AstraFlow: Dataflow-Oriented Reinforcement Learning for Agentic LLMs
Abstract: Reinforcement learning (RL) is increasingly used to improve the reasoning, coding, and tool-use capabilities of LLMs, but agentic RL remains prohibitively expensive. Scaling RL to agentic LLMs requires supporting complex workloads, including multi-policy collaborative training, while efficiently using elastic, heterogeneous, and cross-region compute resources. Existing LLM RL systems support some of these capabilities, but each new extension often requires dedicated system engineering. This burden arises from trainer-centered control architectures and the lack of principled abstractions for RL system components. To address these limitations, we propose AstraFlow, a dataflow-oriented RL system that replaces conventional trainer-centered control with principled component abstractions. In AstraFlow, rollout services, dataflow management, and training are decoupled into autonomous components, enabling the system to natively support complex multi-policy agentic RL workloads and efficiently exploit diverse compute resources. We evaluate AstraFlow across math, code, search, and AgentBench workloads, showing that the same system supports multi-policy training, elastic scaling, heterogeneous cross-region execution, and composable data algorithms without system-level code changes. In multi-policy collaborative training, AstraFlow achieves comparable or better accuracy than existing RL systems while speeding up training time by 2.7x.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces AstraFlow, a new way to train LLMs that act like “agents” (for example, code-writing bots or web search helpers). These agents learn using reinforcement learning (RL), a method where the model tries things, gets feedback, and improves over time—like practicing a sport with a coach. The problem is that current RL training systems are hard to extend and expensive to run, especially when multiple models need to work together. AstraFlow redesigns how the pieces of RL talk to each other so training becomes faster, cheaper, and easier to customize.
Key Goals and Questions
The paper asks: How can we build an RL training system for LLM agents that is:
- Easy to extend when you need new features (like training multiple models that collaborate)?
- Able to use different kinds of computers in different places (for example, mixing fast and slow GPUs, or machines in different regions)?
- Efficient and reliable without a lot of special engineering each time?
In simple terms, the goal is to turn RL training from a tightly controlled, hard-to-modify process into a flexible “plug-and-play” system.
How AstraFlow works (using everyday analogies)
Think of training as a busy kitchen:
- Customers send in orders (prompts).
- Cooks make dishes (agent “rollouts”—the model’s attempts).
- Coaches taste and give feedback (training updates).
- New recipes get sent to all cooks (updated model weights).
Most existing kitchens have one head chef (the “trainer”) directing every step. That works—but it’s slow, rigid, and breaks if you try to add more cooks or kitchens.
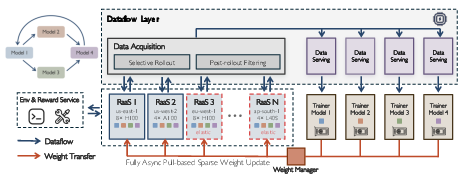
AstraFlow changes this by splitting the work into three parts that coordinate through a shared “conveyor belt”:
1) Dataflow Layer: the sorting center/conveyor belt
- This is a central “sorting center” that manages everything like orders, attempts, and feedback.
- It doesn’t boss anyone around; it just decides what goes where, and in what order.
- You can plug in simple rules here, like:
- Which orders to prioritize,
- Which attempts to keep,
- How to mix old and new examples,
- How to route data to different trainers.
- Because it’s rule-based and modular, you can tweak strategy without changing the cooks or coaches.
2) Rollout-as-a-Service (RaaS): the cooks
- These are independent “cooks” that pull tasks from the conveyor belt, make attempts, and return results.
- You can add or remove cooks anytime (elastic scaling).
- Cooks can be in different kitchens (different hardware or regions). They just need to follow the simple rule: take tasks in, send results out, and occasionally fetch the latest recipe (model) updates.
3) Trainers: the coaches
- Coaches study batches of attempts and update the model (the “recipe”).
- They publish only the changes to the recipe back to the system.
- Trainers don’t manage cooks directly. That means you can swap in different training methods or use multiple trainers at once (for multiple models collaborating), without touching the rest of the system.
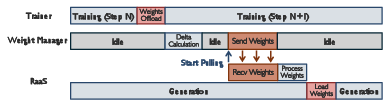
A small but important trick: when trainers send updated models to cooks, AstraFlow usually sends only what changed (like emailing just the edit notes, not the whole book). This “delta” update is much faster, especially across slow networks.
Main Results: What did AstraFlow achieve?
The authors tested AstraFlow on math, code, and agent tasks. Here are the highlights.
- Multi-model teamwork, faster and better:
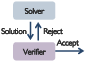
- Example: A “solver” model proposes a math solution and a “verifier” model checks it.
- AstraFlow improved accuracy over training a single model and made training up to 2.7× faster than a popular baseline system that ties everything tightly together.
- Works for coding agents too:
- They tried setups like “solver + selector” (generate two programs, pick the better one) and “solver + test generator” (create tests, then fix code).
- These collaborations improved success rates across several coding benchmarks.
- Automatic scaling with fewer GPU-hours:
- An “agentic maintainer” (a small helper agent) watched the system and automatically adjusted how many rollout workers were running—no special system code needed.
- It kept training almost as fast as an always-overprovisioned setup, while using about 13% fewer total GPU-hours.
- Runs across mixed hardware and regions:
- They used fast local GPUs and slower remote ones connected by a limited network.
- Training stayed stable and accurate because AstraFlow sends mostly the small “delta” updates, not the whole model.
- Training didn’t stall even when remote updates were slow.
- Matches performance of existing RL systems:
- On standard math tasks, AstraFlow matched the speed and accuracy of a well-built trainer-centered system, but with more flexibility.
- Plug-in “data policies” work out of the box:
- They mixed and matched simple strategies like:
- Choosing better prompts before generation (to save compute),
- Dropping low-value results after generation,
- Reusing good examples during training.
- These could be added like modules, without changing the rest of the system.
Why this matters: The results show you can get the benefits of complex RL setups—multiple cooperating models, elastic scaling, cross-region training—without having to rewrite the system for each new feature.
Why this matters and what it could lead to
- Faster progress for agent-based AI: Teams can try new model collaborations (like solver–verifier pairs) more easily and at lower cost.
- Lower training bills: Elastic scaling and delta updates help use GPUs more efficiently.
- Future-proof design: Because components connect through simple interfaces, you can swap in better trainers, smarter rollout engines, or new data strategies without re-engineering the whole pipeline.
- Real-world readiness: The system runs smoothly on mixed hardware and across regions, which is common in cloud and enterprise settings.
In short, AstraFlow turns RL training for agentic LLMs into a flexible, modular system—more like a well-organized logistics network than a single boss running the whole kitchen. This makes advanced training setups easier, cheaper, and faster to build and run.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete follow-up research and engineering.
- External validity of claims across tasks: Although the abstract mentions math, code, search, and AgentBench, the provided evaluation details focus primarily on math and code. It remains unclear how AstraFlow performs on long-horizon, tool-heavy, and interactive agent benchmarks (e.g., open-ended search, OS interaction), including throughput, stability, and accuracy trade-offs.
- Multi-policy scaling beyond two roles: Experiments are limited to two-policy workflows (solver–verifier, solver–selector, solver–test-generator). It is unknown how the dataflow layer behaves with larger multi-policy graphs (≥3–10 trainable policies), more complex communication topologies, or dynamic role activation/deactivation.
- Convergence and bias under asynchrony and staleness: The system relies on fully asynchronous, decoupled components with potential weight and data staleness. There is no analysis or empirical study of:
- How staleness affects convergence, stability, or sample efficiency.
- Whether off-policy corrections (e.g., importance sampling, V-trace) are needed in practice to mitigate bias.
- Sensitivity of performance to staleness thresholds and dataflow policies.
- Generality across RL algorithms: Evaluation primarily uses M2PO and a small set of data policies. It is unclear how AstraFlow supports or impacts other RLHF/RLAIF objectives (e.g., PPO variants, Q-learning-style methods, DPO/RPO), or how different objectives interact with asynchronous, replay-heavy, or staleness-prone pipelines.
- Dataflow policy interactions and conflict resolution: The paper claims composability for algorithms (dynamic sampling, GRESO, replay) but does not study:
- Interference between concurrently enabled policies (e.g., selective rollout + post-filtering + replay).
- Scheduling fairness and prioritization across policies and roles.
- Robust default policies for backpressure, throttling, and batch routing under heavy load.
- Replay and off-policy management specifics: Replay is presented as a pluggable module, but missing are:
- Retention policies, TTLs, or staleness-aware sampling heuristics.
- Deduplication/“exactly-once” semantics for trajectories across failures.
- Empirical ablations quantifying replay’s effect on stability and performance across tasks.
- Fault tolerance and failure semantics: The system asserts component autonomy but does not specify:
- Behavior under trainer crashes, RaaS failures, or network partitions.
- Dataflow layer consistency guarantees (e.g., at-least-once vs exactly-once delivery, idempotency, recovery protocols).
- Impact of failures on training correctness and throughput.
- Scalability limits and potential bottlenecks: There is no analysis of how the centralized dataflow layer scales in:
- Throughput, metadata size, memory footprint, and latency with thousands of RaaS nodes and multiple trainers.
- Coordination overhead when many policies/trainers publish weights and pull data concurrently.
- Sharding, partitioning, or horizontal scaling strategies for the dataflow service.
- Weight-transfer assumptions and edge cases: Sparse delta transfer is promising but underexplored:
- Robustness across hardware, non-determinism, different optimizers, and mixed-precision/quantized inference formats.
- Behavior at higher learning rates or objectives that update more parameters (sparsity collapse, bandwidth spikes).
- Versioning semantics, rollback, and consistency when rollout fleets refresh at different cadences or miss versions.
- Integration and conversion costs when serving backends require different weight layouts or quantization.
- Cross-region/heterogeneous results from real deployments: Cross-region behavior is simulated with bandwidth/latency shaping on three pools. Open issues include:
- Validation on real multi-cloud or geographically distributed clusters with variable egress costs and transient congestion.
- Sensitivity to more extreme RTTs, bandwidth asymmetries, packet loss, or intermittent connectivity.
- Behavior with dozens/hundreds of remote pools and the cumulative effect on trainer-side publish latency.
- Substitutability of rollouts and trainers in practice: While the interface claims backend-agnosticity, only a single serving runtime appears to have been used (SGLang notably mentioned). The cost and effort to integrate other popular runtimes (e.g., vLLM, TensorRT-LLM, TGI) and diverse training stacks remains unquantified.
- Autoscaling policy robustness and stability: The agentic maintainer uses a simple three-zone heuristic and an external LLM (Claude Code) to execute cluster actions. Missing are:
- Stability analysis under noisy signals, oscillation handling, and convergence guarantees.
- Failure modes when the maintainer LLM errs, is rate-limited, or loses access.
- Quantification of the maintainer’s own cost/latency and its effect on responsiveness.
- Comparisons against standard autoscaling controllers (e.g., PID, queue-length-based, or model-based schedulers).
- Comprehensive cost analysis: Results report GPU-hours and iteration time but omit:
- Dollar cost across clouds/regions (including egress fees) and runtime overhead of the dataflow/weight services.
- Energy and carbon metrics, especially under elastic and cross-region operation.
- Cost–accuracy trade-offs across different data policies and rollout scaling strategies.
- Statistical rigor and reproducibility: The paper lacks details on:
- Variance across seeds, confidence intervals, and statistical significance of reported gains.
- Full hyperparameter schedules, compute budgets, token counts, and prompt distributions for each task.
- Reproducibility of “agentic maintainer” behavior given nondeterministic LLM outputs.
- Generalization to tool-use and long-horizon tasks: The architecture should suit tool-calling, environment interaction, and credit assignment across steps, but:
- There are no experiments on OS/embodied tasks (e.g., AlfWorld), web agents, or multi-turn tool workflows with long horizons and sparse rewards.
- No discussion of how trajectory heterogeneity (e.g., intermediate artifacts, tool logs) affects storage, routing, and batch formation.
- Inter-trainer interference and coordination: With multiple trainers/policies writing to the dataflow/weight services:
- How are priority inversions, starvation, or resource contention avoided?
- What mechanisms coordinate joint objectives (e.g., when one policy’s data is a function of another’s behavior)?
- How are deadlocks or feedback loops detected in cyclical multi-policy workflows?
- Security and isolation concerns: Cross-region weight/data movement and “agentic maintainers” executing cluster commands introduce risks:
- Authentication, authorization, and audit controls for RaaS nodes and maintainers are not described.
- Encryption at rest/in transit, access control for multi-tenant clusters, and secret management are unspecified.
- Data governance and privacy: The paper does not address:
- Handling of sensitive data in trajectories, cross-region transfer policies, or data residency constraints.
- Mechanisms for redaction, PII filtering, or GDPR/CCPA compliance in the dataflow layer.
- Serving–training cohabitation and interference: It is unclear how the system behaves when training and production serving share rollout backends or clusters (e.g., isolation, QoS, and preemption policies).
- Evaluation breadth for data policies: Only three data policies are demonstrated. Open questions:
- How easily do ranking-based or learned data selectors integrate?
- Can the dataflow layer support dynamic curriculum learning or dual-criteria objectives (e.g., diversity vs reward)?
- Performance under conflicting objectives across domains (e.g., mixing math, code, and search in a single run).
- Overhead of the dataflow abstraction: There is no microbenchmarking of:
- Latency added by the dataflow layer for task dispatch and batch delivery.
- Memory/storage overhead for metadata and trajectories under large-scale runs.
- Impact on end-to-end throughput relative to trainer-centric baselines.
- Hardware heterogeneity beyond power caps: The study limits heterogeneity to per-GPU power throttling; it does not cover:
- Different GPU generations/vendors, mixed precision capabilities, or memory-limited devices.
- CPU-only or accelerator-diverse rollout nodes and the implications for batching and inference kernels.
- Quantized vs full-precision serving and compatibility with trainer-side weight publishing.
- Robustness to pathological rollouts: No analysis of long-tail trajectories, adversarial prompts, or extreme generation lengths that can cause queue buildup, memory pressure, or trainer starvation—and how the dataflow layer mitigates these.
- Benchmark curation and contamination checks: The work does not discuss data leakage controls for AIME/MATH/LiveCodeBench/Codeforces or check contamination risks in training data and prompts.
- Interface specification and ecosystem integration: The precise API/protocols for RaaS and trainers (schemas, versioning, compatibility guarantees) are not formalized, and the integration path with standard schedulers (Kubernetes/Slurm) is only anecdotally described via the maintainer.
Practical Applications
Below is an overview of practical, real-world applications enabled by AstraFlow’s dataflow-oriented RL architecture, RaaS (Rollout-as-a-Service), trainer abstraction, and sparse delta weight transfer. Each item highlights target sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be piloted with today’s LLMs, existing serving frameworks (e.g., SGLang, vLLM), standard RL trainers, and common cloud/on-prem clusters.
- Bold: Multi-policy RL for software development agents (solver–verifier, solver–selector, test-case generator)
- Sectors: Software, DevTools, QA/Testing
- Tools/products/workflows:
- CI-integrated agent workflows where a “solver” proposes fixes, a “verifier” checks correctness, and a “test-case generator” supplies challenging tests before merge.
- Internal code-assist training loops that reuse existing serving runtimes as RaaS backends and trainer backends without pipeline rewrites.
- A/B evaluation harnesses to compare multi-policy vs. single-policy training on code benchmarks.
- Assumptions/dependencies:
- Suitable reward shaping for code correctness and style.
- Access to unit tests/evaluators and secure sandboxing for code execution.
- Organizational tolerance for asynchronous training and long-tail rollouts.
- Competent base model weights and tool-use prompts (e.g., Qwen3-8B/14B).
- Bold: Cost-aware, no-code rollout autoscaling for RL workloads
- Sectors: MLOps, Cloud Platforms, Finance/Cost Optimization (across industries)
- Tools/products/workflows:
- An “agentic maintainer” that reads AstraFlow’s trainer waiting fraction and throughput reports and issues cluster commands to add/remove RaaS nodes (demonstrated ~13% GPU-hour savings with near-identical accuracy and wall-clock time).
- Kubernetes/Slurm operator or lightweight “Autoscaler Bot” that follows a simple target policy (dead-band rules) to size rollouts in real time.
- Dashboards that surface wait fractions, produced/consumed trajectory rates, and pool health.
- Assumptions/dependencies:
- Programmatic access to cluster control APIs (Kubernetes, Slurm, cloud SDK).
- Stable metrics export from the dataflow layer (waiting fraction, , ).
- Conservative autoscaling policies to avoid oscillations.
- Bold: Heterogeneous and cross-region rollout pooling to exploit spot/preemptible GPUs
- Sectors: Cloud/Edge Computing, Enterprise IT, Finance (cost-effective compute), Research
- Tools/products/workflows:
- Multi-cloud rollout pools with varied GPU power caps and network conditions, seamlessly feeding a local trainer (tolerant of 4 Gbit/s bandwidth and 300 ms RTT).
- Policy to preferentially dispatch tasks to faster/cheaper pools while throttling slow or stale nodes through dataflow routing.
- Assumptions/dependencies:
- Reliable network links and secure connectivity for weight updates and trajectory transfer.
- Rollout backends compatible with RaaS interface; trainer tolerance for asynchrony.
- Bold: Bandwidth-aware sparse delta weight synchronization for distributed rollouts
- Sectors: Multi-site Enterprises, Academia, Government IT
- Tools/products/workflows:
- “Delta-sync connector” that pushes/pulls high-sparsity ( typical) weight updates to remote rollout fleets, dramatically reducing bytes sent per iteration (e.g., 28 GB → ~1.5 GB).
- Scheduled full syncs with amortized cost; per-iteration deltas in the critical path with masked latency.
- Assumptions/dependencies:
- Delta sparsity holds for chosen learning rates/optimizers and bf16 quantization.
- Secure model weight transport and versioning (e.g., object store with signed access).
- Occasional full-syncs tolerated; sufficient overlap with rollout/training steps.
- Bold: Plug-and-play data policy experimentation (pre-, post-, and training-time)
- Sectors: Research, Industrial AI Labs, Model Alignment/Safety
- Tools/products/workflows:
- “Data policy catalogue” featuring dynamic sampling (post-rollout filtering), GRESO (pre-rollout selection), and buffer replay (training-time reuse)—composed without touching trainers or rollouts.
- A/B tests for prompt selection vs. replay vs. filtering trade-offs in cost/accuracy (e.g., dynamic sampling boosts accuracy but increases generations ~3.5×; pre-selection/replay cut rollout load).
- Assumptions/dependencies:
- Clean metadata logging (reward, staleness, origin policy) for algorithm hooks.
- Stable dataflow APIs to control routing, replay, and prioritization.
- Bold: Reuse of existing serving runtimes for RL rollouts
- Sectors: Software, Cloud AI Platforms
- Tools/products/workflows:
- Swap-in of optimized inference engines (e.g., SGLang) as RaaS without modifying trainers, leveraging throughput/latency benefits immediately.
- “RaaS adapter” kits for popular inference servers (vLLM, TensorRT-LLM).
- Assumptions/dependencies:
- Conformance to RaaS contract: task consumption, trajectory return, weight refresh.
- Observability for rollout node throughput and health.
- Bold: Data-local training with remote rollouts for compliance and cost
- Sectors: Finance, Healthcare (non-PHI tasks), Public Sector
- Tools/products/workflows:
- Keep trainers and datasets on-prem/in-region while farming out non-sensitive rollout tasks (search, public data reasoning) to cloud regions via delta sync.
- Virtual partitioning via dataflow routing to ensure sensitive prompts/trajectories never leave secure sites.
- Assumptions/dependencies:
- Clear delineation between sensitive and non-sensitive data/tasks.
- Legal review of model weight movement vs. data movement differences.
- Auditing and access controls on RaaS nodes.
- Bold: Academia-friendly RL platform for multi-agent research at low ops overhead
- Sectors: Academia, Nonprofits, Open-Source
- Tools/products/workflows:
- Run multi-policy experiments on mismatched lab GPUs and modest networks; swap in different trainers and algorithms without engineering.
- Reproducible pipelines for math/code/search with autonomous, fully asynchronous control.
- Assumptions/dependencies:
- Access to base models and open-source tasks; smaller labs may rely on 1.7B–8B models.
- Scriptable cluster access or even single-node “local pool” setups.
- Bold: Customer support and RPA agent training with collaborative policies
- Sectors: Customer Support, BPO, RPA, Enterprise IT
- Tools/products/workflows:
- Multi-policy workflows: e.g., “retriever” + “reasoner” + “validator” to reduce hallucinations and improve ticket resolution.
- Continuous RL fine-tuning from anonymized, synthetic, or human-in-the-loop rewards.
- Assumptions/dependencies:
- High-quality reward signals (task completion, user feedback).
- Clear separation of sensitive data if cross-region rollouts are used.
- Bold: Campus-wide education agents and tutoring research
- Sectors: Education, EdTech
- Tools/products/workflows:
- Multi-role tutors (solver + explainer + checker) trained through AstraFlow to improve resilience and correctness on math/code tasks.
- Use of mixed campus GPU pools with delta weight sync and asynchronous operation.
- Assumptions/dependencies:
- Availability of evaluation rubrics and problem banks for reward signals.
- Governance on student data and on-campus compute policies.
Long-Term Applications
These require further research, scaling, or organizational alignment (e.g., compliance, security hardening, continuous-learning policies).
- Bold: Managed “Agent RL Ops” services from cloud providers
- Sectors: Cloud Platforms, Enterprise AI
- Tools/products/workflows:
- Fully managed RL pipelines with native multi-policy coordination, RaaS pools, pluggable trainers, and policy marketplaces for data algorithms.
- Per-minute cost controls, SLA-aware autoscaling, and usage anomaly detection.
- Assumptions/dependencies:
- Standardized interfaces (dataflow, RaaS, trainer) across vendors.
- Strong multi-tenant isolation and compliance certifications.
- Bold: Federated or edge-assisted rollouts with privacy-preserving weight flow
- Sectors: Healthcare, Finance, Public Sector, Edge/IoT
- Tools/products/workflows:
- Endpoints generate trajectories on-device; trainers aggregate sparse deltas (with DP or HE variants) to protect sensitive gradients.
- “Bring-your-own-rollouts” ecosystems where organizations contribute computation without exposing data.
- Assumptions/dependencies:
- Federated analytics on trajectory quality; secure aggregation at scale.
- Regulatory acceptance of model-weight movement vs. raw data movement.
- Bold: Marketplace for rollout capacity (compute cooperatives)
- Sectors: Cloud/Edge Economy, Energy-Conscious Compute
- Tools/products/workflows:
- Spot-like market where independent providers register RaaS nodes; tasks routed by cost, latency, carbon intensity, and reliability.
- Credit/settlement layer tied to verified throughput and quality (e.g., reward-weighted credits).
- Assumptions/dependencies:
- Trust, auditing, and sandboxing to isolate untrusted providers.
- Bandwidth-aware delta sync and dynamic throttling for unreliable links.
- Bold: Continuous learning for production agents with guardrails
- Sectors: SaaS, DevTools, Customer Support, Search
- Tools/products/workflows:
- Agents continuously collect rollouts (e.g., anonymized user sessions), filtered by dataflow policies (replay, staleness control), and optimize via asynchronous trainers.
- Live multi-policy ensembles (e.g., generator + verifier) updated in rolling windows.
- Assumptions/dependencies:
- Strong safety/review gates, rollback mechanisms, and offline evals.
- Data governance for user data and opt-in policies.
- Bold: Safety-alignment via adversarial multi-policy training
- Sectors: AI Safety, Policy/Standards
- Tools/products/workflows:
- Red-team (attacker) and blue-team (defender/verifier) policies co-trained to harden models against jailbreaks and unsafe tool use.
- Plug-in reward models for risk signals; curriculum routing via dataflow.
- Assumptions/dependencies:
- High-quality red-team datasets and continuously updated threat models.
- Robust detection and containment of unsafe generations during training.
- Bold: Carbon-aware, regulation-aware compute placement
- Sectors: Energy, Sustainability, Regulated Industries
- Tools/products/workflows:
- Dataflow/maintainer policies that shift rollout capacity to low-carbon or off-peak regions while keeping trainers/data in-region for compliance.
- Emissions dashboards tied to per-trajectory compute intensity.
- Assumptions/dependencies:
- Access to real-time grid/carbon signals; region-specific compliance rules.
- Accurate attribution of compute and dataflows to emissions accounting.
- Bold: Cross-organization multi-policy ecosystems (“societies of models”)
- Sectors: Supply Chain, Legal/Compliance, Research Consortia
- Tools/products/workflows:
- Organizations own separate policies (e.g., writer, critic, auditor) and co-train via shared dataflow rules without exposing proprietary data.
- Contractual interfaces and versioned weight exchanges.
- Assumptions/dependencies:
- Legal frameworks for IP attribution and liability; robust access controls.
- Interop standards for metadata, reward semantics, and weight versions.
- Bold: Secure, zero-trust rollout networks
- Sectors: Security, Government, Critical Infrastructure
- Tools/products/workflows:
- Isolation of rollout tasks in strong sandboxes (e.g., WASM, microVMs); attested RaaS nodes with strict egress controls.
- Policy engines that constrain task classes and tool access per node.
- Assumptions/dependencies:
- Hardware attestation or confidential computing options for high-assurance ops.
- Overheads from sandboxing balanced by asynchronous throughput.
- Bold: Healthcare-grade agent training (clinical coding, guideline-constrained reasoning)
- Sectors: Healthcare
- Tools/products/workflows:
- On-prem trainer with de-identified rollouts; verifier policies encode guidelines (e.g., ICD/CPT coding rules) to reinforce compliance.
- Audit trails via dataflow metadata for regulatory review.
- Assumptions/dependencies:
- Regulatory clearance (HIPAA/GDPR); robust de-identification pipelines.
- Clinical reward design and safe evaluation protocols.
- Bold: Robotics and software-RPA planning with multi-role LLM agents
- Sectors: Robotics (task planning), RPA, Industrial Automation
- Tools/products/workflows:
- Text/tool-based planners (perception → planner → checker) co-trained via AstraFlow; integration with simulators or OS tools as rollouts.
- Asynchronous, cross-site rollout farms to accelerate training.
- Assumptions/dependencies:
- High-fidelity simulators and safe tool sandboxes; clear task rewards.
- Bridging to low-level controllers if moving beyond tool/RPA to physical robots.
- Bold: Standardization of RL dataflow/rollout/trainer interfaces and policy governance
- Sectors: Standards Bodies, Policy, Open-Source Ecosystems
- Tools/products/workflows:
- Open APIs/specs for dataflow policies, RaaS contracts, and trainer/weight interfaces—enabling interoperable tools and a “policy plugin” economy.
- Governance guidelines for cross-region weight transfer and auditability.
- Assumptions/dependencies:
- Community/industry alignment; conformance tests and reference implementations.
- Clear mapping between policy semantics and compliance requirements.
Notes on feasibility
- Performance sensitivity: Sparse delta transfer depends on learning rate/optimizer and bf16 representation; extremely aggressive training schedules may reduce sparsity.
- Reward quality: Gains in multi-policy RL hinge on credible reward signals and evaluation tooling (e.g., program executors, math verifiers).
- Network reality: Cross-region benefits require dependable bandwidth and secure channels; intermittent links may need larger buffers or more frequent full syncs.
- Governance: Cross-region weight flow can raise policy/compliance questions even if raw data stays local; organizations may require legal review and logging.
- Security: RaaS nodes executing untrusted tools/code require sandboxing and monitoring; zero-trust designs add overhead that must be masked by asynchrony.
Overall, AstraFlow’s abstractions make RL for agentic LLMs deployable in diverse, real-world environments today (elastic scaling, mixed hardware, multi-policy workflows) and open the door to longer-term, policy- and marketplace-driven compute ecosystems that optimize for cost, compliance, and sustainability.
Glossary
- Agentic RL: Reinforcement learning applied to autonomous, tool-using LLM agents operating in multi-step workflows. "but agentic RL remains prohibitively expensive."
- Asynchronous training: Training where rollout generation and optimization proceed without global synchronization barriers. "the first fully asynchronous multi-policy collaborative RL framework."
- Backpressure: A flow-control mechanism that slows producers or blocks tasks when consumers are overloaded. "or block unsuitable batches through backpressure."
- Buffer replay: Reusing previously collected trajectories across multiple training updates to improve sample efficiency. "including dynamic sampling~\citep{yu2025dapo}, GRESO~\citep{zheng2025act}, and buffer replay."
- Colocated synchronous systems: RL system designs that co-locate rollout and training on the same GPUs and alternate in lockstep. "Colocated synchronous systems such as verl~\citep{sheng2024hybridflow}, Real~\citep{mei2025real}, and RLHFuse~\citep{zhong2025optimizing} place training and rollout on the same GPU pool and alternate between trajectory generation and optimization."
- Cross-region rollout: Executing rollout generation across different geographic regions or data centers. "Cross-region / heterogeneous rollout"
- Curriculum scheduling: Progressively adjusting task difficulty or exposure to guide learning over time. "curriculum scheduling, replay, data mixing, filtering, sampling, and staleness correction"
- Data mixing: Combining multiple data sources or streams into training batches according to a policy. "curriculum scheduling, replay, data mixing, filtering, sampling, and staleness correction"
- Dataflow layer: A shared coordination plane that routes prompts, trajectories, and batches between rollout services and trainers. "The dataflow layer is the coordination plane between rollout services and trainers."
- Dataflow-oriented RL: An RL system design that coordinates components via shared dataflow rather than a central trainer loop. "we propose AstraFlow, a dataflow-oriented RL training system for agentic LLMs."
- Dead band: A control region where no scaling action is taken to avoid oscillations. "applying a dead band $[\tau_{\mathrm{low}, \tau_{\mathrm{high}]$ on :"
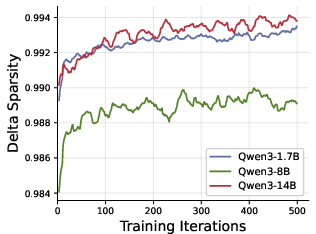
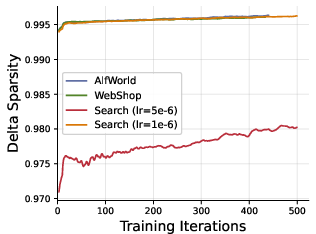
- Delta sparsity: The high fraction of model parameters that remain unchanged between iterations, enabling sparse updates. "With delta sparsity for Qwen3-14B~\citep{yang2025qwen3}"
- Delta weight transfer: Sending only the parameter changes between model versions rather than full checkpoints. "Delta weight transfer."
- Disaggregated RL: Separating rollout generation and training onto different resources to improve utilization. "Disaggregated RL systems such as AReaL~\citep{fu2025areal} and SLIME~\citep{slime_github} address this utilization problem"
- Dynamic sampling: A post-generation filtering strategy that favors trajectories with higher learning value (e.g., advantage). "dynamic sampling~\citep{yu2025dapo}"
- Elastic rollout scaling: Dynamically increasing or decreasing rollout capacity at runtime to match demand. "Runtime elastic rollout scaling"
- GRESO: A selective rollout data algorithm that prioritizes higher-value prompts before generation. "GRESO~\citep{zheng2025act}"
- Heterogeneous rollout: Running rollouts on diverse hardware types or performance profiles across clusters or regions. "heterogeneous and cross-region rollout"
- Long-tail rollout latency: Slowest rollouts dominating synchronous iteration time and causing idle resources. "but it suffers from long-tail rollout latency, leaving expensive trainer GPUs idle during rollout."
- Multi-policy collaborative training: Jointly training multiple interacting policies that play different roles in a workflow. "Multi-policy collaborative training"
- On-policy training: Training that uses data generated by the current policy parameters. "This design guarantees the on-policy training"
- Pull-based sparse weight update: Rollout nodes asynchronously pull only sparse delta updates to refresh weights. "Fully async pull-based sparse weight update."
- RaaS (Rollout-as-a-Service): Treating rollout generation as a standalone service that consumes tasks, produces trajectories, and refreshes weights. "RaaS models rollout generation as a pure agent-serving service."
- Selective rollout: Choosing which prompts to generate based on a policy to avoid low-value trajectories. "selective rollout, curriculum scheduling"
- Staleness correction: Adjusting for or filtering out outdated data or weights to maintain training quality. "staleness correction"
- Trainer-centered control: An architecture where the trainer orchestrates rollout scheduling, data movement, and synchronization. "replaces conventional trainer-centered control with principled component abstractions."
- Trajectory: A generated sequence (e.g., prompts, model outputs, rewards) produced during a rollout episode. "returns trajectories."
- Version-aware refresh: Updating rollout weights based on specific model versions to avoid unnecessary transfers. "full-model transfer, sparse transfer, and version-aware refresh"
- Weight-transfer interface: The API that publishes model weights from trainers and serves them to rollout services. "through a trainer-side weight-transfer interface."
Collections
Sign up for free to add this paper to one or more collections.

