- The paper presents the ERO framework that leverages evolutionary algorithms and layer-wise covariance to enhance System 2 reasoning in LLMs.
- It demonstrates that an evolved Qwen-7B model outperforms larger models like GPT-5 on ARC benchmarks with improved pass@1 scores.
- The study challenges traditional scaling laws by showing that targeted evolutionary adaptations, rather than increased model size, yield significant gains in reasoning performance.
Evolutionary System 2 Reasoning in LLMs: Analysis of the ERO Framework
LLMs have demonstrated utility across a multitude of domains; however, current empirical evidence consistently reveals their pronounced incapacity for System 2 reasoning—deliberate, compositional, and logical cognitive processing. Leading models such as GPT-5 display substantial limitations on benchmarks such as the Abstraction and Reasoning Corpus (ARC), where even top-tier models saturate well below human performance (50% vs. 100%). Central to this gap is the divergence between human intelligence, shaped by open-ended evolution enforcing survival-of-the-fittest pressures, and LLMs, which are confined by fixed, task-specific pretraining regimens.
The paper advances the hypothesis that, by leveraging evolutionary algorithms reminiscent of neuroevolution, LLM parameters can be adaptively optimized under selective pressure to explicitly maximize reasoning performance. The principal research question is thus: Can a competitive evolutionary strategy on LLM populations confer emergent System 2 reasoning, and under what operational constraints does this become tractable?

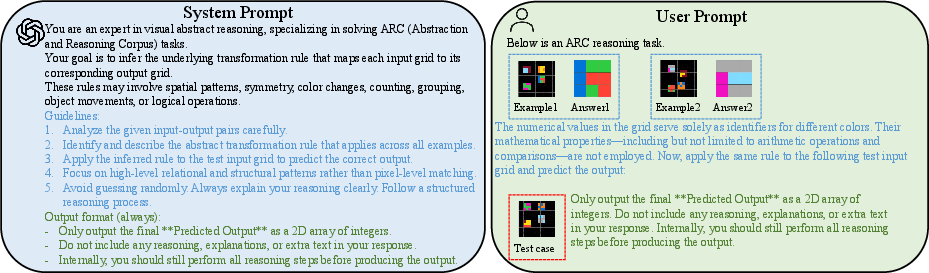
Figure 1: A prototypical ARC reasoning task that targets compositional system-level inference, forming the basis of evaluation for System 2 capability.
The Evolutionary Reasoning Optimization (ERO) Framework
The Evolutionary Reasoning Optimization (ERO) framework adapts multipopulation evolutionary strategies for LLM reasoning enhancement. LLM parameters constitute the genotype; reasoning tasks correspond to the selective environment. The workflow is characterized by the following technical constructs:
Empirical Results
Experiments focus primarily on 15 sampled tasks from ARC, explicitly chosen to span innate core knowledge domains (object cohesion, persistence, number, geometry, etc.) per cognitive-science-congruent categorization. The principal model under evolution is Qwen-7B; comparisons are made to both larger (Qwen-32B, GPT-4o) and state-of-the-art (GPT-5) LLMs.
- Performance Trajectories: ERO systematically amplifies the reasoning performance of initially weak models. Across generations, mean pass@1 scores for the evolved Qwen-7B model surpass those of considerably larger and more heavily trained (pretrained and RLHF-refined) competitors.
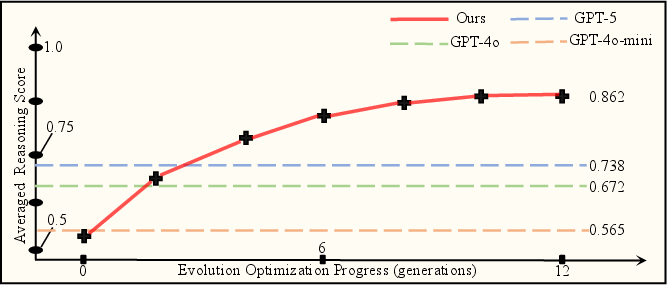
Figure 3: Evolution curves tracking per-generation average ARC pass@1, benchmarking ERO-evolved Qwen-7B against baseline SOTA models.
- Task-Wise Comparison: In 8/15 tasks, the ERO-optimized Qwen-7B outperforms GPT-5. The efficacy is observable in instances tapping varied cognitive priors, demonstrating the optimization’s generalization across logic, arithmetic, and visuospatial domains rather than overfitting to isolated benchmark idiosyncrasies.
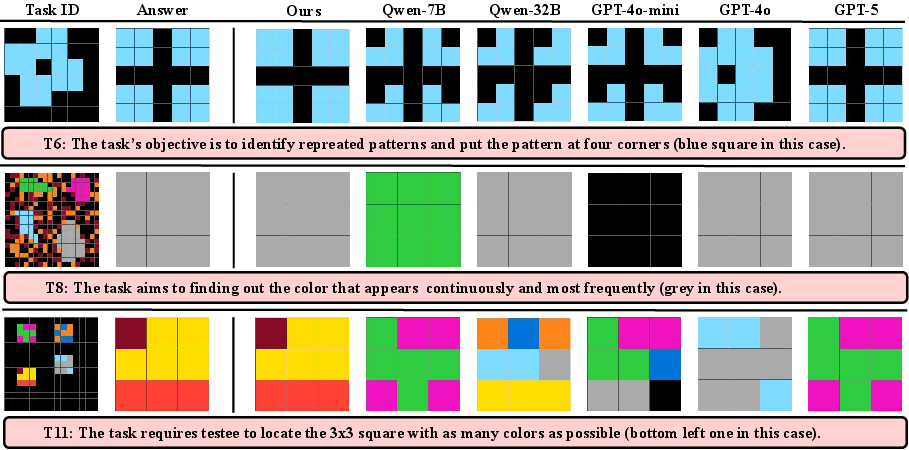
Figure 4: Qualitative showcases, highlighting before-and-after reasoning trajectories for select ARC instances where ERO confers emergent compositional reasoning.
- Scaling Law Contradiction: Results strongly challenge the scaling hypothesis for reasoning ability. Larger models (Qwen-32B, GPT-5) do not universally surpass their smaller counterparts. Instead, post-hoc mutation and selection—instead of model size expansion—yield superior gains, indicating that System 2 reasoning is not linearly correlated with parameter count or corpus breadth.
Implications and Theoretical Considerations
ERO’s core finding is the empirical decoupling of model scale and reasoning performance, instead showing that evolutionary selective pressures can unlock latent compositional abilities within existing model architectures. This reframes the debate on LLM improvement, extending optimization beyond pretraining and instruction tuning into domains of black-box, objective-driven parameter search.
Practically, this translates to feasible post-training enhancement pipelines that are compatible with limited hardware; the evolutionary loop, cache optimization, and parallelism afford tractable exploration of the massive LLM parameter space. Theoretically, ERO introduces a new axis for research on machine intelligence: meta-evolution over reasoning task distributions rather than per-task adaptation, gesturing toward continual, open-ended adaptation reminiscent of human evolution.
Future research directions include scaling ERO to meta-optimization—averaging reasoning scores over a manifold of diverse reasoning environments—which would better capture the generalization sought in general intelligence studies and systematically address the compositionality bottleneck prevailing in current LLMs.
Conclusion
This work operationalizes evolutionary principles for LLM reasoning enhancement, establishing that substantial gains in System 2 reasoning can be achieved by survival-driven optimization in the parameter space, rather than expanding corpus or model size. ERO offers a pragmatic and theoretically sound framework, with clear evidence that evolutionary computation bridges the gap between connectionist architectures and the adaptive, selective processes underpinning human intelligence. These insights motivate the integration of evolutionary dynamics into future LLM design for robust, compositional reasoning.