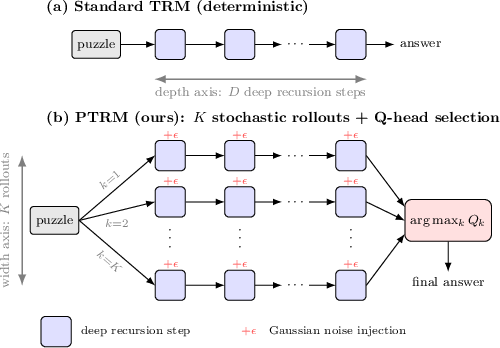
Probabilistic Tiny Recursive Model
Abstract: Tiny Recursive Models (TRM) solve complex reasoning tasks with a fraction of the parameters of modern LLMs by iteratively refining a latent state and final answer. While powerful, their deterministic recursion can lead to convergence at suboptimal solutions, without escape mechanism. A common workaround relies on task-specific input perturbations at test time combined with answer aggregation via voting. We introduce Probabilistic TRM (PTRM), a task-agnostic framework for test-time compute scaling that addresses this limitation through stochastic exploration. PTRM injects Gaussian noise at each deep recursion step, enabling parallel trajectories to explore diverse solution basins, and selects among them using the model's existing Q head (used for early stopping in the original TRM). Without requiring retraining or task-specific augmentations, PTRM enables substantial accuracy gains across benchmarks, including Sudoku-Extreme (87.4% to 98.75%) and on various puzzles from Pencil Puzzle Bench (62.6% to 91.2%). On the latter, PTRM achieves nearly double the accuracy of frontier LLMs (91.2% vs. 55.1%) at less than 0.0001x the cost, using only 7M parameters.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple but powerful way to make a small “thinking” AI better at solving logic puzzles like Sudoku. The base system, called a Tiny Recursive Model (TRM), thinks in steps: it keeps a private “scratchpad” and repeatedly improves its answer. The new idea, called Probabilistic TRM (PTRM), adds tiny, carefully controlled randomness while the model thinks and then uses the model’s own built‑in “confidence meter” to pick the best answer. This boosts accuracy a lot without retraining the model or writing puzzle‑specific tricks.
What questions were they trying to answer?
- Why does a TRM sometimes get stuck on a wrong answer even though it’s close to the right one?
- If we let the model explore several slightly different “thinking paths,” can at least one path find the correct answer?
- Can the model’s own confidence signal (its “Q head”) reliably tell us which of those answers is most likely correct, so we can pick it at test time?
How did they approach it? (Everyday analogy)
Think of the model as a student solving a puzzle on a whiteboard:
- TRM (the base method): The student writes a rough answer, then improves it step by step on the same whiteboard. Because the process is deterministic, the student always follows the same thought path and ends up at the same answer each time. If the student wanders into a “bad groove,” they may keep circling there and never reach the correct solution.
- The problem: Sometimes the student’s thoughts get stuck in a “valley” of wrong ideas. In the paper, these valleys are called “bad basins.” Once you’re in one, it’s hard to climb out.
- PTRM (the new method): Instead of one student taking one path, imagine K identical students solve the same puzzle in parallel. At each thinking step, each student gets a tiny random nudge (like a gentle wiggle of the whiteboard marker). These nudges make them follow slightly different thought paths. After they finish, each student also reports how confident they feel about their answer. This confidence comes from the model’s built‑in “Q head,” trained to tell if an answer is correct. We then pick the answer from the most confident student.
Two scaling knobs:
- Depth (more steps for one student): Let one student think longer.
- Width (more students in parallel): Let many students think at once and choose the best result. The paper shows width is especially effective because parallel attempts are independent and can be run at the same time.
A few terms in simple words:
- “Latent state”: the model’s private scratchpad.
- “Gaussian noise”: tiny, well‑behaved random wiggles added to the scratchpad so each attempt explores a different path.
- “Q head”: a small part of the model that estimates how likely the current answer is correct—basically a confidence meter.
What did they discover? (Key results)
Here are the main takeaways, explained simply:
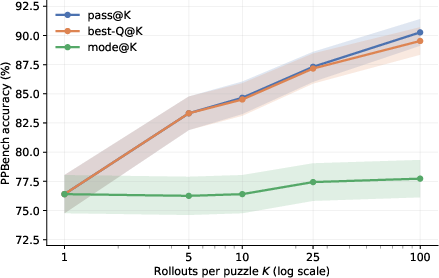
- Multiple tries + confidence picking works: Adding small random nudges at each step and running many parallel tries helps the model escape wrong‑answer valleys and find right answers more often. The model’s confidence meter is usually very good at picking the correct one among the tries.
- Big accuracy gains without retraining:
- On Sudoku-Extreme, accuracy jumped from about 87% to about 99%.
- On a set of different logic puzzles (PPBench), accuracy rose from about 63% to about 91%.
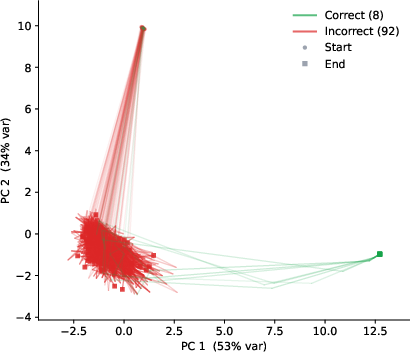
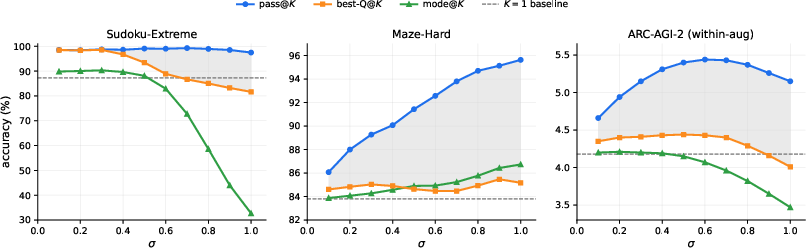
- On another maze puzzle set (Maze-Hard), the method found many more correct answers than before; the confidence picker helped, though it wasn’t perfect on this task.
- On the ARC-AGI-2 challenge, there were smaller but still positive improvements.
- Beats much larger AI systems at a tiny cost: On the PPBench puzzles, this tiny 7‑million‑parameter model using PTRM outperformed some of the most advanced LLMs and even an ensemble of them—while costing a tiny fraction to run.
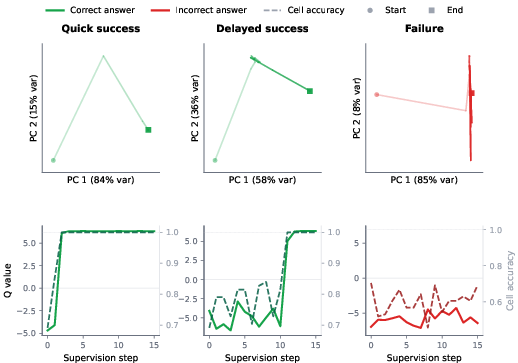
- Confidence follows progress: During the model’s step-by-step reasoning, the confidence meter tends to rise when the partial answer gets closer to correct and stay low when it doesn’t—making it a useful guide for selecting the best rollout.
Why is this important?
- Smarter use of compute at test time: Instead of training bigger models, we can get better results by using the same small model more cleverly when it’s time to answer—run several slightly different thought paths and pick the best.
- Cheaper and greener: A small model that rivals or beats huge models means less money and energy spent.
- Plug‑and‑play: No retraining and no puzzle‑specific tricks are required. You can add this method on top of an existing TRM and likely see gains.
Limitations and future work
- Focused on puzzles: The tests were mainly on grid puzzles (like Sudoku) with clear right/wrong answers. Results may vary on other kinds of problems.
- Not perfect everywhere: On some tasks (like Maze-Hard), the confidence meter wasn’t always the best at picking the right solution, even though correct solutions existed among the tries. Building a stronger checker could improve this further.
- Scale and variety: They used smaller puzzle sizes due to compute limits and tested a subset of puzzle types; more testing would help confirm how broadly this works.
Overall, the paper shows a simple idea—try many slightly different reasoning paths and pick the most confident answer—can make a small “thinking” model perform much better, often beating far larger systems at a tiny cost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work:
- Generalization beyond small-grid puzzles is untested: results are limited to 9×9/10×10 grids and six PPBench types, leaving scalability to larger boards and to the remaining ~88 PPBench puzzle types unknown.
- Transfer to non-grid tasks is unstudied: it remains unclear whether PTRM’s gains extend to math, code, text-based reasoning, or other non-visual/verifiable domains.
- Fairness of cost comparisons is uncertain: PTRM’s GPU wall-clock is compared to provider LLM costs without harmonized assumptions (e.g., amortized infrastructure, batching effects, or energy), which may bias cost-per-correct metrics.
- Selection reliability varies by task: the Q head fails to close the gap to pass@K on Maze-Hard; the paper does not quantify calibration (e.g., AUROC/ECE) or propose selection fixes beyond noting the gap.
- No ablation on where to inject noise: the method injects isotropic Gaussian noise into z at every supervision step; it remains unknown whether injecting into y, both y and z, or into layer-wise activations/weights is better.
- No ablation on when/how to inject noise: there is no study of initial-only noise vs. per-step noise in this setting, stepwise schedules (e.g., annealing), or adaptive σ that responds to Q or latent dynamics.
- Noise distribution design is unexplored: alternatives to Gaussian (e.g., Laplace, uniform, correlated, antithetic, quasi-random) and structured perturbations (e.g., low-rank, subspace-constrained) are not evaluated.
- Exploration strategies are limited: the paper does not compare noise-based exploration to other test-time diversification methods (dropout at inference, weight noise, ensembling checkpoints, MCMC/Langevin dynamics, or gradient-guided perturbations).
- Selection strategies are narrow: only best-Q and mode are evaluated; weighted voting by Q, per-cell confidence aggregation, rank aggregation, or meta-verifiers are not explored.
- Per-step selection is not investigated: selection is performed only on final states; combining information across steps (e.g., best-Q across steps, early commitment when Q spikes, or trajectory-level scoring) may improve reliability and compute-efficiency.
- Adaptive compute is not leveraged: K, D, and σ are fixed per benchmark; instance-wise policies that allocate compute based on early Q signals (e.g., successive halving or bandit allocation) are not studied.
- Using Q for inference-time halting is untested: although Q supports ACT during training, the paper does not evaluate Q-driven early stopping at inference to reduce depth or stop unpromising rollouts.
- Stability and regressions are unquantified: the paper does not report how often noise causes previously correct deterministic predictions to flip to incorrect, or characterize failure modes induced by high σ.
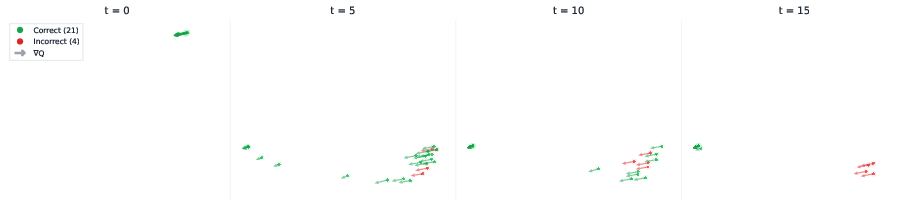
- Mechanistic understanding is limited: beyond PCA projections, there is no quantitative analysis of basin structure (e.g., fixed points, Jacobian spectra, attraction basins, or Lyapunov stability) to explain why/when noise yields escapes.
- Scaling laws for width vs. depth are not established: there is no systematic compute–accuracy frontier showing diminishing returns or optimal K–D trade-offs across tasks.
- Lack of theory for σ–K–D design: success probabilities vs. σ and K are empirical; a simple model for escape probabilities or principled σ schedules is not provided.
- Independence of rollouts is assumed but untested: the correlation between rollouts under isotropic noise (and its effect on pass@K gains) is not measured; decorrelation techniques (e.g., antithetic pairs) are not examined.
- Q head robustness to noise is unproven: Q is trained without noise but used to rank noise-perturbed latents; the impacts of this train–test mismatch on calibration and selection are not quantified.
- Training-time improvements to verification are absent: no experiments assess retraining Q with contrastive objectives, noise augmentation, or puzzle-specific constraints to close the best-Q vs. pass@K gap.
- Constraint-aware verification is not developed: especially for ARC-AGI-2, where verification is hard, the authors do not test constraint checkers, differentiable verifiers, or small verifier networks trained to supplement Q.
- Architecture dependence is unclear: PTRM is tried with TRM-MLP (Sudoku) and TRM-Att (others) without a controlled study of how architecture influences basin geometry, σ sensitivity, and Q calibration.
- Interactions with augmentation pipelines are partial: for ARC-AGI-2, Q is used within-augmentation and then voted across augmentations; cross-augmentation calibration or global selection is not analyzed.
- Hyperparameter transferability is unknown: σ/K/D tuned per dataset may not generalize across puzzle types or scales; no guidelines or auto-tuning procedures are offered.
- Large-K practicality and latency constraints are not addressed: how PTRM performs under tight latency budgets, limited memory, or higher K (e.g., >100) with realistic parallelization constraints remains open.
- Reproducibility and variability are lightly treated: results are averaged over three seeds; broader variability analyses, ablation transparency (e.g., σ sweeps per task), and code/checkpoint availability are not detailed.
- Multi-solution or partially correct tasks are not considered: how Q behaves when multiple valid solutions exist, or when partial-credit metrics are relevant, is not explored.
- Safety under distribution shift is unexamined: robustness to adversarial perturbations, novel puzzle styles, or shifts in clue distributions is not evaluated; Q miscalibration under shift is a risk.
- Comparison to initial-noise-only baselines is indirect: prior reports of negative results are cited, but a head-to-head ablation in the authors’ setting would clarify the importance of per-step noise.
- Downstream uses of PTRM are unexplored: self-improvement loops (e.g., using high-Q rollouts as pseudo-labels), curriculum scheduling of σ, or test-time adaptation are not investigated.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and tooling, especially in settings with verifiable, single-solution problems where PTRM’s Q-head can act as an internal verifier.
- On-device puzzle and game solvers (education, consumer software)
- Use PTRM to deliver near–state-of-the-art Sudoku/logic puzzle solvers on phones or low-cost devices by running K parallel stochastic rollouts and selecting with the Q head, avoiding cloud LLM costs while improving accuracy over deterministic TRM.
- Potential products/workflows: mobile apps for Sudoku/PPBench-style puzzles; teacher dashboards that auto-generate step-by-step solutions; offline “hint engines.”
- Assumptions/Dependencies: availability of a TRM-like backbone trained on the target puzzle; solutions are verifiable; modest parallel compute or batched rollouts.
- Constraint-based scheduling at small/medium scale (operations, SMB tools)
- Apply PTRM to employee rostering, classroom/exam timetabling, or meeting-room assignments where feasibility can be checked; use Q head to pick among candidate schedules and escalate to a heavier solver only if Q remains low.
- Potential products/workflows: spreadsheet add-ins; SaaS microservices that expose a “solve-or-escalate” API; on-prem tools for schools and clinics.
- Assumptions/Dependencies: clear constraints and a verifiable objective; training data that reflects domain constraints; parallelism budget for K rollouts.
- Embedded route and path planning for grid/maze-like environments (robotics, warehousing)
- Use PTRM for fast, low-cost path planning in discrete grids (e.g., maze-like layouts, shelf-to-pack routes) with Q as a feasibility/quality filter; run K in parallel and select highest-Q trajectory.
- Potential products/workflows: warehouse AGV path planners; microcontrollers/GPU-edge modules that pre-screen candidate paths before execution.
- Assumptions/Dependencies: discrete state/action spaces or discretized representations; safety envelope that verifies plans before actuation; Q head aligns with feasibility indicators.
- Rapid, low-cost candidate generation before exact solvers (software, EDA, OR)
- Deploy PTRM as a front-end “proposal generator” that quickly finds good basins for constraint satisfaction (e.g., simple PCB routing, floorplanning sketches), handing the best-Q candidate to a classical solver for refinement.
- Potential products/workflows: EDA tool plugins; OR pipelines that interleave PTRM proposals with MILP/SAT/SMT solvers.
- Assumptions/Dependencies: inexpensive verifier or objective; pipelines to integrate with exact solvers; task distribution close to training.
- Verification-aware fallback policies in production reasoning systems (MLOps, reliability)
- Put the Q head on the serving path as a quality gate: if all K candidates have low Q, escalate to an LLM/canonical solver; otherwise return the best-Q answer. This reduces cloud spend while maintaining accuracy.
- Potential products/workflows: API gateways with tiered compute policies; observability dashboards tracking Q distributions and pass@K gaps.
- Assumptions/Dependencies: calibrated Q head; defined escalation path; latency budget for parallel rollouts.
- Educational tools for explainable reasoning (education)
- Provide multiple candidate solution trajectories and select the strongest (highest-Q), while surfacing alternative rollouts for pedagogy (e.g., “why this went wrong”).
- Potential products/workflows: interactive tutoring apps that visualize basin escapes; teacher tools with per-step Q and cell-accuracy tracks.
- Assumptions/Dependencies: verifiable tasks; UI to expose trajectories; privacy-friendly on-device inference if needed.
- Edge AI for resource-constrained environments (public sector, NGOs)
- Replace expensive LLM agent loops with PTRM for verifiable tasks in low-connectivity settings (e.g., field logistics checklists, inventory reconciliations).
- Potential products/workflows: offline kits with pre-trained TRMs; batch-mode K scaling tuned to power/latency limits.
- Assumptions/Dependencies: tasks convertible to discrete, verifiable outputs; basic parallelism (CPU cores/GPU); domain-specific training.
Long-Term Applications
These applications require further research to strengthen verifiers, generalize to less-structured tasks, or integrate with safety and compliance processes.
- General reasoning on complex, partially verifiable tasks (software, enterprise AI)
- Extend PTRM beyond puzzles to document validation, forms checking, and structured extraction with partial verifiers (unit tests, schemas). Combine Q with external learned/verifier modules to select among K stochastic rollouts.
- Potential tools/workflows: “verifier-augmented” inference stacks where Q is one signal among runtime tests; adaptive K/D tuning based on budget and risk.
- Assumptions/Dependencies: robust verifiers for partial correctness; improved Q calibration; retraining for domain-specific reasoning.
- Program synthesis and code repair with test-driven selection (developer tools)
- Train TRM-like models to propose code patches; run PTRM to explore multiple latent trajectories; use unit tests/static analysis as additional selection signals with the Q head.
- Potential tools/workflows: IDE extensions for low-cost patch suggestions before invoking large code models; CI bots that escalate if Q/test signals diverge.
- Assumptions/Dependencies: mapping code tasks to TRM-style latent refinement; strong test suites; secure sandboxes for execution; improved Q to reflect code quality, not just feasibility.
- Multi-step planning and control with safety-verified selection (autonomy, robotics)
- Use PTRM to generate K candidate plans in model-predictive control; combine Q with formal/simulation-based safety checks; select feasible plans under tight latency.
- Potential tools/workflows: “safety-gated PTRM planners” for drones/AMRs; co-processors that handle parallel rollouts; hierarchical planners where PTRM handles subproblems.
- Assumptions/Dependencies: real-time guarantees; certified safety wrappers; domain adaptation; Q head enhanced to capture safety margins (not only correctness).
- Operations research at scale with hybrid solvers (logistics, energy, finance)
- Employ PTRM as a scalable proposal engine for large routing, dispatch, or portfolio-allocation problems; pass best-Q candidates to stochastic/robust optimizers for finalization.
- Potential tools/workflows: logistics controllers that pre-seed vehicle routes; microgrid controllers that pre-screen dispatch schedules; pre-trade risk filters.
- Assumptions/Dependencies: scalable encodings to TRM; reliable feasibility checks; infrastructure to parallelize K at cluster scale; alignment of Q with economic/safety objectives.
- Healthcare planning and decision support with auditable reasoning (healthcare)
- Apply PTRM to verifiable subproblems (OR scheduling, bed assignment, guideline-constrained treatment sequences); use Q to triage candidate plans and surface rationales.
- Potential tools/workflows: hospital operations consoles; audit trails logging Q and trajectory metrics; human-in-the-loop approval.
- Assumptions/Dependencies: regulatory/compliance validation; high-fidelity constraint sets; calibrated Q; governance for escalation and overrides.
- Policy and civic resource allocation with cost-aware AI (public sector)
- Use PTRM for low-cost, transparent allocation/scheduling in municipalities (e.g., equipment dispatch, shift planning) with internal Q-based assurance and auditable selection.
- Potential tools/workflows: civic tech platforms offering “PTRM-first, escalate on low-Q” workflows; public audit dashboards.
- Assumptions/Dependencies: public data standardization; procurement acceptance of on-device/low-cost AI; safeguards against dataset shift.
- Test-time compute controllers and auto-tuners (ML systems)
- Build controllers that adapt K, depth D, and noise σ per instance to meet SLAs while maximizing accuracy; use pass@K vs. best-Q gaps during validation to set policies.
- Potential tools/workflows: Auto-tuning services; Kubernetes operators that scale inference replicas for width; per-request dynamic budgets in APIs.
- Assumptions/Dependencies: monitoring of Q distributions; reliable correlation between Q and correctness; infra for elastic parallelism.
- Stronger verifiers and learned Q heads for open-ended tasks (research, safety)
- Develop multi-signal verifiers (Q + learned critics + external checks) to close the best-Q vs. pass@K gap seen on tasks like Maze-Hard and ARC-AGI-2; enable PTRM on tasks with weak or delayed verifiability.
- Potential tools/workflows: verifier training pipelines; calibration and out-of-distribution detection; confidence-to-escalation policies.
- Assumptions/Dependencies: datasets with verifier labels; methods to avoid verifier gaming; harmonization of signals into a single selection criterion.
- Hardware-accelerated parallel rollouts on edge (semiconductors, devices)
- Implement PTRM’s width scaling on NPUs/FPGAs for low-latency, low-power inference with many parallel rollouts, enabling on-device reasoning assistants.
- Potential tools/workflows: firmware libraries for batched stochastic recursions; σ-schedulers optimized for energy/perf.
- Assumptions/Dependencies: vendor support for small-batch parallelism; memory-efficient TRM variants; real-time RNG and isolation.
- Cross-model ensembles with verifier-guided selection (enterprise AI)
- Combine multiple small TRMs trained on complementary distributions; run PTRM per model and select across models via meta-Q/verifiers for robust performance under shift.
- Potential tools/workflows: ensemble routers; cost-aware selection layers prioritizing lowest-cost high-Q candidates.
- Assumptions/Dependencies: calibration across models; ensemble governance; prevention of conflicting biases.
In all cases, PTRM’s feasibility is highest when:
- the task has a clearly verifiable solution (exact or approximate),
- a TRM-like model with a trained Q head exists for the domain,
- limited parallel compute is available to scale width K,
- and the Q head’s correlation with correctness is strong enough to select rare-but-correct trajectories.
Glossary
- Adaptive Computational Time (ACT): A mechanism that allows a model to halt computation early when it is confident in its current prediction. "an Adaptive Computational Time (ACT) halting mechanism is used."
- basin (latent space basin): A region in latent space where iterative updates tend to remain, often corresponding to a class of solutions (good or bad). "bad latent space basins (i.e., regions of the latent space which decode to incorrect answers and from which the deterministic recursions cannot escape)"
- best-Q@K: A selection metric that deems the rollout with the highest Q score correct among K candidates. "best-Q@K (the rollout with highest \hat{q} is correct) is a metric available at inference without a correctness oracle."
- binary cross entropy (BCE): A loss function used for binary classification tasks, measuring the difference between predicted probabilities and binary labels. "This is done by adding a binary cross entropy loss between a halting logit \hat{q}=f_Q(y) and the binary exact correctness of the predicted answer \hat{y}=\arg\max f_O(y)"
- cell accuracy: The fraction of individual cells in a grid-like output that are correct, used as a fine-grained accuracy metric. "cell accuracy (fraction of correct cells in the predicted answer)"
- Chains of Thought: Multiple-step reasoning trajectories produced by LLMs that can lead to the same answer. "including Chains of Thought and actual answer"
- cross entropy (CE): A loss function measuring the divergence between predicted class probabilities and the true class distribution. "The loss at each step is calculated using cross entropy between the predicted answer logits f_O(y) and the ground truth y_{true}."
- deep recursion: Executing multiple inner latent updates before producing or refining an output, effectively increasing computational depth. "A deep recursion runs T latent recursions in sequence"
- deep supervision: A training strategy where intermediate states are supervised across multiple steps to encourage progressive refinement. "TRM is trained via deep supervision"
- depth scaling: Increasing the number of recursive (or supervision) steps at inference to allocate more compute per example. "Interaction with depth scaling."
- deterministic inference: An inference procedure with no randomness, yielding the same output for the same input every time. "their deterministic inference does not make full use of their capabilities."
- deterministic recursion: A fixed, non-random iterative update procedure that can converge to suboptimal fixed points. "their deterministic recursion can lead to convergence at suboptimal solutions"
- early stopping: Halting the iterative computation when a confidence signal indicates the current solution is likely correct. "(used for early stopping in the original TRM)"
- Gaussian noise: Random perturbations drawn from a Gaussian distribution added to latents to induce stochasticity. "PTRM injects Gaussian noise at each deep recursion step"
- halting mechanism: A procedure that decides when to stop further computation during training or inference. "Without halting mechanism during training"
- latent space: The internal representation space where the model’s hidden states evolve during reasoning. "regions of the latent space"
- latent state: The internal hidden vector(s) that encode the model’s current reasoning context. "a reasoning latent "
- latent trajectory: The path taken by the latent states across steps during recursive reasoning. "many distinct latent trajectories can reach it."
- logits: Raw, pre-softmax scores output by a model that can be converted to probabilities. "predicted answer logits "
- mode@K: A selection strategy that chooses the most frequent answer among K candidates. "mode@K (most frequent answer across rollouts)"
- oracle upper bound: A theoretical best-case metric assuming access to a perfect correctness signal. "pass@K (any rollout correct) is the oracle upper bound"
- output head: The final linear layer mapping latent representations to answer logits. "the model's output head "
- pass@K: The probability that at least one of K sampled candidates is correct. "pass@K (any rollout correct)"
- PCA (Principal Component Analysis): A dimensionality-reduction technique used to visualize high-dimensional latents. "PCA projection of (top)"
- principal plane: The two-dimensional subspace spanned by the top principal components used for visualization. "project the latents into the principal plane (PCA per puzzle)"
- Probabilistic TRM (PTRM): A stochastic inference framework for TRM that explores multiple noisy trajectories and selects via the Q head. "We introduce Probabilistic TRM (PTRM)"
- Q head: A linear projection trained to estimate the probability that the current answer is correct, used for selection or halting. "TRM's Q head is trained jointly (as a correctness classifier)"
- Q logit: The unnormalized score output by the Q head before applying a sigmoid, used to rank candidates. "the Q logit sharply separates the two populations"
- Q value: The confidence signal (often the sigmoid of the Q logit) indicating likely correctness. "Mean Q value (solid, left axis)"
- rollouts: Independent trajectories of recursive inference generated per input to explore different solutions. "we run parallel rollouts per puzzle"
- stochastic exploration: Randomized search through latent space to discover alternative solution basins. "addresses this limitation through stochastic exploration"
- stochastic rollouts: Noisy, parallel inference trajectories that diversify search paths in latent space. "PTRM: stochastic latent rollouts with Gaussian noise "
- supervision steps: The iterations during training or inference where the model refines latents and outputs under supervision. "for up to supervision steps."
- test-time augmentation: Modifications applied to inputs at inference to improve robustness or accuracy. "task-specific test-time augmentation"
- test-time compute scaling: Allocating additional inference-time computation (e.g., more steps or samples) to improve accuracy. "test-time compute scaling"
- Tiny Recursive Models (TRM): Compact recursive architectures that iteratively refine a latent state and answer. "Tiny Recursive Models (TRM) solve complex reasoning tasks"
- verifier: A mechanism (often external or learned) for assessing whether an output is correct. "a perfect verifier"
- voting: Aggregating multiple candidate answers by frequency or another rule to choose a final answer. "answer aggregation via voting"
- width scaling: Increasing the number of parallel rollouts to improve the chance of finding a correct solution. "Width scaling."
Collections
Sign up for free to add this paper to one or more collections.

