- The paper introduces a hybrid API-GUI paradigm and a scalable distributed RL framework that enables efficient training for autonomous desktop automation agents.
- It employs a three-stage training methodology combining behavior cloning, step-level GRPO, and the Entropulse phase to overcome entropy collapse and enhance exploration.
- Empirical evaluations on the OSWorld benchmark show a 64% performance gain over baselines, with improved task completion efficiency and reduced operational steps.
ComputerRL: End-to-End Online Reinforcement Learning for Desktop Automation Agents
Introduction and Motivation
The paper presents ComputerRL, a comprehensive framework for training autonomous agents to operate complex desktop environments using end-to-end online reinforcement learning (RL). The motivation stems from the limitations of existing GUI agents, which are constrained by human-centric interface designs and the inefficiency of behavior cloning (BC) and model distillation approaches. ComputerRL addresses these challenges by introducing a hybrid API-GUI interaction paradigm, a scalable distributed RL infrastructure, and a novel training strategy—Entropulse—to mitigate entropy collapse and sustain learning in extended RL runs.
Framework Architecture and API-GUI Paradigm
ComputerRL's architecture is built around three pillars: the API-GUI action space, a large-scale parallel desktop environment, and a fully asynchronous RL training framework.
The API-GUI paradigm unifies programmatic API calls with direct GUI actions, allowing agents to leverage the efficiency of APIs while retaining the flexibility of GUI operations. API construction is automated via LLMs, which analyze user-supplied task exemplars, generate interface definitions, implement APIs using application-specific Python libraries, and produce test cases for validation. This workflow significantly reduces manual effort and enables rapid expansion of agent capabilities across diverse applications.
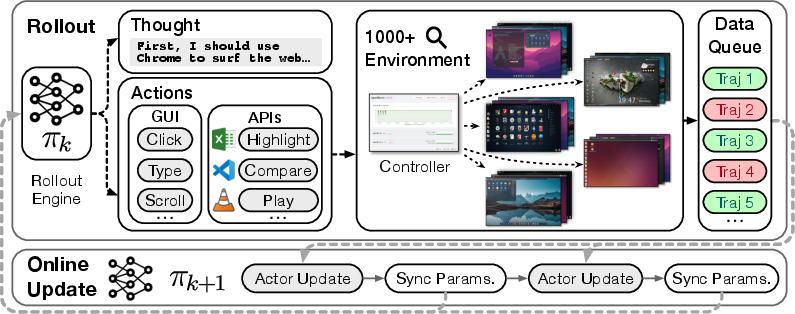
Figure 1: Overview of ComputerRL framework, integrating API-GUI actions and large-scale parallel desktop environments for efficient agent training.
The infrastructure supports thousands of concurrent Ubuntu desktop instances, orchestrated via Docker and gRPC, with a web-based controller for real-time monitoring. The environment is decoupled from the computational backend, enabling flexible resource management and seamless integration with learning algorithms.
Training Methodology: Behavior Cloning, RL, and Entropulse
Training in ComputerRL proceeds in three stages:
- Behavior Cloning (BC) Cold-Start: Initial policy is trained via supervised imitation of trajectories collected from multiple general LLMs. Stratified sampling and model collaboration are used to maximize trajectory diversity and coverage, especially for hard or unsolved tasks.
- Step-Level Group Relative Policy Optimization (GRPO): RL is performed using a step-level extension of GRPO, where each action in a trajectory receives a reward based on verifiable, rule-based task completion. The loss aggregates step advantages, normalized across all actions in a batch, and includes a KL penalty to regularize policy updates.
- Entropulse: To counteract entropy collapse and stagnation in RL, Entropulse alternates RL with supervised fine-tuning (SFT) on successful rollouts. This restores policy entropy, enhances exploration, and enables further performance gains in subsequent RL phases.
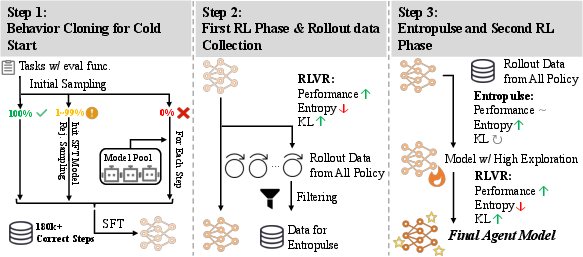
Figure 2: ComputerRL training pipeline, illustrating BC cold-start, RL with step-level GRPO, and Entropulse for entropy recovery.
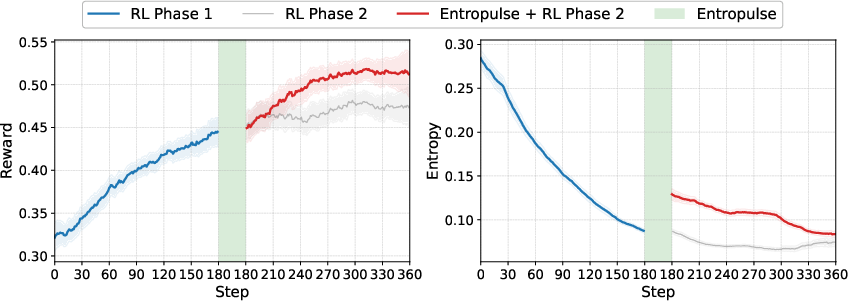
Figure 3: Training curves showing reward and entropy dynamics, with Entropulse restoring exploration and enabling continued improvement.
ComputerRL is evaluated on the OSWorld benchmark using open-source LLMs (GLM-4-9B-0414 and Qwen2.5-14B). The AutoGLM-OS-9B agent achieves a state-of-the-art success rate of 48.1% on OSWorld, representing a 64% performance gain from RL and outperforming proprietary and open baselines such as OpenAI CUA o3 (42.9%), UI-TARS-1.5 (42.5%), and Claude Sonnet 4 (30.7%).
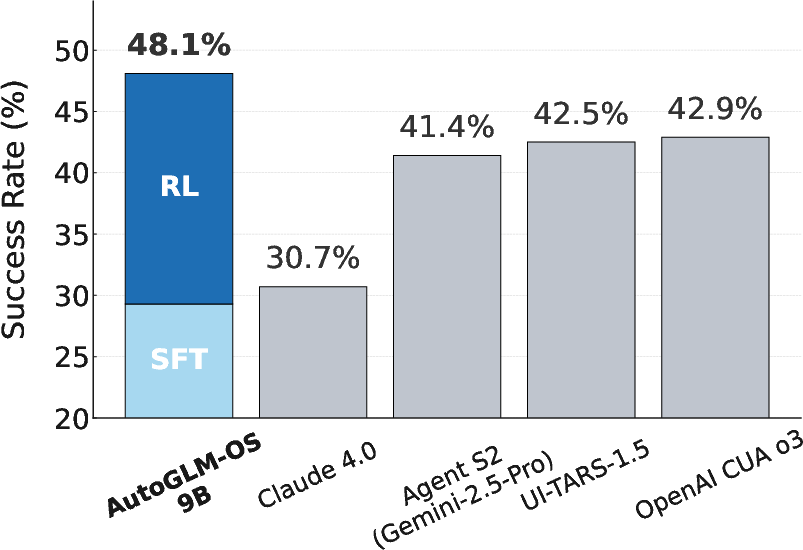
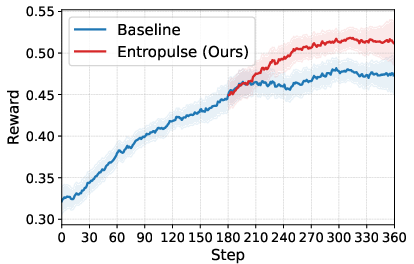
Figure 4: Success rates of agents on OSWorld, with AutoGLM-OS trained via ComputerRL surpassing prior models.
Ablation studies demonstrate that the API-GUI paradigm yields a 134% improvement over GUI-only approaches, with the largest gains in Office and Professional domains. Multi-stage training, particularly the Entropulse phase, is critical for maintaining exploration and achieving optimal performance. The agent exhibits strong proficiency in long-range planning and complex reasoning, completing tasks with up to 1/3 fewer steps than baselines.
Qualitative Case Studies and Error Analysis
Case studies illustrate the agent's ability to execute diverse desktop tasks, including table creation in LibreOffice Calc, text formatting in Writer, system resource monitoring via Terminal, and image transfer between GIMP and Writer.
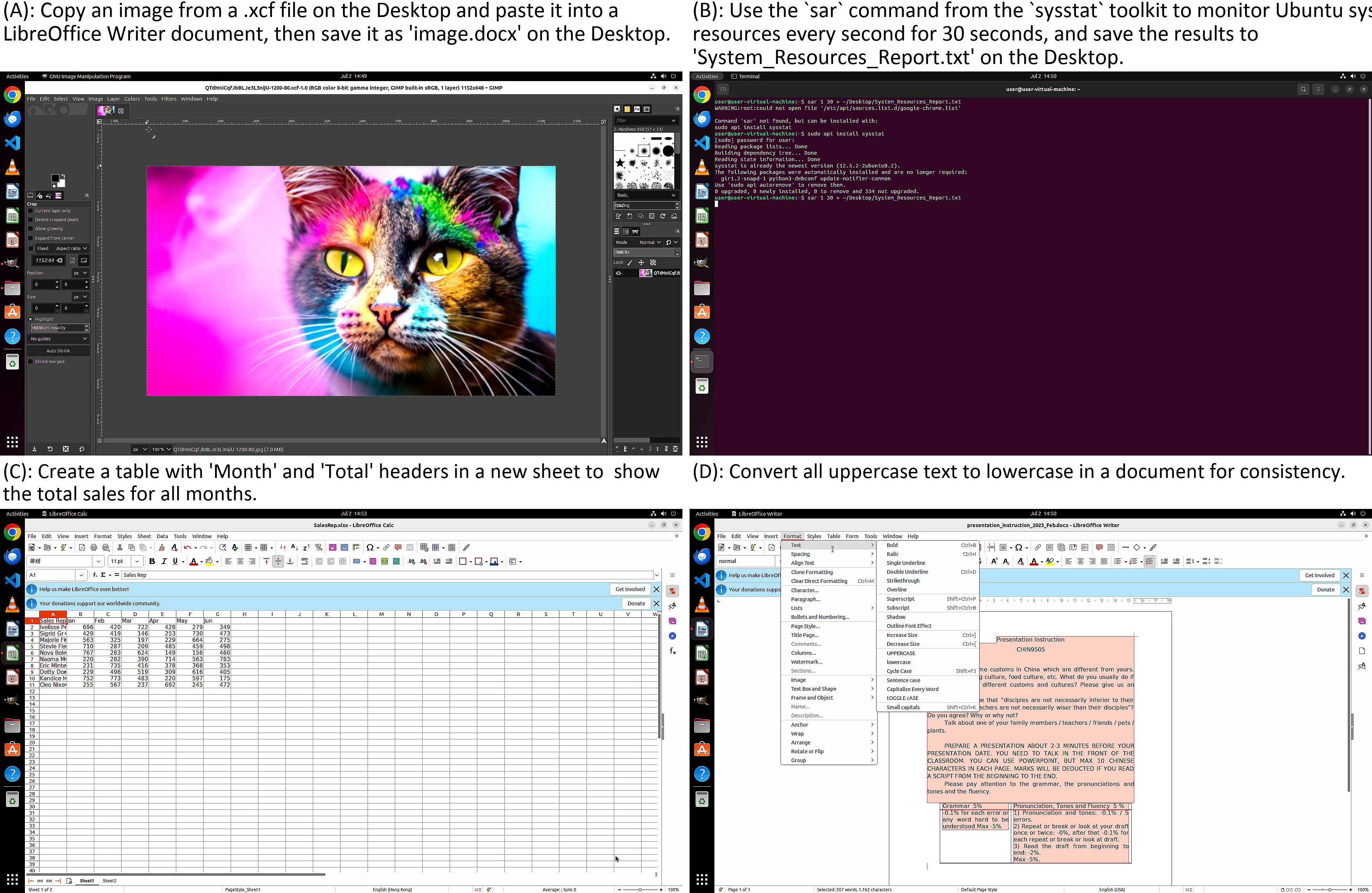
Figure 5: Examples of AutoGLM-OS executing multi-application user tasks in the Ubuntu desktop environment.
Figure 6: Stepwise execution of a table creation task in LibreOffice Calc.

Figure 7: Execution of a text case conversion task in LibreOffice Writer.
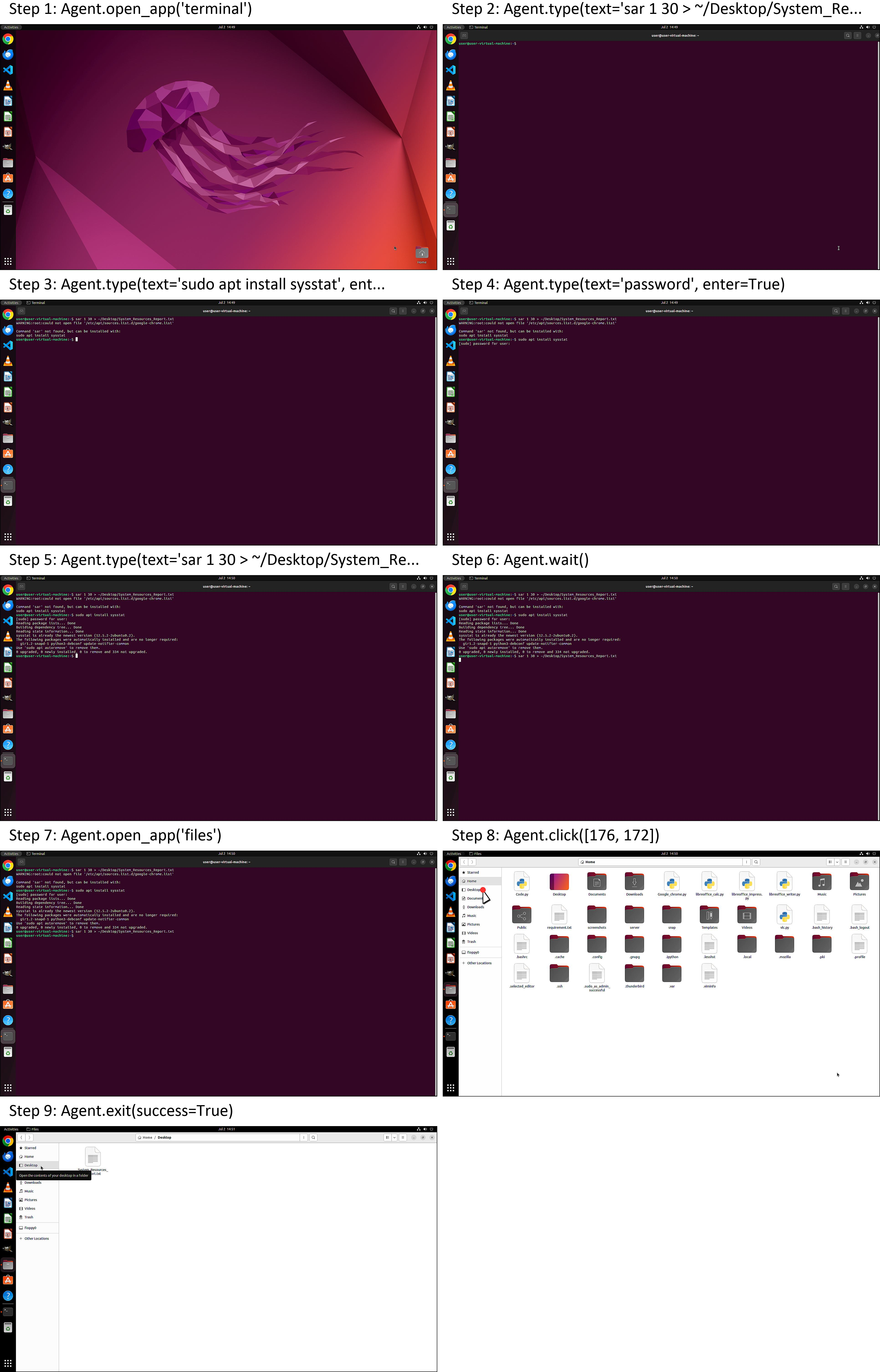
Figure 8: System resource monitoring and report generation via Terminal.
Figure 9: Image transfer from GIMP to LibreOffice Writer and document saving.
Error analysis reveals that failures are primarily due to visual perception errors (25.8%), multi-application coordination (34.4%), operational illusions (14.2%), and other factors (25.6%). Representative failure cases include misunderstanding task requirements and incorrect click operations.
Figure 10: Failure due to question misunderstanding in a text processing task.

Figure 11: Failure due to incorrect click operations when changing GIMP's theme.
Implications and Future Directions
ComputerRL establishes a scalable and robust foundation for training generalist desktop agents. The hybrid API-GUI paradigm and distributed RL infrastructure enable efficient learning and generalization across heterogeneous applications. The Entropulse strategy provides a principled solution to entropy collapse, facilitating sustained policy improvement.
Practical implications include the potential for persistent, autonomous desktop assistants capable of orchestrating complex workflows, adapting to novel interfaces, and integrating multimodal perception. Theoretical implications involve the design of RL algorithms and training curricula that balance exploration and exploitation in high-dimensional, long-horizon environments.
Future research should focus on expanding training diversity, enhancing multimodal perception, developing hierarchical planning for long-horizon autonomy, and establishing safety and alignment protocols for agent actions in sensitive digital environments.
Conclusion
ComputerRL advances the state of the art in desktop automation agents by integrating API-based and GUI actions, scalable data collection, and multi-stage RL training. The framework demonstrates superior reasoning, accuracy, and generalization on OSWorld, laying the groundwork for more capable and persistent autonomous computer use agents. The work highlights promising directions for future research in intelligent human-computer interaction and RL-based agent training.