- The paper introduces a novel evolutionary framework (EvoTD) that combines skill-based seeding, complexity mutation, and skill crossover to enhance LLM reasoning.
- The paper demonstrates significant performance improvements across benchmarks, with gains of 8.2% on AIME 24 and robust cross-domain generalization.
- The paper highlights curriculum evolution benefits, ensuring diversity and scalability in task synthesis to drive advanced reasoning frontiers.
Evolutionary Task Discovery: Structured Skill-Complexity Evolution for Advanced LLM Reasoning
Motivation and Problem Definition
The Evolutionary Task Discovery (EvoTD) framework addresses a fundamental bottleneck in LLM reasoning enhancement: the lack of scalable, diverse, and systematically complexified training data. Prevailing post-training paradigms such as Reinforcement Learning from Verifiable Rewards (RLVR) exhibit performance limitations due to static and homogeneous corpora—typically curated or web-scraped question-answer pairs—which constrain the exploration of algorithmic difficulty and skill transfer. Existing LLM training synthesis methods (e.g., Evol-Instruct, self-play frameworks), reliant on unstructured mutations or superficial diversity metrics, frequently suffer from mode collapse or semantic redundancy, neglecting both compositional logical coverage and systematic scaling of complexity.
EvoTD formalizes data synthesis as directed search over a structured abstraction space spanned by two orthogonal axes: Algorithmic Skills (semantic logic backbone) and Complexity Attributes (parameteric structural constraints). This enables principled curriculum construction, targeting both breadth (skill composition, combinatorial novelty) and depth (difficulty scaling, robustness) of reasoning challenges.
EvoTD Framework: Abstraction and Evolutionary Operators
EvoTD organizes reasoning tasks on a dual-axis manifold, with S denoting the set of algorithmic skills and C denoting complexity attributes. The framework operationalizes task evolution through three key evolutionary steps:
- Skill-based Seeding: Initial task samples are generated by explicitly conditioning synthesis on individual skills, maximizing initial semantic coverage and avoiding mode collapse.
- Complexity Attribute Mutation: Mutations intensify structural attributes (e.g., input size, recursion depth, branching factor) while preserving core logical skills. The mutation operator leverages LLM metacognition to verify attribute applicability and compositional integrity, systematically generating harder variants that expand the solver's reasoning robustness.
- Skill Crossover: Tasks are synthesized via combinatorial logic composition, integrating synergistic sets of skills that yield genuinely interconnected challenge instances. Crossover search is regularized to prevent degenerate sequential concatenations and ensures deep structural interdependence.
The evolutionary proposal cycle is governed by a multi-objective fitness protocol, filtering each synthesized task by executability, skill alignment, and learnability (dynamic zone of proximal development assessment). This guarantees pedagogical value, computational validity, and adaptive curriculum progression as solver capabilities mature.
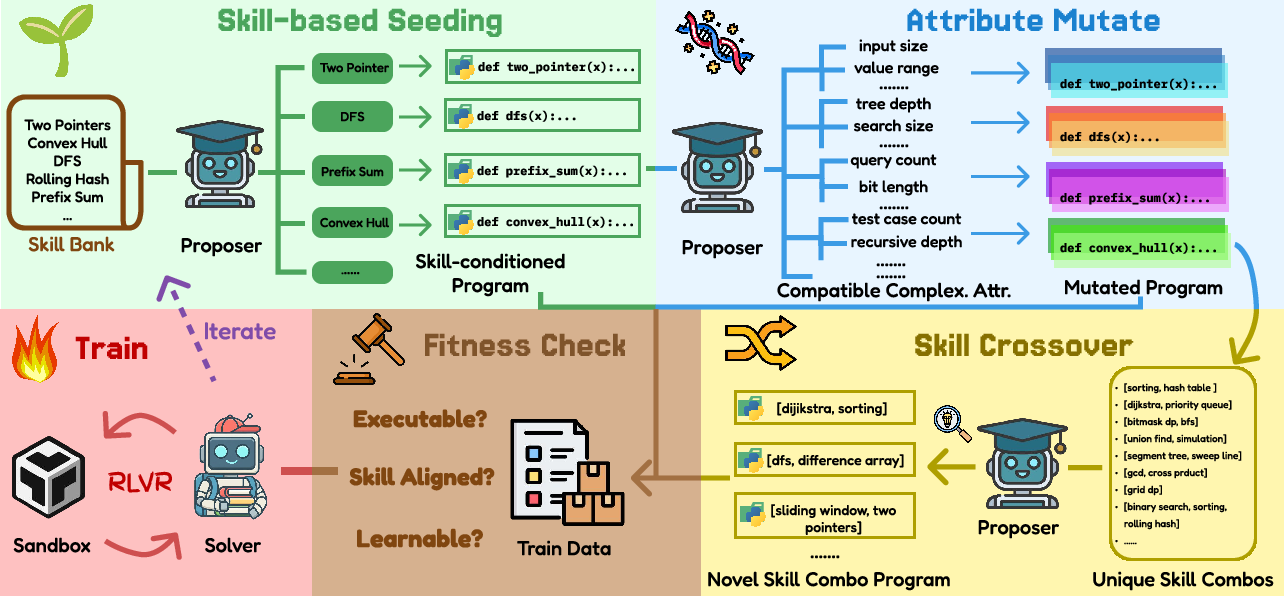
Figure 1: EvoTD procedural flow integrating skill seeding, complexity mutation, skill crossover, fitness verification, and solver training.
EvoTD was evaluated across five rigorous benchmarks, comprising code generation (LiveCodeBench v6, MBPP+), mathematical reasoning (AIME 24/25, OlympiadBench), and general-domain reasoning (MMLU-Pro, SuperGPQA). Results demonstrate:
- Superior Reasoning Gains: On the Qwen3-4B reasoning backbone, EvoTD achieves +8.2% improvement on AIME 24 and +7.2% on AIME 25 relative to baselines, with consistent gains in both Pass@1 and Pass@8 metrics. These improvements are most pronounced on the hardest subsets, confirming the impact of complexity scaling.
- Cross-Domain Robustness: Performance lifts span in-domain coding (+5.7%) and out-of-domain mathematics (+6.4%), substantiating the transfer effect from skill-based semantic curriculum construction.
- Homogeneity Collapse Avoidance: Unlike distillation paradigms that inflate single-sample metrics and degrade multi-sample learning, EvoTD maintains strong diversity—yielding monotonic scaling in both Pass@1 and Pass@8 over multiple iterations.
- Combinatorial Novelty and Skill Coverage: EvoTD achieves substantially higher unique skill combination ratios than heuristic baselines, aligns its synthesized distribution closer to uniform skill entropy, and extends combinatorial reasoning frontiers (Figure 2).
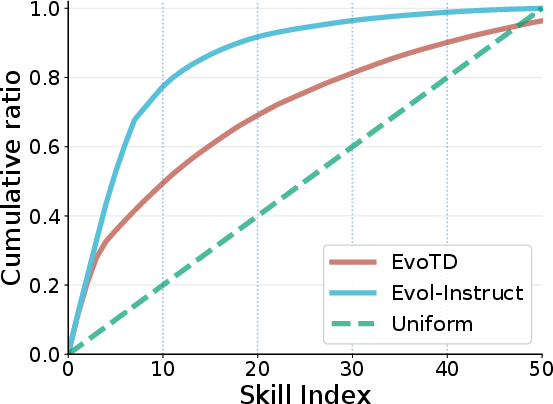
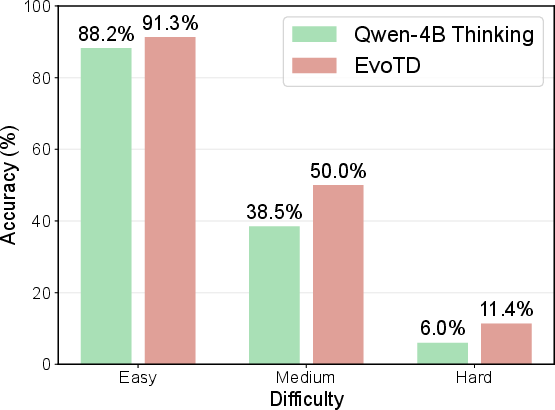
Figure 2: (a) Skill frequency cumulative distribution showing near-uniform coverage; (b) detailed performance breakdown on LiveCodeBench v6.
- Baseline Comparison: EvoTD outperforms resource-intensive self-evolving baselines (SPIRAL, Agent0) on every backbone, demonstrating advantages in both sample efficiency and generalization across architectural, regime, and parameter scale axes.
- Operator Ablation: Removal of Attribute Mutation degrades math reasoning (-2.1%), especially on competitive benchmarks. Skill Crossover ablation reduces generalization, confirming the necessity of both operators for frontier expansion.
Mechanisms of Curriculum Expansion
Skill Uniformity: Skill-based seeding regularizes semantic diversity, preventing curriculum collapse into dominant reasoning patterns.
Attribute Mutation: Complexity scaling induces difficulty modulation, producing training distributions with lower solver success rates and driving adaptation towards scale-invariant logic.
Crossover Synergy: Multi-skill synthesis yields deeply interconnected problems, validated through LLM-as-a-judge fidelity audits, with >90% of generated crossover tasks exhibiting genuine algorithmic interdependence.
Zone of Proximal Development: Learnability filtering calibrates difficulty in real-time, ensuring that task distribution tracks solver capability and enables continual curriculum advancement.
Implications and Future Directions
The EvoTD framework reframes LLM self-improvement from black-box heuristic mutation to transparent, evolutionarily structured data synthesis. The paradigm decouples logical primitives from instance complexity, supporting scalable curriculum evolution that is pedagogically effective, empirically robust, and interpretable. Practical implications include:
- Efficient Reasoning Scaling: EvoTD enables base model scaling without the computational overhead of multi-agent self-play or tool augmentation. Sample efficiency is substantiated by higher valid sample yield per candidate (36% accept rate vs 63% for heuristics).
- Domain-Agnostic Curriculum Synthesis: Skill-bank extraction and complexity attribute identification are LLM-driven and transferrable across domains, facilitating adaptation to new reasoning tasks and environments.
- Generalization and Transfer: Gains transfer robustly to STEM-adjacent fields, confirming that abstract logical primitives are foundational for broad multi-disciplinary reasoning.
Future developments will focus on dynamic skill-bank expansion, open-ended taxonomy discovery, and adaptation of the framework to domains lacking programmatic verifiers (e.g., argumentation, multi-modal tasks), potentially leveraging learned reward models or LLM-as-judge protocols.
Conclusion
EvoTD demonstrates that structured evolutionary search over skill-complexity manifolds is a practical and effective approach for enhancing LLM reasoning. Attribute Mutation and Skill Crossover are necessary and complementary for constructing diverse, progressively challenging curricula that drive frontier expansion. The empirical results support the conclusion that structural evolution yields substantially superior training signals compared to unconstrained heuristic generation, with broad generalization and efficiency benefits.

