Test-time Recursive Thinking: Self-Improvement without External Feedback
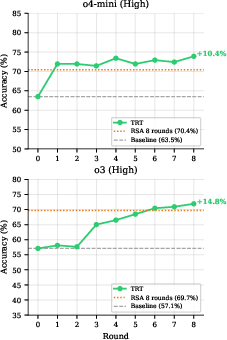
Abstract: Modern LLMs have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple idea to help AI models (like chatbots) get better at solving a problem while they’re solving it—without anyone telling them the right answer. The method is called Test-time Recursive Thinking (TRT). Think of it like a student who tries a few different ways to solve a problem, picks the best attempt, learns from the mistakes in the other attempts, writes a “don’t do this again” list, and then tries again—getting better each round.
What questions are the researchers asking?
They focus on two big questions:
- Can an AI improve its reasoning on the fly (at test time) without being trained again?
- How can it do two hard things at once: 1) Try many different, smart approaches (not just random guesses), and 2) Decide which answer is best without being shown the correct answer?
How does the method work?
Imagine you’re finding your way through a maze:
- You try several different paths (different strategies).
- You pick the path that seems best (best solution so far).
- You look at the wrong paths to see what went wrong (mistakes and pitfalls).
- You write down a short “do-not-do” list, so next time you avoid those bad paths.
- Then you try again with new, smarter strategies.
TRT follows exactly this loop in three stages, repeating it for a few rounds:
- Generate: The AI creates multiple solutions using different “strategies” (for example, in coding, one approach might focus on speed, another on memory; in math, one might use algebra, another might use cases).
- Select: The AI picks the best solution by checking itself.
- For math with one correct answer, it looks for answers many good attempts agree on.
- For code, it writes its own tests and runs the programs to see which one passes more tests.
- Reflect: The AI compares the best solution to the others, figures out why the weaker ones failed, and updates a short “don’t do this” knowledge list. Then it designs new strategies for the next round that avoid past mistakes.
A couple of helpful analogies:
- The “knowledge list” is like a personal checklist of mistakes to avoid (“don’ts”), not a long diary. This keeps memory short and useful.
- “Strategies” are like different game plans—try a greedy algorithm vs. dynamic programming in code, or try solving a math problem by working backward vs. breaking it into cases.
What did they find, and why does it matter?
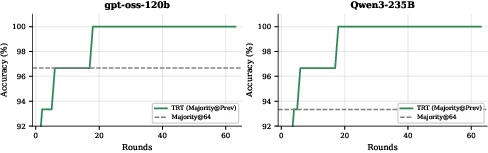
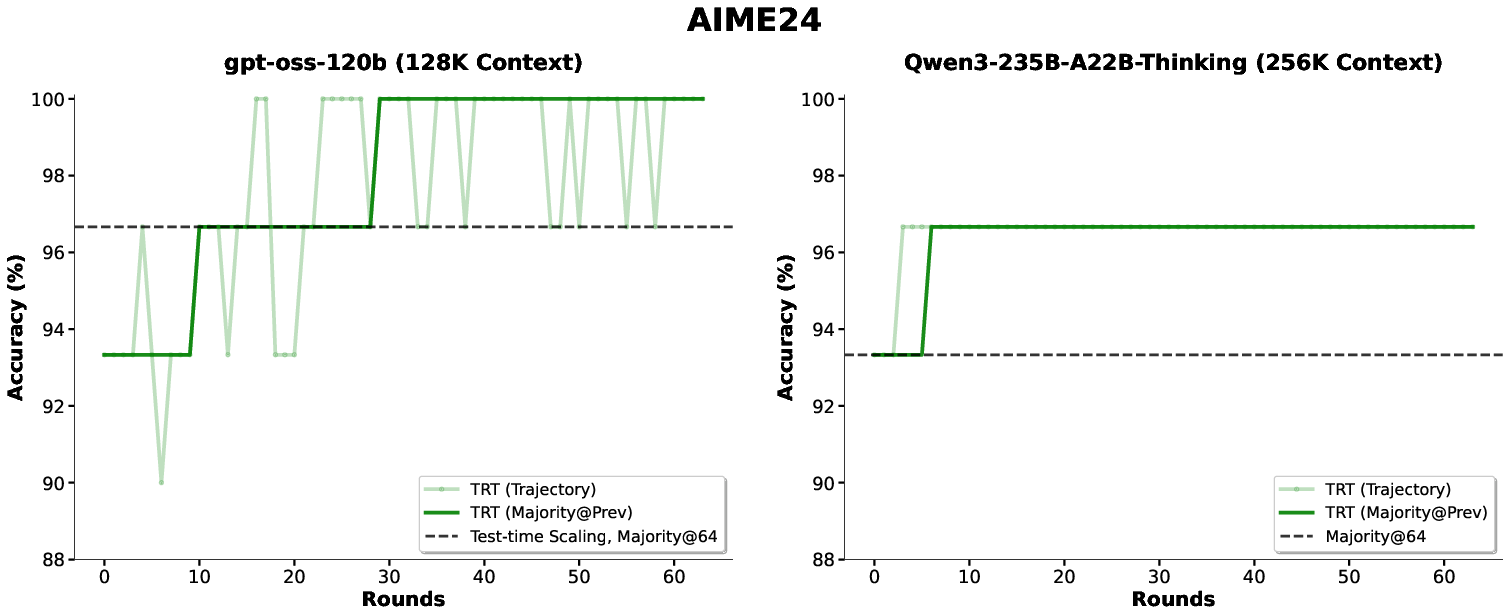
- Math (AIME 2025/2024): Using TRT, open-source models solved 100% of the problems—meaning they eventually got every answer right by learning from their own attempts.
- Code (LiveCodeBench hard problems): TRT boosted accuracy by about 10–15 percentage points for strong coding models. It also beat another multi-try method that combines solutions (RSA).
- The wins come from two things working together:
- Better exploration: designing different strategies each round finds more good ideas than random sampling.
- Better selection: self-made tests for code help pick the strongest solution each round.
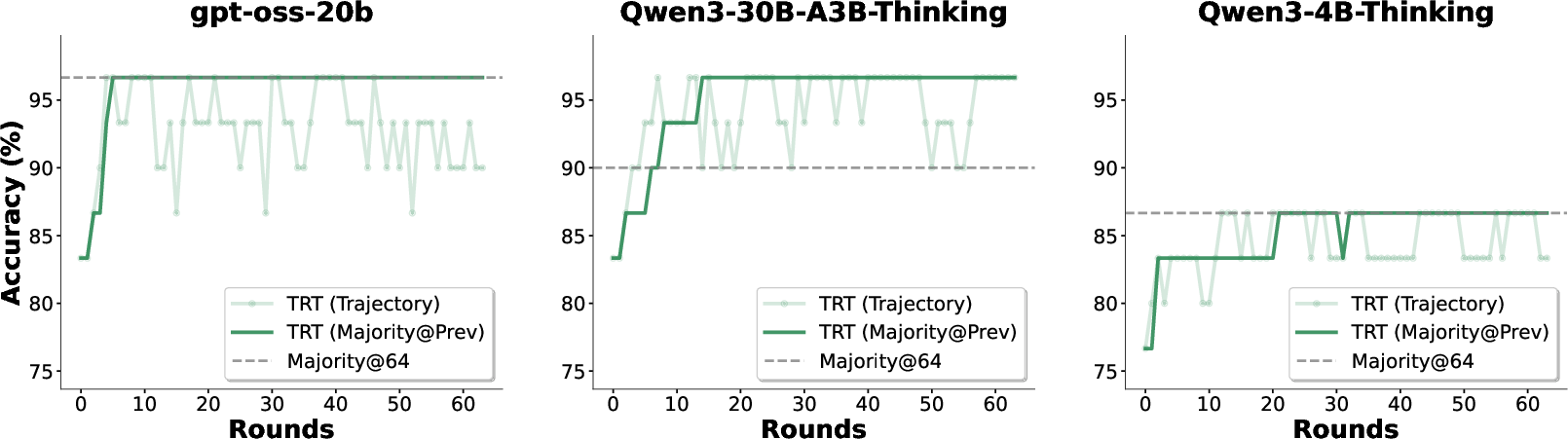
- “Depth beats breadth”: Doing more rounds of “try, pick, learn” helps more than just trying a bigger batch all at once.
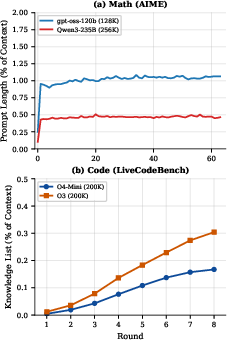
- Tiny memory, big impact: The “don’t do this again” list stayed very small (well under 2% of the model’s context), so it doesn’t clog the AI’s memory.
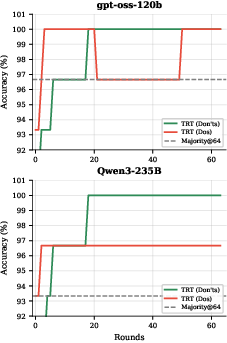
- Learning from failures works: Writing down what to avoid (“don’ts”) helped more than writing down what worked (“dos”), especially in math.
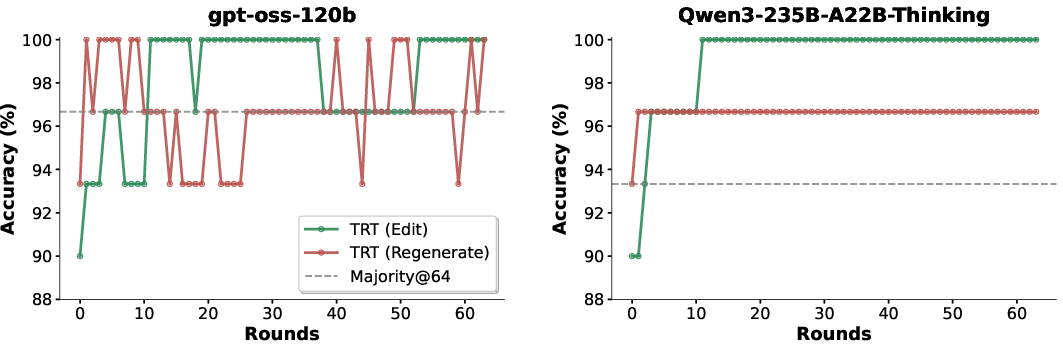
- Real breakthroughs: TRT solved some problems that weren’t solved even after many independent attempts—meaning the method didn’t just get luckier; it explored smarter.
Why is this important?
TRT shows that an AI can improve itself, on the spot, without extra training or being shown the right answers. That can make:
- Math solvers and coding assistants more reliable
- Fewer repeated mistakes (thanks to the “don’t” list)
- Better use of the same compute budget (finding better solutions with smarter exploration and self-checks)
There are limits: writing good tests is hard, and this process uses extra time because it repeats in rounds. But the benefits—more correct answers without extra training data—are promising.
What could come next?
- Sharing knowledge across different problems (not just within one) to generalize faster
- Stronger self-checks (like better tests or proof checkers)
- Combining TRT with training-time methods to make future models even better at this “try–pick–learn” loop
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Generalization beyond two domains:
- Validate TRT on tasks without single definitive answers (e.g., open-ended reasoning, multi-step proofs, planning, dialog) and on domains where execution-based verification is impractical.
- Selection without ground truth:
- Develop and benchmark stronger self-verification mechanisms for non-executable tasks (e.g., proof checkers, logical consistency checks, constraint solvers, probabilistic self-auditing), and quantify how they reduce the selection gap.
- Coverage and reliability of model-generated tests:
- Measure unit-test coverage and quality (mutation testing, differential testing, path coverage) and quantify false-pass/false-fail rates; analyze how insufficient tests misguide selection and knowledge accumulation.
- Robustness to incorrect “best” selections:
- Study failure modes where an incorrect rollout is selected as , leading to drift in accumulated “don’t” knowledge; design recovery mechanisms (e.g., cross-round re-evaluation, adversarial testing, ensemble self-verification).
- Stability across runs and seeds:
- Report variance, confidence intervals, and statistical significance on LiveCodeBench and other datasets; the paper only demonstrates instance-level stability for AIME.
- Compute/efficiency tradeoffs:
- Provide wall-clock, token, and energy cost per round; derive compute-optimal schedules for depth () vs. breadth (), and adaptive stopping rules under fixed budgets.
- Baseline coverage:
- Compare TRT against stronger or more varied baselines under matched compute (e.g., Tree of Thoughts, Best-of-N with process/outcome reward models, inverse-entropy sequential voting, beam search with verification).
- Open-source replication in code:
- Test TRT with open-weights coding models to assess replicability without proprietary systems; quantify how model quality affects test generation and selection reliability.
- Details of execution environment:
- Specify sandboxing, resource limits, and security policies for running model-generated code; evaluate safety, determinism, and the impact of environment differences on pass rates.
- Knowledge representation and pruning:
- Systematically ablate the design choices (negative “don’t” constraints vs. positive “do” rules; granularity; templating; conflict resolution; pruning strategy) and measure effects on performance and stability.
- Handling contradictory or outdated knowledge:
- Develop automated detection and resolution of conflicting knowledge entries, and adaptive pruning beyond “remove up to one per round”; measure its impact on long-horizon tasks.
- Cross-problem knowledge transfer:
- Aggregate and retrieve knowledge across tasks; quantify transfer gains, catastrophic interference, and the utility of global “playbooks” vs. per-instance memory.
- Theoretical guarantees:
- Formalize conditions for convergence, sample complexity, and selection error bounds under imperfect self-verification; characterize when depth truly beats breadth.
- Strategy diversity and causality:
- Go beyond correlational analysis to causally link strategy diversity to solve rates (e.g., controlled interventions on strategy clusters, counterfactual analysis).
- Dynamic re-selection across rounds:
- Explore inter-round re-ranking of accumulated candidate solutions using improved tests/knowledge, rather than selecting solely within each round; quantify recoverable accuracy.
- TRT instability cases:
- Analyze “TRT Unstable” problems (baseline solved, TRT lost) to identify root causes (e.g., over-pruning, mis-specified strategies, test-induced biases) and propose safeguards.
- Extension to more complex math:
- Evaluate TRT on mathematical tasks lacking mutual exclusivity or requiring formal proof validation; integrate autoformalization and proof assistants for selection.
- Bias in self-generated tests and strategies:
- Detect whether self-tests and strategies bias the system toward certain solution families; measure diversity collapse and propose debiasing (property-based tests, adversarial test generation).
- Prompting and reproducibility:
- Release full prompts for strategy design, selection heuristics, and reflection; perform sensitivity analyses on prompt variants to ensure reproducibility and robustness.
- Long-horizon scalability:
- Stress-test TRT with many more rounds and larger contexts to empirically validate memory efficiency claims; evaluate retrieval-augmented memory and compression methods.
- Integration with reward models or RL:
- Investigate hybrid TRT with lightweight learned verifiers or RL-trained selectors; quantify how little external supervision is needed to close the residual selection gap.
- Dataset scale and diversity:
- Expand beyond AIME (30 problems per year) and LiveCodeBench v6 hard split to larger and more diverse benchmarks; assess domain shift and long-tail performance.
- Safety and misuse risks:
- Systematically evaluate the societal impacts mentioned (e.g., energy cost, capability amplification) with concrete metrics, and propose mitigation strategies aligned with test-time scaling.
Practical Applications
Below are practical, real-world applications that arise from the paper’s Test-time Recursive Thinking (TRT) framework—an iterative “Generate → Select → Reflect” process that lets models self-improve at inference time without external labels—together with sector mapping, deployment ideas, and feasibility notes.
Immediate Applications
The following can be deployed with today’s LLMs where a self-verification signal exists (e.g., unit tests, simulators, consistency checks, mutual exclusivity of answers).
- TRT-powered coding assistants in IDEs (software)
- What: Enhance code generation reliability by synthesizing rollout-specific implementation strategies (e.g., DP vs. greedy), generating unit tests, executing them in a sandbox, and iteratively refining.
- Tools/products/workflows: VS Code/JetBrains plugins; “TRT mode” for GitHub Copilot/CodeWhisperer; local Docker sandbox for test execution.
- Assumptions/dependencies: Secure execution sandbox; reliable test generation; compute budget for multi-round inference.
- CI/CD “TRT Gates” for PR validation (devops/software)
- What: When a pull request introduces changes, generate multiple candidate fixes/implementations; auto-generate tests and select the best; reflect to record failure modes for subsequent runs.
- Tools/products/workflows: GitHub Actions/GitLab CI runners with TRT steps; ephemeral containers; caching of knowledge lists per repository.
- Assumptions/dependencies: Stable, deterministic tests; policy for compute/time budget; governance for auto-merging.
- Automated bug triage and hotfix selection (software/security)
- What: Generate multiple fix strategies for issues or CVEs; synthesize exploit/regression tests; select the patch that passes tests; store learned “don’ts” for recurring bug patterns (off-by-one, boundary checks).
- Tools/products/workflows: Issue tracker integration (Jira, GitHub Issues); SAST/DAST hooks; patch candidate ranking dashboard.
- Assumptions/dependencies: High-quality repro and test harnesses; sandboxed exploit testing; human approval for critical repos.
- Data/Analytics assistants with synthetic verification (data engineering/BI)
- What: Produce SQL/Pandas rollouts with different strategies (CTE vs. window functions, eager vs. lazy eval); auto-generate synthetic datasets and expected outputs to test code before applying to production.
- Tools/products/workflows: Notebooks (Jupyter, Databricks) with TRT cells; dbt pre-commit TRT checks; warehouse sandboxes.
- Assumptions/dependencies: Faithful synthetic data/test oracles; data access policies; reproducible environments.
- Enterprise search/Q&A with self-consistency checks (software/support)
- What: For single-answer queries (mutual exclusivity), sample reasoning paths and select via self-consistency/contradiction checks; preserve “rejected-answers list” to avoid repeated errors.
- Tools/products/workflows: RAG pipelines with answer-consistency validators; “rolling majority” answer aggregator.
- Assumptions/dependencies: Queries with unambiguous answers; calibrated self-judgment prompts; fallback escalation policy.
- Documentation/spec generation with auto-checkers (product/engineering)
- What: Draft multiple spec variants, generate acceptance criteria and edge-case tests (e.g., examples, I/O formats), select the draft consistent with criteria; record contradictions found to avoid repetition.
- Tools/products/workflows: Spec authoring assistants in Confluence/Notion; lint-like TRT checks for docs.
- Assumptions/dependencies: Clearly stated acceptance criteria; structured templates enabling machine-checks.
- Education: math/CS tutors with failure-driven feedback (education)
- What: For problems with unique answers (e.g., AIME-style math), use mutual exclusivity for selection and track “don’ts” (common pitfalls); for CS, generate tests and show why certain approaches fail.
- Tools/products/workflows: Interactive tutor apps; LMS integrations; step-by-step reflection feedback.
- Assumptions/dependencies: Task types with clear correctness signals; compute budget for multi-round feedback per student.
- Customer support/IT troubleshooting bots with TRT playbooks (support/IT ops)
- What: Generate multiple diagnostic paths, run safe commands/tests (e.g., ping, service status) in a sandbox, select the best remediation; record ineffective steps to avoid them in future tickets.
- Tools/products/workflows: Helpdesk integrations (Zendesk, ServiceNow); runbook orchestration with sandboxed probes.
- Assumptions/dependencies: Safe execution/simulation environment; guardrails for actions; auditable logs.
- Spreadsheet and no-code automation with self-tests (daily life/business ops)
- What: Create multiple spreadsheet formulas/macros or low-code automations; auto-generate sample sheets and assertions to verify; select and refine the most robust solution.
- Tools/products/workflows: Add-ins for Google Sheets/Excel; no-code platforms (Zapier, Airtable) with TRT verification steps.
- Assumptions/dependencies: Representable test cases; permission to operate on samples; clear success criteria.
- Content conversion/transformation pipelines (ETL/docs/devrel)
- What: Multiple conversion strategies (e.g., Markdown→HTML, JSON→CSV), generate conformance tests (schema checks, examples) and pick the strategy that passes; distill recurring data-format “don’ts”.
- Tools/products/workflows: ETL pipelines with TRT checkpoints; schema validators and content linters.
- Assumptions/dependencies: Machine-checkable schemas; high-quality validators; stable formats.
- Auto-grading and test design assistants (education/assessment)
- What: Given a programming or math assignment, propose diverse solutions, generate tests/rubrics, and refine to reduce false positives/negatives; store frequent student mistakes as “don’ts”.
- Tools/products/workflows: LMS integrations (Gradescope, Coursera); sandboxed execution for student code.
- Assumptions/dependencies: Cheating/overfitting safeguards; clear scoring policy; bias review.
- Agent frameworks with plug-and-play TRT loops (AI dev/tooling)
- What: Add a Generate-Select-Reflect wrapper around existing agents to improve pass@k and selected-solution accuracy without retraining.
- Tools/products/workflows: Orchestrators (LangChain, Smith, Semantic Kernel) with TRT modules; knowledge-list store (JSON or vector DB).
- Assumptions/dependencies: Domains with usable self-verification; context limits; minimal extra latency tolerated by users.
Long-Term Applications
These rely on higher-fidelity verifiers, stronger domain governance, or scaling TRT beyond single instances (e.g., shared knowledge across tasks), and thus need further research or infrastructure.
- Autonomous software maintenance at scale (software/enterprises)
- What: Continuous TRT agents that propose refactors, synthesize extensive regression suites, run them in CI, and safely merge improvements; cross-repo knowledge of anti-patterns.
- Tools/products/workflows: “Self-healing repo” platforms; TRT knowledge bases across orgs.
- Assumptions/dependencies: Org-wide test coverage; approval workflows; robust rollbacks and provenance.
- Robotics task planning with simulation-based selection (robotics/automation)
- What: Generate multiple task plans/policies, simulate across environment and edge cases, select best, and reflect on failure modes to refine policy search.
- Tools/products/workflows: High-fidelity simulators (Isaac, MuJoCo, Gazebo); safety sandboxes; policy validators.
- Assumptions/dependencies: Sim-to-real transfer reliability; fast, realistic simulation; safety-certified execution.
- Clinical decision support with guideline-constrained TRT (healthcare)
- What: Propose differential diagnoses/treatment plans, auto-check against machine-readable guidelines and contraindications, select safest plan; store “don’ts” (e.g., drug interactions).
- Tools/products/workflows: CDS modules integrated with EHRs; formalized guideline libraries; audit trails.
- Assumptions/dependencies: Regulatory approval; high-quality structured guidelines; clinical supervision; data privacy.
- Legal drafting/contract analysis with formal consistency checks (legal/compliance)
- What: Create alternative contract clauses, auto-check logical/semantic consistency (e.g., cross-references, definitions), select consistent draft; record recurring pitfalls.
- Tools/products/workflows: Legal authoring environments with TRT validators; clause-level knowledge bases.
- Assumptions/dependencies: Formal verification tools for legal logic; jurisdiction-specific rule sets; human oversight.
- Financial modeling and risk analysis with backtest-driven TRT (finance)
- What: Generate multiple trading/risk strategies, backtest/forward-test on rolling windows, select robust performance, capture failure patterns (overfitting, regime sensitivity).
- Tools/products/workflows: Backtesting harnesses; data governance; model risk management (MRM) alignment.
- Assumptions/dependencies: Clean datasets; lookahead-bias prevention; compliance and explainability.
- Scientific discovery assistants (labs/automation)
- What: Propose hypotheses/experiment protocols, simulate or run small-scale tests, select promising results, and accumulate negative constraints to guide future experiments.
- Tools/products/workflows: Lab automation (liquid handlers, robotic labs); scientific simulators; experiment tracking (ELNs).
- Assumptions/dependencies: Reliable simulators or high-throughput experiments; safety and ethics review.
- Cross-problem TRT knowledge hubs (org-level “playbooks”)
- What: Move from per-instance memory to org-wide “don’ts” and strategy libraries that improve future tasks across teams/domains.
- Tools/products/workflows: Centralized TRT knowledge services; taxonomy and vetting pipelines.
- Assumptions/dependencies: Knowledge curation and de-duplication; privacy/IP controls; drift detection.
- Training-time TRT optimization (model development)
- What: Meta-RL or RL fine-tuning that trains models to design better strategies and self-verifiers; “TRT-optimized” foundation models.
- Tools/products/workflows: Benchmarks for selection quality; synthetic verifiers during training.
- Assumptions/dependencies: Stable reward signals without ground truth; compute cost; generalization beyond seen verifiers.
- Dynamic test-time compute orchestration (systems/infra)
- What: Runtime systems that allocate rounds/rollouts adaptively based on uncertainty signals and selection gaps, optimizing latency vs. accuracy.
- Tools/products/workflows: Inference schedulers; A/B of depth vs. breadth policies; cost-aware routing.
- Assumptions/dependencies: Reliable uncertainty estimators; SLO-aware policies; observability.
- Regulatory compliance automation with machine-checkable rules (policy/compliance)
- What: Generate alternative compliance responses, auto-check against formalized regulations/standards, select compliant outputs; iterate to cover edge cases.
- Tools/products/workflows: Machine-readable regulatory corpora; audit and traceability layers.
- Assumptions/dependencies: Formalized, up-to-date regulations; third-party certification; human-in-the-loop governance.
- Human-in-the-loop verification marketplaces (multi-domain)
- What: Crowd or expert validators provide targeted tests/verifiers that TRT can incorporate when self-generated signals are insufficient.
- Tools/products/workflows: Test marketplace APIs; reputation systems; plug-in verifiers.
- Assumptions/dependencies: Incentive alignment; quality control; privacy/security constraints.
Common Assumptions and Dependencies Across Applications
- A domain-appropriate self-verification signal is available (unit tests, simulators, mutual exclusivity, formal rules, synthetic data, or consistency checks).
- Safe, sandboxed execution environments for code/tests and simulations.
- Compute budget for multi-round inference (depth often beats breadth; TRT adds reflection calls).
- Sufficient context window or compact memory design (TRT’s distilled “don’ts” help).
- Governance: auditability, security, and human oversight for high-stakes use cases.
- Risk of overfitting to self-generated tests/verifiers; mitigations include adversarial test generation, randomized test seeds, and periodic external evaluation.
These applications leverage the paper’s key findings: iterative depth (rounds) yields more gain than parallel breadth, selection improves dramatically with self-generated tests or structural properties, and distilled negative knowledge scales efficiently—enabling practical, compute-aware self-improvement without external labels.
Glossary
- Ablation: An experimental analysis that removes or adds components to measure their contribution to performance. "The ablation in~\cref{tab:ablation} shows that test execution contributes 7.4 percentage points of improvement, confirming its effectiveness for discriminating between candidates."
- Agentic Context Engineering: A method where the prompt context is treated as an evolving playbook that accumulates strategies across rounds. "\citet{zhang2025ace} propose Agentic Context Engineering, which treats contexts as evolving playbooks that accumulate and refine strategies through rounds of generation, reflection, and curation."
- Best-of-N sampling: Generating multiple candidate solutions and choosing the highest-scoring one according to a reward model. "Best-of-N sampling with reward models~\citep{cobbe2021training,lightman2023let} uses outcome or process reward models to select the highest-scoring solution from multiple candidates."
- Chain-of-Thought: A reasoning paradigm where models produce explicit, step-by-step explanations to solve problems. "\citet{aghajohari2025markovian} addresses the challenge of ever-growing Chain-of-Thought by proposing Markovian thinking, which decouples thinking length from context size by maintaining constant-size states across reasoning chunks."
- Contrastive analysis: Comparing strong and weak solutions to extract actionable insights about why certain reasoning paths succeed or fail. "We address this by distilling actionable insights from contrastive analysis to improve exploration quality, while self-verification enables effective selection without trained reward models."
- Cumulative Best: The best accuracy achievable across all rounds if an oracle could pick the best solution post hoc each time. "we report accuracy (accuracy of the selected solution of each round), Cumulative Best (best accuracy achievable with oracle across all rounds) and pass@k (pass rate with accumulated rollouts at round )."
- Cumulative regret: A metric in reinforcement learning that sums the performance shortfall over time compared to the optimal policy. "\citet{qu2025mrt} formalizes test-time compute optimization as a meta-RL problem, showing that optimizing cumulative regret yields 2-3 relative gains over outcome-reward RL."
- Execution-Based Self-Verification: Selecting code solutions by generating and executing tests to empirically validate correctness. "Code Generation: Execution-Based Self-Verification."
- In-context policy adaptation: Adjusting a model’s behavior within the current context window across episodes without changing weights. "\citet{jiang2025lamer} demonstrate that cross-episode training induces exploration through in-context policy adaptation."
- Inverse-entropy voting: A selection method that weighs answers inversely to their entropy, favoring more confident predictions. "recent work on the Sequential Edge~\citep{sharma2025sequential} suggests that inverse-entropy voting in a sequential setting can outperform parallel self-consistency at matched compute."
- LiveCodeBench: A benchmark suite for evaluating executable code generation and competitive programming tasks. "We evaluate on 203 hard problems from LiveCodeBench v6~\cite{jain2024livecodebench}."
- Lookahead and backtracking: Search techniques that explore future steps and revert to earlier states to improve solution quality. "Tree of Thoughts~\citep{yao2023tree} extends chain-of-thought for deliberate exploration over coherent units of text with lookahead and backtracking."
- Majority voting: Aggregating multiple answers by choosing the most frequent one among diverse reasoning chains. "Self-consistency~\citep{wang2022self} samples diverse reasoning chains and selects answers through majority voting."
- Markovian thinking: A reasoning approach maintaining constant-size states across chunks to decouple thinking length from context size. "\citet{aghajohari2025markovian} addresses the challenge of ever-growing Chain-of-Thought by proposing Markovian thinking, which decouples thinking length from context size by maintaining constant-size states across reasoning chunks."
- MatryoshkaThinking: A recursive test-time scaling strategy that enables efficient reasoning through nested refinement. "MatryoshkaThinking~\citep{chen2025matryoshkathinking} employs recursive test-time scaling to enable efficient reasoning."
- Meta-RL: Meta-reinforcement learning; training agents to learn how to learn, balancing exploration and exploitation across tasks. "Meta-RL teaches agents to rapidly adapt to new tasks by balancing exploration and exploitation across episodes~\citep{duan2016rl,wang2016learning}."
- Mutual exclusivity: A property of certain problems where exactly one answer is correct, enabling stronger verification signals. "we exploit the property of mutual exclusivity."
- Oracle: A hypothetical selector that can always choose the best-performing candidate among those generated. "Cumulative Best (best accuracy achievable with oracle across all rounds)"
- Outcome-reward RL: Reinforcement learning that optimizes rewards based on final outcomes rather than intermediate processes. "optimizing cumulative regret yields 2-3 relative gains over outcome-reward RL."
- Parallel Thinking: A baseline that generates multiple independent reasoning traces and aggregates them. "The rolling majority vote (Majority@Prev) shows monotonic improvement, outperforming the Parallel Thinking baseline (Majority@64)."
- pass@k: The probability that at least one of k generated candidates passes the evaluation or tests. "we report accuracy (accuracy of the selected solution of each round), Cumulative Best (best accuracy achievable with oracle across all rounds) and pass@k (pass rate with accumulated rollouts at round )."
- Population (RSA): The number of candidate solutions maintained and refined per iteration in recursive aggregation methods. "we compare Test-time Recursive Thinking with 2 rollouts per round over 8 rounds against RSA with population 2 with 8 iterations."
- Process reward models: Reward models that score reasoning processes (intermediate steps) rather than just final outcomes. "uses outcome or process reward models to select the highest-scoring solution from multiple candidates."
- Recursive Self-Aggregation (RSA): A method that iteratively refines populations of candidate reasoning chains by aggregating subsets’ outputs. "Recursive self-aggregation (RSA) iteratively refines populations of candidate reasoning chains by aggregating subsets~\cite{venkatraman2025rsa}"
- Rolling majority vote: Aggregating answers across rounds by taking the majority among previous selections, enabling monotonic improvements. "The rolling majority vote (Majority@Prev) shows monotonic improvement, outperforming the Parallel Thinking baseline (Majority@64)."
- Self-consistency: Sampling multiple diverse reasoning chains and selecting an answer via aggregation to improve reliability. "Self-consistency~\citep{wang2022self} samples diverse reasoning chains and selects answers through majority voting."
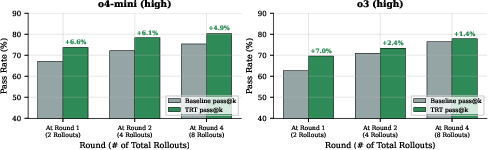
- Self-generated test execution: Using model-created tests to execute and rank code solutions without external feedback. "Self-generated test execution reduces the selection gap significantly (from 11.8\% to 4.9\% for o4-mini, 16.3\% to 3.5\% for o3)."
- Self-Refine: An approach where models iteratively generate feedback on their own outputs and refine them. "Self-Refine~\citep{madaan2023selfrefine} demonstrates that LLMs can iteratively generate feedback on their own outputs and refine accordingly, with 20\% improvements across diverse tasks."
- Sequential Edge: A setting or approach highlighting the advantage of sequential methods over parallel ones in aggregation strategies. "recent work on the Sequential Edge~\citep{sharma2025sequential} suggests that inverse-entropy voting in a sequential setting can outperform parallel self-consistency at matched compute."
- Selection gap: The performance difference between the best solution achievable across rounds and the solution actually selected each round. "Self-generated test execution reduces the selection gap significantly (from 11.8\% to 4.9\% for o4-mini, 16.3\% to 3.5\% for o3)."
- SoftTFIDF: A similarity measure that combines TF-IDF weighting with token similarity, used to analyze strategy text changes. "We analyze how models adapt their strategies across rounds using SoftTFIDF~\cite{cohen2003comparison} on the per-rollout strategy text to measure strategy similarity between consecutive rounds."
- Test execution: Running generated code against tests to validate correctness during selection. "TRT accuracy over 8 rounds with test execution on LiveCodeBench v6 hard problems, compared to RSA with 8 rounds."
- Test-time compute optimization: Allocating and optimizing computational effort during inference to improve performance. "\citet{qu2025mrt} formalizes test-time compute optimization as a meta-RL problem, showing that optimizing cumulative regret yields 2-3 relative gains over outcome-reward RL."
- Test-time Recursive Thinking (TRT): An iterative self-improvement framework that generates, selects, and reflects on rollouts without external feedback. "We formalize this framework as Test-time Recursive Thinking (TRT)."
- Tree of Thoughts: A structured search method over reasoning steps with lookahead and backtracking to improve solution quality. "Tree of Thoughts~\citep{yao2023tree} extends chain-of-thought for deliberate exploration over coherent units of text with lookahead and backtracking."
- Verbal reinforcement learning: Guiding agents via verbal feedback and maintaining reflective text to improve subsequent trials. "Reflexion~\citep{shinn2023reflexion} introduces verbal reinforcement learning, where agents reflect on task feedback and maintain reflective text in episodic memory to improve subsequent trials."
- Verifiable rewards: Rewards that can be checked against ground-truth or deterministic validators during reinforcement learning. "reinforcement learning (RL) with verifiable rewards"
Collections
Sign up for free to add this paper to one or more collections.

