- The paper presents an evolutionary search over executable RL update rules via LLM-guided macro mutations and crossovers, bypassing canonical methods.
- It employs GPT-5.2 and Claude 4.5 as generative operators, yielding novel algorithms like CG-FPD and DF-CWP-CP that outperform traditional baselines on benchmark tasks.
- Ablation studies reveal that moderate Levenshtein regularization improves structural diversity and convergence, highlighting a trade-off between peak performance and training stability.
Evolutionary Discovery of Reinforcement Learning Algorithms via LLMs
Problem Statement and Motivation
The paper "Evolutionary Discovery of Reinforcement Learning Algorithms via LLMs" (2603.28416) confronts a central challenge in reinforcement learning (RL): the lack of automated methods for discovering novel learning update rules. Whereas neural architecture search, hyperparameter tuning, and reward function discovery have been substantially automated, the update rule — the core logic by which agents learn from experience — has traditionally been hand-designed. Differentiable meta-learning approaches and evolutionary strategies applied to structured loss expressions still operate in restrictive spaces, unable to generate fundamentally novel update rules constituting executable training code. The primary obstacle is the discrete, brittle, and highly implementation-sensitive nature of programmatic RL update logic: naive mutations often yield invalid or dysfunctional algorithms that cannot be assessed via gradient-based optimization or local search.
Methodological Framework
The proposed approach formulates RL algorithm discovery as an evolutionary optimization over the space of executable update rules, where each candidate represents a distinct, complete training procedure.
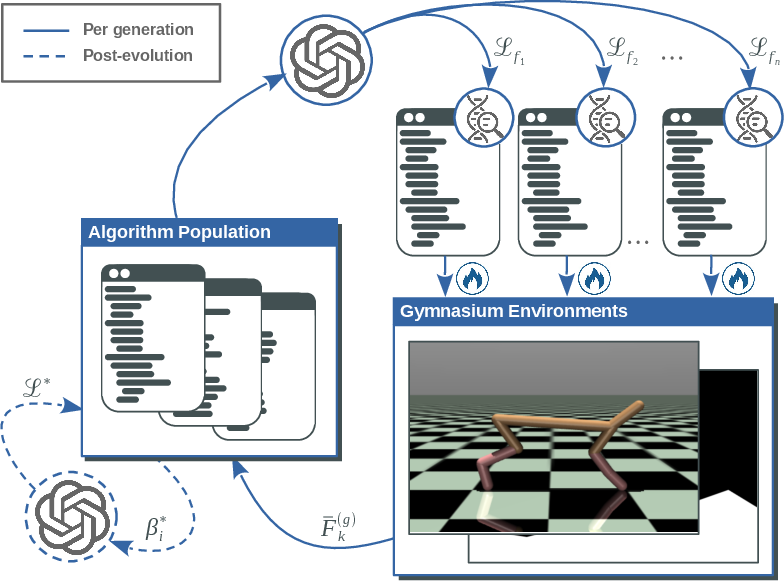
Figure 1: Iterative population-based evolution of RL algorithms guided by LLMs, with selection based on end-to-end performance and LLM-driven hyperparameter refinement.
Each generation comprises a diverse population of candidate update rules, instantiated as Python code, which are subjected to LLM-guided macro-mutation and diversity-aware crossover. Standard canonical mechanisms—actor-critic decomposition, temporal-difference losses, value bootstrapping—are explicitly forbidden in the generation process to promote structural novelty. Every new candidate is validated by fully training the corresponding algorithm across a suite of Gymnasium benchmarks, with mean normalized task returns serving as scalar fitness. To address the acute hyperparameter sensitivity intrinsic to RL update rules, a post-evolution hyperparameter optimization stage is conducted via LLMs, which propose bounded, context-aware parameter ranges for each evolved rule.
Macro mutation enables semantically coherent, large-scale rewrites of algorithmic building blocks, leveraging LLMs trained on code to produce consistent, executable variations. Crossover is regulated by a Levenshtein distance penalty between parent code, balancing fitness and structural diversity; this regularization is crucial for maintaining search-space coverage and avoiding collapse via trivial recombinations.
Experimental Setup
Evolutionary search is executed using both GPT-5.2 and Claude 4.5 Opus as generative operators. Two independent random seeds per model yield populations evolved for 10 generations on CartPole-v1, MountainCar-v0, Acrobot-v1, LunarLander-v3, and HalfCheetah-v5—spanning discrete/continuous action spaces and sparse/dense rewards.
Each candidate update rule is evaluated through exhaustive full-environment training across five random seeds, with fitness defined as the mean normalized maximum episodic return over environments and seeds. The highest-fitness update rules are further refined using LLM-driven hyperparameter sweeps. The final evaluation is performed on the union of training and unseen test environments, with identical policy architectures and optimizers across all baselines (PPO, SAC, DQN, A2C) and discovered algorithms, ensuring strict attribution of performance differences to update rule design.






Figure 2: Diverse Gymnasium environments used for training and validation span both discrete and continuous control regimes.
Results and Analysis
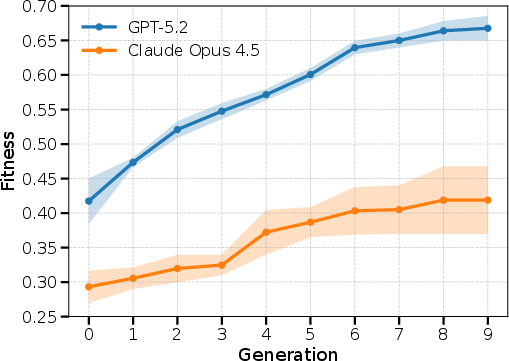
Figure 3: Monotonic improvement of maximum population fitness per generation, with GPT-5.2 yielding strong convergence and higher final fitness than Claude 4.5 Opus.
Both LLMs facilitate monotonic fitness improvement across generations; however, GPT-5.2 consistently discovers update rules exhibiting substantially higher aggregate fitness ([0.65,0.69]) compared to Claude 4.5 Opus.
The two top-performing, non-canonical algorithms, selected from independent GPT-5.2 runs, are:
- Confidence-Guided Forward Policy Distillation (CG-FPD): A model-based algorithm using short-horizon latent planning as a teacher signal for policy distillation, eschewing value functions and gradients.
- Differentiable Forward Confidence-Weighted Planning with Controllability Prior (DF-CWP-CP): An algorithm leveraging differentiable world-model rollouts, confidence-weighted desirability objectives, and controllability-augmented learning signals independent of Bellman updates or value estimation.
Post-refinement, both algorithms attain competitive or superior seed-averaged returns to baselines on multiple tasks (e.g., CG-FPD achieves −105.8±10.5 on MountainCar-v0, outperforming PPO/A2C/DQN; DF-CWP-CP attains 260.6±19.1 on LunarLander-v3, surpassing all baselines). In several cases, the algorithms match the deterministic solvability of PPO on CartPole and InvertedPendulum and outperform on Swimmer.
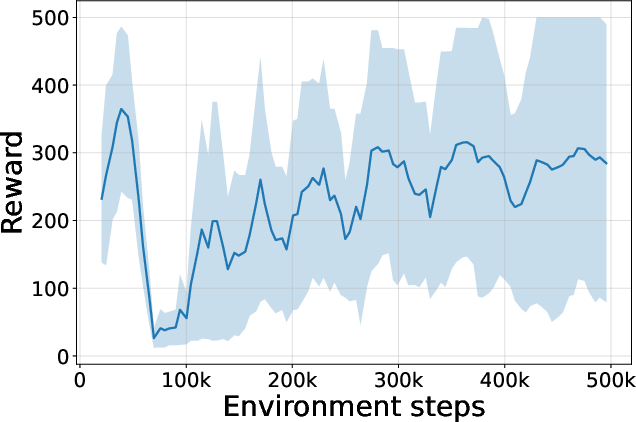
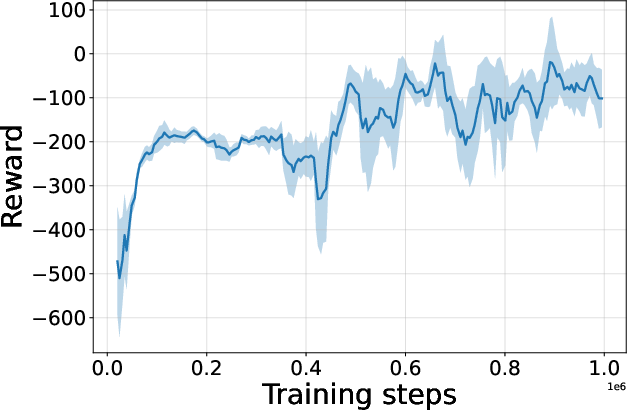
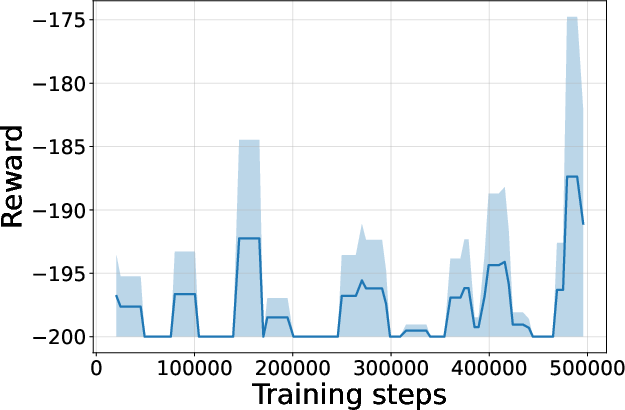
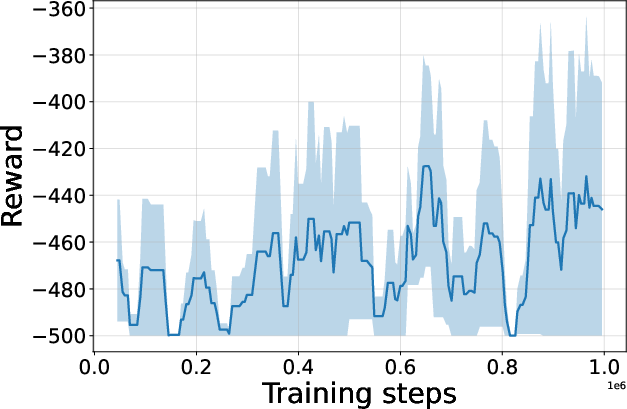
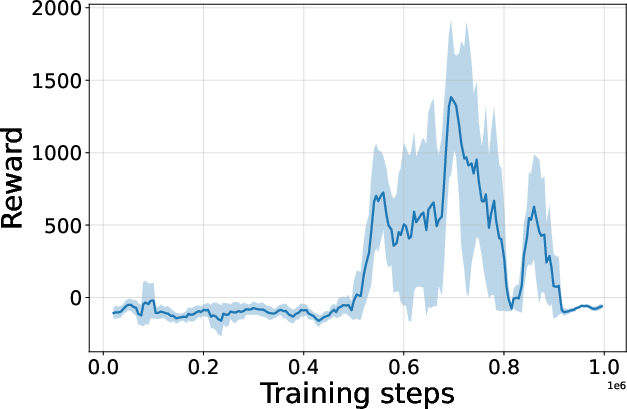
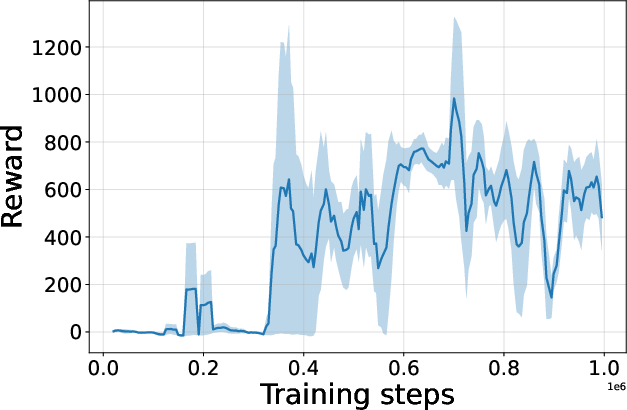
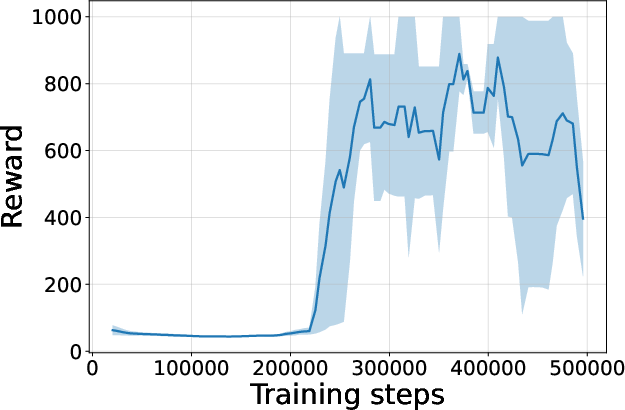
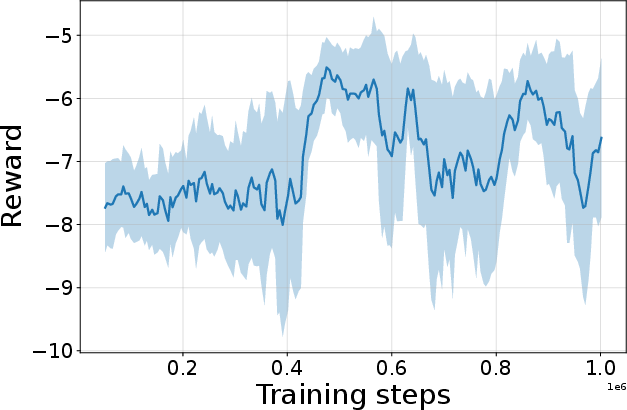
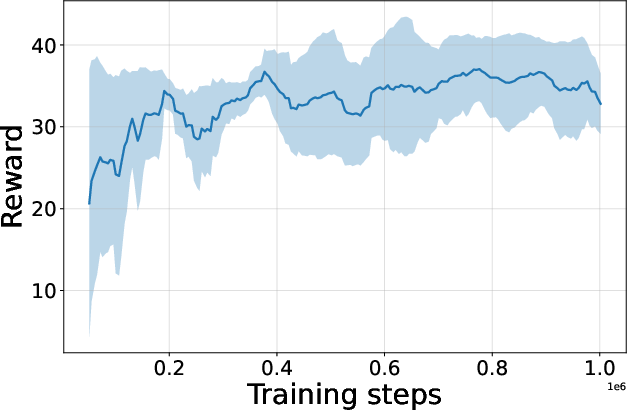
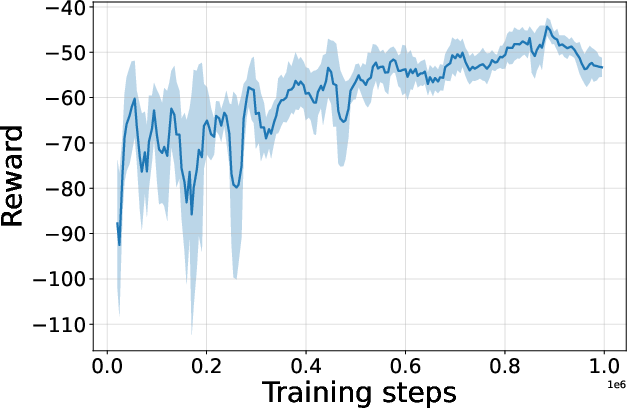
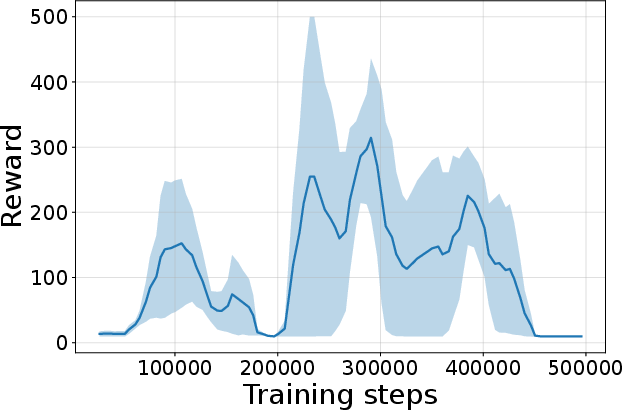
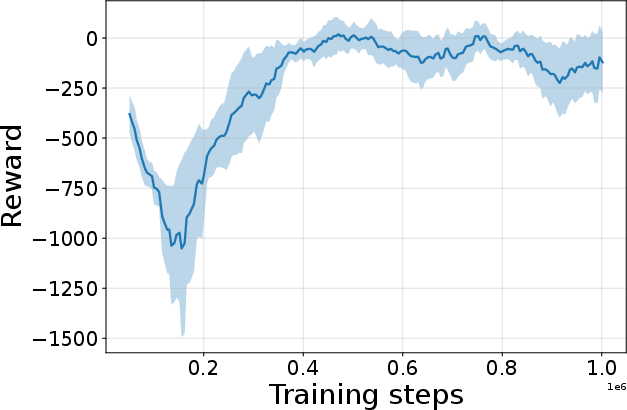
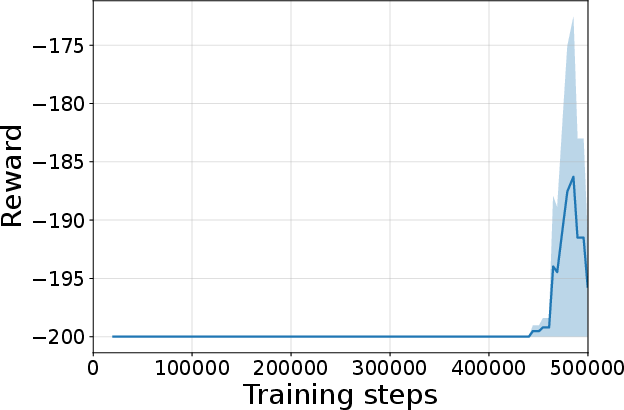
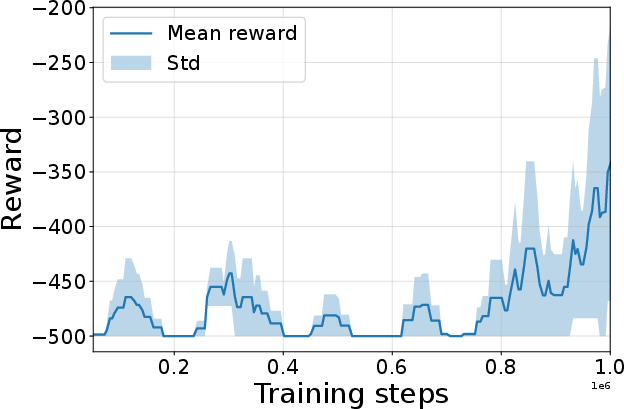
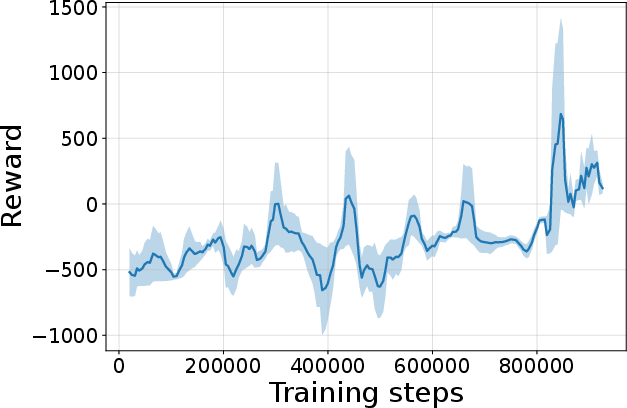
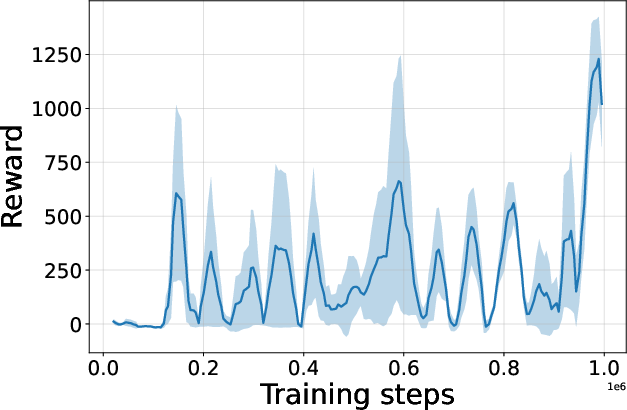
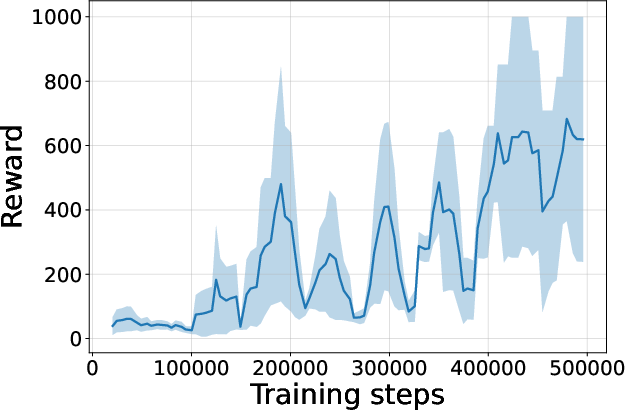
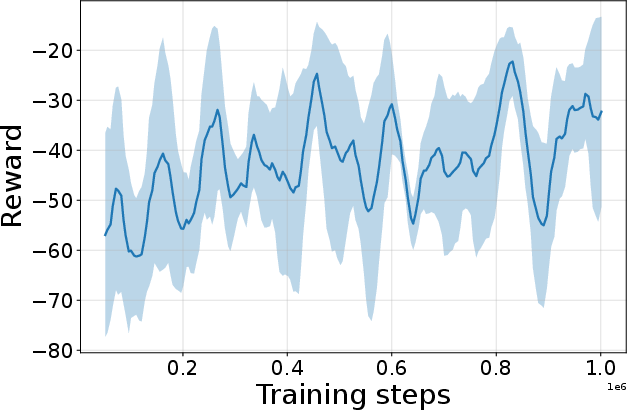
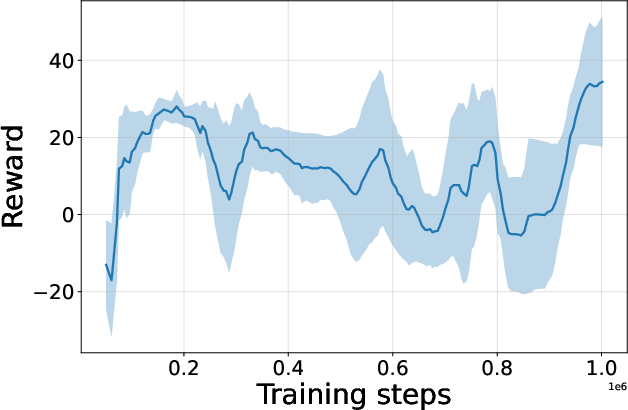
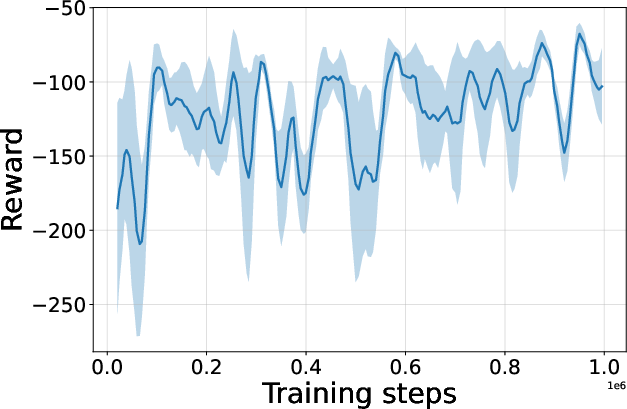
Figure 4: Seed-averaged evaluation learning curves for CG-FPD and DF-CWP-CP demonstrating high peak performance and trajectory variability across ten environments.
Despite high peak performance, evolved algorithms often present greater instability during training compared to regularized baselines, demonstrating a trade-off between maximality and robustness intrinsic to non-canonical update rules.
Ablation and Algorithmic Implications
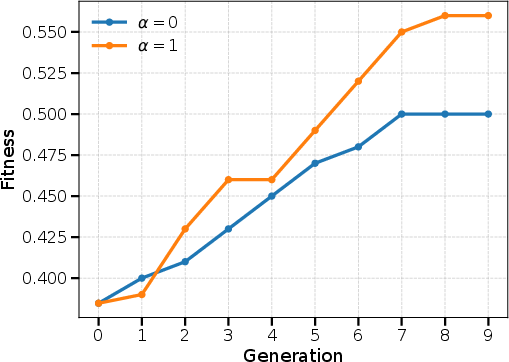
Figure 5: Impact of Levenshtein regularization (α) in crossover; moderate α yields the best balance between convergence and population diversity.
Ablation experiments highlight the necessity of regularization in crossover: intermediate similarity weights yield highest efficacy, confirming that structural diversity is vital in an unconstrained program search space. Further, introducing terminal value bootstrapping regularizes CG-FPD and reduces variance, but universally depresses peak performance—a notable empirical finding indicating that value-estimate-based regularization can trade off stability for optimality, even outside classical actor-critic algorithms.
Practical and Theoretical Implications
This research demonstrates that high-capacity LLMs can serve as effective generative operators over the space of programmatic RL learning rules, enabling evolutionary search for update rules rather than secondary system components. The deliberate preclusion of canonical mechanisms, coupled with LLM-guided code synthesis, leads to the emergence of algorithms with structures and learning signals that differ fundamentally from policy-gradient, Q-learning, and imitation paradigms. The resultant policy behaviors and learning dynamics indicate that task-level competency does not uniquely depend on value-based bootstrapping or gradient estimation, raising new questions on the sufficiency and necessity of standard RL machinery.
On the practical side, this approach is computationally intensive, as each candidate algorithm must be validated by full-scale training. However, it establishes a viable foundation for future, more scalable frameworks. As LLMs improve in generative and reasoning capabilities, and surrogate fitness models are developed, one can anticipate the evolution of even more sophisticated, task-adaptive algorithms with emergent, interpretable mechanisms. Combining this approach with flexible recombination of canonical and synthesized modules could catalyze a paradigm shift in data-driven RL algorithm engineering.
Conclusion
The paper substantiates the feasibility of closed-loop, LLM-driven evolutionary search over executable RL update rules, resulting in original algorithms that are competitive with state-of-the-art baselines without recourse to traditional value function estimation or policy gradients. This work elevates RL algorithm discovery to the programmatic level, facilitating empirical investigation of the landscape beyond well-trodden policy and value update formulas. While presently resource-limited, the method exposes powerful new avenues for AI systems capable of self-organizing learning logic calibrated directly for embodied task performance, setting a research trajectory with profound implications for automated ML and reinforcement learning theory.