Part II: ROLL Flash -- Accelerating RLVR and Agentic Training with Asynchrony
Abstract: Synchronous Reinforcement Learning (RL) post-training has emerged as a crucial step for enhancing LLMs with diverse capabilities. However, many systems designed to accelerate RL post-training still suffer from low resource utilization and limited scalability. We present ROLL Flash, a system that extends ROLL with native support for asynchronous RL post-training. ROLL Flash is built upon two core design principles: fine-grained parallelism and rollout-train decoupling. Guided by these principles, ROLL Flash provides flexible programming interfaces that enable a fully asynchronous training architecture and support efficient rollout mechanisms, including queue scheduling and environment-level asynchronous execution. Through comprehensive theoretical analysis and extensive experiments, we demonstrate that ROLL Flash significantly improves resource utilization and scalability over synchronous RL post-training. ROLL Flash achieves up to 2.24x speedup on RLVR tasks and 2.72x on agentic tasks, using the same GPU budget as synchronous baselines. Furthermore, we implement several popular off-policy algorithms and verify that asynchronous training can achieve performance on par with synchronous training.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “violet — Accelerating RLVR and Agentic Training with Asynchrony”
Overview
This paper is about making the training of LLMs faster and more efficient. It introduces “violet,” a system that helps an existing toolkit called ROLL run training in an asynchronous way. In simple terms, violet lets different parts of the training process work at the same time instead of waiting for each other, which reduces wasted time and speeds things up.
What questions does the paper try to answer?
The paper focuses on three main questions:
- How can we reduce wasted time when LLMs generate responses of very different lengths?
- Can we keep training going even while new data is being generated, without hurting accuracy?
- Will this approach scale well when we use more GPUs (graphics cards) and different kinds of tasks, like math problem solving and interactive “agent” tasks?
How does the system work? (Methods and approach)
The paper explains the usual training process and how violet changes it:
- Normal (synchronous) training:
- Two main stages repeat over and over:
- 1) Rollout: the model generates answers or takes actions in an environment (like a game or tool), and a reward or score is given based on how good those answers/actions are.
- 2) Training: the model updates its weights using those rewards.
- The problem: everyone waits for the slowest part. If one answer takes a lot longer (the “long tail”), the whole batch waits. GPUs sit idle. This wastes time.
- violet’s asynchronous approach:
- The rollout and training stages are decoupled, meaning they run on separate resources and in parallel. While new samples are being generated, training can keep going on previously collected samples.
- Fine-grained parallelism: instead of doing everything as one big batch, violet manages each sample separately. This lets the system overlap tasks, like:
- Generate an answer for one sample
- Interact with the environment for another sample
- Compute rewards for a third sample
- All at the same time
To make this work smoothly, violet introduces simple roles you can think of like an efficient factory:
- LLMProxy: like a traffic controller for the model’s inference. It batches requests, advances decoding step by step, and immediately hands off completed results without waiting.
- EnvManager: like a game host for each environment. It gets actions from the model and sends back observations, looping until a task ends.
- SampleBuffer: like a pantry or storage area that holds generated samples ready for training.
- AsyncController: like a conductor that coordinates when to update the model’s weights and when to consume batches from the SampleBuffer for training.
A key safety feature is the “asynchronous ratio.” Think of it like a freshness label:
- It limits how “old” the policy (the version of the model used to generate a sample) can be relative to the current training model.
- This keeps samples from being too stale, which helps maintain training stability and accuracy.
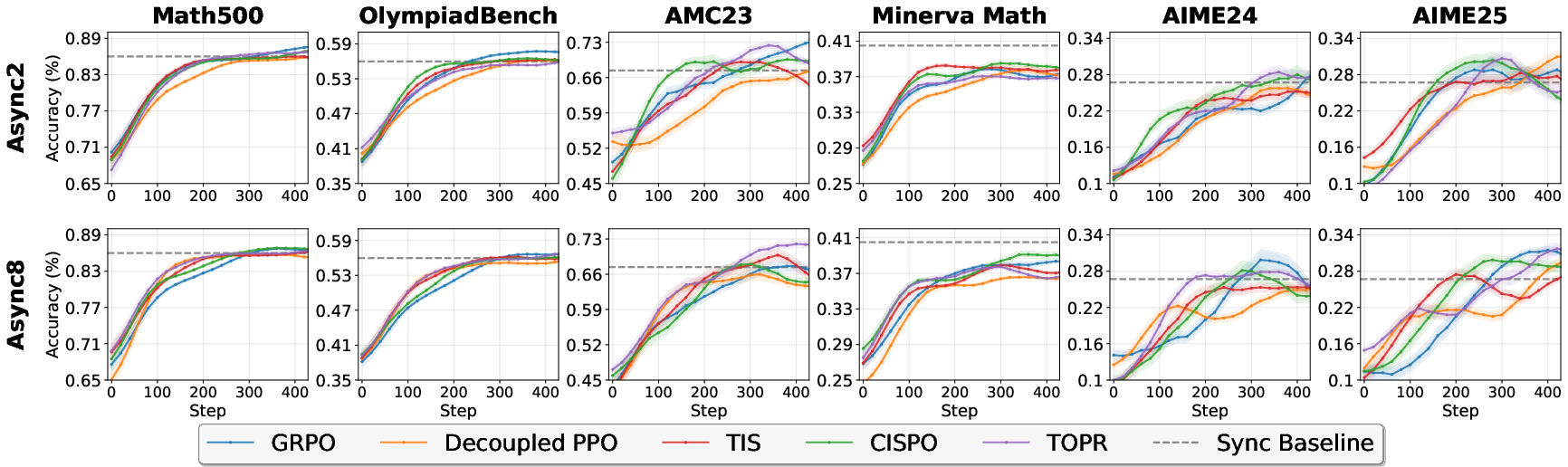
Finally, because asynchronous training uses samples generated by older model versions, the paper tests “off-policy” algorithms (like GRPO and variants of PPO) that are designed to handle this mismatch safely.
What did they find, and why is it important?
Here are the most important results:
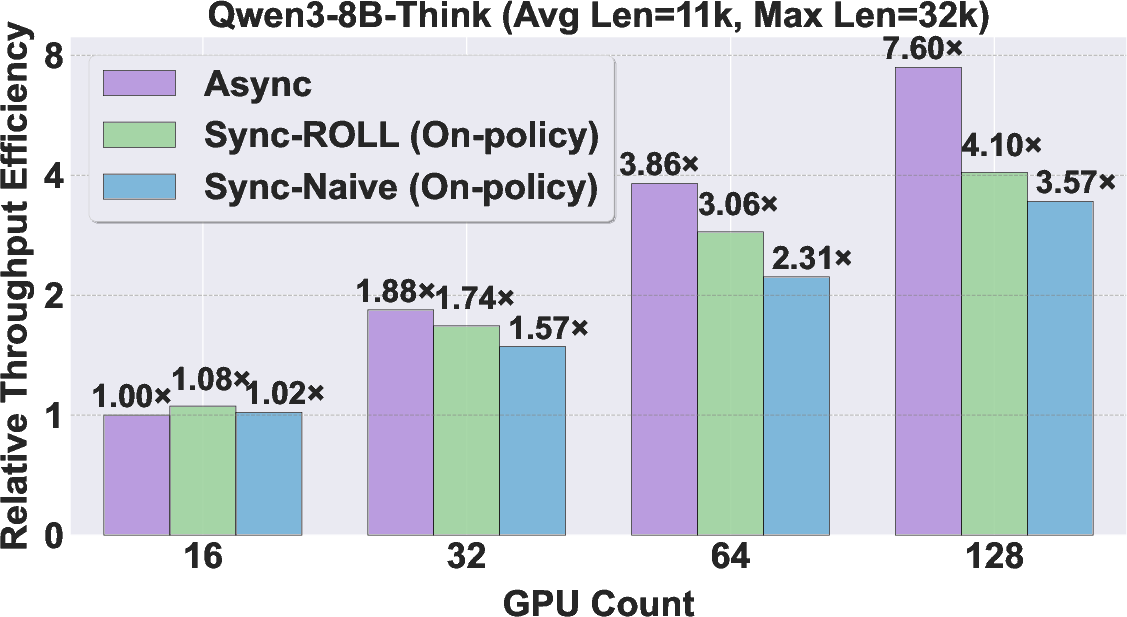
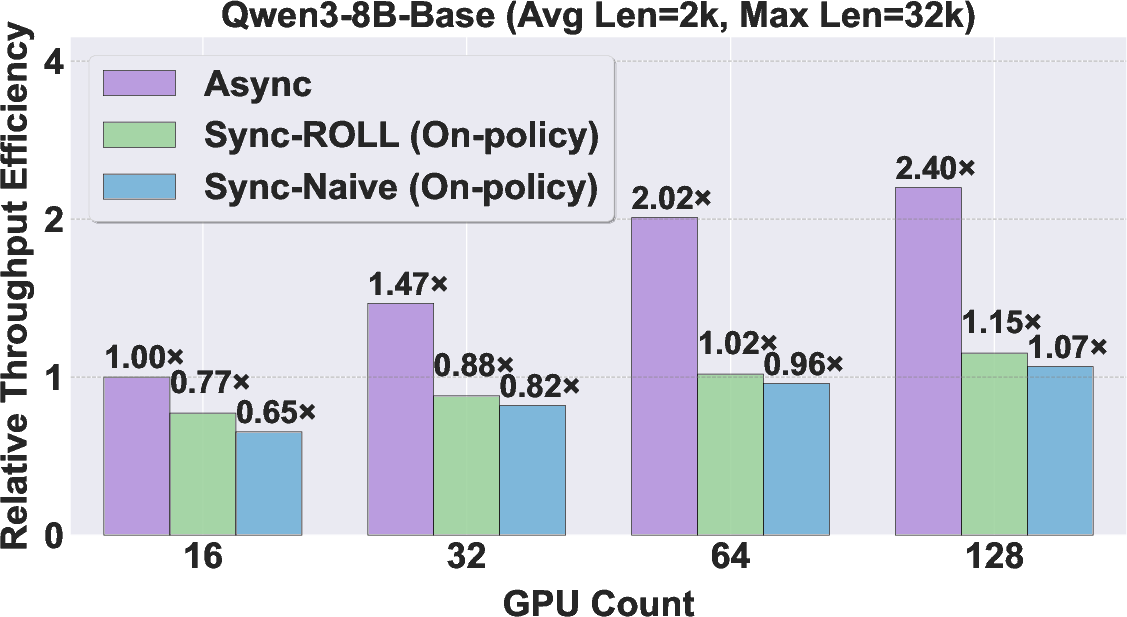
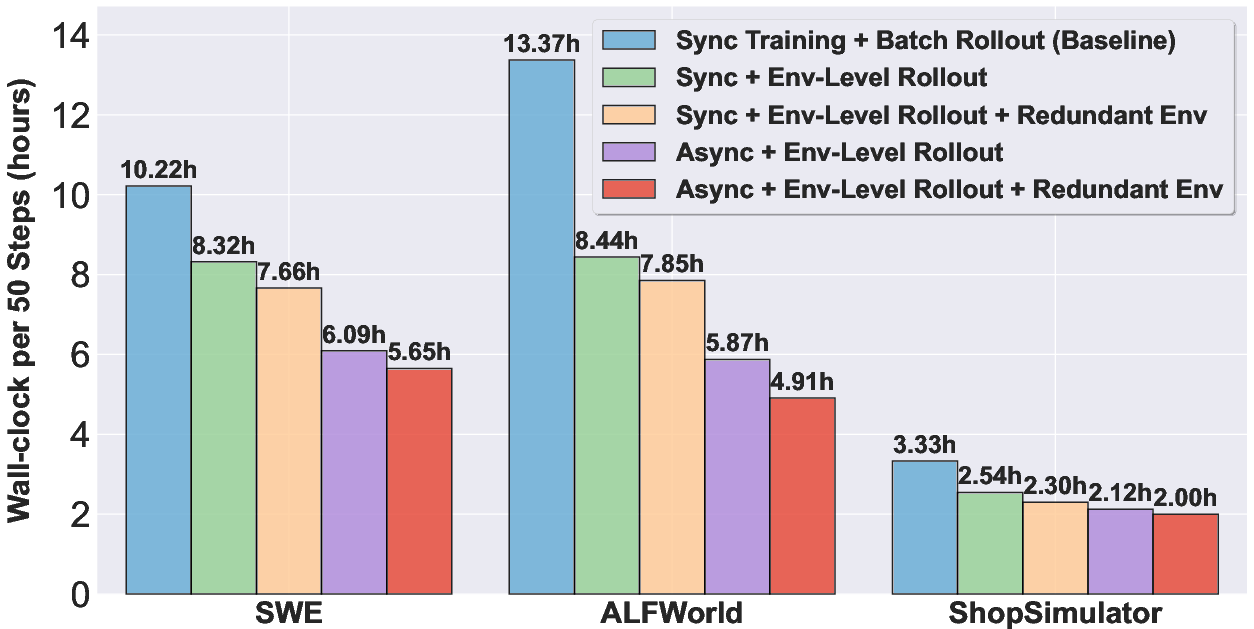
- Faster training: violet achieves up to 2.24× speedup on RLVR tasks (like solving math problems where answers can be checked) and up to 2.72× speedup on agent tasks (like ALFWorld and SWE, where the model interacts step-by-step with tools or environments).
- Better scalability: adding more GPUs helps more when using the asynchronous approach because the system avoids waiting for long responses. It reaches higher throughput and uses resources more efficiently.
- Small “freshness” limits are enough: an asynchronous ratio of around 2 often gives most of the speed benefits without sacrificing performance. In other words, you don’t need a big lag between the “rollout model” and the “training model” to see gains.
- Stable performance: with the right off-policy methods (including GRPO and others), asynchronous training performs on par with synchronous training—even while running faster. This means you can have speed without losing accuracy.
This matters because training LLMs is expensive and slow, especially when responses vary a lot in length. Violet’s design keeps GPUs busy and avoids bottlenecks, saving time and cost.
What does this mean for the future? (Implications)
- Training large models can be made much more efficient by letting different parts run in parallel and by managing samples at a fine-grained level.
- Systems like violet can help researchers and engineers scale up training to many GPUs without hitting “waiting” bottlenecks.
- With safe controls (like the asynchronous ratio) and off-policy algorithms, speed doesn’t have to come at the cost of quality.
- Faster, more scalable training could accelerate progress in areas like math reasoning, code generation, and tool-using agents—making smarter models more affordable and more widely available.
In short, violet shows that careful system design plus the right training algorithms can make LLM post-training both faster and just as accurate, which is a big step forward for building powerful AI systems.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to be directly actionable for future work.
- Lack of learning-theoretic guarantees: no formal convergence or performance bounds for off-policy/asynchronous training under bounded staleness (asynchronous ratio), beyond runtime analysis.
- Staleness-control theory: no quantitative link between the asynchronous ratio and policy divergence (e.g., KL, TV distance), learning bias/variance, or final accuracy; no principled way to set or adapt it online.
- Automated alpha/β tuning: no controller to jointly adapt the asynchronous ratio and train–infer resource split in response to queue lengths, reward drift, or latency statistics.
- Heavy-tailed rollout modeling: theoretical bounds assume bounded generation time; no analysis for heavy-tailed or Pareto-like latency distributions common in long-context decoding.
- Token-level importance sampling: algorithms are presented at trajectory level; no rigorous treatment of token-level IS ratios, their variance explosion on long sequences, and principled clipping schedules.
- Interrupted/resumed rollouts: no method to correct bias when a sample is started under one policy and resumed under a newer policy; unclear how importance weights are computed for mixed-policy trajectories.
- SampleBuffer policies: no prioritization/eviction strategy (e.g., by staleness, reward, uncertainty) or its impact on stability and sample efficiency; claim of “no sample wasted” is untested for quality.
- Prompt replication and redundancy bias: no analysis of how replication/redundant rollouts skew data distribution, over-represent easy/short prompts, or harm generalization; no deduplication or reweighting scheme.
- Reward pipeline bottlenecks: no study of latency/variance of reward computation (learned vs. programmatic), its scaling, or co-scheduling with generation; no handling of noisy/biased reward models.
- Stability at high staleness: experiments with Async Ratio beyond 8 and under nonstationary rewards are absent; limits where performance collapses remain undefined.
- Breadth of evaluation: benchmarks focus on specific RLVR and a few agentic tasks (ALFWorld, SWE); missing diverse domains (multi-modal RLHF, tool-use with real APIs, dialogue safety/alignment).
- Scale limits: no results for very large models (e.g., 32B–70B+) with tensor/pipeline parallelism, nor quantification of weight-broadcast overheads and network contention at multi-node scale.
- Heterogeneous accelerators: no exploration on TPUs or mixed GPU generations; unclear portability of LLMProxy scheduling and KV cache management across backends.
- KV cache and memory pressure: no profiling of cache thrash, prefill/decoding mix, or paging under fine-grained asynchrony and prompt replication; no memory-aware scheduler.
- Communication topology: no design/benchmarking of parameter dissemination (parameter-server vs. all-reduce vs. multicast), nor impact of network bandwidth/latency on staleness and throughput.
- Fault tolerance and reproducibility: no discussion of crash recovery, exactly-once semantics in SampleBuffer, deduplication after failures, or determinism under asynchrony.
- Data quality vs. staleness: no direct measurement of reward/accuracy degradation as a function of per-sample staleness; no prioritization of fresher or higher-reward samples during training.
- Safety and alignment: no study of reward hacking, harmful content, or catastrophic forgetting under stale off-policy updates; no integration with safety filters or constrained RL.
- Hyperparameter sensitivity: limited analysis of clipping thresholds, group sizes, KL penalties, and their interactions with staleness and sequence length; no guidance for robust defaults.
- Energy and cost efficiency: throughput gains are reported, but there is no GPU-hour, dollar cost, or energy-per-sample analysis; unclear trade-offs under fixed budget constraints.
- Queueing/backpressure analytics: no queue-theoretic model to predict saturation regimes, backlog growth, or instability with varying rollout distributions and reward latencies.
- Online performance monitoring: no mechanism to monitor and bound off-policy drift (e.g., online KL to rollout policy) and trigger corrective actions (alpha reduction, buffer flush).
- Broader algorithmic coverage: limited to PPO/GRPO and a few off-policy variants; no evaluation for actor–critic with bootstrapping, return-conditioned policies, V-trace, or Q-learning in the async regime.
- Long-horizon agentic credit assignment: no analysis of how asynchrony affects credit assignment, partial observability, and tool/API rate limits in complex environments.
- Workload variability: no sensitivity studies for highly stochastic environments or non-stationary data; unclear robustness to distribution shift during training.
- Scheduling fairness: no strategy to prevent starvation of long prompts or hard environments in queue scheduling; no fairness/age-based scheduling policy.
- Code availability and integration: unclear release status of violet extensions, APIs, and reproducibility artifacts (configs, seeds, logs) to replicate the reported results.
- Measurement rigor: limited statistical testing across benchmarks; lack of run-to-run variance reporting and significance tests for performance parity claims with synchronous baselines.
Practical Applications
Immediate Applications
Below are actionable, deployable use cases that can be implemented now using the paper’s system, findings, and methods.
- Accelerate existing RLHF/RLVR pipelines for LLMs
- Sector: software/AI labs, cloud ML platforms
- What to do: Integrate violet’s rollout–train decoupling and fine-grained parallelism (LLMProxy, EnvManager, SampleBuffer, AsyncController) into existing post-training workflows (e.g., PPO/GRPO-based RL). Adopt queue scheduling, prompt replication, and environment-level asynchronous rollout to mitigate long-tail generation stalls.
- Expected benefit: 1.5–2.7× throughput increases; better GPU utilization; reduced training wall-clock time and cost.
- Tools/products/workflows: “violet mode” in ROLL (
https://github.com/alibaba/ROLL), an AsyncController plugin for vLLM-serving stacks, resource partitioning playbooks (β split for training vs inference), staleness guardrails via per-sample asynchronous ratio α. - Assumptions/dependencies: Access to inference engines (e.g., vLLM), RL datasets/reward models, off-policy algorithm support (CISPO, TOPR, Decoupled PPO), workloads with length variability (long-tail decoding), operational capacity to tune α and β.
- Cost and energy reduction in model training operations
- Sector: cloud providers, sustainability/energy management, enterprise MLOps
- What to do: Apply queue scheduling and prompt replication to reduce idle GPU time during rollouts; decouple rollout and training to avoid synchronization stalls; track and optimize utilization using the paper’s theoretical bounds to select β and α.
- Expected benefit: Fewer GPU-hours per training run; lower energy consumption and carbon footprint; improved cluster efficiency.
- Tools/products/workflows: Utilization dashboards that surface μ_gen, L_gen, μ_train; auto-tuners for β and α; carbon accounting instrumentation.
- Assumptions/dependencies: Accurate telemetry for generation and training timing; existing Kubernetes/Ray-style orchestration to reallocate GPUs on the fly.
- Faster iteration for agentic training in software engineering and embodied environments
- Sector: software (SWE/code agents), robotics simulation
- What to do: Use EnvManager wrappers to run environment-level asynchronous trajectories; adopt redundant environment rollouts to smooth throughput; train agents against ALFWorld-like tasks and SWE benchmarks with decoupled rollout/training.
- Expected benefit: 1.8–2.7× speedups; quicker evaluation loops; faster agent upgrades.
- Tools/products/workflows: Environment connectors (sim-to-LLM bridges), reward workers integrated with async buffers, agent training orchestration with alpha-bound staleness.
- Assumptions/dependencies: Reliable environment APIs/simulators; reward signal quality; safe interruption/resume semantics for trajectories.
- MLOps auto-tuning of resource split and staleness
- Sector: DevOps/MLOps tooling
- What to do: Implement an auto-tuner that uses the paper’s end-to-end time bounds to set β (training/inference GPU split) and α (asynchronous ratio) for given rollout sizes, model sizes, and sequence lengths.
- Expected benefit: Near-optimal throughput without manual trial-and-error; stability preserved via bounded staleness.
- Tools/products/workflows: “β–α tuner” microservice; policy freshness dashboards; guardrails that suspend/resume rollout based on buffer health.
- Assumptions/dependencies: Real-time measurements of μ_gen, L_gen, μ_train; hooks to manipulate worker pools; tolerance for minor training wait to stay up-to-date.
- Academic experimentation with off-policy algorithms for LLM RL
- Sector: academia/research
- What to do: Use violet to compare PPO/GRPO against off-policy variants (Decoupled PPO, Truncated IS, CISPO, TOPR/Weighted TOPR), evaluate pass@1 across math/code/tool-use datasets under different α.
- Expected benefit: Reproducible, performance-preserving async training baselines; insights into staleness-robust optimization.
- Tools/products/workflows: Sample freshness constraints at per-sample level; standardized ablations over model size, sequence length, rollout size.
- Assumptions/dependencies: Dataset access (e.g., DAPO-Math-18K), consistent evaluation metrics and reward functions.
- Enterprise governance for compute allocation and training SLAs
- Sector: enterprise IT policy/PMO
- What to do: Establish internal guidelines that favor async pipelines under long-tail workloads; encode α bounds and β splits into training SLAs to balance speed and stability.
- Expected benefit: Predictable training timelines; improved ROI on GPU budgets.
- Tools/products/workflows: Policy documents, SLA templates, change management workflows for rollout–train decoupling.
- Assumptions/dependencies: Organizational buy-in; alignment with safety and quality controls.
- Open-source community acceleration
- Sector: open-source/model hubs
- What to do: Incorporate violet’s async pipeline in community LLM post-training repos to shorten release cycles for reasoning/code models.
- Expected benefit: Faster model updates; broader access to efficient RLVR training practices.
- Tools/products/workflows: ROLL extensions, example configs for popular models (Qwen3-Base/Think), CI/CD jobs with async rollouts.
- Assumptions/dependencies: Maintainer capacity to adopt new components; compatibility with existing infra.
- Stability-first training with bounded staleness
- Sector: all deploying RL post-training
- What to do: Use small α (often 1–2) to reach peak throughput while preserving performance parity; combine with Weighted TOPR or GRPO clipping to control variance.
- Expected benefit: High throughput with near-lossless accuracy; reduced risk of off-policy drift or collapse.
- Tools/products/workflows: Alpha guardrails, token-level IS clipping, proximal references in Decoupled PPO.
- Assumptions/dependencies: Proper algorithm selection; monitoring of divergence (KL to reference policy).
Long-Term Applications
The following use cases require additional research, scaling, or productization before broad deployment.
- Real-time, privacy-preserving online RLHF from user interactions
- Sector: consumer tech, e-commerce, finance
- Vision: Stream user feedback as asynchronous rollouts collected at the edge; central training consumes buffered trajectories with α-bound staleness.
- Potential products: Streaming RLHF trainer; “learn-from-use” personalization platform.
- Assumptions/dependencies: Safety filters, consent and privacy compliance, robust IS clipping under nonstationary feedback, low-latency infra.
- Federated asynchronous RL training across institutions
- Sector: healthcare, finance, public sector
- Vision: Decentralized EnvManagers run client-side rollouts; central SampleBuffer aggregates anonymized trajectories; off-policy training ensures stability despite staleness/heterogeneity.
- Potential products: Federated RLHF orchestrator; secure aggregation pipelines with staleness auditing.
- Assumptions/dependencies: Differential privacy, secure transport, model/version tracking, regulatory approvals.
- Carbon-aware, grid-responsive training schedulers
- Sector: energy policy, cloud sustainability
- Vision: Optimize β and rollout scheduling based on real-time carbon intensity; shift compute to greener windows while maintaining freshness constraints.
- Potential products: Carbon-optimized trainer; policy engine that trades α vs emissions.
- Assumptions/dependencies: Grid carbon APIs, workload elasticity, compliance with operational SLAs.
- On-device/edge continual learning for autonomous robots and IoT agents
- Sector: robotics, industrial IoT, autonomous vehicles
- Vision: Rollouts on-device (sensing/action loops) with intermittent cloud training; async ratio and IS clipping manage staleness across intermittent connectivity.
- Potential products: Edge EnvManager SDK; hybrid edge–cloud AsyncController.
- Assumptions/dependencies: Reliable buffering, bandwidth constraints, safety certification, lightweight models/algorithms.
- Elastic training marketplaces and multi-tenant orchestrators
- Sector: cloud, GPU marketplaces
- Vision: Violet-compatible schedulers that adapt β, α, and queue scheduling across heterogeneous pools; provide SLAs for throughput/staleness.
- Potential products: Marketplace-native async RL orchestrator; utilization-based billing.
- Assumptions/dependencies: Robust fault tolerance; hardware heterogeneity handling; standardization of telemetry.
- Large-scale educational tutoring agents trained via RLVR
- Sector: education/edtech
- Vision: Train math/logic tutors with async pipelines to handle long reasoning traces; integrate pedagogy-aware reward models.
- Potential products: RLVR training suite for tutors; assessment-integrated reward workers.
- Assumptions/dependencies: High-quality, pedagogically aligned rewards; safety/accuracy guarantees.
- Financial analysis and trading agents with accelerated RL in simulated markets
- Sector: finance
- Vision: Use environment-level async rollouts against market simulators; off-policy corrections to stabilize learning under regime shifts.
- Potential products: Async RL agent trainer for market micro-simulations; risk-aware staleness bounds.
- Assumptions/dependencies: Realistic simulators, risk controls, compliance, robust evaluation.
- AI safety tooling for staleness auditing and bounded-policy updates
- Sector: AI safety, governance
- Vision: Formalize α-bound freshness and IS clipping as safety constraints; audit pipelines for divergence (KL) and off-policy drift.
- Potential products: Staleness/audit dashboards; policy-update guardrails.
- Assumptions/dependencies: Logging of policy versions and sampling distributions; governance frameworks.
- Community standards and benchmarks for asynchronous RL post-training
- Sector: academia/industry consortia
- Vision: Establish shared benchmarks, metrics, and best practices for async RLVR/agentic training (e.g., pass@1 vs throughput vs energy).
- Potential products: Benchmark suites; reference configs; reproducibility checklists.
- Assumptions/dependencies: Community buy-in; funding/support; cross-vendor compatibility.
Notes across all applications:
- The largest gains occur when generation is long-tail and memory-bandwidth bound; synchronous baselines underperform in such regimes.
- Stability depends on appropriately chosen off-policy algorithms and small α; monitoring KL to reference policy and IS ratios is recommended.
- Operational success hinges on telemetry for μ_gen, L_gen, μ_train and the ability to reallocate GPUs (β) dynamically.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a concise definition and a verbatim usage example.
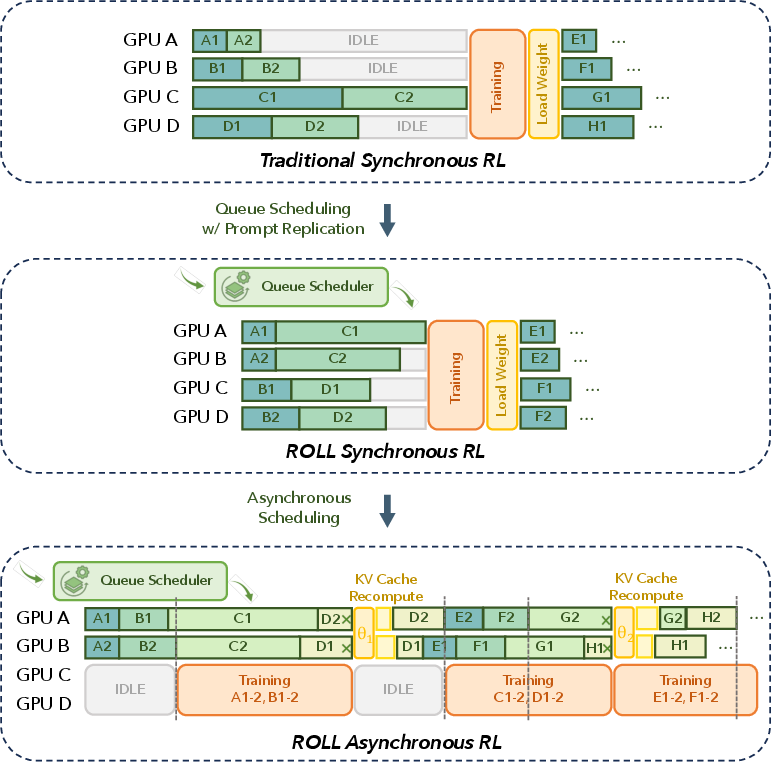
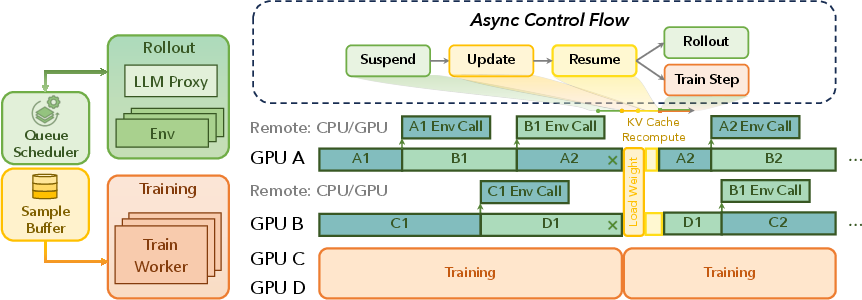
- ABORT: A control command to immediately cancel running inference requests and reclaim them for rescheduling. "ADD to enqueue new requests and ABORT to interrupt running requests and reclaim them into the SampleBuffer for subsequent recomputation and generation."
- Actor LLM: The policy model that generates responses (actions) during rollout and may interact with environments. "In the rollout stage, an actor LLM generates a batch of responses and assigns a reward signal to each response until the rollout terminates."
- Actor-critic framework: A reinforcement learning paradigm that uses an actor (policy) and a critic (value estimator) for stable learning. "PPO \citep{schulman2017proximal} is a widely used policy gradient algorithm based on the actor-critic framework."
- ALFWorld: A benchmark environment for evaluating agentic policies in language and embodied tasks. "Together, these comprehensive experiments validate the broad effectiveness and efficiency of our approach across diverse RL and agentic workloads... yield speedup on ALFWorld and on SWE."
- AReaL: A scalable RL post-training framework that relaxes synchronization barriers between rollout and training. "A seminal work AReaL~\citep{fu2025areal} presents a scalable RL post-training framework that relaxes the synchronization barrier between rollout and training."
- Asynchronous ratio: A hyperparameter bounding how many model versions rollout can lag behind training, controlling sample freshness. "violet introduces asynchronous ratio, which bounds the policy version gap between the current policy and the one that initiated a sampleâs generation."
- Asynchronous training: A training paradigm where rollout and optimization run in parallel without strict synchronization, consuming potentially stale samples. "we implement several popular off-policy algorithms and verify that asynchronous training can achieve performance on par with synchronous training."
- AsyncController: The orchestration component that manages weight updates, trajectory batching, and coordination between rollout and training. "violet runs an asynchronous training pipeline via a purple{AsyncController} and a shared SampleBuffer."
- Autoregressive decoding: Token-by-token generation process used by LLMs to produce sequences, often a throughput bottleneck. "During the rollout stage, LLM generation performs thousands of autoregressive decoding steps to produce each complete response."
- BaseEnv: The underlying environment interface that receives actions and returns observations/rewards within agentic rollouts. "applies it to BaseEnv via step, processes the resulting observation, and repeats until a termination condition is met."
- CISPO: An off-policy optimization method that clips importance-sampling ratios asymmetrically to stabilize learning. "e.g., Truncated IS~\citep{munos2016safe,espeholt2018impala}, CISPO~\citep{chen2025minimax} and TOPR~\citep{roux2025tapered} to preserve accuracy."
- DAPO-Math-18K: A math-focused dataset used for evaluating RL post-training throughput and performance. "on the DAPO-Math-18K~\citep{yu2025dapo} dataset (other details in \autoref{app:training_details})."
- Decoupled PPO: An off-policy variant of PPO that uses a proximal (intermediate) policy to regulate updates when training on stale samples. "Decoupled PPO introduces a proximal policy $\pi_{\mathrm{prox}$ to better regulate policy updates."
- EnvManager: A worker that manages environment interaction loops and communicates with the LLM serving proxy for fine-grained rollouts. "violet introduces LLMProxy, EnvManager, SampleBuffer, and AsyncController."
- Generalized Advantage Estimation (GAE): A technique to compute low-variance, bias-controlled advantage signals in RL. "advantage , typically computed via Generalized Advantage Estimation (GAE)~\citep{schulman2015high}"
- Group Relative Policy Optimization (GRPO): A critic-free RL algorithm that derives token-level advantages from normalized group reward statistics. "Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath} proposes a critic-free alternative that constructs advantage signals by sampling multiple responses per prompt and normalizing their rewards."
- Importance sampling (IS) weights: Reweighting factors applied to off-policy samples to correct for distribution mismatch between behavior and target policies. "which retains gradients for all samples but clips the importance sampling weights to stabilize training"
- Importance-sampling (IS) ratio: The ratio of current to behavior policy probabilities used in off-policy gradient correction. "Gradient truncation, which truncates gradients for tokens whose importance-sampling (IS) ratios lie outside a trust region"
- KL divergence: A measure of divergence between probability distributions, used for regularizing policy updates. "GRPO adds KL divergence explicitly as a regularization term in the loss."
- LLMProxy: The proxy orchestrator that schedules, executes, and post-processes LLM inference requests across backend workers. "violet introduces LLMProxy, EnvManager, SampleBuffer, and AsyncController."
- Long-tail rollouts: Rare but very long generation instances that cause stragglers, idle resources, and poor throughput. "long-tail rollouts incur substantial resource idleness and underutilization."
- Memory-bandwidth bound: A regime where performance is limited by memory throughput rather than compute, constraining scaling. "Decoding is predominantly memory-bandwidth bound, so scaling out to more GPUs does not increase decoding speed."
- Off-policy algorithms: Methods that enable learning from data generated by older or different policies while maintaining stability. "we implement several popular off-policy algorithms and verify that asynchronous training can achieve performance on par with synchronous training."
- On-policy: A training setting where data is generated by the current policy being optimized, with strict synchronization. "Sync-ROLL (On-policy): A synchronous architecture enhanced with ROLL-specific optimizations, including Queue Scheduling and Prompt Replication"
- Pass@1: An accuracy metric indicating whether the first generated solution is correct. "all methods achieve comparable Pass@1 accuracy across benchmarks and differences are minimal."
- Prefill step: An inference phase that processes the prompt/context before iterative decoding begins. "executing a single decoding or prefill step over a batch of requests"
- Producer–consumer model: A pipeline pattern where data producers (rollout) continuously feed consumers (training) to avoid stalls. "Asynchronous training follows a producerâconsumer model, where the rollout stage remains saturated with continuous response generation and does not stall for the training stage."
- Proximal policy: An intermediate policy used to constrain updates or bridge between old and current policies in off-policy PPO variants. "Decoupled PPO introduces a proximal policy $\pi_{\mathrm{prox}$ to better regulate policy updates."
- Proximal Policy Optimization (PPO): A popular RL algorithm that uses a clipped surrogate objective to limit policy updates for stability. "PPO \citep{schulman2017proximal} is a widely used policy gradient algorithm based on the actor-critic framework."
- Proximal reference model: A fixed or slowly-updated reference policy used to compute regularization (e.g., KL) or stability checks. "our training phase includes not only parameter updates but also inference passes over both the initial and proximal reference models."
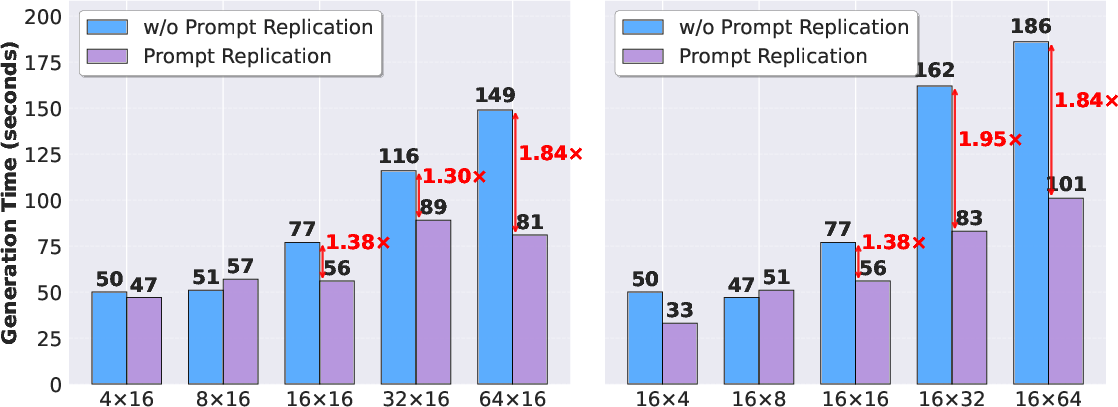
- Prompt replication: Strategy to duplicate prompts across GPUs to smooth load, mitigate stragglers, and improve utilization. "Leveraging this capability, we implement prompt replication and redundant environment rollouts"
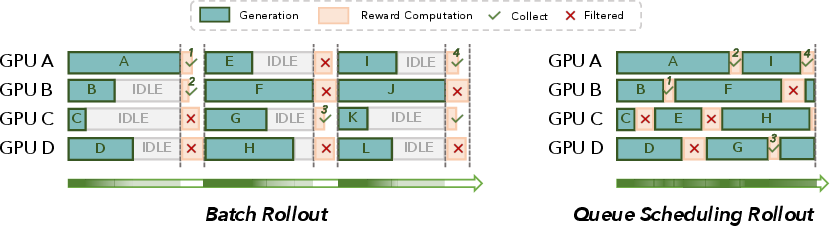
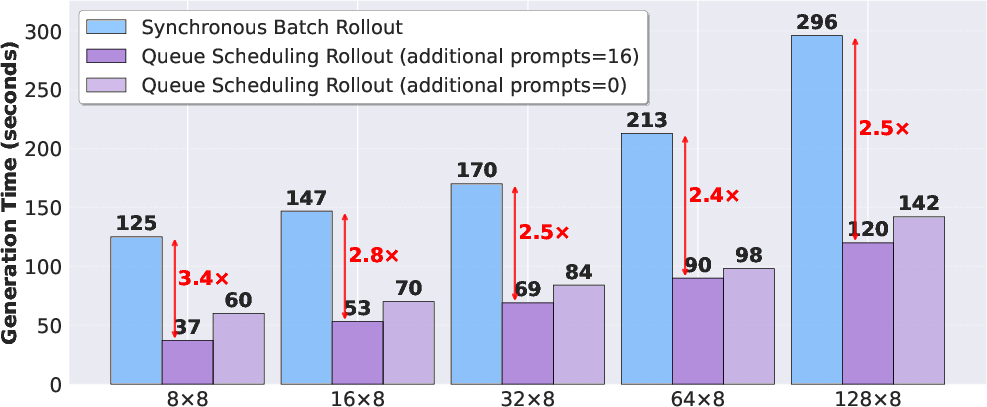
- Queue scheduling: A fine-grained scheduling mechanism that immediately assigns new tasks to any idle worker to reduce tail latency. "violet provides flexible programming interfaces that enable a fully asynchronous training architecture and support efficient rollout mechanisms, including queue scheduling and environment-level asynchronous execution."
- Resource bubbles: Periods of idle compute due to synchronization barriers or straggling tasks that reduce utilization. "Nevertheless, they often suffer from severe resource bubbles, particularly during the rollout stage"
- Reward shaping: Modifying reward signals to improve learning dynamics without changing optimal policies. "Theoretically, it acts as reward shaping that emphasizes intra-group differences to preserve gradient discriminability"
- RLVR: A class of reinforcement learning tasks emphasizing verifiable rewards for LLM post-training. "violet achieves up to speedup on RLVR tasks"
- ROLL: A reinforcement learning post-training system/framework that violet extends with asynchronous capabilities. "we present violet, which strengthens ROLL~\citep{roll} with asynchronous execution"
- Rollout–train decoupling: Architectural separation of rollout and training to run concurrently on distinct resources. "Second, rollout--train decoupling places the rollout and training stages on separate resources and executes them in parallel."
- SampleBuffer: A shared buffer storing generated trajectories for asynchronous consumption by the training stage. "A pool of blue{EnvManager} processes act as independent producers: they generate trajectories and enqueue them into SampleBuffer."
- Stop-gradient operator: A computational operation that blocks gradient flow through specific terms to stabilize optimization. "We use to denote the stop-gradient operator (gradients are not backpropagated through this term)"
- TOPR: An off-policy method that truncates IS weights selectively, preserving learning signals from high-return samples while suppressing noise. "Notably, TOPR partitions trajectories into two sets: (high-return/correct) and (low-return/incorrect), applying truncation only to to preserve learning signals from good trajectories while suppressing noise from poor ones."
- Trajectory: A sequence of states, actions, and rewards collected during environment interaction. "producing tuples of states and actions that form a trajectory."
- Trust region: A bounded interval around unity for IS ratios that constrains updates to prevent instability. "tokens whose importance-sampling (IS) ratios lie outside a trust region"
- Truncated IS: An off-policy technique that caps IS ratios to reduce variance and stabilize learning. "e.g., Truncated IS~\citep{munos2016safe,espeholt2018impala}, CISPO~\citep{chen2025minimax} and TOPR~\citep{roux2025tapered}"
- vLLM: A high-throughput LLM inference engine used as the backend in the serving pipeline. "manages an inference engine (e.g., vLLM)."
- Weighted TOPR: A variant of TOPR that adjusts the balance between positive and negative samples to improve stability. "We also introduce Weighted TOPR, which improves stability by flexibly balancing positive and negative samples, thereby enhancing stability across diverse training scenarios."
Collections
Sign up for free to add this paper to one or more collections.