Gym-Anything: Turn any Software into an Agent Environment
Abstract: Computer-use agents hold the promise of assisting in a wide range of digital economic activities. However, current research has largely focused on short-horizon tasks over a limited set of software with limited economic value, such as basic e-commerce and OS-configuration tasks. A key reason is that creating environments for complex software requires significant time and human effort, and therefore does not scale. To address this, we introduce Gym-Anything, a framework for converting any software into an interactive computer-use environment. We frame environment creation itself as a multi-agent task: a coding agent writes setup scripts, downloads real-world data, and configures the software, while producing evidence of correct setup. An independent audit agent then verifies evidence for the environment setup against a quality checklist. Using a taxonomy of economically valuable occupations grounded in U.S. GDP data, we apply this pipeline to 200 software applications with broad occupational coverage. The result is CUA-World, a collection of over 10K long-horizon tasks spanning domains from medical science and astronomy to engineering and enterprise systems, each configured with realistic data along with train and test splits. CUA-World also includes CUA-World-Long, a challenging long-horizon benchmark with tasks often requiring over 500 steps, far exceeding existing benchmarks. Distilling successful trajectories from the training split into a 2B vision-LLM outperforms models 2$\times$ its size. We also apply the same auditing principle at test time: a separate VLM reviews completed trajectories and provides feedback on what remains, improving Gemini-3-Flash on CUA-World-Long from 11.5% to 14.0%. We release all code, infrastructure, and benchmark data to facilitate future research in realistic computer-use agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching and testing AI “computer-use agents”—programs that can move a mouse, type on a keyboard, and use apps—on real, complicated computer tasks. Instead of training them on simple chores (like changing a wallpaper), the authors build a way to turn almost any software into a practice “level” with realistic data and long, multi-step goals. They call the framework Gym-Anything, and the big collection of practice tasks they created with it is called CUA-World.
What questions were the researchers trying to answer?
- How can we quickly and reliably turn many different apps (from spreadsheets to medical or astronomy tools) into practice environments for AI agents?
- How can we make sure these practice tasks are realistic and tied to real jobs that matter in the economy—not just toy examples?
- How can we check if an AI agent really did the task correctly, step by step, especially when tasks take hundreds of actions?
- Can training on these richer tasks make smaller AI models better at using computers?
- Can a “test-time auditor” (a separate AI that reviews the work after the fact) help agents finish long tasks better?
How did they do it? (In simple terms)
Think of this like building a giant “video game” for AI agents, where each app (like a spreadsheet program or a medical-imaging viewer) is a different level, and each level has missions. The authors built tools and a process to make lots of levels fast and to grade the missions fairly.
Here’s the approach, using everyday analogies:
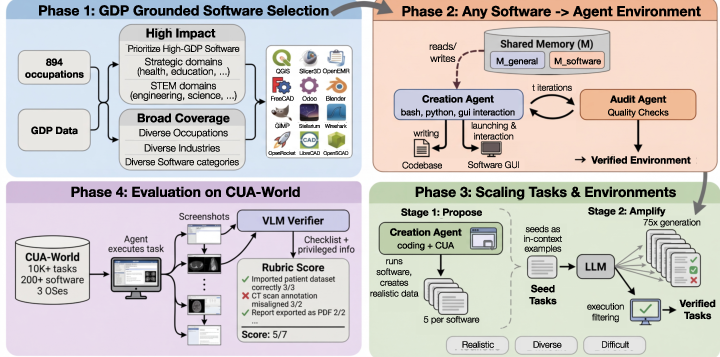
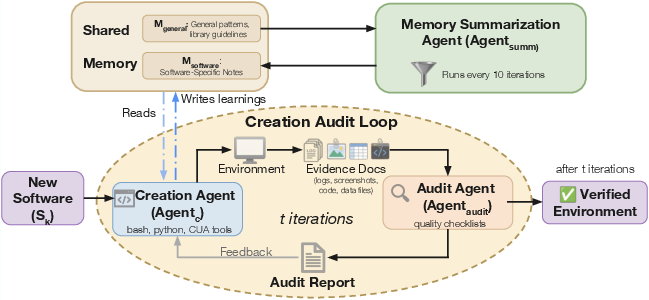
- Builder and Inspector loop:
- A “builder” AI writes setup scripts to install a piece of software, load realistic data, and prepare the app so it’s ready to use—just like a game designer building a level.
- The builder collects proof (screenshots, logs) that the setup works.
- An independent “inspector” AI checks that proof against a quality checklist—like a safety inspector making sure the level isn’t broken. If problems are found, the builder fixes them.
- They save tips and fixes to a shared “notebook” so future setups get faster and better.
- A simple recipe for any app:
- Every app environment is described by just three short scripts—install, configure, and task-setup—plus a small config file. This makes it easy to reuse, version, and run across different operating systems (Linux, Windows, Android) and across many computers at once.
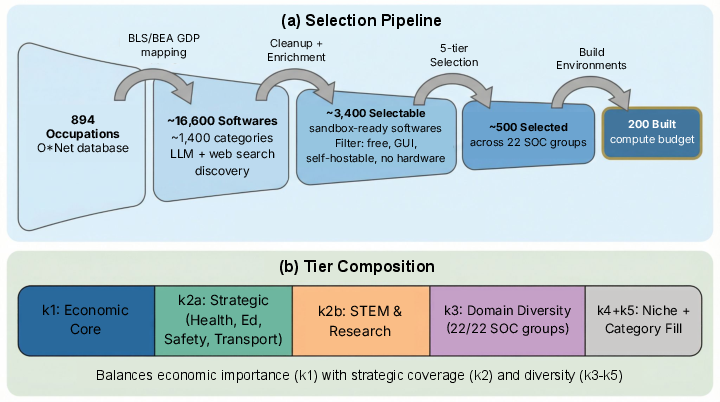
- Choosing software that matters in real jobs:
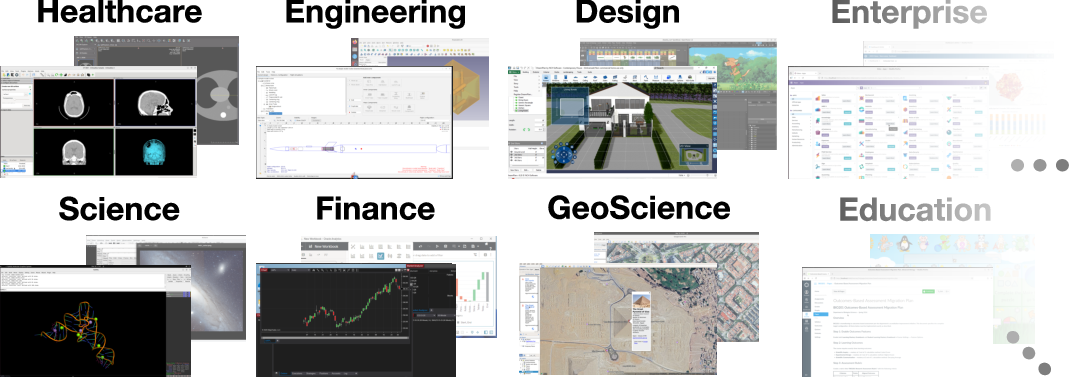
- Instead of picking random apps, the team used U.S. economic data to find software tied to real work that contributes to GDP. They selected 200 apps that cover all major occupation groups (healthcare, engineering, finance, education, etc.).
- They focused on apps that can be “sandboxed” (free, self-hostable, with a graphical interface, and no special hardware).
- Creating many realistic tasks:
- First, an expensive, high-quality “proposer” AI creates a few excellent example tasks per app and actually runs them to make sure they work.
- Then, a cheaper AI “amplifies” those examples into many more tasks, inspired by the good seeds. Extra checks filter out broken or repetitive tasks.
- Grading with a checklist and a hidden answer key:
- For each task, a vision-LLM (VLM) grades the agent’s work using a checklist of small goals (like sub-steps).
- The grader can use “privileged information”—facts pulled from the setup scripts and datasets (like the true tumor location in a scan)—that the agent does not see. Think of it as an answer key only the teacher can read.
- There are also “integrity” checks to make sure the agent didn’t cheat (for example, by editing files directly instead of using the app’s interface).
What did they find, and why does it matter?
Here are the main results:
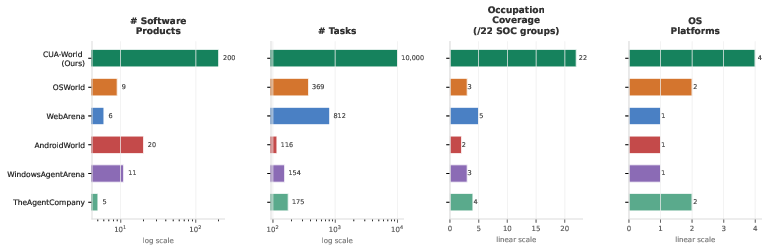
- A huge, realistic task collection (CUA-World):
- Over 10,000 tasks across 200 apps, covering every major occupation group and multiple operating systems.
- Tasks are long-horizon (many steps), realistic, and split into train and test sets so researchers can learn and evaluate fairly.
- A very challenging long-task benchmark:
- CUA-World-Long has 200 extra-hard tasks (one per app) that often take hundreds of steps.
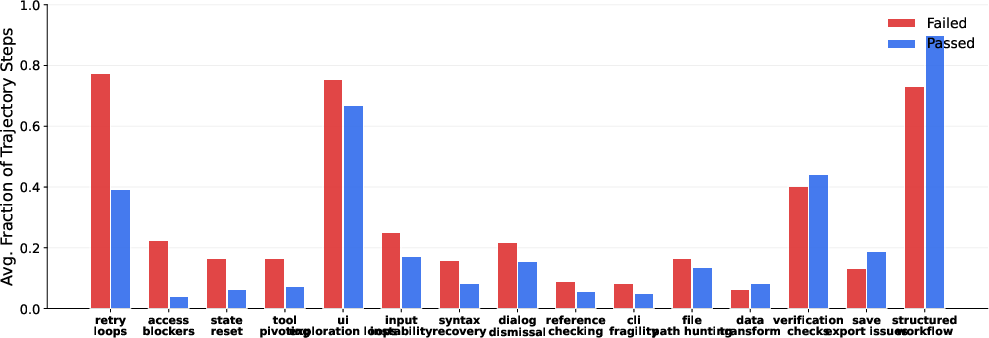
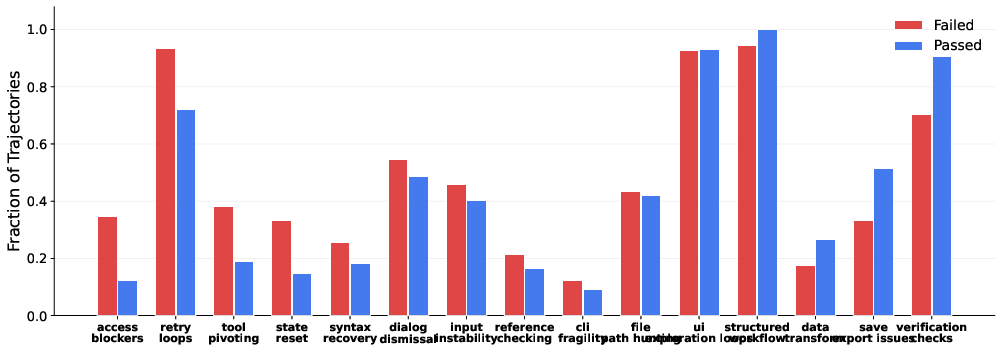
- Even top models struggle—one strong model only passed 27.5% of these. This shows today’s agents still have trouble with very long, real-world workflows.
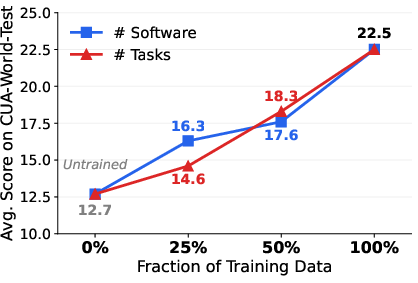
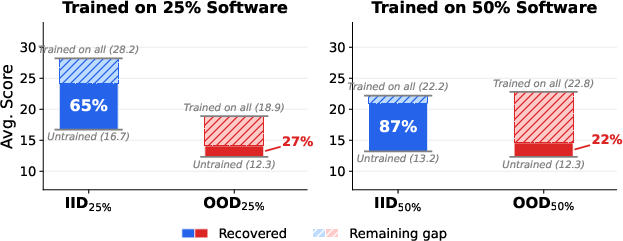
- Smaller models can learn a lot:
- By “distilling” (teaching) a 2-billion-parameter model using successful example runs from stronger models, the small model beat other models that are twice its size. It also learned to use new software it hadn’t seen before.
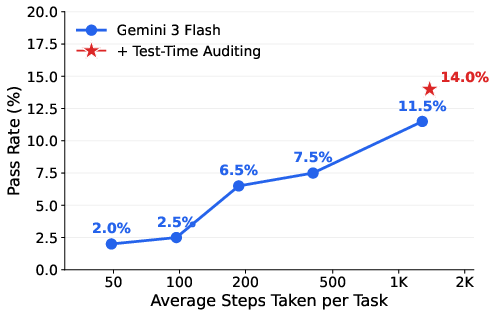
- Auditing helps at test time:
- After an agent says “I’m done,” a separate reviewer AI looks at what’s left and gives feedback. This boosted one model’s score on CUA-World-Long from 11.5% to 14.0%.
- It doesn’t solve everything, but it helps reduce the “I stopped too early” problem.
Why this matters:
- This work moves beyond simple computer tasks and tests AI on the kinds of software and workflows people actually use at work. That makes training and evaluation much more meaningful.
- The framework (Gym-Anything) shows a practical way to scale up realistic, long, and varied tasks without tons of human labor.
- The checklist-based grading with a hidden answer key makes evaluations more reliable and fair.
What’s the bigger impact?
If AI agents can truly learn to operate many types of real software over long workflows, they could:
- Help professionals in healthcare, engineering, finance, education, and more with complex, time-consuming digital tasks.
- Give researchers a common, realistic benchmark to compare and improve agents.
- Speed up progress toward trustworthy computer assistants that can handle real office and lab work—not just short demos.
The authors are releasing the code, infrastructure, and data so others can build on it. In short, this paper sets up a realistic training ground and scorecard for the next generation of AI that uses computers like people do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps that remain unresolved and could guide future research.
- US-centric selection bias: The GDP-grounded software selection focuses on U.S. data; it is unclear how well the software mix generalizes to other economies, industries, and non-English locales.
- Validity of GDP-to-software attribution: The per-software GDP attribution relies on LLM-estimated category and software shares with web search; there is no reported sensitivity analysis, human validation, or reproducibility study across model versions and prompts.
- Substitution fidelity: Many high-impact applications are replaced by sandboxable alternatives; the behavioral and skill-transfer gap between substitutes and the real (often cloud-licensed) software is unmeasured.
- macOS/iOS and broader platform coverage: The environment excludes macOS and iOS and largely omits cloud/SaaS-only enterprise software (e.g., Office 365, Salesforce, SAP S/4HANA Cloud); the consequences for ecological validity are not quantified.
- Enterprise credential workflows: Realistic multi-user, credentialed, and compliance-heavy workflows (SSO, RBAC, audit trails) are not modeled; methods to safely simulate them remain open.
- Cross-application workflows: The benchmark offers limited evidence of tasks that require orchestrating multiple applications in a single workflow (e.g., data transfer among ERP, spreadsheets, email, and BI dashboards); coverage and evaluation for multi-app dependencies are missing.
- Software/version drift and reproducibility: There is no systematic study of how environment robustness changes with OS/app version updates, different display settings, or container backends; version pinning and reproducibility guarantees are unspecified.
- Determinism and variability controls: The paper does not quantify nondeterminism sources (timers, race conditions, network timeouts) or provide seeds and methods to reproduce trajectories reliably across runs/hardware.
- Security and supply-chain risk: Automatically downloading/running third-party software and datasets at scale raises malware and supply-chain concerns; threat modeling and mitigation (scanning, sandbox hardening, egress controls) are not discussed.
- Compute/resource accessibility: Running 400+ concurrent environments on 1,600 CPUs sets a high resource bar; pathways for smaller labs to reproduce results at reduced scale are not provided.
- Task solvability and realism after amplification: The non-agentic amplification step may introduce trivial, duplicate, or impossible tasks; the VLM-based start-state filter alone is insufficient to guarantee solvability, and no post-hoc passability audit is reported.
- Coverage metrics for task space: There is no formal metric for functional coverage within each application (feature/API/UI coverage) or across domains; diversity is qualitatively enforced but not quantitatively measured.
- Human baseline and expert validation: The benchmark lacks human performance baselines and expert review of task realism/difficulty at scale to calibrate VLM verifiers and task design.
- VLM verifier reliability and drift: While checklist-based verification shows higher agreement than alternatives, there is no large-scale inter-annotator agreement study, adversarial stress testing, or analysis of verifier drift across VLM versions.
- Integrity check enforcement: The integrity checklist (e.g., “used the intended software,” “no file edits to bypass UI”) is not backed by instrumented OS-level monitors (process, window, file, network hooks); hence, undetected shortcutting remains possible.
- Privileged information extraction accuracy: Automated extraction of ground truth from setup scripts may mis-specify checklists; error rates, failure modes, and auditing procedures for extraction are not reported.
- Reward hacking and partial-credit pitfalls: Agents may strategically satisfy high-weight checklist items without accomplishing the intended outcome; strategies to harden checklists against such behavior are not explored.
- Internationalization and accessibility: Tasks assume English UIs; there is no support or evaluation for other languages, locale formats, or accessibility modalities (screen readers, high-contrast modes).
- Action-space completeness: It is unclear whether the standardized action space robustly supports complex interactions (drag-and-drop nuances, multi-select, clipboard/file dialogs, IME input, OS-level hotkeys) across all OSs.
- Long-horizon temporal persistence: Real-world work often spans days with stateful projects; the benchmark does not model multi-session persistence (e.g., recovery after reboot, hand-offs), nor evaluate agents’ ability to resume work.
- Coverage of non-GUI modalities: Many digital workflows combine GUIs with CLI/API automations; the benchmark focuses on GUI agents and does not explore hybrid GUI–API/CLI tasks.
- Scaling beyond 200 applications: Although the pipeline is “fully automated,” the scalability and failure rates (creation vs. audit iterations) for thousands of applications are unquantified.
- Multi-agent creation–audit robustness: Both creation and audit are driven by closely related frontier models; correlated failure modes and the benefits of cross-model or ensemble auditing are not systematically assessed.
- Memory summarization efficacy: The shared memory and summarization agent are central to scale-up, yet there are no measurements of their impact on creation time, failure rates, or error propagation over iterations.
- Distillation methodology transparency: The teacher model, selection criteria for trajectories, training objective, and ablations (e.g., effect of software/task diversity, trajectory length) are not fully specified; reproducibility and data release for training are unclear.
- Generalization outside CUA-World: The model’s transfer to other benchmarks (e.g., OSWorld, AndroidWorld, web arenas) is not reported; cross-benchmark generalization and negative transfer remain open.
- Overfitting to UI templates: There is no analysis of whether trained agents overfit to specific UI frameworks/themes (e.g., Gtk/Qt, Windows variants) or how well they handle unseen themes and DPI/scaling changes.
- Test-time auditing safeguards: The reviewer model provides feedback to the acting agent; how to prevent leakage of privileged information, avoid degeneracy (infinite loops), and generalize beyond a single model is not studied.
- Metrics beyond pass rate: The evaluation emphasizes pass rate/partial credit; time-to-completion, number of recoveries from errors, safety/irreversibility, and user-centric metrics are not analyzed.
- Data licensing and privacy: Use of domain datasets (e.g., medical imaging, email corpora) raises licensing/PII concerns; provenance tracking and compliance checks are not detailed.
- Train–test contamination at the UI/state level: Although instruction-level contamination is addressed, shared base configurations and reused datasets across splits may leak solution affordances; a deeper contamination analysis is missing.
- Releasing reproducible Windows/Android setups: It is unclear whether full VM/container images or only scripts are released for all OSs (especially Windows), and how licensing is handled; this affects replicability.
- Handling dynamic internet dependence: Many modern apps require online services; the sandbox excludes non-self-hostable software, leaving a gap in evaluating internet-dependent workflows or simulating them faithfully.
- Adversarial evaluation: No adversarial setting is provided where agents attempt to fool the VLM verifier; building red-team scenarios to evaluate verifier robustness is unexplored.
- Continual benchmark maintenance: Processes for updating tasks/software, deprecating broken environments, and ensuring longitudinal comparability across versions are not specified.
- Benchmarking training algorithms: The benchmark is used for distillation but not to systematically evaluate RL/planning/constraint-solving algorithms with long-horizon credit assignment and sparse feedback; this is an open direction.
- Teaming and tool ecosystems: Coordination between multiple agents (planner–executor–verifier) or integrating external tools (RPA, OCR/ASR, domain-specific solvers) is not benchmarked.
- Economic impact linkage: While GDP informs selection, there is no framework to translate benchmark performance improvements into estimated productivity gains or ROI by occupation/software.
Practical Applications
Below is a synthesized set of practical applications that flow from the paper’s findings and methods, organized by deployment horizon. Each bullet summarizes the application, the sectors it impacts, what tools/products/workflows might emerge, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed now with currently available software, compute, and LLM/VLM capabilities.
- Rapid conversion of internal software into agent-ready sandboxes (Industry, Software, Cloud/IT)
- What/How: Use Gym-Anything’s “environment-as-code” (install/configure/task-setup scripts + config) to turn in-house or open-source tools into reproducible, interactable agent environments for testing and training.
- Tools/Products: “Gym-Anything library” adoption; “Agent Testbed” CI pipelines; containerized Windows/Linux/Android envs; “Environment Pack” templates.
- Assumptions/Dependencies: Software must be sandboxable (self-hostable, free tier, GUI, no specialized hardware); container/VM infrastructure; access to realistic open datasets; basic ops for Docker/Apptainer and display forwarding.
- Benchmarking and vendor evaluation of GUI copilots/agents (Industry procurement, Policy, Software)
- What/How: Use CUA-World and CUA-World-Long to run realistic, long-horizon evaluations on tools like ERP, analytics, imaging, and office suites; compare models with checklist-based scoring.
- Tools/Products: “Benchmark-as-a-Service” for agent evaluation; sector-specific task suites; scoring dashboards.
- Assumptions/Dependencies: Mapping benchmark tasks to the org’s software stack; compute time for long episodes; acceptance of VLM/verifier judgments.
- GUI QA and regression testing with VLM checklists (Software engineering, DevOps/MLOps)
- What/How: Replace brittle scripted UI tests with Gym-Anything tasks + checklist-based VLM verification (with privileged information) for end-to-end feature flows and regression detection.
- Tools/Products: “Checklist Verifier SDK” integrated into CI; screenshot/log artifacting; test triage dashboards.
- Assumptions/Dependencies: Deterministic task setup; stable VLM verification; screenshot security; compute for parallel testing.
- Training smaller on-prem/edge agents via distillation (Finance, Healthcare, Enterprise IT)
- What/How: Distill teacher trajectories from CUA-World-style environments into compact (≈2B) VLMs that outperform larger models in targeted workflows; deploy on controlled hardware for privacy.
- Tools/Products: “Distillation pipeline” for internal workflows; compact VLM inference stacks; edge deployment kits.
- Assumptions/Dependencies: Access to teacher model and trajectory data; privacy/compliance policies; sufficient training compute; data provenance to avoid leakage.
- Test-time auditor to reduce premature stopping and errors (RPA, Support, Daily life)
- What/How: Add a separate VLM “auditor” to review an agent’s trajectory before declaring success and provide corrective feedback, reducing false completions.
- Tools/Products: “Agent Auditor” microservice; agent-orchestration plug-ins that gate completion on audit results; escalation workflows.
- Assumptions/Dependencies: Extra inference cost/latency; auditor prompt design; clear integrity rules; monitoring for auditor-agent collusion risks.
- Employee training labs with auto-grading on real software (Education, Enterprise L&D)
- What/How: Build hands-on labs on real applications (spreadsheets, CRM, EHR simulators) using tasks with automated feedback and partial credit via checklists.
- Tools/Products: “Interactive Lab Packs”; automated graders; progress analytics.
- Assumptions/Dependencies: Free-tier or open-source software; licensing for training datasets; isolation for safe experimentation; VLM verification reliability.
- Academic research on long-horizon planning and robustness (Academia)
- What/How: Use CUA-World (train/test) and CUA-World-Long to research planning, interruption handling, tool-use, and verification approaches; benchmark new agents.
- Tools/Products: Baselines; ablation studies on privileged-information verifiers; reproducible training splits.
- Assumptions/Dependencies: Access to compute; familiarity with containerized environments; openness to VLM-based evaluation.
- GDP-grounded prioritization for AI investments (Policy, Corporate strategy)
- What/How: Use the GDP-anchored software/occupation mapping to identify which digital workflows matter most economically and prioritize automation or training accordingly.
- Tools/Products: “Automation Opportunity Maps” by occupation/domain; ROI calculators.
- Assumptions/Dependencies: US-centric data (requires localization for other countries); LLM-estimated software/category shares; periodic data refresh.
- Data/task curation at scale via propose-and-amplify (Academia, Software, Training teams)
- What/How: Generate a few high-quality agentic seed tasks and amplify them with a cheaper LLM, then filter using a VLM; quickly build diverse task corpora for new apps.
- Tools/Products: “Task Amplifier” pipeline; semantic deduplication; start-state consistency checks.
- Assumptions/Dependencies: Seed task quality; LLM budget; VLM filters can produce false positives/negatives.
- Agent safety and integrity enforcement (Compliance, Risk)
- What/How: Apply integrity checklists to ensure agents don’t bypass intended workflows (e.g., editing config files directly vs using the app UI); zero score on violations.
- Tools/Products: Policy packs; automated integrity audits; action provenance logs.
- Assumptions/Dependencies: Strong isolation and logging; carefully designed integrity rules per application; attacker models for red-teaming.
- High-throughput environment orchestration for agent workflows (Cloud/IT Ops)
- What/How: Run hundreds of concurrent environments across CPU clusters (e.g., SLURM) using caching at install/configure/task stages; schedule long-horizon runs efficiently.
- Tools/Products: Cluster orchestration recipes; caching stores; resource quotas and monitors.
- Assumptions/Dependencies: Container/VM support for Linux/Windows/Android; GPU/CPU capacity; ops expertise.
- Course assignments and assessment in real tools (Education)
- What/How: Create reproducible assignments on spreadsheets, IDEs, GIS, scientific imaging tools with auto-verification; reusable across semesters.
- Tools/Products: Curriculum-aligned task packs; auto-grading rubrics; analytics.
- Assumptions/Dependencies: Software availability on campus hardware; accessibility compliance; student privacy.
- Personal skill practice in safe sandboxes (Daily life)
- What/How: Practice spreadsheet analysis, photo editing, or statistical workflows in preconfigured sandboxes with immediate, checklist-based feedback.
- Tools/Products: “Skill Drills” with guided tasks; portable sandbox bundles.
- Assumptions/Dependencies: Local compute; open datasets; simplified setup UX for non-experts.
- Vendor SDKs for agent compatibility and verification (Software vendors)
- What/How: Expose environment setups, privileged-information hooks, and checklists so third-party agents can integrate and be evaluated consistently.
- Tools/Products: “Agent Compatibility SDK”; verification endpoints; test images.
- Assumptions/Dependencies: Vendor engineering bandwidth; API stability; handling of proprietary data.
Long-Term Applications
These require further research, ecosystem coordination, or integration with proprietary systems and regulatory frameworks.
- Reliable automation of complex enterprise workflows (ERP/CRM/EHR, Finance, Supply chain)
- What/How: Train and validate agents end-to-end on long-horizon tasks (e.g., account reconciliation, claims processing) with audit trails and integrity checks before running on live systems.
- Tools/Products: “Enterprise Agent Copilots” with built-in auditors; safe staging-to-prod promotion pipelines.
- Assumptions/Dependencies: Access to proprietary software/data; IT governance; rigorous evaluation; incident response.
- Certification standards for computer-use agents (Policy, Standards bodies, Regulators)
- What/How: Sector-specific “CUA exams” (e.g., healthcare, finance) using long-horizon tasks and privileged-info verification; minimum pass thresholds for deployment.
- Tools/Products: Conformance test suites; third-party audit labs.
- Assumptions/Dependencies: Multistakeholder consensus; legal frameworks; versioned benchmarks to avoid overfitting.
- Sector benchmark consortia and environment packs (Healthcare, Education, Engineering)
- What/How: Regularly updated task suites curated with domain experts; shared across vendors and researchers.
- Tools/Products: “Sector Packs” with data, tasks, and verifiers; governance councils.
- Assumptions/Dependencies: Data licensing; expert participation; sustained funding.
- OS-level agent interfaces and “Agent Mode” (Platform/OS vendors)
- What/How: Native, secure APIs for screenshot/controls, privileged verification hooks, and integrity enforcement integrated into Windows/Linux/Android.
- Tools/Products: Unified action/observation APIs; permissioned capability profiles; sandbox attestation.
- Assumptions/Dependencies: Vendor buy-in; security models and isolation; backward compatibility.
- Marketplace for environment/task packs and auditor modules (Software ecosystem)
- What/How: Buy/sell curated environments, tasks, and auditor plug-ins for specific software verticals.
- Tools/Products: “Agent App Store” for training/evaluation assets.
- Assumptions/Dependencies: Interoperability standards; IP/licensing models; quality control.
- Continuous auditing and self-correction in production (RPA/MLOps)
- What/How: Auditor agents monitor running agents, detect partial completion, suggest next steps, and block unsafe completions; feedback loops improve reliability at scale.
- Tools/Products: Orchestration platforms with “watcher” patterns; audit dashboards; policy engines.
- Assumptions/Dependencies: Tolerable latency/cost overhead; robust failure detection; human escalation paths.
- Personalized, on-device assistants trained from user trajectories (Consumer, SMB)
- What/How: Privacy-preserving distillation from a user’s own workflows into compact models that operate their everyday apps reliably.
- Tools/Products: On-device training runtimes; consented trajectory capture; federated learning options.
- Assumptions/Dependencies: User consent and privacy-safe logging; efficient training on edge; safety controls.
- Automated environment construction for proprietary/paid software (Enterprise, Cloud)
- What/How: Secure vendor-provided headless images/simulators for agent training/evaluation; usage metering to respect licensing.
- Tools/Products: “Secure Simulation Enclaves”; license-aware job schedulers.
- Assumptions/Dependencies: Vendor cooperation; legal/licensing frameworks; isolation guarantees.
- Curriculum learning at scale across thousands of apps (Academia, AI R&D)
- What/How: Progressive curricula that teach agents transferable GUI skills; measure generalization to unseen software and workflows.
- Tools/Products: Curriculum generators; difficulty scaffolding; meta-evaluation suites.
- Assumptions/Dependencies: Larger, diverse datasets; memory/planning advances; stable evaluation protocols.
- Policy planning and labor-market forecasting with GDP-grounded models (Policy, Think tanks)
- What/How: Use occupation–software GDP mapping to forecast automation exposure and design targeted upskilling/reskilling programs.
- Tools/Products: “Automation Risk Dashboards”; regional adaptation of GDP pipelines.
- Assumptions/Dependencies: Up-to-date local labor and wage data; uncertainty modeling; stakeholder acceptance.
- Safety-assured deployments in regulated sectors (Healthcare, Finance)
- What/How: Require agents to pass domain-specific long-horizon tests; use privileged-info verification and integrity gates in production; human-in-the-loop policies.
- Tools/Products: “Safety Gateways” for clinical/financial tasks; audit logs for compliance.
- Assumptions/Dependencies: Regulatory approval; validated datasets; robust post-market surveillance.
- Next-gen GUI testing standard supplanting brittle scripts (Software industry)
- What/How: VLM checklist verification becomes the standard for end-to-end UI testing, reducing maintenance and increasing coverage.
- Tools/Products: IDE plug-ins; migration toolkits from Selenium/Appium to checklist-based harnesses.
- Assumptions/Dependencies: Verified VLM reliability; cost controls; standardized test artifacts.
- Human–agent collaborative work with auditor-mediated oversight (Enterprise workflows)
- What/How: Auditors synthesize remaining work and risks for humans and agents, enabling reliable handoffs and shared accountability.
- Tools/Products: Collaboration consoles; provenance-aware task boards; co-pilot/coach pairs.
- Assumptions/Dependencies: UX integration; culture and training; clear escalation policies.
- Global adaptation of selection pipelines beyond the U.S. (International policy, Multinationals)
- What/How: Localize occupation and software mapping, GDP attribution, and software selection to reflect regional economies.
- Tools/Products: Country-specific datasets; multilingual task generation and verification.
- Assumptions/Dependencies: Access to local labor stats; multilingual LLM/VLMs; domain expertise for validation.
Notes on cross-cutting assumptions/dependencies:
- Strong LLMs/VLMs are needed for creation, auditing, task amplification, and verification; quality and cost will affect scalability.
- Verification relies on privileged information extracted from setup scripts; when ground truth is opaque (e.g., proprietary configs), new PI sourcing or hybrid programmatic checks may be required.
- Security and isolation are non-negotiable for production and training, especially with real or sensitive data; network/process/file isolation and audit trails are essential.
- The GDP-grounded selection pipeline is US-focused; applying it elsewhere requires local labor/industry data and may change priorities.
- Windows and Android orchestration can entail licensing or virtualization constraints; plan for legal and technical compliance.
Glossary
- agent-driven environment construction: An approach where autonomous agents programmatically create or configure environments rather than humans doing it manually. "agent-driven environment construction"
- Apptainer: A container runtime (formerly Singularity) commonly used in HPC to run containers without root privileges. "apptainer"
- AUC: In pharmacokinetics, the area under the concentration–time curve, reflecting overall drug exposure. "AUC by 71\%"
- BJD_TDB: Barycentric Julian Date in Barycentric Dynamical Time; a precise astronomical time standard used for timing events like exoplanet transits. "BJD_TDB"
- BRAF inhibitor: A class of cancer drugs that inhibit the BRAF kinase involved in cell growth signaling pathways. "BRAF inhibitor"
- checklist-based VLM verifier: An evaluation method that uses a vision-LLM to score multi-step tasks via a weighted checklist of subtasks for partial credit. "checklist-based VLM verifier"
- Cmax: In pharmacokinetics, the maximum observed drug concentration in plasma after dosing. "Cmax by 33\%"
- context fatigue: Degradation in LLM performance when handling very long prompts, leading to omissions or errors. "context fatigue"
- creation-audit loop: An iterative process where one agent creates an environment and another independently audits evidence of correctness, feeding back issues for refinement. "creation-audit loop"
- CYP3A4: A major human liver enzyme that metabolizes many drugs; its inhibition or induction can cause significant drug–drug interactions. "CYP3A4"
- differential photometry: An astronomical technique that measures a target star’s brightness relative to comparison stars to reduce noise. "differential photometry."
- display forwarding: Routing the graphical output of applications running in containers/VMs to a controllable display so agents (or users) can interact with the UI. "display forwarding"
- enterprise resource planning (ERP) system: Integrated enterprise software that manages core business processes like finance, procurement, and supply chain. "enterprise resource planning (ERP) system"
- frontier model: A state-of-the-art, large-scale AI model at the leading edge of capability. "frontier model"
- gymnasium-style API: An interface patterned after the Gym/Gymnasium RL frameworks, standardizing observations (e.g., screenshots) and actions (e.g., mouse/keyboard). "gymnasium-style API"
- light curve: A plot of an astronomical object's brightness versus time, used to detect events like exoplanet transits. "light curve"
- long-horizon: Describing tasks that require many sequential steps and sustained planning to complete. "long-horizon tasks"
- O*NET: A comprehensive U.S. occupational database providing standardized information on jobs, used here to link software usage to occupations. "O*NET data"
- privileged information: Ground-truth data available to the verifier (e.g., from setup scripts) but not to the evaluated agent, used to assess correctness. "privileged information"
- propose-and-amplify: A generation pattern where a stronger agent creates high-quality seeds and a cheaper model scales them up using in-context examples. "propose-and-amplify strategy"
- readiness polling: Programmatically waiting for services to become available (e.g., via health checks) before proceeding to dependent steps. "readiness polling"
- rootless systems: Execution environments where containers run without elevated (root) privileges, common on shared clusters. "rootless systems"
- sandboxable: Suitable for packaging into an isolated, interactive environment without external accounts, paid licenses, or special hardware. "sandboxable"
- self-hostable: Software that can be deployed and run locally without requiring a managed cloud account. "self-hostable"
- slurm: An open-source workload manager used on HPC clusters to schedule and run jobs. "slurm"
- SOC major groups: The top-level categories in the U.S. Standard Occupational Classification system used to group related occupations. "SOC major groups"
- Vision-LLM (VLM): A model that jointly processes images and text to reason about visual tasks and language instructions. "Vision-LLM (VLM)"
- visual grounding: The process of linking textual references to specific visual elements on the screen to verify UI state or actions. "visual grounding"
- wage bill: Total labor payments for an occupation, computed as employment multiplied by mean wage, used here to estimate GDP contributions. "wage bill"
Collections
Sign up for free to add this paper to one or more collections.

