The Last Human-Written Paper: Agent-Native Research Artifacts
Abstract: Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
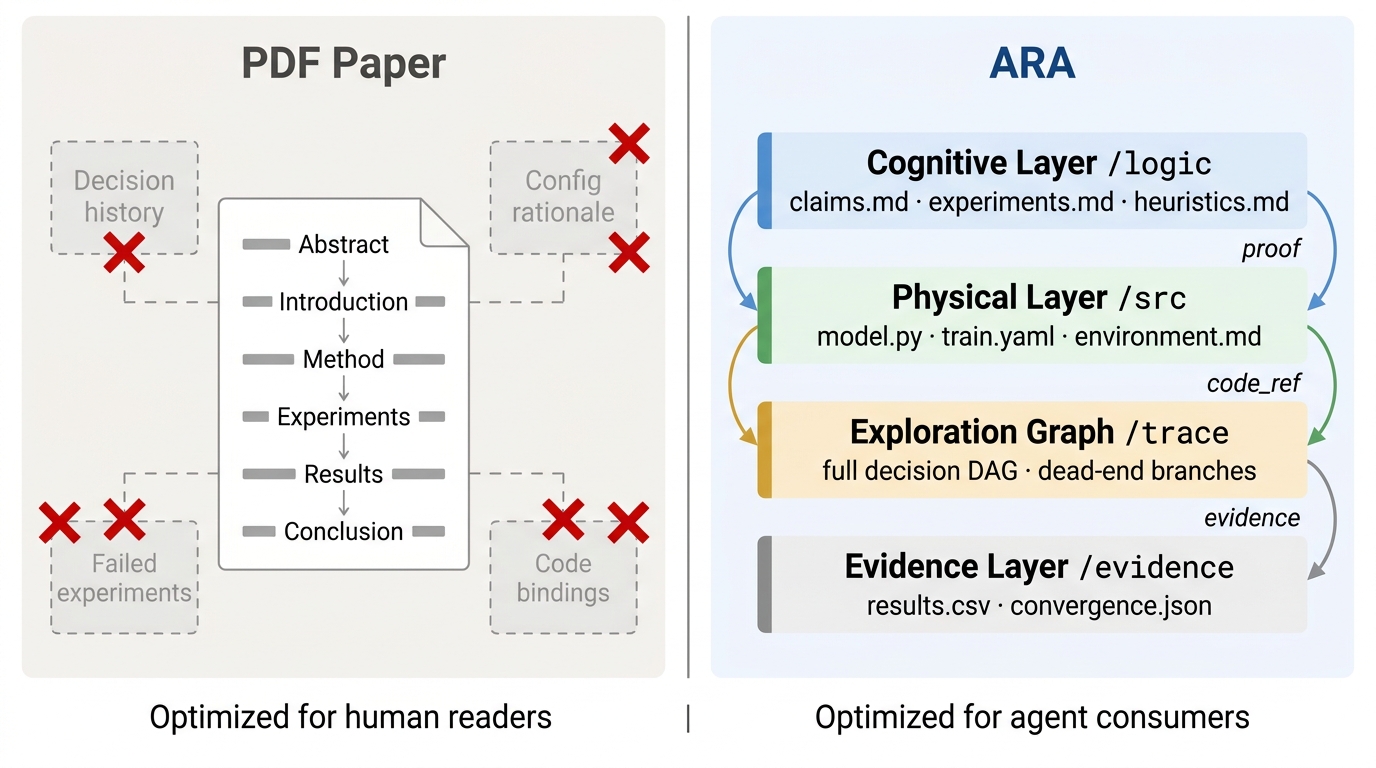
This paper is about changing how science is shared so that both people and AI helpers can truly understand, rerun, and improve it. Today, most research is published as a neat story (a PDF paper). That story leaves out a lot: failed tries, tiny engineering details, and the messy path the researchers took. That’s fine for humans skimming a paper, but it’s a problem for AI tools that need exact instructions. The authors propose a new kind of research package called an Agent‑Native Research Artifact (shortened to “Ara”) that stores science like a well-organized project box the AI can actually operate.
What problem is the paper trying to solve?
The paper says current papers pay two “taxes”:
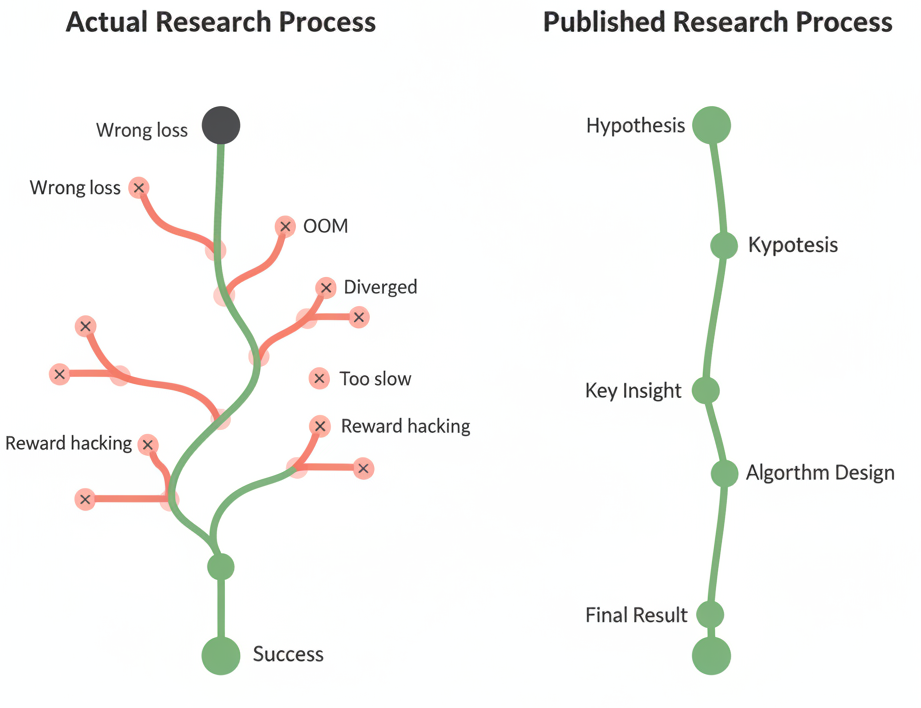
- Storytelling Tax: To make a clean story, papers hide most failed experiments and dead ends. This makes other people (and AIs) repeat the same mistakes, wasting time and money.
- Engineering Tax: Papers and code repositories often skip little-but-important details (like exact settings or “tricks”) that you need to re-run the work.
In simple terms: science papers are like recipes that leave out steps and throw away all the attempts that didn’t work. That’s okay for a nice read, but not for rebuilding the dish.
What are the authors’ goals?
The authors want to:
- Replace the “pretty story” paper with a research package that an AI can run, check, and build on.
- Keep the full research path, including failures, so others don’t waste time repeating them.
- Close the gap between high-level ideas and the exact code and settings needed to make them work.
- Make reviewing research partly automatic, so human experts can focus on judging what’s truly new and important.
How does Ara work? (Methods and approach)
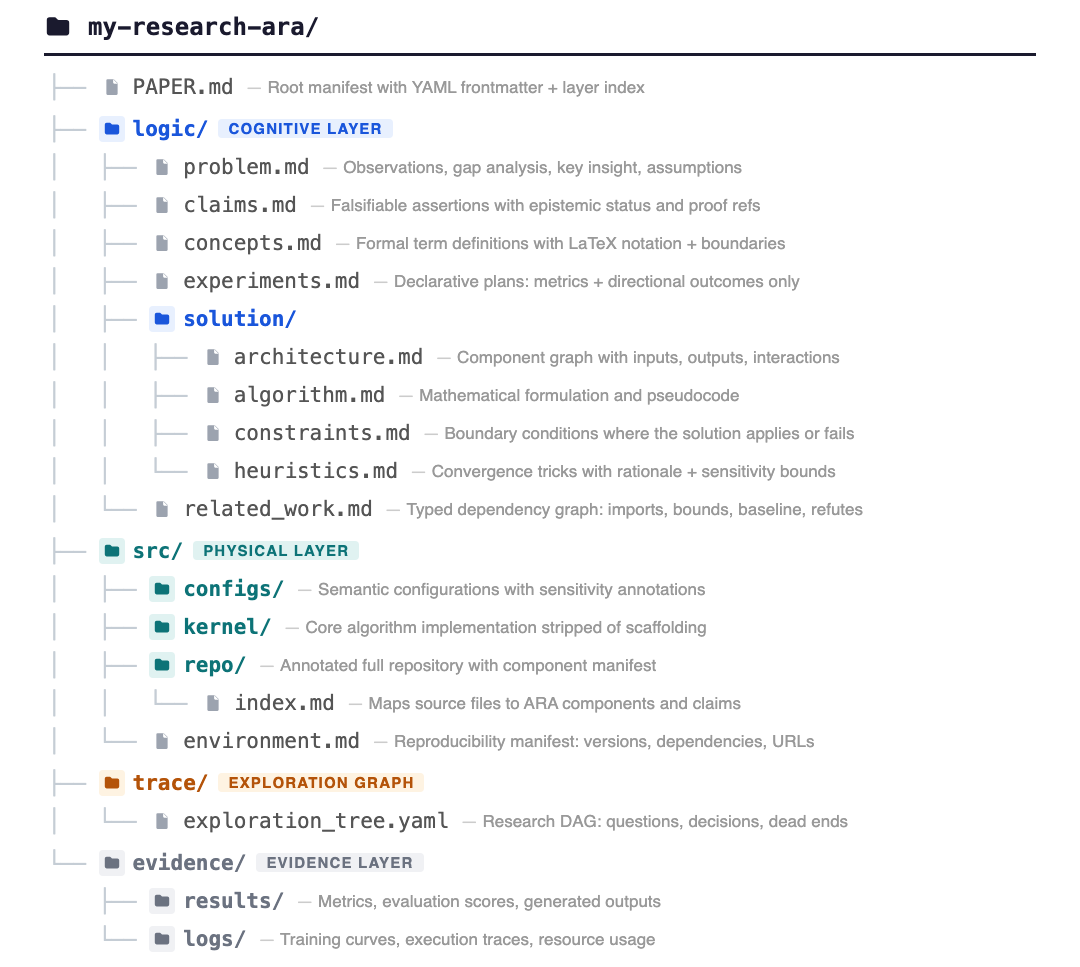
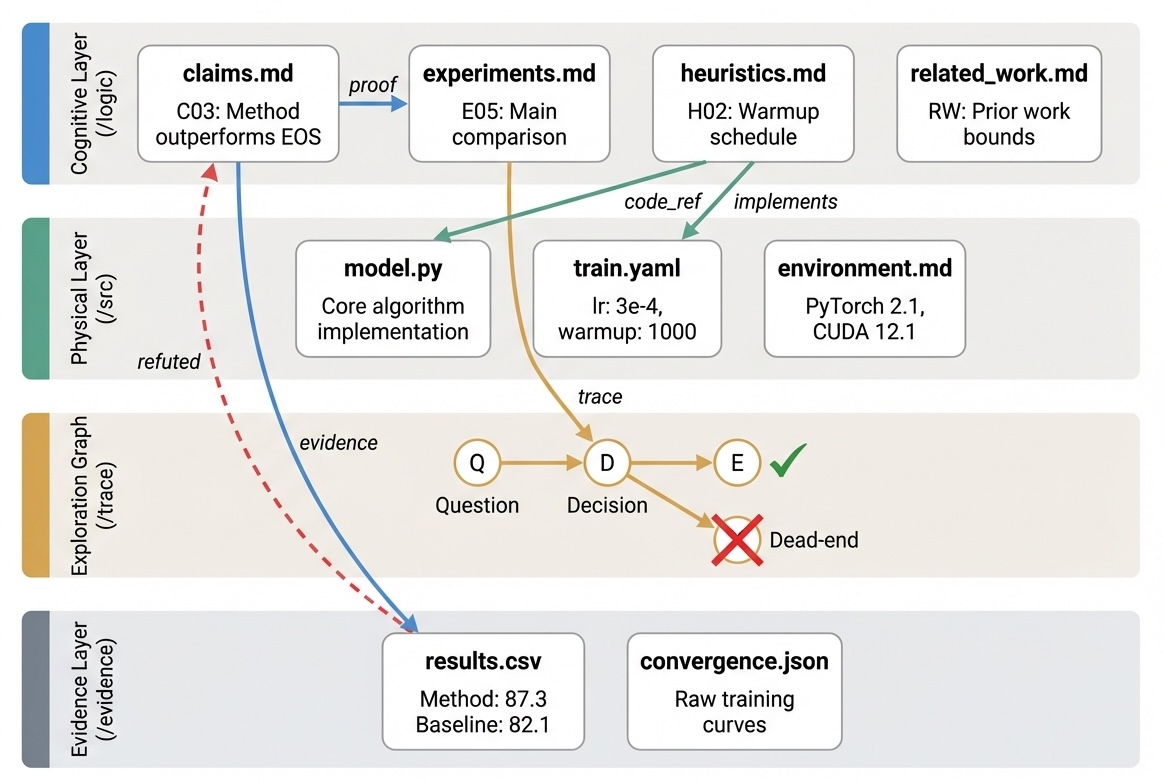
Think of Ara as a research project box with four labeled compartments:
- Logic (the “why” and “what”):
- Clear problem, ideas, claims, and how those claims should be tested.
- Written in short, precise language so an AI can query it easily.
- Code (the “how”):
- The actual, runnable code and every configuration (like exact hyperparameters, versions, hardware).
- Two modes: a small “core” for algorithm papers, or a full repo for systems papers, both well-indexed.
- Exploration graph (the “path taken”):
- A branching map of all the choices, failed experiments, pivots, and lessons learned.
- This is like keeping a map of all turns you tried, not just the final route.
- Evidence (the “proof”):
- Raw numbers, logs, and outputs that back up every claim, with direct links connecting claims → tests → code → results.
To support this new format, the authors build three tools:
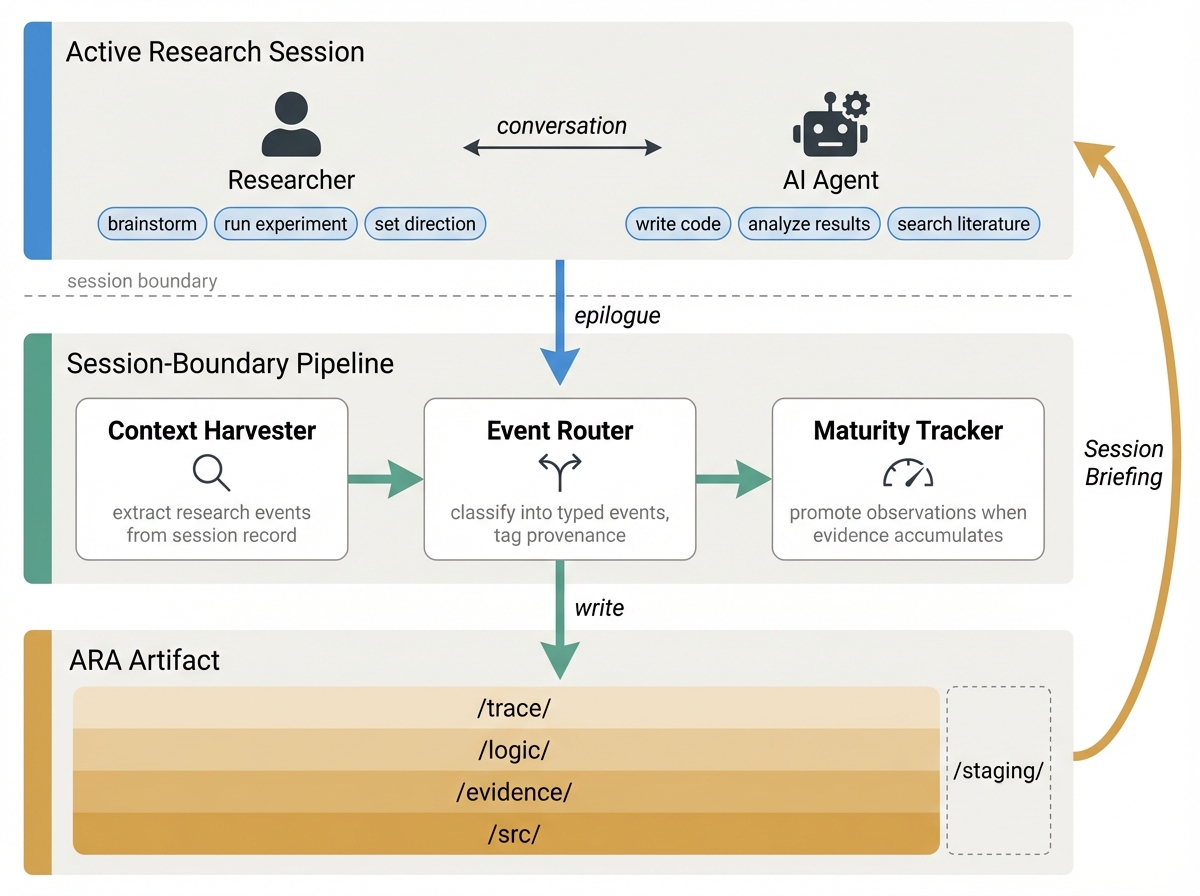
- Live Research Manager: A background helper that watches normal researcher–AI work chats and automatically logs decisions, experiments, and dead ends into the Ara structure. This means researchers don’t have to write extra documentation—the process is captured as they go.
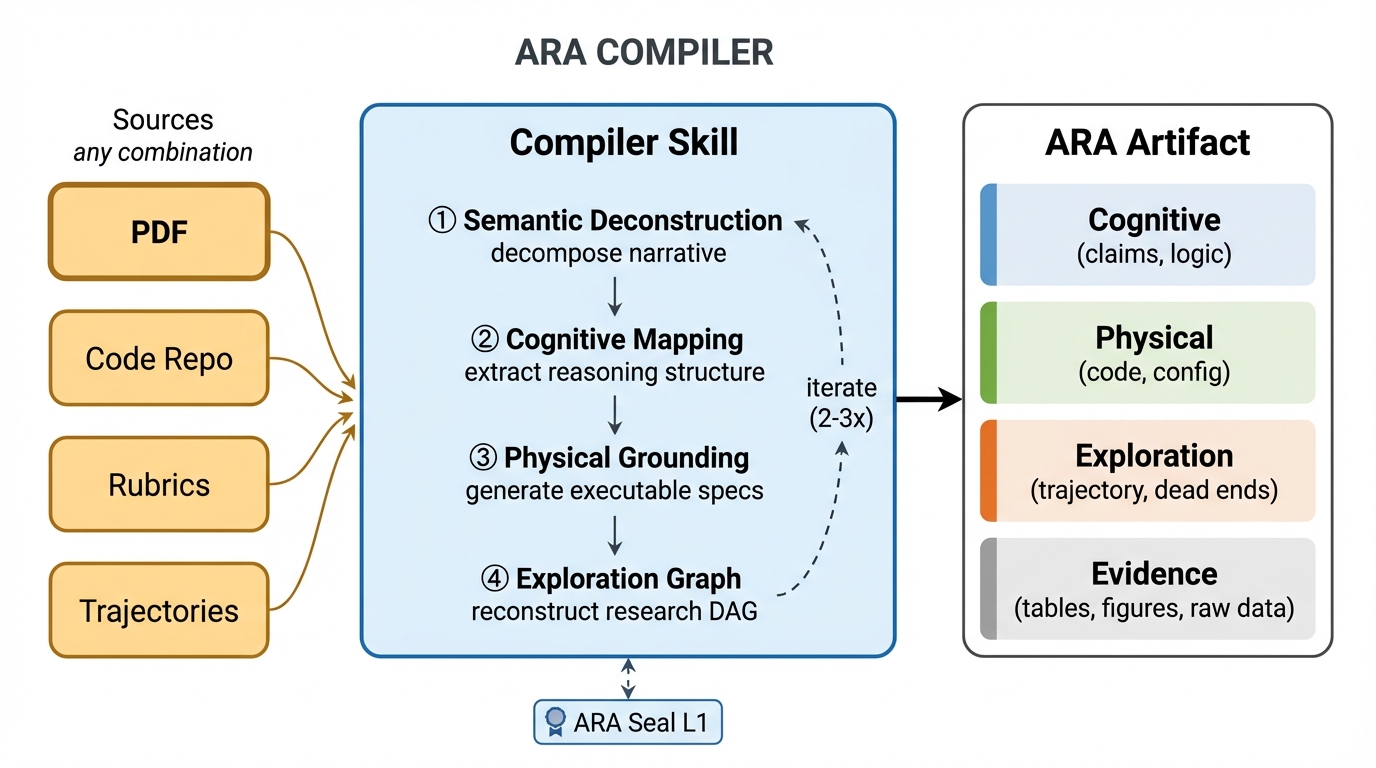
- Ara Compiler: A converter that takes old PDFs, code repos, and experiment logs and turns them into a proper Ara. It reconstructs the links between claims, code, and evidence that are usually scattered across text and appendices.
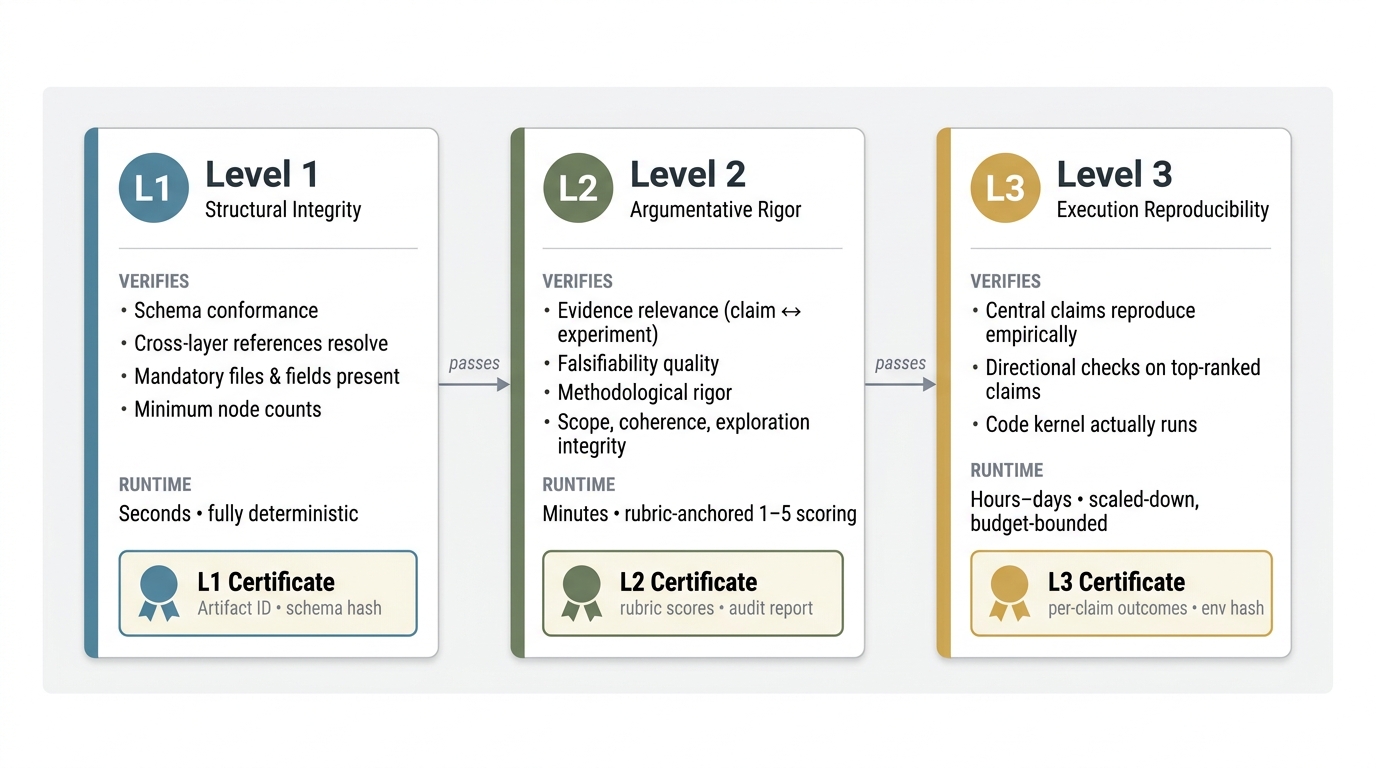
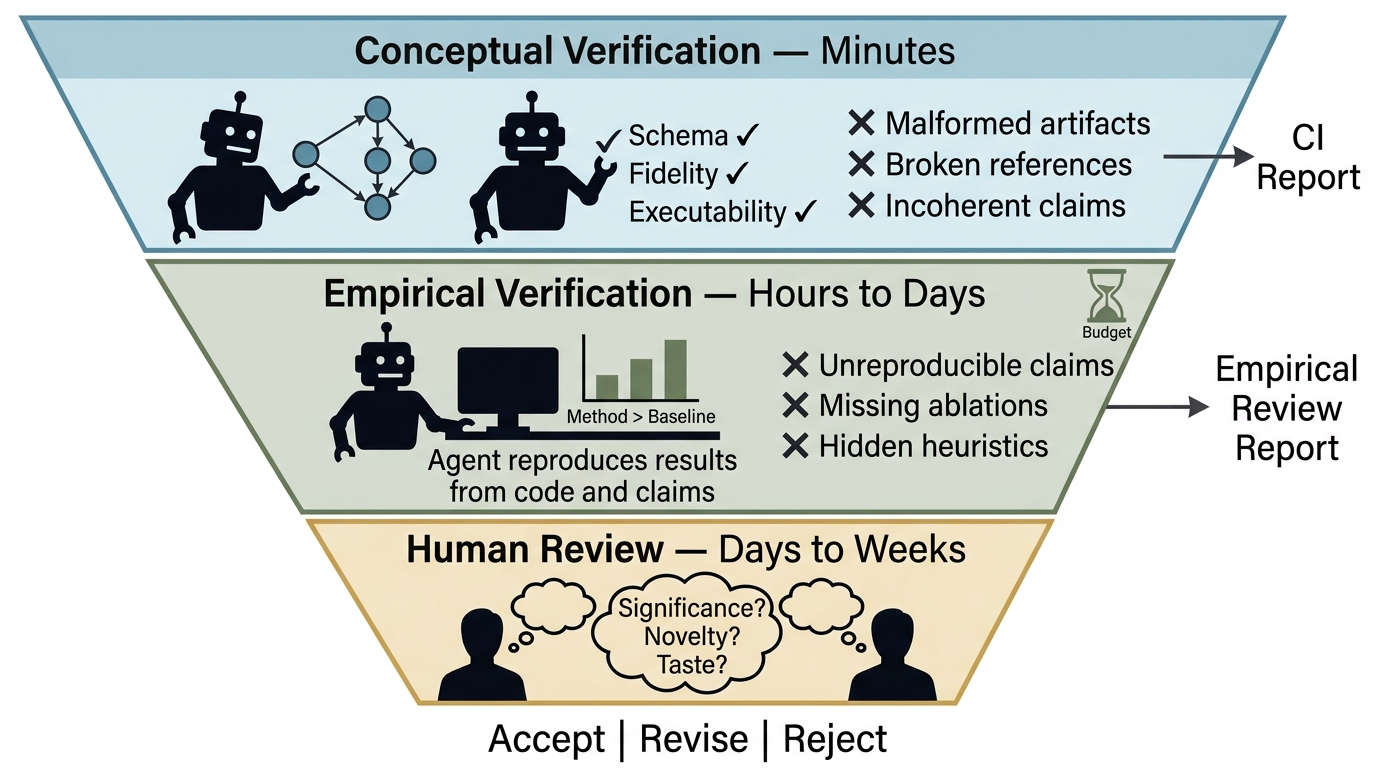
- Ara‑native Review System: An automated checker, called the ARA Seal, with three levels: 1) Structure checks (fast): Is the artifact well-formed and consistent? 2) Argument checks (minutes): Do the claims have appropriate tests and logic—without running code? 3) Reproducibility checks (hours to days): Do scaled-down runs show the claims hold qualitatively?
These machine checks free human reviewers to focus on significance and novelty.
What did they measure and find?
The authors tested Ara in three ways: understanding, reproduction, and extension.
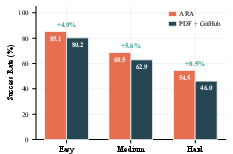
- Understanding: On a benchmark where an AI answers questions about papers (PaperBench), switching from normal papers to Ara boosted accuracy from about 72% to 94%. Reason: Ara’s structure makes answers easier to find and verify.
- Reproduction: On a benchmark where an AI tries to re-run results (RE‑Bench), success went up from about 57% to 64%. This is a meaningful gain in a hard problem, helped by complete settings and linked evidence.
- Extension (going beyond the paper): They gave AIs open-ended tasks building on past work. Keeping the failure traces in Ara sped up progress—AIs didn’t re-try dead ends. However, for very capable AIs, those past traces could sometimes “anchor” their thinking too much, making it harder to explore bold new ideas. In other words, memory of past failures is a compass but can become a fence if the agent is capable enough to jump it.
They also studied the “taxes” in today’s system:
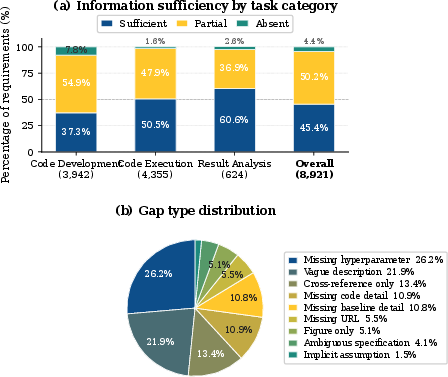
- Only about 45% of details needed to reproduce results were fully specified in typical papers. Code-related details were especially under-specified, and missing hyperparameters alone caused over a quarter of gaps.
- On RE‑Bench, failed runs consumed about 90% of the compute cost. Without access to prior failures, agents waste huge amounts rediscovering dead ends.
Why is this important?
- Better, faster science: Ara turns research into something AIs can execute, not just read. This helps AIs (and people) reproduce results, check claims, and try new ideas more quickly.
- Less waste: By saving failures and exact settings, others won’t waste time repeating the same mistakes or guessing missing details.
- Fairer, clearer review: Automated checks handle the mechanical parts (like “do claims link to evidence?”), so human reviewers can focus on whether the work is truly significant and new.
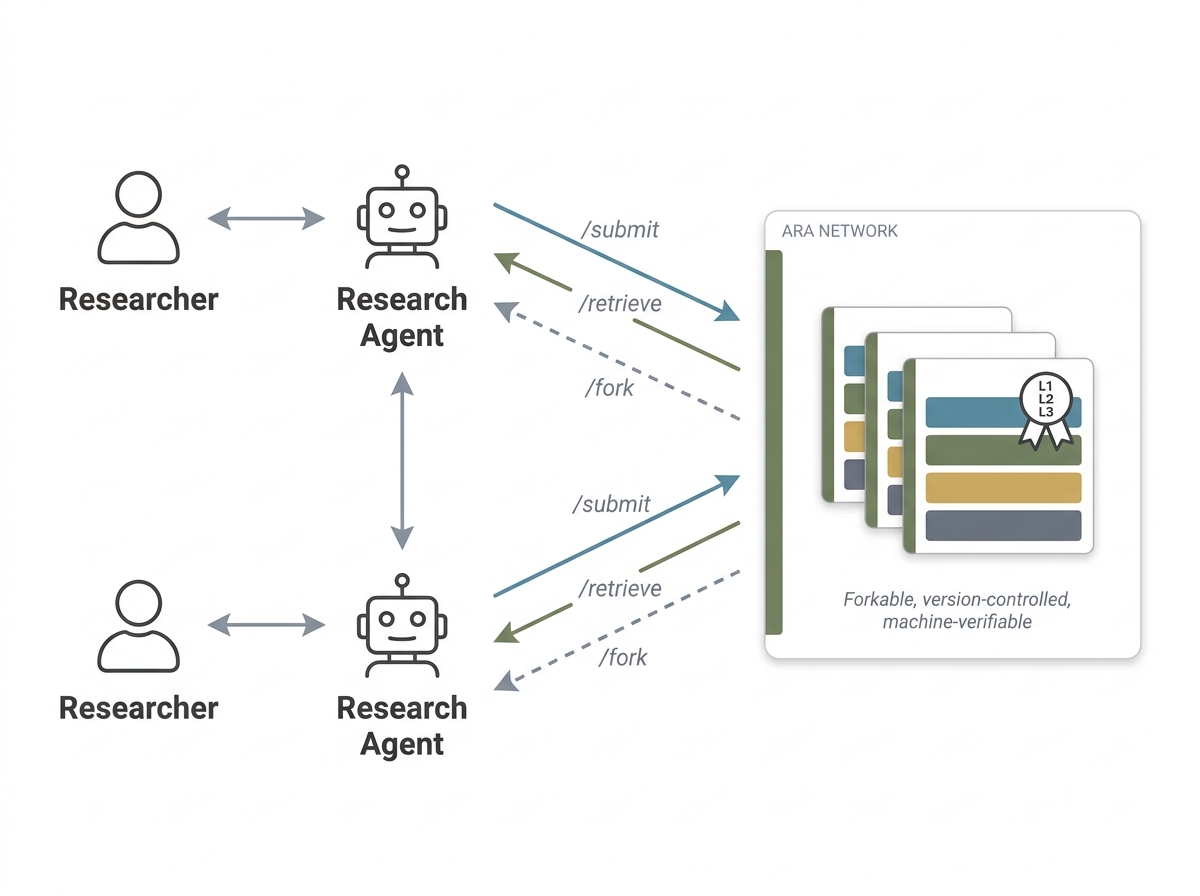
- Science that compounds like software: Because Ara is structured and versioned, projects can be forked, merged, and improved—much like code on GitHub—letting progress build layer by layer.
Simple takeaways and future impact
- Papers won’t go away, but they can become “views” of a richer artifact. Ara’s four layers keep ideas, code, exploration, and proof neatly connected.
- The Live Research Manager removes extra paperwork by capturing the research process as it happens.
- The Ara Compiler lets us convert old work into this new, AI-operable format, so we don’t lose the past.
- The ARA Seal gives fast, machine-checked confidence in structure, logic, and basic reproducibility.
- As AIs become standard lab partners, Ara could make research more reliable, reusable, and collaborative—helping discoveries spread and stack up faster, while freeing humans to do the creative thinking that matters most.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is framed to be actionable for future research.
- Generalization beyond CS code-centric work: how to adapt Ara’s four layers to wet-lab science, robotics, HCI studies, clinical trials, and other domains where “executable code” is insufficient (e.g., instrument protocols, physical calibration data, SOPs, lab notebooks).
- Evaluation breadth and representativeness: validate Ara across more venues, tasks, and disciplines; report per-domain and per-claim-type performance, with large-scale ablations across models, agent frameworks, and artifact complexities.
- Layer-wise causal contribution: rigorously ablate the cognitive, physical, exploration, and evidence layers to quantify each one’s marginal effect on understanding, reproduction, and extension outcomes.
- Comparison to existing standards: head-to-head benchmarks and interoperability mappings versus FAIR, RO-Crate, Nanopublications, and AGENTS.md (conversion fidelity, lineage preservation, operability).
- Anchoring from failure traces: methods to prevent exploration graphs from constraining capable agents (e.g., retrieval policies that diversify, novelty bonuses, mixture-of-explorers, controlled exposure to dead ends); quantify the effect on extension tasks.
- Incentives and adoption: mechanisms for crediting negative results and failure traces, venue policies, reviewer workload models, and author-side cost-benefit analyses that make Ara preferable to PDFs in practice.
- Schema governance and evolution: versioning strategy, backward compatibility plan, namespacing for domain-specific extensions, and community processes for proposing, reviewing, and deprecating schema fields.
- Provenance integrity and tamper-evidence: cryptographic signing, content-addressable storage, trusted timestamps, reproducible builds, and auditable provenance chains from claims to code/evidence to prevent fabrication or post-hoc edits.
- Secure execution for Level 3: formal threat model and reference sandbox (containers, syscall filters, network isolation, least-privilege data access) validated via red-team tests against malicious or booby-trapped Aras.
- Privacy, IP, and licensing: redaction workflows, selective disclosure policies per layer, license propagation/compatibility checks, DP-based logging for sensitive traces, and institutional compliance pathways.
- Live Research Manager fidelity: quantitative accuracy of event extraction, provenance-tagging precision/recall, misclassification repair tools, and UX for human-in-the-loop edits without reintroducing documentation burden.
- Handling sensitive conversations in LRM: encryption-at-rest, local-only modes, retention schedules, audit logs, and granular opt-in/opt-out to protect lab IP and human subjects information.
- Compiler reliability and limits: accuracy benchmarks for PDF→Ara and repo→Ara across styles and venues, hallucination detection, cross-layer binding correctness, confidence scoring, and fallbacks when code/repo is missing or outdated.
- Capability-relative sufficiency: operational thresholds that define “sufficient for reproduction” per task and per agent class; guidance for authors to meet current capabilities and automatically re-assess as models improve.
- Cost and energy footprint: compute budgeting for Level 3, carbon accounting, caching/reuse of prior verifications, fairness mechanisms for resource-limited authors, and policies to triage high-cost claims.
- Evidence storage at scale: policies for retaining large logs and generated artifacts (compression, deduplication, sharding), content-addressable storage, and expiration/archival schedules that preserve reproducibility.
- Interop with data citation: standardized DOIs/handles for datasets, models, and sub-artifacts (claims, experiments), with resolvable lineage and machine-actionable metadata.
- Theoretical contributions: representation of proofs, lemmas, and assumptions in /logic; integration with proof assistants; criteria and tooling for “reproducibility” of theory (mechanized verification vs. informal).
- Non-determinism and hardware variance: robust reproducibility criteria (tolerance bands, statistical tests), seed/hardware pinning across vendors, and procedures to diagnose nondeterministic failures.
- Baseline adequacy and leakage: domain-specific checklists/playbooks that the Level-2 Auditor can consult to flag missing baselines, data leakage, metric misalignment, or under-specified ablations.
- Rigor Auditor validation: inter-rater reliability versus expert humans, calibration methods, domain transferability, and defenses against gaming (adversarial tests that pass Level-2 yet remain unsound).
- Goodharting the Seal: detect/prevent artifacts optimized to pass Levels 1–3 without real substance (e.g., random spot checks, post-acceptance replications, unpredictably sampled full-scale audits).
- Risks of collective inference: evaluate how adding “collective_inference” heuristics affects discovery vs. conformity; governance for promoting/demoting inferred heuristics and preventing ossified groupthink.
- Human readability and pedagogy: quality of compiled narrative views for teaching and dissemination; user studies comparing Ara-derived narratives to traditional PDFs on comprehension and retention.
- Collaboration and concurrency: merge semantics for multi-author/multi-agent edits, especially for the /trace DAG; conflict resolution, fine-grained provenance of edits, and rollback policies.
- Citation and micro-attribution: normative practices and infrastructure for citing Aras, individual claims, experiments, and even dead-end nodes; credit allocation across forks and merges.
- Multilingual support: faithful translation of /logic while preserving formal semantics, cross-lingual retrieval, and multilingual evidence/claims alignment.
- Legal and ethical compliance: embedding IRB/ethics metadata, consent status, export control tags, safety restrictions for models/data, and automated compliance checks during review.
- Artifact identity and lineage: stable IDs, DOI assignment, content hashes, fork/merge lineage tracking, equivalence and derivation relations across versions and derivatives.
- Claim selection for Level 3: principled sampling strategies (by centrality, novelty, risk), criteria to escalate from directional checks to full replications, and safeguards against overstating scale-dependent claims.
- Evidence withholding robustness: protocols ensuring verifying agents cannot glean expected numbers from training or the web (air-gapped verification, controlled corpora, delayed evidence release policies).
- Repository longevity and discovery: sustainable hosting for Aras, indexing/search infrastructure, metadata schemas for discovery, and community curation and deprecation processes.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s tools, drawing directly on Ara’s four-layer protocol, the Live Research Manager, the Ara Compiler, and the ARA Seal (Levels 1–3). Where relevant, each item notes sectors, likely tools/products/workflows, and assumptions/dependencies that could affect feasibility.
- ARA-native internal R&D documentation and knowledge management
- Sectors: software/AI, robotics, medtech, fintech, autonomous vehicles, semiconductors
- What: Replace ad‑hoc READMEs and slide decks with Ara packages that capture claims (/logic), code kernels (/src), exploration graphs (/trace), and raw outputs (/evidence); use preserved failure traces to prevent rediscovery of dead ends and accelerate onboarding.
- Tools/workflows: Live Research Manager as an IDE/chat agent skill; repository “Ara bot” that maintains schema conformance; ARA Seal Level 1 checks as a pre-merge gate; internal “Exploration Graph” visualizer.
- Assumptions/dependencies: Availability of competent coding agents; willingness to expose failures internally; containerized or pinned environments; basic change management for new documentation norms.
- CI/CD reproducibility gates for ML and systems development
- Sectors: MLOps, data platforms, systems software
- What: Add ARA Seal Level 1 (structural integrity) and Level 2 (argumentative rigor) to CI; run budgeted Level 3 “directional” tests as nightly jobs to detect regressions in claims (e.g., “new optimizer still converges faster than baseline on small data”).
- Tools/workflows: “Seal Runner” in CI; evidence-redacted sandboxes for Level 3; auto-open issues when rigor checks fail.
- Assumptions/dependencies: Determinism remains hard in ML—use seeds, hardware hashes, and tolerance bands; compute budgets must be set; containerization required.
- Compliance and model governance with provenance-first audit trails
- Sectors: healthcare (clinical ML), finance (SR 11‑7, model risk), autonomous vehicles, public sector analytics
- What: Use /trace and /evidence to provide end-to-end lineage of decisions, experiments, and outcomes; grant auditors read access to logic/src while withholding /evidence to deter fabrication; attach ARA Seal certificates to model cards.
- Tools/workflows: Governance dashboards showing claim→experiment→evidence chains; redaction tooling for sensitive evidence; policy templates referencing ARA Seal levels.
- Assumptions/dependencies: Regulator acceptance of ARA-style credentials; secure access controls; PII/PHI handling for evidence.
- Legacy research conversion for searchable, operable knowledge bases
- Sectors: academia, publishers, industrial research labs
- What: Batch-compile PDFs/repos into Aras to enable agent-native search over claims, dependencies, and failure modes; improves agent comprehension and Q&A (paper reports 72.4%→93.7% Q&A gain).
- Tools/workflows: Ara Compiler CLI/SaaS; bulk ingestion pipelines tied to institutional repositories; crosswalks to DOIs.
- Assumptions/dependencies: Access to original code/data; quality of legacy PDFs; compiler accuracy depends on source completeness.
- ARA-native peer review triage for venues and funders
- Sectors: scientific publishing, funding agencies, corporate R&D review boards
- What: Run Stage 1–2 pipeline (Seal Levels 1–2) to filter submissions before human review; attach structured rigor reports so reviewers focus on novelty and significance.
- Tools/workflows: Rigor Auditor service with anchored rubrics; track per-claim issues and severities; compute budgets for optional Level 3 spot-checks.
- Assumptions/dependencies: Venue/workflow integration; reviewer training on reading Seal reports; shared sandboxes.
- Classroom and bootcamp assignments as Ara packages with autograding
- Sectors: education (CS, data science, engineering)
- What: Students submit Aras; instructors auto-grade structure (Level 1), argumentative rigor (Level 2), and small-scale reproducibility (Level 3); teach scientific method via exploration graphs and falsifiable claims.
- Tools/workflows: LMS plugin for Seal runs; DAG visualizations for feedback; template Aras for labs.
- Assumptions/dependencies: Faculty buy-in; compute quotas for Level 3; student data privacy.
- Benchmark and dataset releases as Aras to curb regression drift
- Sectors: AI benchmarking, open-source communities
- What: Package task definitions and metrics in /logic and keep gold data in /evidence; use baseline dependencies to auto-detect regressions when PRs land.
- Tools/workflows: Evidence-separated public/private splits; regression bots reading claim graphs; versioned manifests.
- Assumptions/dependencies: Dataset licensing; stable metric schemas; maintainership capacity.
- Research Q&A and dependency-aware retrieval for agents
- Sectors: AI tools, literature discovery platforms, enterprise search
- What: Index /logic, claim graphs, and exploration nodes for agent-native retrieval, enabling precise answers (“which ablations support Claim C3?”) and auto-constructed related-work dependencies.
- Tools/workflows: Ara indexers; semantic search over typed fields; “claim diff” across artifacts.
- Assumptions/dependencies: Sufficient corpus of Aras; metadata consistency; evaluation of retrieval quality.
- Preference-signal curation for training research assistants
- Sectors: AI model training, toolmakers
- What: Extract accept/reject/revise events and lessons from /trace to build high-signal datasets for RLAIF/RLHF on research behaviors and heuristics.
- Tools/workflows: Data pipelines with provenance tags; policy filters; curriculum sampling from exploration graphs.
- Assumptions/dependencies: Data rights for training; careful privacy scrubbing; mitigations against overfitting to prevailing heuristics.
- Cross-team “research diff/merge” to manage parallel exploration
- Sectors: large engineering orgs, research labs
- What: Treat Ara as forkable, diffable units; visualize where teams explored overlapping branches and synthesize pivots.
- Tools/workflows: DAG diff tool; merge strategies for claims and configs; milestone tagging via version control.
- Assumptions/dependencies: Cultural adoption of artifact-first workflow; conflict resolution policies.
- Safety-critical experimentation logging
- Sectors: robotics, autonomous systems, industrial control, energy systems modeling
- What: Record failure modes and lessons as dead_end nodes with reproducible traces; accelerate hazard analysis and safety case preparation.
- Tools/workflows: “Exploration Graph” viewer integrated with incident logging; export to safety case templates.
- Assumptions/dependencies: Alignment with existing safety standards; secure storage of logs; disciplined tagging.
- Citizen science and maker projects with minimal Ara templates
- Sectors: daily life, community labs, hobbyist engineering
- What: Use slimmed-down Aras to plan experiments, log dead ends, and share repeatable builds; community members can reproduce and extend projects reliably.
- Tools/workflows: Web-based Ara wizards; low-code experiment runners; QR-linked evidence bundles.
- Assumptions/dependencies: Simple UX; minimal compute; limited need for strict Level 3.
Long-Term Applications
These opportunities require broader adoption, further research, or scaling efforts (e.g., standardization, regulation, higher-capability agents).
- Venue-wide Ara-native publishing and archiving
- Sectors: scientific publishing, digital libraries
- What: Make Aras first-class publication units with DOIs; PDFs become compiled views from the artifact; long-term archival with reproducibility credentials attached.
- Tools/workflows: Repository-backed submission portals; artifact viewers; persistent Seal certificates.
- Assumptions/dependencies: Community standards; incentives for sharing failures; library infrastructure.
- Regulator-endorsed ARA credentials for high-stakes ML
- Sectors: healthcare, finance, automotive, aviation, public sector
- What: Reference ARA Seal Levels in guidance; require Level 1–2 for filings and Level 3 sampling for deployments; align /logic with safety-case structures.
- Tools/workflows: Compliance playbooks; evidence redaction standards; mapping to GSN/safety case artifacts.
- Assumptions/dependencies: Formal adoption in regulatory frameworks; legal recognition of machine-verifiable credentials.
- Agent ecosystems that fork, extend, and trade Aras at scale
- Sectors: AI platforms, marketplaces, open science
- What: “GitHub for research” where agents discover, fork, and compose Aras; compute-for-credit marketplaces execute Level 3 verification; royalty/attribution via provenance.
- Tools/workflows: Artifact registries; claim-level dependency billing; trust/reputation systems.
- Assumptions/dependencies: IP licensing models; robust sandboxes; governance to prevent plagiarism and low-quality spam.
- Cross-artifact collective inference to surface tacit heuristics
- Sectors: AI tools, methods research, MLOps
- What: Aggregate heuristics/configs across Aras to recommend defaults and highlight anomalies; suggest missing ablations/controls based on community patterns.
- Tools/workflows: Compiler enrichment modules; outlier detectors; “method linting” agents.
- Assumptions/dependencies: Large, diverse corpus; bias controls to avoid homogenizing exploration; opt-in signals.
- Fully or semi-autonomous research loops
- Sectors: foundational AI research, applied R&D
- What: Agents read Aras, generate hypotheses, execute experiments, update /logic and /trace, and propose new artifacts; humans provide oversight on significance and risk.
- Tools/workflows: Closed-loop research IDEs; budgeted exploration managers; red-team/blue-team governance.
- Assumptions/dependencies: More capable agents; safety guardrails; clear human-in-the-loop checkpoints.
- Integrated safety cases and certification pipelines
- Sectors: automotive (ISO 26262), robotics (ISO 10218), medical devices (IEC 62304)
- What: Map Ara claims and evidence to safety-claim structures; maintain live, audit-ready safety cases that evolve with code and experiments.
- Tools/workflows: Schema crosswalks to safety standards; auto-updated safety case documents; certification audit exports.
- Assumptions/dependencies: Standard alignment; third-party certifier tooling; long-term evidence retention.
- Enterprise-wide adoption of Ara-like artifacts beyond research
- Sectors: software engineering, product management, operations
- What: Extend the exploration graph and claim/evidence bindings to design reviews, A/B tests, incident postmortems, and architecture decisions.
- Tools/workflows: “Architecture-Native Artifacts” with decision logs and rollback lessons; ops dashboards with falsifiable hypotheses for changes.
- Assumptions/dependencies: Process change management; integration with existing ALM/ITSM systems.
- Consumer-facing claim verifiers for products and information
- Sectors: media, e-commerce, sustainability reporting
- What: Mini-Ara bundles for product or news claims that link assertions to evidence and methods; apps can display “evidence-backed” badges.
- Tools/workflows: Simplified Seal checks; browser extensions/app integrations; third-party attestations.
- Assumptions/dependencies: Producer participation; UX that conveys rigor without overwhelming users; misinformation adversaries.
- Funding and tenure incentive reform anchored in preserved failure knowledge
- Sectors: academia, government funding
- What: Credit negative results and high-quality exploration traces; evaluate projects on rigor and compounding value, not only positive outcomes.
- Tools/workflows: Metrics dashboards (e.g., reuse of dead_end lessons); portfolio-level Seal statistics; new grant/reporting templates.
- Assumptions/dependencies: Cultural shifts; policy updates; fair-credit attribution.
- Interoperability with FAIR, RO‑Crate, Nanopublications, and AGENTS.md
- Sectors: research data management, standards bodies
- What: Create crosswalks so Aras import/export to existing standards; agents get execution-ready structure without losing archival compatibility.
- Tools/workflows: Converters; ontology mappings; validation suites spanning standards.
- Assumptions/dependencies: Standards convergence; joint working groups; sustained maintenance.
- Sector-specific pipelines that mandate negative results capture
- Sectors: pharmaceuticals/drug discovery, energy grid modeling, climate science
- What: Use /trace to reduce cost of rediscovering failed leads; speed up exploration by sharing dead ends across teams and institutions.
- Tools/workflows: Consortia repositories with confidential evidence access; meta-analysis tools for failure modes.
- Assumptions/dependencies: Data-sharing agreements; IP concerns; privacy/security controls.
Notes on feasibility across all items
- Agent capability dependency: Many benefits scale with coding/reasoning agent quality; however, Level 1–2 checks and structural benefits are useful immediately.
- Compute constraints: Level 3 verification needs budgeted, sandboxed execution; organizations must set realistic policies.
- Privacy/IP: Evidence layers may contain sensitive data; layered access and redaction are necessary.
- Adoption and incentives: Structural change requires venue, funder, and organizational buy-in; aligning incentives (credit for rigor and failures) is critical.
- Reproducibility realities: Hardware/seed variance and nondeterminism remain; use environment pinning, tolerance bands, and directional checks as the paper proposes.
Glossary
- Ablation: An experimental test that removes or isolates components to assess their causal impact on results. "causal claims require isolating ablations, generalization claims require heterogeneous test conditions, improvement claims require baseline comparisons"
- AGENTS.md standard: An emerging documentation format oriented toward AI agents explaining how to use code repositories. "The emerging AGENTS.md standard~\citep{openai2025agentsmd} provides agent-oriented documentation for code repositories but does not address the epistemic structure of research itself."
- Agent-Native Research Artifact (Ara): A machine-executable research package with structured layers for logic, code, exploration history, and evidence. "We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers"
- agent skill: A lightweight, prompt-based capability that turns a general-purpose agent into a domain-specialized one without custom SDKs. "We implement the Live Research Manager as an agent skill~\cite{agentskills2025}"
- agent-sufficient specification: The level of precision and detail required for an AI agent to correctly execute a method, beyond prose for human reviewers. "the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten."
- ARA Seal: A machine-verifiable credential indicating an Ara’s structural integrity, argumentative rigor, and (optionally) execution reproducibility. "We define the ARA Seal as a machine-verifiable credential with three escalating levels"
- Argumentative Rigor: A Level-2 ARA Seal criterion assessing whether claims are epistemically supported by appropriate evidence and logic. "Level 2 -- Argumentative Rigor"
- Baseline: A reference method or system used for comparison to evaluate improvements. "methodological rigor, covering baseline adequacy, ablation coverage, statistical reporting, and metric--claim alignment."
- Code-paper reconciliation: Systematic cross-referencing of a codebase against paper claims to surface undocumented assumptions or tricks. "the agent performs code-paper reconciliation, cross-referencing the codebase against claims to surface tacit knowledge"
- collective_inference: A tag indicating knowledge inferred from patterns across multiple artifacts rather than stated in the current source. "tagged collective_inference so downstream agents can distinguish stated from inferred knowledge."
- Cross-layer reference resolution: Verification that links across layers (e.g., claims to experiments, code to evidence) are valid and consistent. "schema conformance, cross-layer reference resolution, required field completeness"
- Dependency graph: A structured representation of how concepts, claims, or methods depend on each other. "structured scientific logic that distills the paper's conceptual abstractions into queryable claims and dependency graphs"
- Directed acyclic graph (DAG): A graph with directed edges and no cycles, used here to model the research exploration history. "exploration_tree.yaml stores the complete research directed acyclic graph (DAG) as a nested YAML tree"
- Epistemic provenance: Metadata capturing the origin and authorship of knowledge (e.g., user vs. AI) to preserve trust and accountability. "Faithful epistemic provenance: every event is tagged with provenance (user, ai-suggested, ai-executed, user-revised) to preserve epistemic origin."
- Evidence Layer: The Ara layer that stores raw outputs (metrics, logs) grounding each claim. "The Evidence Layer (/evidence)."
- Exploration Graph: The Ara layer preserving the branching research process, including dead ends and pivots. "an exploration graph that preserves the failures compilation discards"
- FAIR principles: Guidelines that data and metadata should be Findable, Accessible, Interoperable, and Reusable. "The FAIR principles~\citep{wilkinson2016fair} mandate findable, accessible data but say nothing about the structure of research arguments."
- Falsifiability: The quality of a claim being framed so it can be tested and potentially refuted by evidence. "falsifiability quality, checking that criteria are actionable, non-tautological, scope-matched, and independently testable without access to proprietary data"
- Forensic bindings: Explicit links connecting claims to their verifying experiments, code, and evidence across Ara layers. "Cross-layer forensic bindings link claims in /logic to evidence in /evidence and code in /src."
- Hyperparameter: A configuration parameter set before training that controls model behavior (e.g., learning rate). "missing hyperparameters alone account for 26.2\% of all gaps"
- Kernel mode: A /src packaging mode that retains only core algorithmic modules with typed interfaces, omitting boilerplate. "Algorithmic contributions use kernel mode: only the core modules with typed I/O signatures"
- Live Research Manager: A background system that captures and structures the research process into Ara without extra documentation burden. "a Live Research Manager that captures decisions and dead ends during ordinary development"
- Manifest (PAPER.md): The top-level Ara file with YAML frontmatter indexing layers to enable quick triage by agents. "rooted in a manifest PAPER.md whose YAML frontmatter and layer index enable an agent to triage relevance in tokens"
- Methodological rigor: The thoroughness and appropriateness of experimental methods, baselines, ablations, and statistical reporting. "and methodological rigor, covering baseline adequacy, ablation coverage, statistical reporting, and metric--claim alignment."
- Nanopublications: Structured, atomized scientific assertions with provenance, not typically including execution details. "Nanopublications~\citep{groth2010nanopub} formalize atomic claims but lack the execution layer needed for reproduction."
- Operational specification: A precise, actionable description of how to run and verify an implementation, beyond high-level prose. "the operational specification needed to execute it."
- Ontology (file-system ontology): A formal, structured organization of concepts—in Ara, a directory schema for research knowledge. "The Agent-Native Research Artifact (Ara) protocol defines a file-system ontology that transforms CS research from a narrative document into a machine-executable knowledge package."
- Pivot: A deliberate change in research direction recorded in the exploration history. "five typed node kinds---question, decision, experiment, dead_end, pivot"
- Progressive disclosure: A design principle where agents load only relevant layers/files to conserve context window resources. "the structure further supports progressive disclosure: agents load only the layers and files relevant to their current task"
- Repository mode: A /src packaging mode that retains the full implementation, annotated to link files to Ara components. "Systemic contributions (CUDA kernels, distributed training, systems architectures) use repository mode: the full implementation is retained but annotated via an index.md manifest"
- Rigor Auditor: An agent that evaluates an Ara’s argumentative rigor using rubric-anchored checks without running code. "a Rigor Auditor agent evaluates whether the content of a Level-1-valid artifact is epistemically sound along six objective dimensions"
- RO-Crate: A standard for packaging research artifacts as archival bundles with metadata. "RO-Crate~\citep{soilandreyes2022rocrate} packages research artifacts as archival bundles, not executable objects."
- Sandboxed coding agent: An agent that executes code in an isolated environment during reproduction checks. "execution reproducibility (hours to days, sandboxed coding agent)."
- Schema conformance: The property that structured files adhere to required fields and formats. "schema conformance, cross-layer reference resolution, required field completeness"
- Structural Integrity: An ARA Seal Level-1 criterion verifying that the artifact is well-formed and internally consistent. "Level 1 -- Structural Integrity"
- Tacit knowledge: Unwritten implementation details (tricks, decisions) that are often learned through experience. "Between the two lies tacit knowledge~\citep{polanyi1966tacit}---algorithmic tricks, implementation decisions, and configuration choices"
- Typed I/O signatures: Explicitly specified input/output types for code modules to enable reliable orchestration by agents. "only the core modules with typed I/O signatures"
- YAML frontmatter: A YAML header section in a Markdown file providing structured metadata. "YAML frontmatter and layer index enable an agent to triage relevance"
- YAML tree: A hierarchical YAML structure used to encode parent–child relationships (e.g., in exploration graphs). "as a nested YAML tree"
Collections
Sign up for free to add this paper to one or more collections.

