- The paper demonstrates that fine-grained task selection and micro mixing yield significant performance gains, with up to a 42.9% improvement on reasoning benchmarks.
- The study reveals that synthetic data interventions provide little benefit compared to the high-quality, carefully curated instruction-tuning data.
- Empirical results indicate robust generalization, as SuperNova-trained models outperform baselines across diverse reasoning tasks and out-of-distribution benchmarks.
SuperNova: Data Curation Framework for General Reasoning in LLMs with RLVR
Motivation and Background
LLMs have demonstrated significant advances in reasoning for formal domains, particularly mathematics and code, largely enabled by Reinforcement Learning with Verifiable Rewards (RLVR). However, their general reasoning capabilities—including causal inference, pragmatic logic, and temporal understanding—remain underdeveloped. The primary constraint is the lack of high-quality, verifiable data spanning these broader reasoning skills. Previous approaches attempting to extend RLVR with web-sourced or synthetic datasets are hampered by noise, verification difficulties, and domain specificity, resulting in limited transfer to truly general reasoning tasks. SuperNova proposes a systematic data curation framework leveraging high-quality instruction-tuning resources (e.g., SuperNI, FLAN) to bridge this gap.
SuperNova Framework: Components and Approach
SuperNova is structured as a multi-stage curation pipeline, targeting RLVR-based reasoning improvement in LLMs:
- Task Selection: Candidate tasks from instruction-tuning datasets are reformatted into verifiable formats amenable to RLVR, e.g., multiple-choice questions. Task utility is empirically measured by downstream impact on complex reasoning benchmarks (specifically BBEH), revealing substantial variance—even degradation—from certain tasks. Fine-grained, controlled RL experiments show that multi-hop reasoning tasks produce the largest gains.
- Task Mixing: SuperNova evaluates macro vs. micro mixing. Macro mixing aggregates top tasks based on overall utility, while micro mixing selects top tasks unique to each benchmark sub-task. Micro mixing outperforms macro mixing consistently, demonstrating that coverage across reasoning sub-skills is better preserved by targeted selection.
- Data Interventions: Various synthetic augmentations, including increased context, compositional difficulty, and prior violation, are applied to the best mixture. None provide improvement over the base, underscoring that augmenting already curated data is non-trivial and can degrade verifiability and quality.

Figure 1: The SuperNova framework systematically curates reasoning data from natural instructions, analyzes task selection and mixing strategies, and investigates synthetic intervention efficacy.
Experimental Findings
Impact of Task Selection
Empirical evaluation demonstrates a 7.6 percentage point (pp) gap between best- and worst-performing tasks on BBEH-mini, with some tasks degrading baseline performance. The most effective categories include multi-hop reasoning and coreference resolution, but individual task-level analysis is essential due to category-level noise.
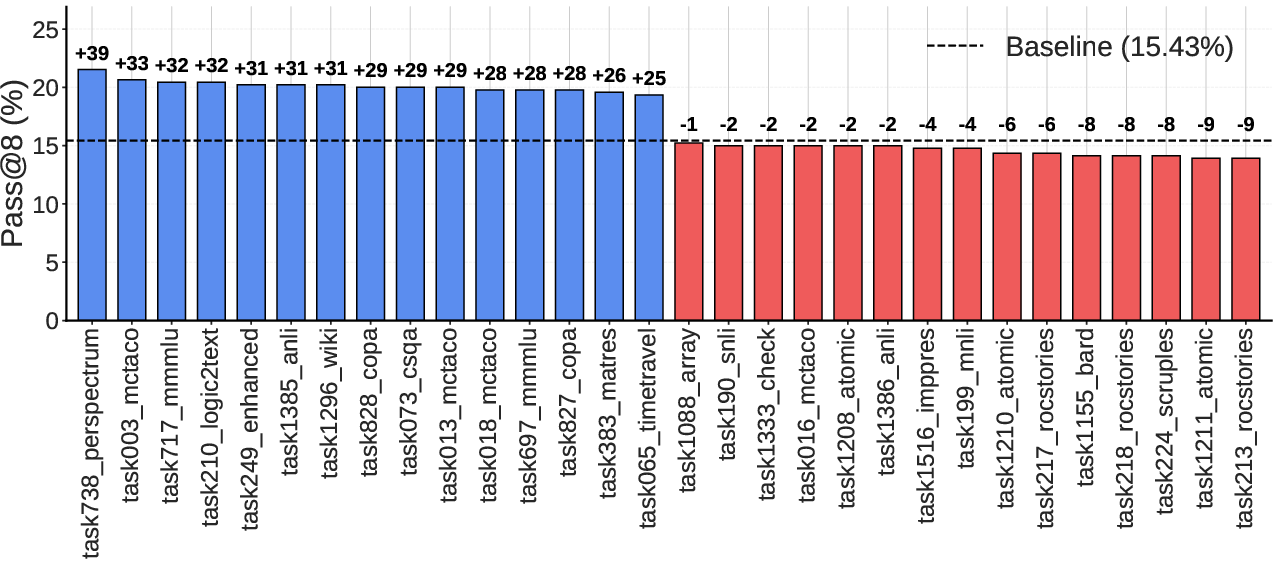
Figure 2: Task selection has substantial downstream impact on general reasoning; only a subset of tasks substantially improve performance.
Task Mixing Strategy
Micro mixing achieves a pass@8 of 22.8%, outperforming macro mixing across aggregation depths. Marginal gains plateau as more tasks are added, illustrating a diversity-quality trade-off.
Synthetic Data Interventions
Augmentations such as going against prior and long-context do not improve performance beyond the best curated mixture, confirming the difficulty of synthetic improvements once data verifiability and task relevance are optimized.
Comparative and Scaling Results
SuperNova-trained models (Qwen3, LLaMA3 families, sizes 0.6B through 4B) consistently outperform strong baselines (Qwen3-8B, General-Reasoner-4B, Olmo-3-7B-Think). SuperNova-4B achieves a relative gain of 42.9% (pass@8) on BBEH-test, and outperforms Qwen3-8B by 8.2pp. The gains persist and scale with increased values of k up to 128, indicating improved exploration and broader solution diversity.
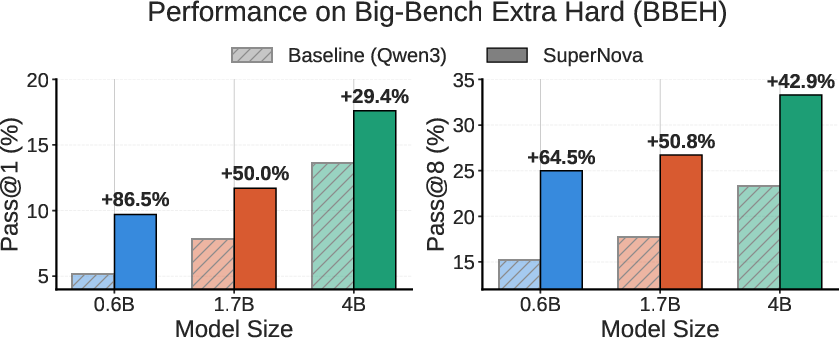
Figure 3: Training with SuperNova data yields consistent pass@k improvements across model sizes and k values.
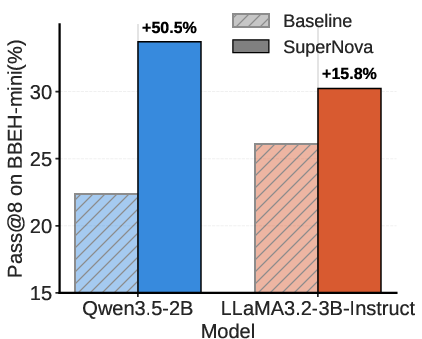
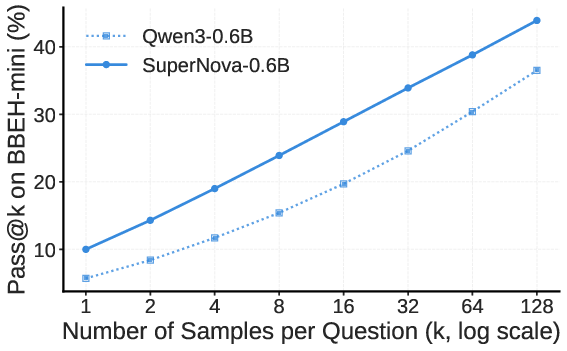
Figure 4: SuperNova-trained models consistently outperform baselines across both Qwen and LLaMA families; gains persist as k increases.
SuperNova achieves robust generalization to out-of-distribution benchmarks (BBH, MMLU-Pro, Zebralogic, MATH500), with up to 21pp improvement on logical reasoning (Zebralogic), and maintains competitive performance on math-oriented datasets.
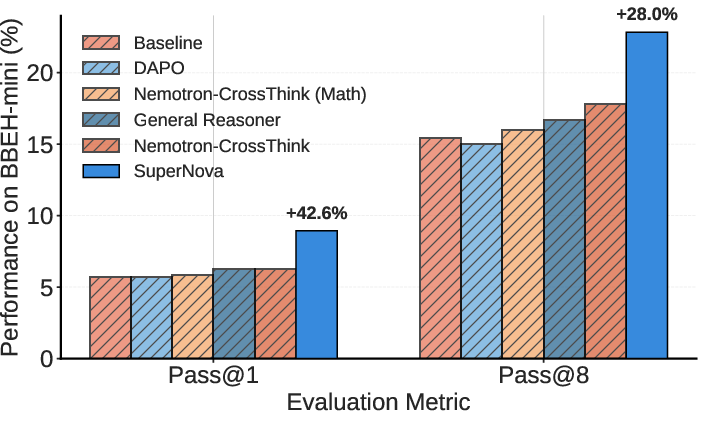
Figure 5: On BBEH-mini, SuperNova outperforms all existing reasoning datasets by substantial margins in pass@1 and pass@8.
Theoretical and Practical Implications
SuperNova's methodology demonstrates that principled, fine-grained data curation leveraging instruction-tuning datasets enables RLVR to elicit broad general reasoning in LLMs, even at smaller model scales. Strong numerical results show that task selection and mixing mechanisms are critical; surface-level task similarity, domain expansion, and synthetic augmentations offer minimal utility. This work provides practical guidance for RLVR-based training in general reasoning, shifting focus from quantity and domain coverage to quality and utility of training tasks.
On the theoretical front, the study isolates factors underlying reasoning generalization, revealing non-transferability between STEM reasoning (math/code) and general reasoning benchmarks. The results suggest that fine-grained skill representation within instruction datasets is key for effective RLVR in broader reasoning.
Speculation on Future Directions
SuperNova points toward data-centric development in general reasoner LLMs, particularly for applications requiring causal, pragmatic, and temporal inference. Further expansion may include more granular sub-task analysis, dynamic task selection during RLVR training, and exploration under unbounded compute/data regimes. Additionally, leveraging real-world problem-solving or domain-specific general reasoning benchmarks beyond academic sets could validate and extend these curation insights.
Methodologically, future work could investigate automated task utility ranking, iterative task selection, or construction of synthetic verifiable samples rooted in instruction-task structures.
Conclusion
SuperNova presents an empirically rigorous and methodologically explicit data curation pipeline for RLVR-based training of general reasoning in LLMs, demonstrating strong gains over existing baselines and scaling behaviors. Fine-grained task selection and mixing are critical to successful reasoning enhancement, and synthetic interventions remain difficult to leverage. The framework provides actionable insights and theoretical grounding for future RLVR training in broad reasoning skills, supporting further practical and theoretical advances in LLMs for real-world problem-solving applications.

