- The paper presents ClawGUI, an end-to-end infrastructure unifying scalable RL training, standardized evaluation, and real-device deployment for GUI agents.
- ClawGUI-RL employs advanced reward mechanisms including dense process rewards and hierarchical GiGPO, yielding a 2.6% absolute improvement in success on benchmark tasks.
- ClawGUI-Eval ensures reproducible benchmarking via a three-stage pipeline, while ClawGUI-Agent offers hybrid control with personalized memory for effective real-device interactions.
ClawGUI: A Unified Full-Stack Infrastructure for GUI Agent Training, Evaluation, and Deployment
Motivation and Problem Statement
Recent progress on GUI automation via agent-based methods has demonstrated the promise of application control by agents that operate directly on visual interfaces rather than backend APIs. While point solutions for grounding, navigation, and online RL have incrementally improved, the limiting factor is not the expressiveness of isolated models—rather, it is the lack of integrated, reproducible, and end-to-end infrastructure that spans training, evaluation, and user-facing deployment. Existing systems are either closed, limited to virtual environments, suffer from non-reproducible benchmarks, or fail to reach the user on real devices.
ClawGUI addresses this deficit by providing a unified, open-source framework that covers the entire GUI agent lifecycle. It integrates:
- Scalable online RL training (ClawGUI-RL) validated across both emulated and physical environments,
- Standardized, precisely controlled evaluation across major benchmarks and models (ClawGUI-Eval),
- Turnkey deployment to user devices across multiple OS's and chat platforms (ClawGUI-Agent).
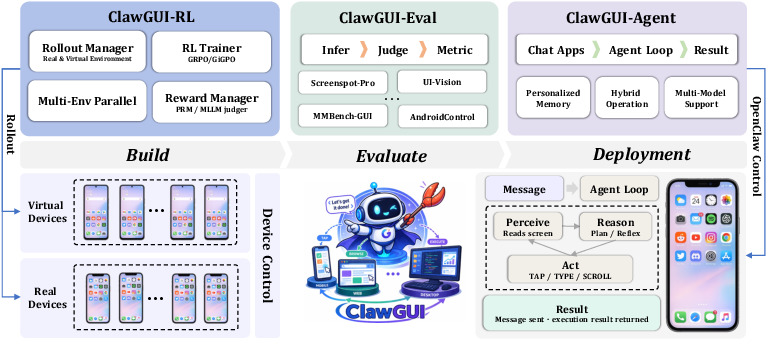
Figure 1: Overview of ClawGUI, which unifies RL training, standardized evaluation, and real-device deployment for GUI agents.
ClawGUI-RL: Scalable RL Agent Training for GUI Environments
ClawGUI-RL provides RL infrastructure to support both large-scale parallel virtual rollouts and direct training on physical devices, crucial for bridging the sim-to-real gap encountered in GUI tasks.
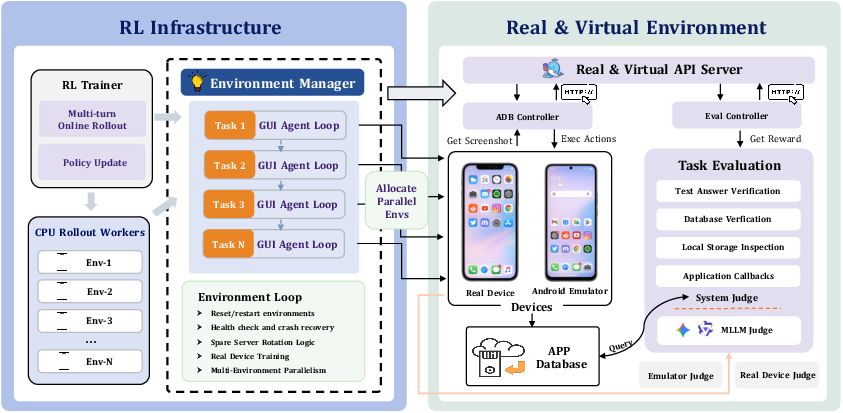
Figure 2: ClawGUI-RL orchestrates parallel rollouts over real/virtual devices and provides robust system-level and MLLM-judged reward signals for RL training.
Environment Management
ClawGUI-RL abstracts both Docker-based Android emulators and heterogeneous physical devices via a unified backend, enabling smooth interchangeability during training. Key system features include:
- Robust health-checking and automatic failover on container crashes,
- System-level verification for emulators and MLLM-based reward signaling for real devices,
- Automated environment reset and state management.
This abstraction enables reliable multi-task rollouts and allows the training pipeline to scale across device types without systemic drift.
GUI RL tasks pose unique credit assignment challenges due to sparse and delayed rewards. Two core reward signals are supported:
- Binary outcome reward: 1 on success at episode terminus.
- Dense process reward (PRM integration): ClawGUI incorporates a step-level Process Reward Model, which evaluates the effect of agent actions on intermediate screenshots, providing dense signals during long interaction sequences.
The framework supports advanced RL optimization strategies. GiGPO, integrated as the principal algorithm, enables fine-grained hierarchical advantage normalization—assigning local advantages by clustering steps into anchor-state sub-groups. This outperforms traditionals such as GRPO which, by default, treat all episode steps equally.
Key empirical outcome: On MobileWorld GUI-Only, replacing GRPO with GiGPO yields a 2.6% absolute improvement in Success Rate (14.5% → 17.1%), highlighting the importance of dense per-step reward for effective RL policy learning on GUIs.
ClawGUI-Eval: Standardized and Reproducible Evaluation
Progress in GUI agents is confounded by silent drift across evaluation practices—coordinate normalization, prompt formatting, image resolution, and postprocessing can each alter reported accuracy substantially, undermining cross-paper comparisons.
ClawGUI-Eval introduces a strictly versioned, three-stage evaluation pipeline:
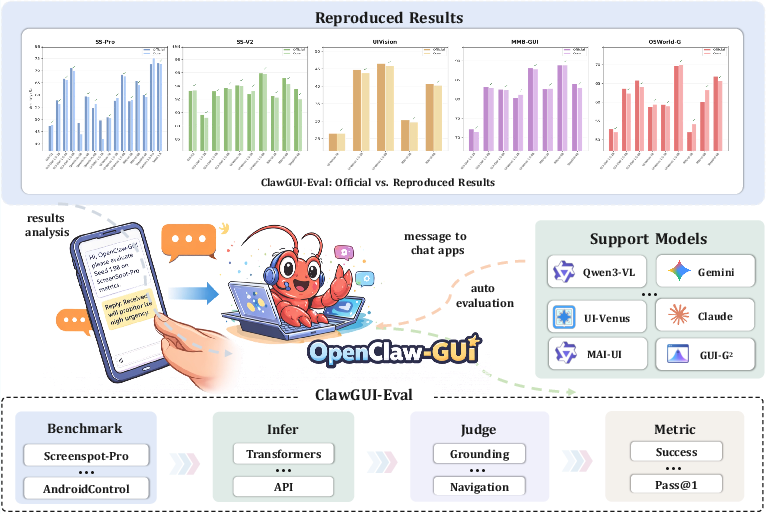
Figure 3: ClawGUI-Eval executes a standardized Infer → Judge → Metric pipeline across 6 benchmarks and 11+ models with reproducibility guarantees.
Evaluation Pipeline
- Infer: Model predictions are generated under pinned configurations (local or remote inference, with strict temperature and checkpointing control).
- Judge: Benchmark-specific judges (with support for polygonal, multi-action, and refusal cases) translate outputs into correctness.
- Metric: Aggregates sample-level judgments with systematic breakdowns by platform and task category.
All code and prediction outputs are public, ensuring that any group can accurately reproduce or re-judge results—even across expensive model inferences.
Result: ClawGUI-Eval achieves a 95.8% reproduction rate versus official reported values across six benchmarks and over a dozen models. Failure cases correlate with missing disclosure in original papers (such as prompt templates or image preprocessing), not with irreducibility of tasks or models.
ClawGUI-Agent: Real Device User Deployment and Personalized Automation
Deployment is addressed by ClawGUI-Agent, which enables both local and remote agent operation across Android, HarmonyOS, and iOS platforms. Users interact naturalistically through major chat platforms (Feishu, DingTalk, Telegram, etc.), and the agent acts on devices via a persistent, message-driven control loop.
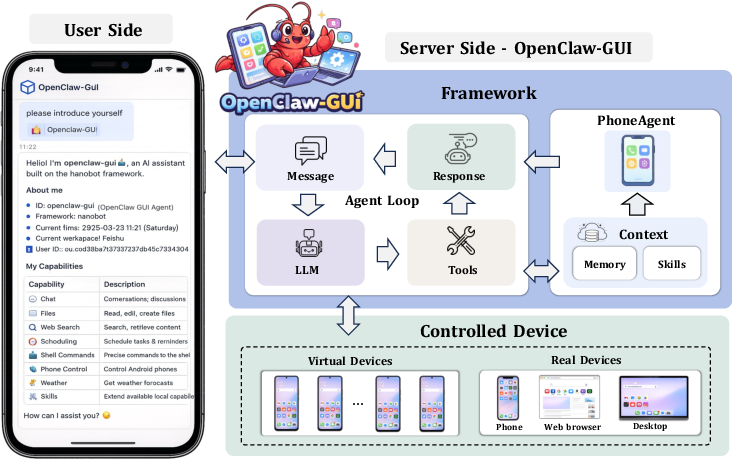
Figure 4: ClawGUI-Agent provides deployment via chat-driven command, persistent memory, and hybrid CLI/GUI execution across device types.
Hybrid Control and Personalized Memory
- Hybrid CLI/GUI Action Routing: CLI primitives are exploited where available for efficiency, with fallbacks to GUI-based control for universality and interpretability.
- Persistent Personalized Memory: User context, frequent contacts, and app usage statistics are embedded and retrieved across agent sessions for routine and adaptive behaviors. Duplicate memory entries are actively merged, maintaining relevance and scalability over time.
Benchmark evaluation can be triggered from any chat interface via natural language, and the agent returns structured result breakdowns, closing the loop between system evaluation and user deployment.
Empirical Validation
The effectiveness of ClawGUI is validated through:
- End-to-end training of ClawGUI-2B (based on MAI-UI-2B, sharing base weights) with the new RL infrastructure. On MobileWorld GUI-Only, ClawGUI-2B achieves a 17.1% Success Rate, strongly outperforming the same-scale MAI-UI-2B baseline (11.1%) and even surpassing larger models such as Qwen3-VL-32B (11.9%) and UI-Venus-72B (16.4%).
- Ablations demonstrate the pivotal contribution of dense step-level rewards, as discussed above.
- Agentic frameworks based on proprietary frontier models (e.g., Gemini-3-Pro + UI-Ins-7B, Claude-4.5-Sonnet + UI-Ins-7B) report higher numbers but require closed-source planners—ClawGUI aims to make comparable methods available and reproducible in the open domain.
Implications and Future Directions
Infrastructure as performance multiplier: The results underscore that advanced RL infrastructure and strict evaluation control can close substantial performance gaps without requiring massive increases in base model scale or post hoc tricks.
Mass-deployable, open-source pipeline: With public code and prediction artifacts, ClawGUI fulfills a reproducibility mandate and serves as a benchmark substrate for further experimental work on agent decision algorithms and reward engineering.
Towards system-level, persistent agents: The integrated design of personalized memory and hybrid control in ClawGUI-Agent aligns with a vision of continual, user-adaptive, and on-device agentic intelligence. Medium-term directions include tighter OS-level integration, privacy-preserving local training, and the introduction of predictive GUI world models to support model-based planning, aligning with research on GUI environment dynamics (Zheng et al., 10 Feb 2026, Luo et al., 15 Apr 2025).
Conclusion
ClawGUI is the first open-source framework to robustly unify RL training (across emulated/real devices), reproducible evaluation, and deployment for GUI agents. By offering robust infrastructure for end-to-end GUI agent development, ClawGUI enables strong models with modest scale to outperform much larger vanilla baselines, strictly defines evaluation protocols for trustworthy comparisons, and translates these gains to practical, real-world user platforms with personalized persistence.
This framework lays a foundation for both community-wide scientific progress and the rapid prototyping and deployment of user-facing, capable GUI agents (2604.11784).