- The paper introduces a dual-route task synthesis pipeline that combines persona-driven and skill-grounded approaches to generate a 13.5K instance dataset.
- The framework leverages black-box rollouts, supervised fine-tuning, and reinforcement learning with reward thresholding to achieve significant performance gains.
- The ClawGym-Bench and detailed agent behavior analysis validate the framework's efficacy in bridging performance gaps in environment-grounded tasks.
ClawGym: A Comprehensive Scalable Framework for Environment-Grounded Agent Development
Motivation and Context
Claw-style agent environments—epitomized by platforms like OpenClaw—demand autonomous agents capable of executing non-trivial, multi-step workflows over local files, orchestrating diverse tools, and persistently updating workspace state. This setting poses unique challenges: absence of systematic large-scale, verifiable training datasets; lack of diagnostic evaluation resources; and limitations in current agent training and evaluation paradigms. Prior benchmarks and datasets are insufficient, as they either focus on static reasoning, lack executable context, or fail to scale across diverse operational and persona requirements (2604.26904).
Framework Overview and Design
ClawGym proposes a data-centric, end-to-end pipeline integrating scalable task synthesis (ClawGym-SynData), agent training (ClawGym-Agents), and rigorous evaluation (ClawGym-Bench).
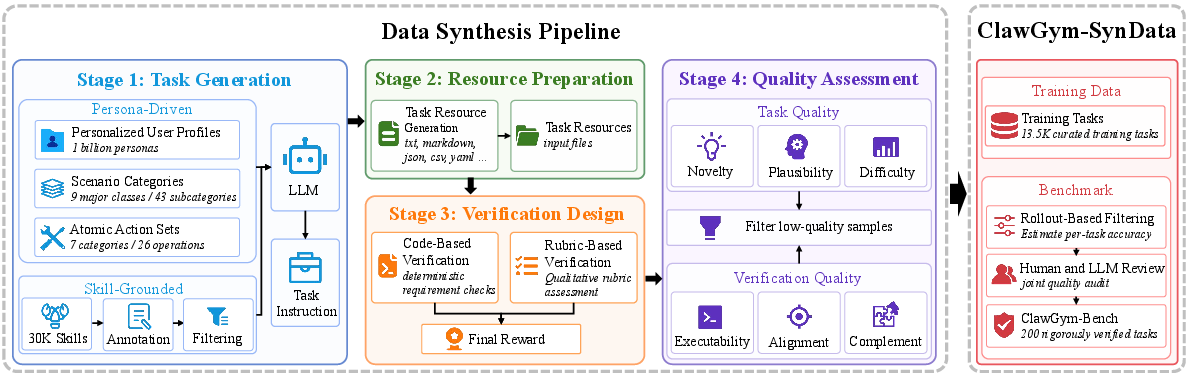
Figure 1: Overview of the ClawGym-SynData pipeline, which generates tasks from persona-driven and skill-grounded sources, prepares task resources, designs hybrid verification, filters samples through quality assessment, and constructs training and benchmark data.
Task Synthesis
The framework introduces a dual-route pipeline for synthesizing Claw-style tasks:
- Persona-driven top-down synthesis: Tasks are generated based on sampled user personas and scenario taxonomies, allowing diverse, realistic, and contextually grounded agent instructions.
- Skill-grounded bottom-up synthesis: Atomic operations and high-level skills are extracted and filtered from the OpenClaw skill registry, subsequently composed into multi-step, executable workflows.
The pipeline automatically generates mock workspace resources, ensuring each task's initial state is reproducible and executable. Hybrid code-based and rubric-based verification schemas support both deterministic and qualitative evaluation, fostering the synthesis of tasks that are simultaneously diverse and rigorously verifiable.
Automated Assessment and Data Quality
A comprehensive quality assurance protocol discards redundant, implausible, and low-difficulty tasks via embedding similarity checks, LLM-based plausibility and difficulty assessments, and code/rubric verifier validation. Extensive human and LLM-assisted reviews further enhance the data fidelity. The final training dataset, ClawGym-SynData, comprises 13.5K instances.
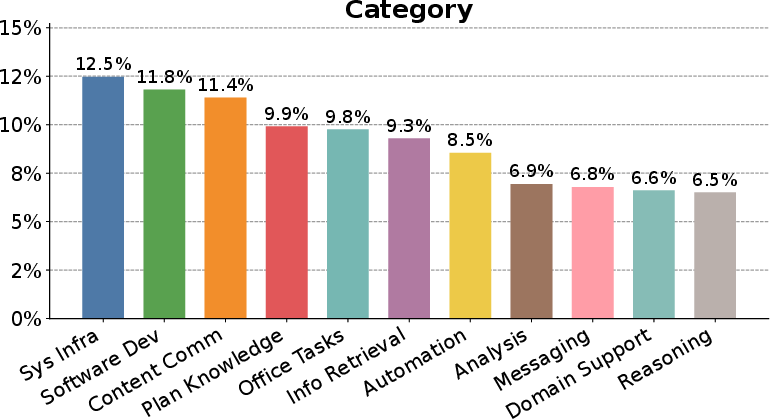
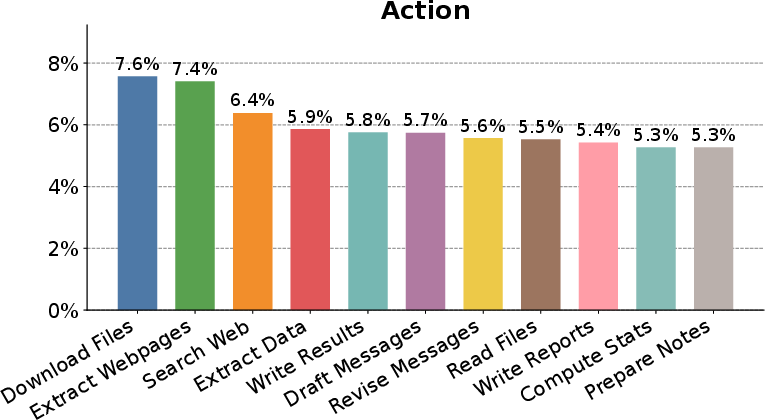
Figure 2: Scenario category distribution for persona-driven synthesis, evidencing coverage across a broad task spectrum.
Agent Training Paradigm
Trajectory Collection via Black-Box Rollout
Training leverages authentic OpenClaw execution via black-box rollouts across distributed Dockerized sandboxes, preserving full agent-environment interaction fidelity. Trajectories are collected using strong teacher models (MiniMax-M2.5, GLM-5.1), and are aggregated, deduplicated, and filtered based on hybrid verification scores. The resulting 24.5K high-fidelity multi-turn trajectories yield non-trivial, diverse agent traces with rich tool use and deliberation patterns.
Supervised Fine-Tuning and RL
ClawGym-Agents are produced via multi-turn SFT on the Qwen3-series architectures. A reward-thresholding criterion (optimal at 0.5) balances completion fidelity and coverage/diversity. Extra-long context extensions (e.g., YaRN for 64K tokens) enable the models to learn coherent long-horizon strategies and workspace manipulations. Masking of execution-produced tokens during training prevents spurious imitation of deterministic feedback.
Additionally, a lightweight RL pipeline is realized via per-task sandbox parallelism and outcome-reward-only policy optimization with GRPO, directly employing verifier scores. RL further boosts performance atop both vanilla and fine-tuned SFT backbones.
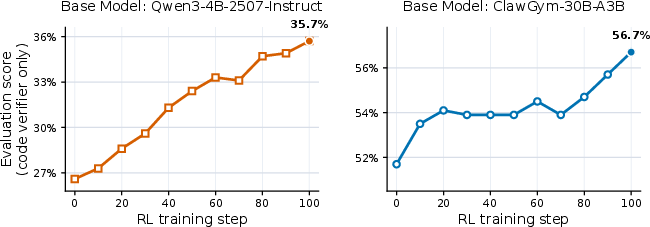
Figure 3: RL training curves on ClawGym-Bench, using code-based verifiers only.
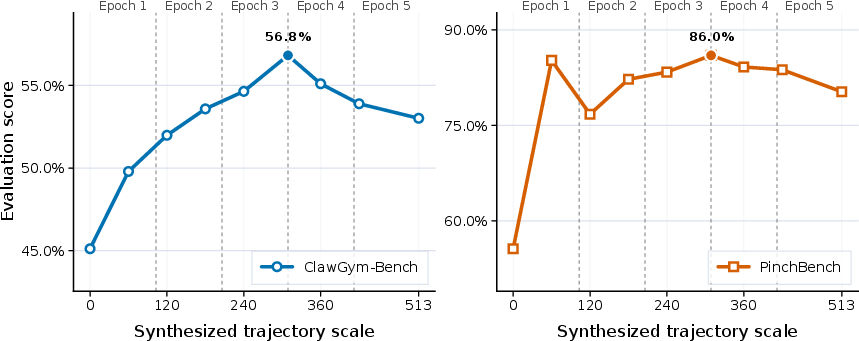
Figure 4: Effect of training trajectory scale on SFT model performance—demonstrating substantial gains at moderate scales, and overfitting with excessive epochs.
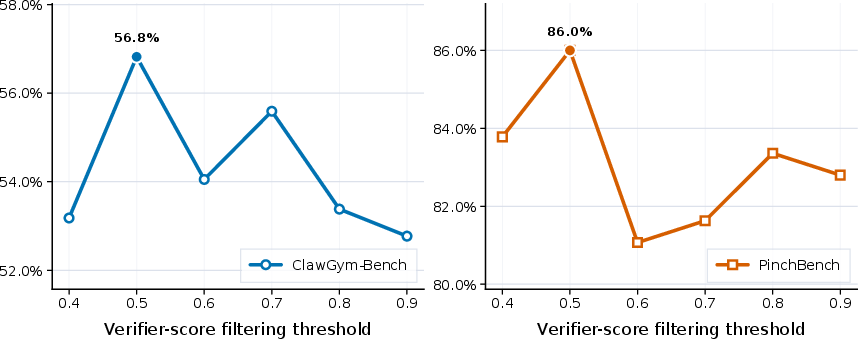
Figure 5: Effect of reward thresholding in trajectory filtering on SFT performance; a threshold of 0.5 delivers the best trade-off.
ClawGym-Bench is constructed through multi-stage filtering from the synthesized data, enforcing elevated requirements on task solvability, verification precision, and category balance. Difficulty-aware rollout calibration (via strong and weak agents) and LLM-assisted human review ensure each of the 200 tasks is both discriminative and achievable. The benchmark spans six competency areas (e.g., productivity, automation, analysis, planning, software engineering), with 22% of samples requiring hybrid code/rubric evaluation.
- Evaluation harnesses, strict resource initializations, and robust verifiers ensure low-variance scoring—standard deviation <1% under repeated runs.
- Solvability is empirically validated through strong-agent completions and reference solutions, supporting reliable diagnosis of agent capabilities.
Experimental Results and Numerical Highlights
- Performance Gains: SFT on ClawGym-SynData yields marked improvements for compact models, outperforming larger non-specialized models (e.g., ClawGym-30A3B exceeds Qwen3-235B-A23B on both ClawGym-Bench and PinchBench).
- Qwen3-8B: +43.46% on ClawGym-Bench; +38.90% on PinchBench.
- Qwen3-30B-A3B: +25.96% on ClawGym-Bench; +54.68% on PinchBench.
- Ablation: Mixed persona-driven and skill-grounded synthesis outperforms either approach alone, confirming the necessity of dual-route task coverage.
- Data Scaling: Moderate training exposure maximizes robustness, while excessive epochs yield marginal overfitting.
- Reward Thresholding: Filtering at a reward threshold of 0.5 efficiently trades off trajectory quality and diversity; thresholds too lax or too strict degrade downstream performance.
Behavioral and Capability Analysis
Detailed cross-model behavioral analyses reveal key observations:
- Tool Use: High-performing agents structure tool usage in robust pipelines (e.g., discovery → inspection → aggregation), recovering from execution errors coherently. Weaker agents exhibit brittle or invalid tool sequencing even after recovery.
- Long-Horizon Robustness: Strong models reason through multi-step errors and achieve idempotent completions; weaker models accrue unresolved failures, often stalling at error bottlenecks.
- Fine-Grained Instruction Compliance: Strong models systematically enforce all conditional requirements (e.g., filters, aggregation logic) in outputs. Weaker models produce plausible artifacts superficially, but with subtle rule violations that propagate through downstream results.
- Across model scales, failure modes stratify by level: smaller models make basic tool/instruction errors; mid-sized models lack workflow reliability; strong models mainly fail in completion precision and consistency.
Theoretical and Practical Implications
ClawGym demonstrates that systematic synthetic data generation, grounded in both user scenarios and operational skills with hybrid verification, can substantially bridge model performance gaps in practical, environment-grounded workflows. The approach validates the scalability and transferability of such data-centric pipelines, with compact models achieving or exceeding the capabilities of considerably larger backbones in specialized contexts. The effective use of hybrid, multi-route reward and assessment strategies sets a new bar for agent training and evaluation methodologies. The integration of RL with parallel sandboxing further suggests viable routes to scalable agent improvement.
Practically, the release of ClawGym-SynData, ClawGym-Agents, and ClawGym-Bench is poised to accelerate research and deployment of robust autonomous agents for real-world productivity, automation, and system administration tasks.
Future Directions
Advancing beyond current limitations, promising avenues include:
- Incorporating more granular intermediate verification criteria (e.g., step-wise feedback, error recovery heuristics).
- Extending synthesis to real-user distributions for higher ecological validity.
- Refining RL training with hierarchical, process-aware reward decomposition.
- Exploring trajectory-level efficiency, safety, and recovery benchmarking beyond final-state correctness.
- Scaling to multimodal and cross-system agent capabilities.
Conclusion
ClawGym delivers a scalable, modular framework unifying task synthesis, agent training, and diagnostic evaluation in Claw-style environments (2604.26904). Its dual-route data pipeline, hybrid verification, and robust evaluation resources underpin consistent, significant model improvements. The results and analyses substantiate the value of environment-grounded synthetic supervision, robustly bridging the performance and capability gap in the new generation of autonomous digital agents.