, with zero coordination overhead between them. Applied to personal agents, OpenClaw-RL enables an agent to improve simply by being used, recovering conversational signals from user re-queries, corrections, and explicit feedback. Applied to general agents, the same infrastructure supports scalable RL across terminal, GUI, SWE, and tool-call settings, where we additionally demonstrate the utility of process rewards. Code: https://github.com/Gen-Verse/OpenClaw-RL


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
The paper introduces OpenClaw‑RL, a way to help AI “agents” (like chatbots or computer-using bots) get better simply by being used. After every action an agent takes, something happens next—a user replies, a program prints an error, a button changes on the screen. The authors call this the “next‑state signal.” Their key idea is: these next‑state signals already tell the agent how well it did (evaluation) and often how to do better next time (direction). OpenClaw‑RL collects those signals live and uses them to train the agent continuously, across many kinds of tasks.
What questions the paper asks
The researchers focus on three simple questions:
- Can we turn the “what happens next” after each agent action into useful feedback without extra labeling work?
- Can we use this feedback to train all kinds of agents—personal chat assistants, command‑line (terminal) bots, GUI (mouse-and-screen) bots, coding bots, and tool‑using bots—using one unified system?
- Is it better to learn from both “how good was that?” scores and “what should you do instead?” hints than from scores alone?
How it works (methods in plain language)
Think of an agent like a student doing steps in a project:
- After each step, the “next state” (what happens next) is like the teacher’s reaction or the test result.
- Sometimes the reaction is a score (good/bad). Sometimes it’s a helpful comment (try doing X instead).
OpenClaw‑RL turns both kinds of feedback into learning signals:
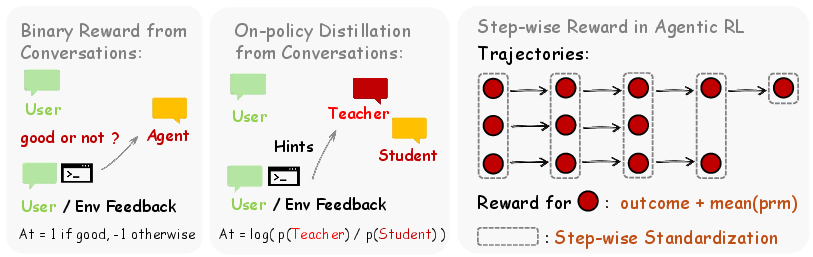
- Evaluative signals = “How well did you do?”
- The system uses a judge model (called a Process Reward Model, or PRM) to read the next state and give a simple reward (for example: +1 for helpful, −1 for harmful, 0 for unclear).
- This is like getting a thumbs‑up or thumbs‑down after each step.
- Directive signals = “How should you change?”
- Often the next state contains hints, like “You should check the file first” or an error message showing exactly what went wrong.
- OpenClaw‑RL extracts a short, clear hint from this using a judge model, adds that hint to the original prompt, and then compares what the model would have written with the hint versus without it.
- This technique is called Hindsight‑Guided On‑Policy Distillation (OPD). It gives token‑by‑token guidance—basically, it highlights which parts of the answer should be strengthened or weakened. Think of it as a teacher pointing to exact words or steps and saying “more like this” or “less like that,” not just giving a final score.
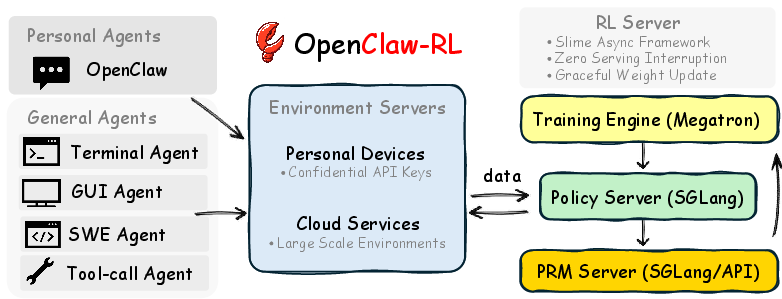
To make this work in real use, the system is built as four separate loops that run at the same time:
- Serving: answers users now.
- Environment: runs tasks (like a terminal or a GUI).
- Judge: scores steps and extracts hints.
- Trainer: updates the model in the background.
Because these parts don’t block each other, the agent can learn while it’s still being used, with no downtime.
The same setup works for:
- Personal agents (like your own conversational assistant), learning your preferences from your replies, corrections, and feedback.
- General agents (terminal, GUI, coding, tool‑using), learning from program outputs, test results, and API responses.
Finally, for long tasks, the system adds per‑step rewards (process rewards) to end‑of‑task rewards (outcome rewards). That way, the agent isn’t waiting until the very end to learn; it gets feedback at each step.
What they found (main results and why they matter)
Here are the main takeaways the authors report from their experiments and simulations:
- Learning just by being used works. A personal agent improved its style and behavior after a few dozen real interactions by using users’ re‑queries, corrections, and feedback as training signals.
- Two signals are better than one. Combining simple scores (evaluative signals) with concrete hints (directive signals) led to bigger improvements than using scores alone. The hints method (OPD) was especially powerful but used fewer, higher‑quality training examples; combining both gave the best of both worlds.
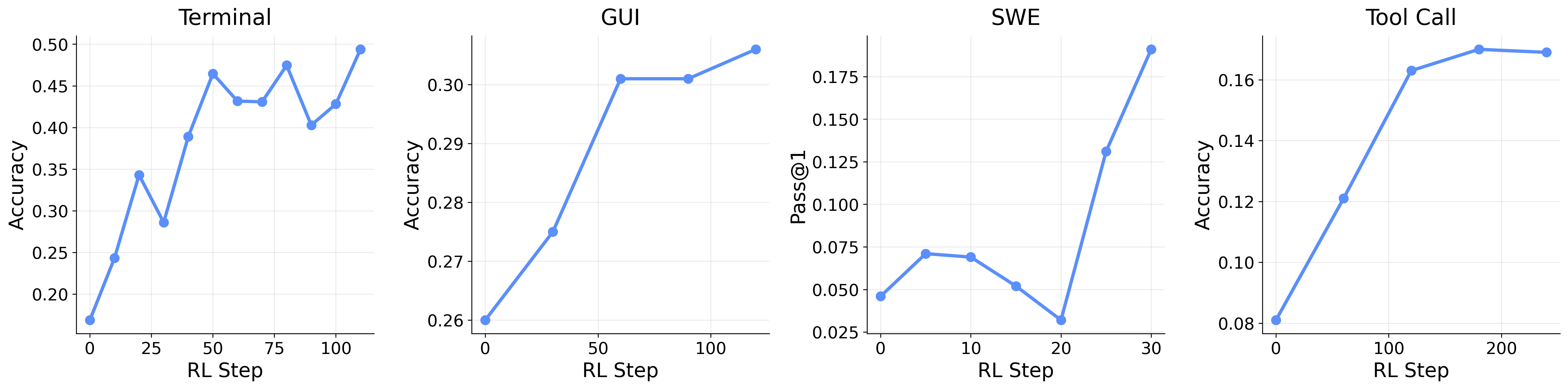
- One system, many agent types. The same training pipeline worked across terminal, GUI, coding (SWE), and tool‑call agents. This shows the approach is general and scalable.
- Step‑by‑step rewards help long tasks. Mixing per‑step “process” rewards with outcome rewards beat outcome‑only training, which makes sense: giving feedback at each step helps the agent know which parts of a long plan were helpful or harmful.
Why this matters:
- Agents can personalize to you over time without hand‑made datasets.
- Agents that use computers (clicking, typing, coding, calling tools) can learn faster and more reliably by listening to signals they already see.
- Continuous, live learning becomes practical because serving and training don’t interrupt each other.
What this could change (implications)
- Smarter personal assistants: Your assistant can adapt to your tone, preferences, and feedback as you use it, like a friend who learns your style.
- More reliable computer‑use bots: Terminal/GUI/coding agents can improve at long, multi‑step tasks by getting feedback at each step, not just at the end.
- Unified training for many tasks: Teams can use one framework to train many kinds of agents, making development simpler and faster.
- Practical continuous improvement: Because training, judging, and serving run in parallel, agents can improve in the background without pausing their service.
A few practical notes the authors hint at:
- Good judges matter: scoring and hint extraction need to be accurate to guide learning well.
- Privacy and safety are important: since learning comes from user interactions and system outputs, careful handling and filtering are needed.
- Extra compute: process reward models add cost, but they often pay off with better learning.
In short, OpenClaw‑RL shows how to turn the natural “what happens next” after every agent action into useful lessons, so agents can keep improving just by doing their jobs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research.
- Human-in-the-loop validation: Results for personal agents are based on simulated users and LLM-based judges; no A/B tests or longitudinal studies with real users measuring satisfaction, trust, or behavioral changes.
- Evaluation circularity and bias: The same (or closely related) LLM family is used for simulation and scoring in personalization experiments, risking bias and optimistic estimates; independent human or third-party evaluation is missing.
- Generalization beyond training sets: GUI evaluation is reported on (parts of) the training set; out-of-distribution generalization and robustness on held-out tasks are not assessed.
- Task correctness vs personalization trade-offs: Personalization is optimized and evaluated via style-oriented scores; effects on factual correctness, safety, and long-term task success are unmeasured.
- Multi-objective control: No mechanism or ablations for balancing correctness, safety, and personalization (e.g., CL-style constraints, multi-objective RL) are provided.
- PRM reliability and calibration: The PRM is used with majority voting but lacks validation of calibration, inter-judge agreement, robustness to noise, or domain transfer across modalities (terminal/GUI/SWE/tool-call).
- PRM training/data provenance: How PRMs are trained, tuned, or adapted across domains (and whether they are co-evolving with the policy) is unspecified; there is no analysis of judge–policy co-adaptation or reward hacking.
- Ambiguity handling in next-state signals: When user reactions are implicit or mixed, the PRM “makes an estimate”; the impact of label noise on learning stability and methods for uncertainty-aware filtering are not evaluated.
- Adversarial or misleading feedback: No defenses against malicious users or corrupted environments that inject deceptive next-state signals or hints; trust, provenance, and anomaly detection strategies are absent.
- OPD hint extraction quality: Precision/recall of the hint extractor is not quantified; no analysis of when hints help vs hurt, or error modes (e.g., verbose, off-topic, or incorrect hints).
- OPD for negative outcomes: The method describes hint generation when the judge assigns a positive score; the strategy for failures (negative outcomes) and how to derive corrective hints in that case is unclear.
- Teacher–student leakage in OPD: Using the same model as a “teacher” under a hint-augmented prompt may amplify existing biases and errors; the benefits vs risks (compared to stronger external teachers or ensembles) are not studied.
- Token-level advantage computation details: How per-token advantages interact with PPO ratios, clipping, normalization, and length biases is not fully specified or ablated; stability with per-token negative advantages is untested.
- Credit assignment beyond immediate rewards: Binary RL uses immediate, per-turn rewards without return-based credit (e.g., GAE, TD(λ)); effectiveness for delayed rewards in long-horizon tasks remains unexplored.
- Outcome/process reward aggregation: Outcome and process rewards are simply summed; no ablations on weighting schedules, normalization, discounting, or conflict resolution between signals.
- Step-index grouping for variance reduction: Grouping by step index (instead of state clusters) is heuristic; its statistical properties, bias/variance trade-offs, and alternatives are not evaluated.
- Data selection and coverage in OPD: Strict filtering for “valid hints” trades quantity for quality; the acceptance rate, coverage across scenarios, and impact on sample efficiency are not reported.
- Scheduling across heterogeneous streams: With a single policy learning from personal, terminal, GUI, SWE, and tool-call streams, there is no curriculum/scheduler to prevent negative transfer or mode collapse across tasks.
- Multi-tenant personalization: How to prevent cross-user interference (e.g., one user’s preferences degrading another’s experience) and whether per-user adapters or isolation mechanisms are needed is not addressed.
- Catastrophic forgetting: Continuous online updates (KL=0 in some personal settings) may erode general capabilities; safeguards, replay buffers, or regularization strategies are not evaluated.
- Safety and alignment drift: Learning directly from user signals can encode unsafe or manipulative behaviors; no content moderation, safety objectives, or alignment constraints are integrated or measured.
- Privacy and data governance: Personal-device interactions and logs are collected/retained; consent management, PII handling, minimization, on-device learning, or differential privacy are not discussed.
- Latency, cost, and scalability: The asynchronous architecture’s impact on user-perceived latency, throughput, and compute costs (especially PRM hosting) is not quantified; no profiling or scaling curves are shown.
- Stability under asynchronous updates: The system serves requests during training, but there is no analysis of stale-policy effects, safe rollout under mid-epoch updates, or rollback/canary deployment strategies.
- Robustness across modalities: PRMs and policies vary by setting (text-only vs vision-language), but cross-modal consistency, error propagation, and reliability (especially GUI PRM quality) are not assessed.
- Hyperparameter sensitivity: KL coefficients, clip ratios (including asymmetric upper bounds), and weights for combined objectives are fixed without ablations; stability regions and best practices are unclear.
- Group-relative standardization alternatives: The paper avoids GRPO-style standardization in personal settings but does not explore alternative variance reduction techniques suited to online, heterogeneous streams.
- Handling partial successes: Process rewards are ternary (+1/0/−1), which may be too coarse for nuanced progress; designing and evaluating graded PRMs remains open.
- Prompt-injection risk via hints: Appending hints to user messages could be exploited; delineation, sandboxing, and sanitization of hint content are undeveloped.
- Reproducibility and reporting: Key prompts, judge templates, acceptance thresholds, and implementation details (e.g., tokenization, sampling parameters) are not fully specified; statistical significance is not reported.
- Benchmark breadth: General-agent results are shown on a limited set (with training-set evaluation in GUI); broader, standardized benchmarks and cross-framework comparisons are needed.
- Unified single-policy vs per-domain models: Despite the claim that “one policy can learn from all,” experiments use different models per setting; feasibility and trade-offs of a single unified policy remain untested.
- Negative transfer analysis: There is no measurement of how training on one interaction type influences performance on others (e.g., GUI training affecting SWE or personal chat quality).
- Safety of the “avoid detection” use case: Optimizing to evade AI-detection in homework raises ethical issues; policies guarding against unethical optimization objectives are not considered.
- Update cadence and log purging: Logs are purged at weight updates, but how update cadence affects traceability, auditing, and the ability to diagnose regressions is not explored.
- Off-policy data use: All methods are framed as online/on-policy; whether and how to leverage stored trajectories safely (e.g., importance sampling, replay) is not investigated.
- Failure recovery: No mechanisms for detecting and reverting harmful updates (e.g., performance regressions, alignment drift) are described.
- Heterogeneous reward scales: Combining different PRMs and outcomes across tasks may cause scale mismatch; normalization/calibration across streams is not studied.
- Long-horizon robustness: Max step limits (e.g., 10–30) are relatively short; performance and stability on truly long workflows are untested.
Practical Applications
Immediate Applications
The following applications can be deployed today using the OpenClaw-RL framework and its methods (Binary RL via PRM and Hindsight-Guided On-Policy Distillation), leveraging the asynchronous, decoupled pipeline (serving with SGLang, training with Megatron, orchestration via slime) and supported environments (personal devices, terminal, GUI, SWE, and tool-call).
- Self-improving customer support and sales chatbots (customer service, SaaS)
- What: Bots that learn from user re-queries, thumbs-downs, escalations (evaluative) and explicit corrections (“please check account status first”) (directive).
- Tools/workflows: PRM majority vote for turn-level satisfaction; OPD hints from user replies; non-blocking logs; graceful weight updates with A/B gating.
- Dependencies/assumptions: PRM calibration to reduce label noise; user consent and data governance; compute budget for always-on training; rollbacks for regressions.
- Personal writing/communication assistants that adapt to individual style (productivity, education)
- What: Assistants that quickly personalize tone, structure, and vocabulary from users’ corrections and preferences (as demonstrated in the paper’s student/teacher simulations).
- Tools/workflows: On-device or private API deployment; OPD for token-level stylistic guidance; Binary RL for broad coverage.
- Dependencies/assumptions: Sufficient corrective signals; privacy and academic integrity controls; per-user model versioning or adapters.
- Teacher grading assistant aligned to rubric and tone (education)
- What: Grading copilot that learns to provide specific, friendly, rubric-aligned feedback from teacher edits and comments.
- Tools/workflows: OPD from reviewer comments; PRM from accept/reject or approval actions; session-aware logging for course/rubric context.
- Dependencies/assumptions: Clear ownership of data; bias and fairness auditing; institution policies on AI-assisted grading.
- DevOps and IT terminal agents that improve from execution feedback (software/IT operations)
- What: Shell agents that iterate faster by learning from stdout/stderr, exit codes, and operator hints.
- Tools/workflows: Terminal sandbox; step-wise PRM (process rewards) integrated with outcome signals; safe-command whitelists; rollback scripts.
- Dependencies/assumptions: Strong sandboxing and guardrails; deterministic repro environments; access controls.
- Adaptive GUI RPA bots for enterprise workflows (RPA, back-office automation)
- What: Screen automation agents that self-tune from GUI state diffs and task progress signals (form-filling, ERP, CRM).
- Tools/workflows: Accessibility tree capture; PRM for per-step progress; OPD from operator corrections (“click the second item”); parallel cloud-hosted environments.
- Dependencies/assumptions: Stable UI locators; permissioning for screen capture; handling of non-deterministic UIs and latency.
- SWE agents that learn from tests, diffs, and lints (software engineering)
- What: Coding agents that improve patch quality by using test verdicts (pass/fail), compiler diagnostics, and diffs as dense supervision.
- Tools/workflows: CI integration; test harnesses as outcome/process signals; OPD from error traces; step-wise PRM + outcome integration.
- Dependencies/assumptions: Reliable test coverage; safe write access to branches; code security scanning; revert mechanisms.
- Tool-call reasoning agents for BI/analytics and operations (finance, business intelligence, ops)
- What: Agents that query APIs/functions and learn from return values and error traces (e.g., data retrieval, reporting, monitoring).
- Tools/workflows: Tool-call PRM judging; OPD from operator prompts; rate-limit aware retries; step-indexed advantage standardization.
- Dependencies/assumptions: Stable APIs; secrets management; hallucination controls and schema validation.
- In-app product assistants that self-optimize from telemetry (SaaS/mobile)
- What: Embedded assistants that learn from user actions (undo/redo, re-open, abandonment) and optional micro-feedback prompts.
- Tools/workflows: Event instrumentation feeding PRM; lightweight hint prompts to elicit OPD; blue/green deployments for safe updates.
- Dependencies/assumptions: Consent and privacy controls; careful mapping from product events to evaluative rewards; network reliability for async pipeline.
- PRM-as-a-Service for step-wise rewards (ML tooling)
- What: Drop-in judge endpoints for step-level evaluation across domains (GUI progress, tool-call success, conversational satisfaction).
- Tools/workflows: Majority-vote PRM API; domain-specific prompt templates; dashboards for calibration and drift monitoring.
- Dependencies/assumptions: Domain adaptation of PRMs; hosting cost and latency; periodic re-calibration with ground truth.
- Continuous-learning MLOps control plane (MLOps/platform)
- What: A reusable RL control plane enabling non-blocking logging, live judging, training, and graceful weight updates across many agents.
- Tools/workflows: SGLang serving; Megatron training; slime orchestration; versioned weight rollouts; observability and rollback.
- Dependencies/assumptions: Cluster compute; SRE practices for high availability; strong monitoring and alerting.
- Accessibility and assistive GUI companions (assistive tech)
- What: Agents that reduce repeated misclicks or navigation errors by learning from user corrections and screen-state transitions.
- Tools/workflows: GUI next-state capture; OPD from “what I meant to do” hints; per-user personalization profiles.
- Dependencies/assumptions: Device permissions; low-latency interactions; privacy protections for sensitive content.
- Internal compliance/review copilot (legal/compliance)
- What: Drafting and review assistant that adapts to reviewer edits and approvals/rejections for policy or contract documents.
- Tools/workflows: OPD from reviewer notes; PRM from approval states; document-change tracking as next-state signal.
- Dependencies/assumptions: Audit trails; strict access controls; human-in-the-loop sign-off; bias/risk assessment.
Long-Term Applications
The following opportunities extend the paper’s methods to broader domains or require further research, scaling, or regulatory alignment before widespread deployment.
- Cross-modal, universal enterprise agent that learns across terminal, GUI, and tool-call streams (enterprise automation)
- What: A single policy that co-learns from diverse environments and continuously improves end-to-end workflows.
- Dependencies/assumptions: Robust PRMs across modalities; cross-domain replay and stability; strong safety interlocks; significant compute.
- Clinical decision and documentation assistants learning from outcomes and clinician feedback (healthcare)
- What: Agents that adapt to health-system protocols with step-wise PRMs (validated task progress) and OPD from clinician notes.
- Dependencies/assumptions: Regulatory approvals (HIPAA/GDPR), rigorous evaluation on patient safety, verifiable outcome labels, robust guardrails against reward hacking.
- Autonomous lab and scientific research assistants (R&D, life sciences)
- What: Agents controlling instruments or analyses that learn from experiment results and scientist feedback at each step.
- Dependencies/assumptions: Instrument APIs and safe automation layers; reliable process rewards; high-fidelity simulation for pretraining.
- Robotics and logistics agents using next-state sensor feedback and operator corrections (robotics, warehousing)
- What: Extending PRM/OPD to physical next-state signals (pose, task success) and operator guidance (teleop or post-hoc notes).
- Dependencies/assumptions: Real-time constraints; sim-to-real transfer; safety certification; robust reward design for non-text signals.
- Privacy-first, on-device, continuously trained personal OS agent (consumer OS, phones/PCs)
- What: An assistant that learns locally from user interactions without cloud logs, using on-device PRM and OPD.
- Dependencies/assumptions: Edge compute capacity; federated or differential privacy techniques; power/thermal constraints; secure model updates.
- Sector-specific PRM libraries and benchmarks (finance, energy, law)
- What: Curated, validated PRMs for step-wise evaluation (e.g., reconciliation progress in finance, procedure progress in energy, compliance checkpoints in law).
- Dependencies/assumptions: Domain expertise; ground-truth acquisition; ongoing calibration; community benchmarks.
- Self-optimizing CI/CD pipelines where agents repair failing builds/tests (software delivery)
- What: Agents that auto-triage and propose fixes, learning from test verdicts and reviewer accept/reject signals at each step.
- Dependencies/assumptions: Strict guardrails, security scanning, rollbacks, reproducibility, and code ownership policies.
- Adaptive education platforms with safe, per-learner personalization (edtech)
- What: Course assistants that adjust pedagogy and style from learners’ interactions and outcomes while enforcing academic integrity.
- Dependencies/assumptions: Clear policy boundaries (no cheating), fairness across demographics, offline evaluation against learning outcomes.
- Policy and standards for continuous-learning agents (public policy, governance)
- What: Frameworks for consent capture, update transparency, audit logs, and rollback rights in live-learning systems.
- Dependencies/assumptions: Cross-jurisdictional alignment; standardized telemetry and logging schemas; oversight bodies and audits.
- Safety research: robust OPD and anti-reward-hacking defenses (AI safety)
- What: Methods to detect exploitative behaviors, adversarial hints, or spurious PRM feedback in continuous learning loops.
- Dependencies/assumptions: Adversarial evaluation datasets; real-time anomaly detection; human red-team processes.
Notes on Cross-Cutting Assumptions and Dependencies
- PRM quality and calibration: Majority voting helps, but domain-specific prompt design, regular re-calibration, and validation against ground truth are critical for reliability.
- Hint extraction and sparsity: OPD benefits most when directive signals are available; strict filtering improves signal quality but may reduce sample volume—deploy alongside Binary RL for coverage.
- Privacy, consent, and logging: Non-blocking logs and per-weight-version records must be combined with opt-in consent, data minimization, and secure retention policies.
- Safety and guardrails: Especially in code, terminal, GUI, healthcare, and robotics settings, sandboxing, access control, rollbacks, and human-in-the-loop controls are essential.
- Infrastructure readiness: Asynchronous training requires stable serving/training clusters, monitoring, and rollout mechanisms to avoid service regressions.
- Evaluation and rollback: Continuous A/B tests, shadow deployments, and fast rollback are necessary to manage live updates safely across all sectors.
Glossary
- agentic RL: Reinforcement learning applied to autonomous agents that act through multi-step interactions with tools and environments. "general agentic RL"
- asynchronous design: A systems architecture where components run concurrently without blocking each other. "asynchronous design"
- Binary RL: An RL approach that uses binary evaluative signals (e.g., +1/−1/0) as rewards for optimization. "Binary RL via PRM converts evaluative next-state signals into dense scalar process rewards"
- clipped surrogate (PPO-style): The PPO objective that clips policy ratio updates to stabilize training. "a standard PPO-style clipped surrogate with asymmetric bounds"
- context-enriched distillation: A training method that augments prompts with structured context to guide model outputs. "context-enriched distillation"
- credit assignment: Determining which actions contributed to success or failure in long sequences. "dense per-step credit assignment"
- DPO: Direct Preference Optimization, a method that optimizes policies from preference pairs without explicit reward modeling. "DPO"
- GRPO: Group Relative Policy Optimization, which estimates advantages relative to groups to avoid a critic network. "as in GRPO"
- Hindsight-Guided On-Policy Distillation (OPD): The paper’s method that extracts hints from next states to build an enhanced teacher and provide token-level guidance. "Hindsight-Guided On-Policy Distillation (OPD)"
- Hindsight relabeling: Reinterpreting past experience using information from future outcomes to create better training signals. "Hindsight relabeling"
- KL coefficient: The scaling factor on a Kullback–Leibler divergence penalty used to constrain policy updates. "the KL coefficient"
- long-horizon: Tasks requiring many decision steps before outcomes are observed. "long-horizon tasks"
- majority vote: Aggregating multiple judge outputs by choosing the most frequent decision. "majority vote"
- MDP: Markov Decision Process, a formal model of sequential decision making with states, actions, transitions, and rewards. "MDP "
- Megatron: A large-scale training system used here for policy optimization. "Megatron for policy training"
- on-policy distillation: Distilling a model using data generated by its current policy, often to leverage execution feedback. "on-policy distillation enables directional improvement"
- outcome rewards: Rewards computed only from final task results rather than intermediate steps. "outcome rewards"
- policy gradient: A class of RL methods that optimize policies by ascending the gradient of expected return. "directional policy gradient"
- PPO: Proximal Policy Optimization, a stable policy gradient method that limits update size via clipping. "PPO-style"
- PRM (Process Reward Model): A model that scores intermediate steps to provide dense supervision. "PRM judge"
- process reward: A per-step reward derived from immediate feedback about an action’s quality. "This forms a natural process reward"
- RLHF: Reinforcement Learning from Human Feedback, an alignment approach using human preference signals. "RLHF"
- RLVR: Reinforcement Learning from Verifiable Rewards, where rewards are derived from objectively checkable outcomes. "In standard RLVR"
- SGLang: A serving system used here to deploy and query the policy during training. "SGLang for policy serving"
- slime framework: The underlying infrastructure enabling fully decoupled, asynchronous RL components. "slime framework"
- step-wise rewards: Rewards assigned at each step of an interaction to provide dense supervision. "step-wise rewards"
- SWE: Software Engineering; used here for coding agents and tasks with executable feedback. "SWE"
- teacher context: The augmented input (with hints) given to a model acting as a teacher for distillation. "enhanced teacher context"
- token distribution: The probability distribution over next tokens produced by a LLM. "token distribution"
- token-level advantage: A per-token signal indicating how to adjust probabilities based on teacher vs. student log-probs. "token-level advantage"
- tool-call: An action where the agent invokes an external function or API to obtain results. "tool-call"
- trajectory: The sequence of states, actions, and outcomes generated during an episode. "the reward for the entire trajectory"
- verifiable outcomes: Final results that can be objectively checked (e.g., tests), providing reliable reward signals. "verifiable outcomes"
Collections
Sign up for free to add this paper to one or more collections.