- The paper introduces a co-evolutionary verification framework that enables LLM-based agents to self-evolve multi-component skill packages using binary pass/fail signals.
- The proposed method achieves a 71.1% pass rate on SkillsBench, outperforming human-curated skills by +17.6 percentage points and significantly surpassing naive baselines.
- Iterative evolution with a surrogate verifier yields portable skills that consistently improve performance across models and in 9 out of 11 domains.
EvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Introduction and Motivation
EvoSkills introduces a co-evolutionary verification framework for autonomous skill evolution in LLM-based agents, targeting the synthesis and refinement of structured, multi-file skill packages beyond atomic tool invocation. The work is motivated by the empirical weaknesses exposed by SkillsBench: manual, human-authored skills are both label-intensive and, crucially, subject to human--machine cognitive misalignment, with human-designed procedural guidance often degrading LLM agent performance in some domains. EvoSkills directly addresses the self-evolution of executable skills, incorporating both a Skill Generator and a Surrogate Verifier under constrained feedback, where only pass/fail signals from ground-truth oracles are observable. This approach avoids reliance on human supervision or ground-truth diagnostic signals, avoiding information leakage and improving practical agent autonomy.
Co-Evolutionary Verification Framework
The central mechanism of EvoSkills is tightly coupled co-evolution between two information-isolated LLMs: the Skill Generator, responsible for generating and refining skill bundles for a given task, and the Surrogate Verifier, which generates and iteratively escalates test cases and structured error diagnostics on observed outputs from the generator. Only when the surrogate suite is passed does an opaque ground-truth oracle signal (binary pass/fail) trigger further escalation or skill acceptance.
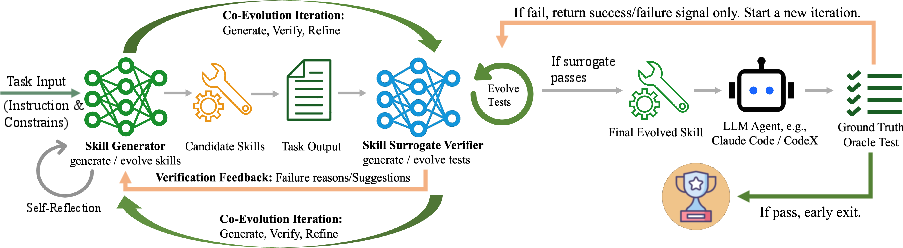
Figure 1: Overview of the EvoSkills co-evolutionary framework: the skill generator and surrogate verifier iteratively refine skills via structured diagnostic feedback, with only oracle pass/fail signals enforcing information isolation.
The task formalism adheres to a partially observable MDP where the agent never observes the hidden test set, necessitating indirect optimization via the surrogate. Skill refinement proceeds via actionable failure feedback from the surrogate, with no access to test content. When surrogate tests are insufficiently discriminative (i.e., generator passes surrogate but fails oracle), the verifier escalates the test set based on observable artifacts, never the skill logic.
Skill Structure and Optimization Objective
Skills are defined as structured, multi-component packages composed of scripts, workflow documentation, and task-specific references. The optimization objective is to maximize the expected ground-truth reward on task execution when conditioning the policy on a candidate skill. The intractable nature of optimizing against an opaque oracle is addressed by maximizing proxy surrogate test performance, with the policy and test suite co-evolving under strict information barriers.
The tight alternation—skill refinement under a fixed surrogate suite, followed by verification suite escalation upon detected surrogate-oracle discrepancies—ensures the solution does not overfit to surrogate signals but rather traverses the space of skills discoverable by the agent's own situated trial and error.
Experimental Results and Analysis
Skill Quality and Baseline Comparison
EvoSkills achieves a 71.1% pass rate on SkillsBench (Claude Opus 4.6 + Claude-Code), exceeding the no-skill baseline by +40.5 percentage points and surpassing human-curated skills by +17.6pp. All tested self-generation baselines, including chain-of-thought guided prompting and Anthropic's official skill-creator, offer negligible gains, demonstrating the insufficiency of simple self-generation or one-pass prompts. The advantage of EvoSkills arises from iterative, feedback-driven evolution, not the static prompt.
Evolution Dynamics
The pass rate trajectory over evolution rounds reveals rapid improvement once verification commences: starting on par with the no-skill baseline, surpassing human-curated skill performance after three refinement iterations, and converging by the fifth round. The mean per-task cost for convergence is 4.1 verification cycles, with 2.4 ground-truth oracle interventions, highlighting practicality in computational requirements.
Cross-Model Transferability
A striking result is observed in cross-model transfer. Skills evolved by Claude Opus 4.6, when installed on six additional LLM backbones spanning five independent providers, produce substantial performance gains (+36 to +44pp over no-skill baselines), confirming the generality of evolved skills. Notably, skills encode reusable structural priors, not model-specific artifacts.
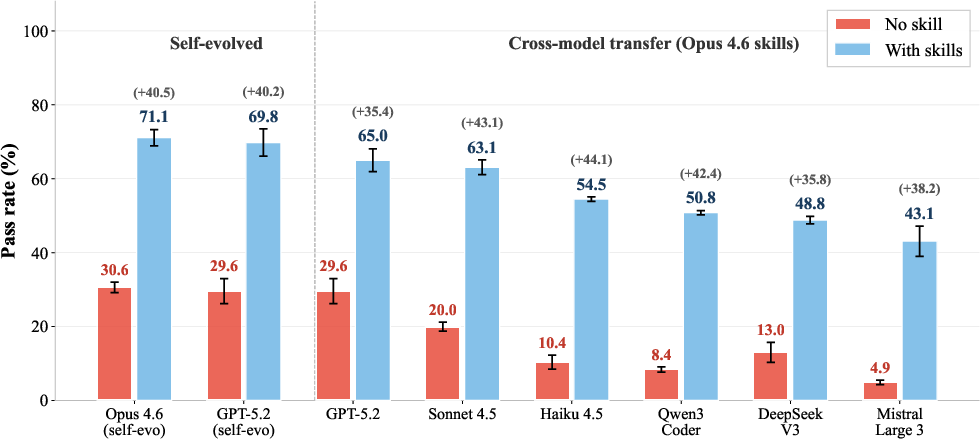
Figure 2: Opus-evolved skills generalize across six additional LLMs, yielding large absolute performance improvements in all cases.
The self-evolved skills on matched backbones still outperform those transferred, indicating that local adaptation offers modestly higher returns but is not strictly necessary for strong task transfer.
Per-Domain Analysis and Human--Machine Misalignment
Domain-decomposed results show self-evolved skills outperform human-curated skills in 9 out of 11 domains, with the largest margins in domains where human procedures either fail to provide structure or directly impede LLM reasoning (e.g., Natural Science, Finance). In some domains, human curation actively harms performance—a direct signal of misalignment between human-crafted workflows and agent-cognitive structure.
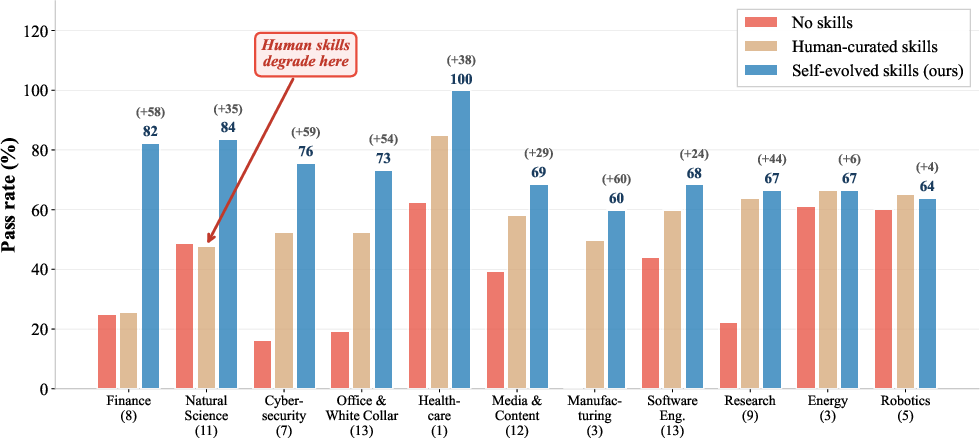
Figure 3: Domain-level breakdown showing self-evolved skills systematically outperform or rescue agent performance in domains where human-curated skills degrade task completion.
These observations underscore a key theoretical insight: autonomous, model-centric evolution bridges the inductive gap between the agent's native reasoning modes and the structured procedural scaffolding needed for complex tasks, which cannot be robustly engineered by static, human-written documentation.
Iteration Analysis & Interpretability
Further breakdown of iteration cost shows that failed tasks cluster at higher cycles, yet most cases achieve convergence well within the allotted budget, balancing diagnostic coverage against computational feasibility. The verification cycles absorb a substantial part of the burden, as only the hardest cases escalate to repeated oracle interrogation.
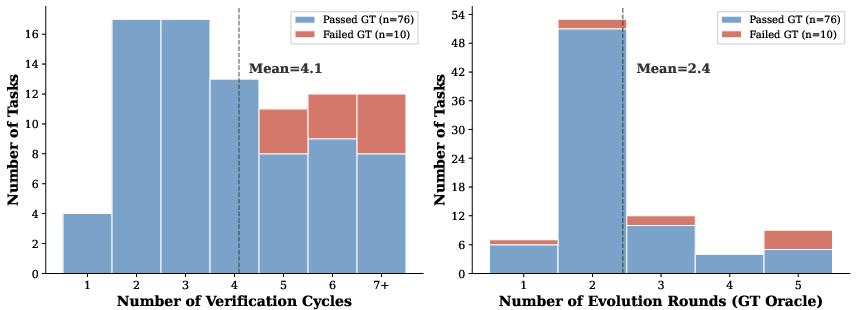
Figure 4: Tasks requiring many verification and oracle rounds are more likely to remain unsolved, indicating correlation between search depth and inherent task complexity.
Heatmap analysis of per-task condition performance reveals that self-evolved skills frequently recover tasks unsolved by naive or human-curated baselines, further evidencing the expressivity advantage of feedback-driven evolution.
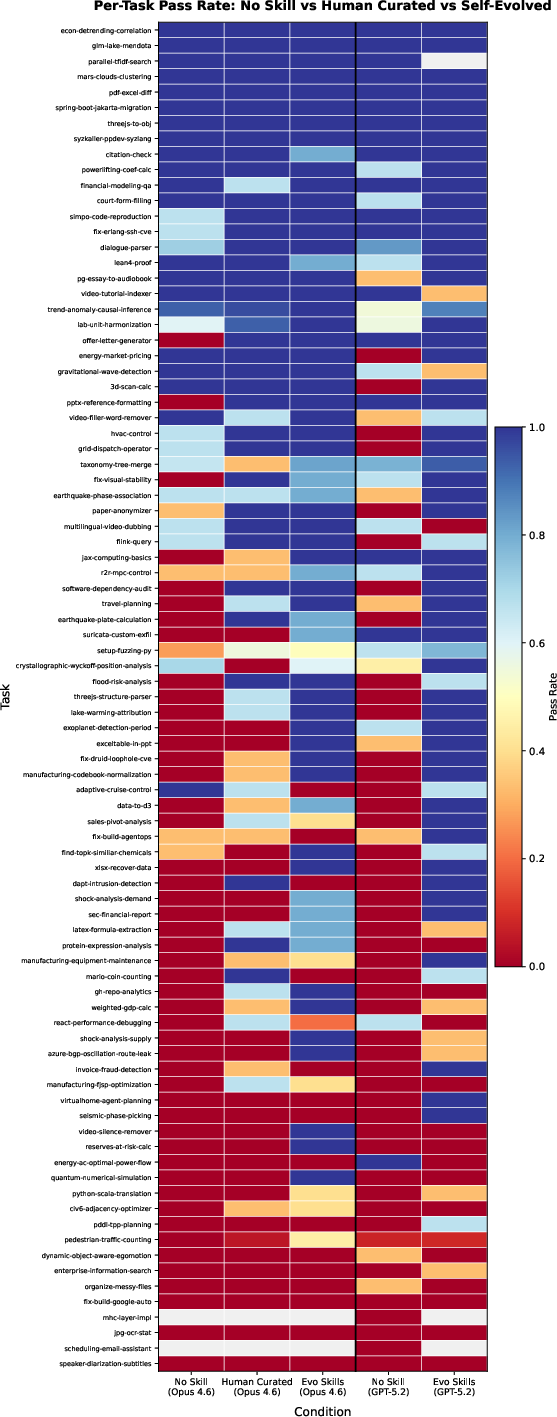
Figure 5: Evolved skills solve long-tail tasks missed by all static baselines, as indicated by the darker regions in the heatmap for difficult task rows.
Implications and Future Directions
This work shows that LLM agents equipped with co-evolutionary verification can autonomously discover and refine highly portable, richly structured skills, achieving task completions that both saturate and surpass the feasible benefit of human procedural writing. The absence of reliance on test content or human supervision makes the approach scalable to scenarios with limited supervision.
Practically, EvoSkills offers a blueprint for continual agent improvement in dynamic environments, where hidden evaluation criteria and evolving task distributions dominate. Theoretically, it suggests a sharp distinction between model-generated and human-curated cognitive priors, requiring architectures that can reconcile these differences via agent-driven meta-learning.
Looking forward, EvoSkills can be extended toward multi-model and multi-agent settings, where skill packages may be evolved jointly across heterogeneous models, or specialized for agent collectives solving distributed workflows. Further, abstraction of skills into modular, hierarchical libraries can promote knowledge reuse and composition at broader scales.
Conclusion
EvoSkills decisively demonstrates that co-evolutionary agent-driven skill self-generation not only strictly outperforms both naive self-generation and human-crafted curation but also produces skill artifacts with strong cross-model generality and domain robustness. The results highlight the limitations of direct human procedural abstraction and motivate further research in model-aligned, autonomous skill synthesis under opaque supervision constraints.

