- The paper demonstrates a hierarchical multi-agent architecture that orchestrates specialized agents with dynamic error correction, significantly improving experiment reproduction.
- It employs fine-grained task decomposition and a shared workspace to produce modular, reproducible codebases, with performance gains of up to 66.1% over baselines.
- The introduced P2C-Ex protocol achieves a Pearson correlation of r=0.862, validating the framework’s robust evaluation and reducing error propagation.
HiRAS: A Hierarchical Multi-Agent Framework for Paper-to-Code Generation and Execution
Introduction and Motivation
The automation of experiment reproduction from scientific papers remains a pivotal challenge in computational research due to the shortage of accessible codebases and the increasing complexity of methodologies. The paper "HiRAS: A Hierarchical Multi-Agent Framework for Paper-to-Code Generation and Execution" (2604.17745) introduces a hierarchical agentic architecture, HiRAS, specifically designed to address the inherent limitations of prior sequential or weakly supervised multi-agent frameworks in end-to-end experiment reproduction. By analytically structuring agent orchestration and prioritizing error correction and task completeness, HiRAS aims to deliver robust and generalizable performance, confronting challenges such as error cascades, insufficient code structuring, and the reproducibility crisis affecting contemporary machine learning research.
Framework Architecture
HiRAS decomposes the reproduction workflow into fine-grained, phase-specific tasks, allocated to specialized agent roles—planning, analysis, code generation, and code execution. Each agent operates with a curated toolset and context, interacting within a shared workspace allowing effective artifact exchange. The workflow is coordinated and supervised by hierarchical manager agents with global visibility and explicit authority to (re)invoke subordinate agents, dynamically adjust plans, correct errors, and verify intermediate outputs. The orchestration logic establishes a tree-structured execution pathway, ensuring progressive refinement of outputs and targeted error recovery.
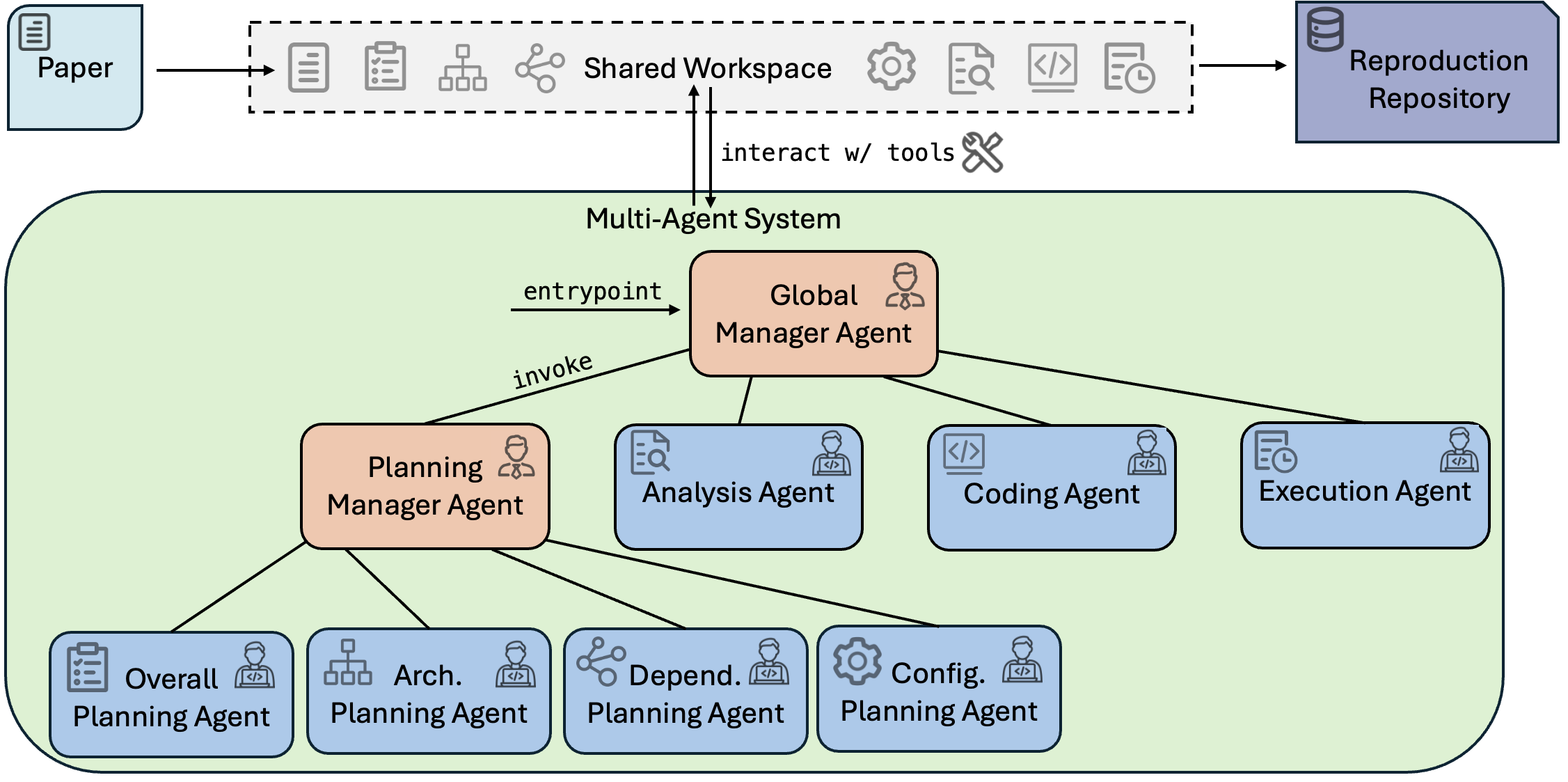
Figure 1: Overview of the HiRAS framework, showing fine-grained phase decomposition, specialized agents, and proactive hierarchical manager agents coordinating via a common workspace.
Supervisory manager agents are critical for global consistency and robustness. They actively inspect outputs, detect incompleteness or hallucinations, and initiate corrective cycles. This architecture stands in stark contrast to pipelines where agent invocations are rigid and early-stage failures propagate unchecked.
Methodological Contributions
HiRAS delivers several methodological advances:
- Hierarchical Supervision: Unlike passive mediatory designs (e.g., AutoGen, Feudal Managers), HiRAS manager agents possess inspection and invocation privileges enabling them to enforce completeness, verify correctness, and resolve conflicts throughout the workflow lifecycle.
- Granular Task Decomposition: Plans are broken down into detailed implementation, architectural, dependency, and configuration sub-phases. This not only reduces cognitive load per agent but aligns artifacts (e.g., code modules, tests) with reproducibility requirements for complex machine learning pipelines.
- Dynamic Corrective Invocation: By maintaining shared memory and global visibility, HiRAS manager agents re-invoke sub-agents with targeted instructions for refinement or error resolution in response to feedback from execution or inter-agent reports.
- Structured Shared Workspace: All specialized agents utilize file-system abstractions to read/write artifacts, supporting reproducible and auditable workflows.
Evaluation Protocols: Benchmarks and Metrics
The framework is rigorously evaluated on PaperBench (Starace et al., 2 Apr 2025), a benchmark comprising ICML 2024 papers with curated rubrics for code, execution, and result fidelity; and Paper2Code (Seo et al., 24 Apr 2025), targeting end-to-end codebase synthesis from paper texts. Evaluation is conducted using both open-source (Qwen3-Coder-480B (Yang et al., 14 May 2025), DeepSeek-v3.1-Terminus (DeepSeek-AI et al., 2024)) and proprietary (Claude-Sonnet) LLM backbones, ensuring results are not conflated with model bias.
The authors exposed a critical deficiency in the original reference-free evaluation protocol of Paper2Code—LLM-as-a-judge metrics, when given limited context, erroneously inflated scores for trivial or none-code repositories due to evaluator hallucination. To correct for this, the authors proposed Paper2Code-Extra (P2C-Ex), which augments the prompt with repository-level metadata (e.g., file count, structure), sharply increasing correlation with reference-based evaluation and expert human assessment.
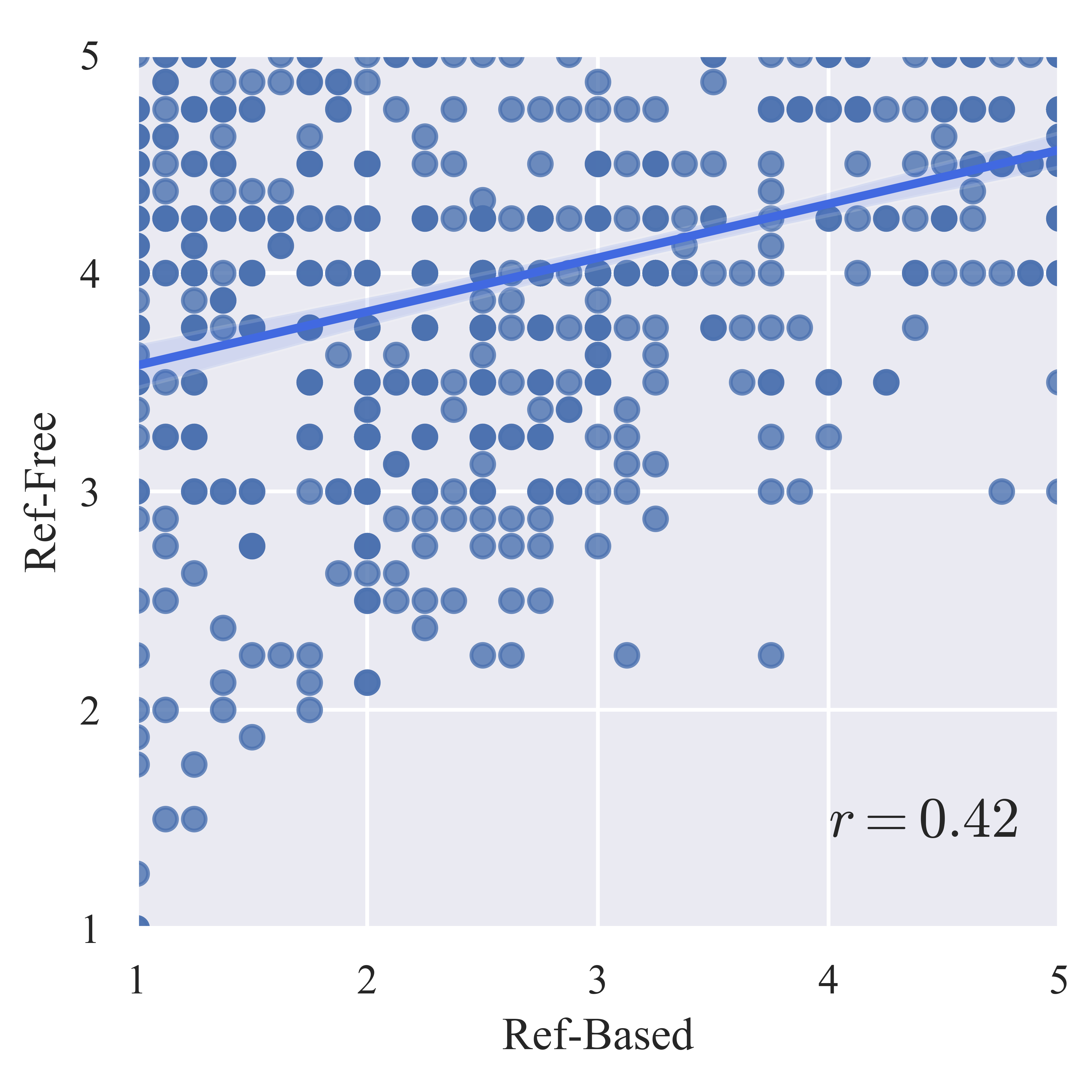
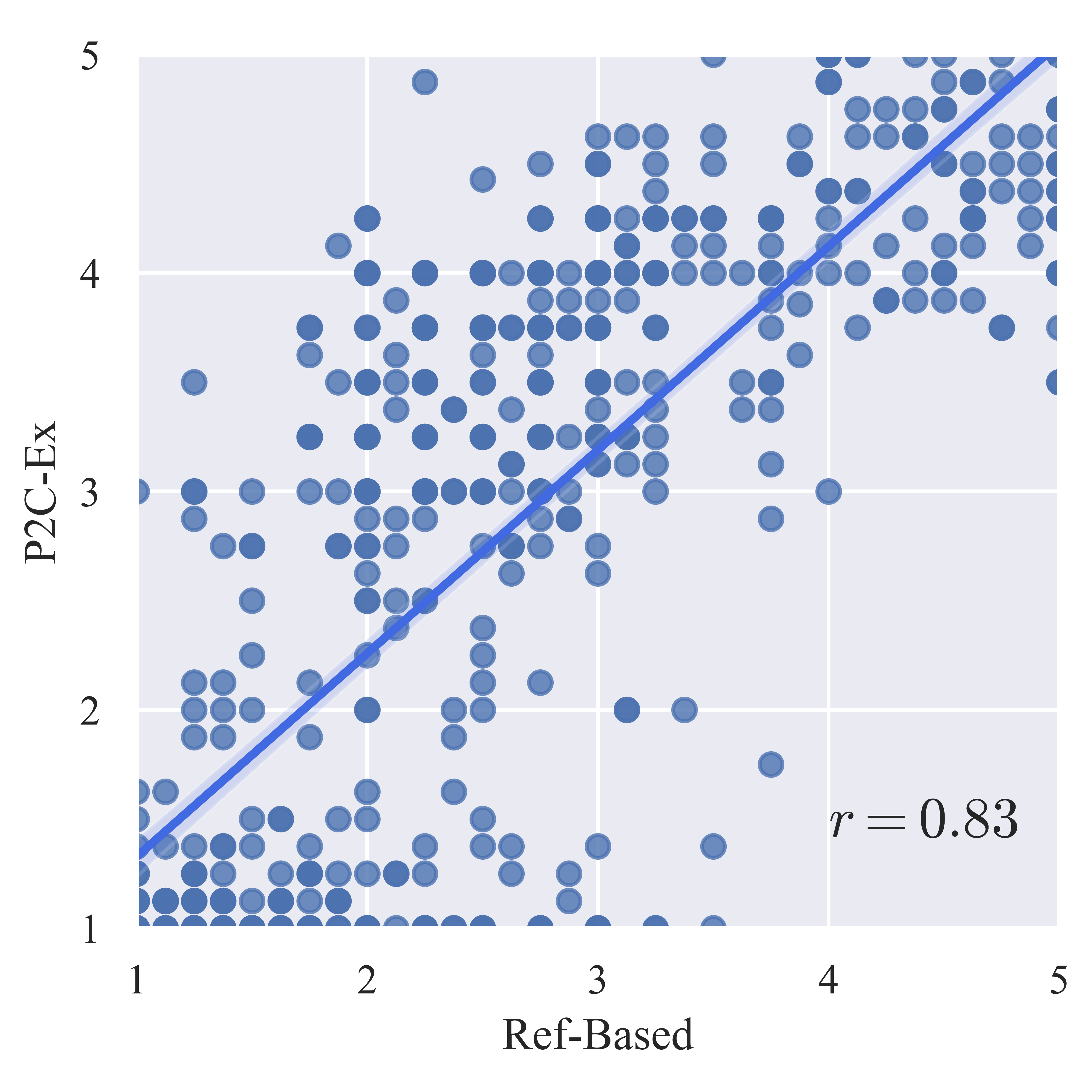
Figure 2: Comparisons of Reference-Based vs. Reference-Free evaluation—demonstrating poor reliability of reference-free without repository structure signals, and the effectiveness of the P2C-Ex protocol.
Quantitative Results
HiRAS demonstrates consistently higher performance relative to prior baselines in both code development and full experiment reproduction evaluations. Salient results include:
- On PaperBench-CodeDev (using DeepSeek-v3.1), HiRAS achieves 57.4%, outperforming PaperCoder (40.8%) and AutoReproduce (41.5%). When using Qwen3, HiRAS achieves 45.7% versus PaperCoder's 36.9%.
- With proprietary Claude-Sonnet, HiRAS attains 64.1%, surpassing baselines reliant on commercial APIs.
- On the full PaperBench (requiring both code and successful program execution), HiRAS maintains substantial lead, with improvements of 25.7–66.1% over the strongest baselines depending on backbone.
- On Paper2Code, HiRAS outperforms comparable methods under both reference-based and robustified reference-free protocols, with the implemented P2C-Ex metric yielding Pearson correlation r=0.862 with the reference-based gold standard, a significant improvement over prior protocol alignment (r=0.423).
These results validate that HiRAS's explicit hierarchical supervision mechanism yields superior reproducibility, error mitigation, and generalization, especially as open-source LLMs narrow the gap with proprietary models.
Empirical Analysis: Case Studies and Failure Modes
Direct comparison of code repositories produced for the same target paper demonstrates that HiRAS generates modular, auditable, and robust codebases, whereas baselines (PaperCoder, AutoReproduce) tend to yield flatter structures with greater frequency of underspecified modules, missing inter-file dependencies, and runtime errors. Qualitative analysis reveals that HiRAS's manager agents frequently intervene to request plan or artifact refinements, resulting in more explicit experimental milestones and architectural rigor.
The dominant failure mode identified in HiRAS is the execution phase, rather than code generation; execution errors are predominantly attributable to subtle inter-file dependencies and inadequate module integration, especially in complex repository layouts—this is precisely where hierarchical error correction is most exploited.
Theoretical and Practical Implications
The principal contribution of HiRAS is the demonstration that hierarchical, proactive supervision in multi-agent LLM systems deeply enhances reproducibility, reliability, and autonomy in scientific experiment reproduction. This design reduces uncorrected error propagation, supports modular task expansion, and enables meaningful evaluation improvements through meta-evaluation robustification (P2C-Ex). The consistent lead over both baseline and state-of-the-art frameworks underscores the emergent necessity of active supervision and dynamic task reallocation in agentic research pipelines.
Practically, HiRAS may serve as a blueprint for future automated scientist systems, especially in settings demanding rigorous artifact tracing and iterative refinement, such as algorithmic benchmarking, distributed scientific research, and codebase curation for open science. The protocol improvements for reference-free evaluation metrics have direct impact on reproducibility benchmarks, potentially influencing their adoption in the broader community.
Directions for Future Research
Open avenues for exploration include:
- Integration of hetero-LLM hierarchies to exploit ensemble effects and model-specific strengths;
- Learning-based manager policies, possibly leveraging reinforcement or imitation learning for invocation strategies;
- Expanding agent toolsets for automated environment provisioning, dataset acquisition, and hardware configuration;
- Transferability analyses to measure generalization from mainstream ML methodologies to other scientific domains (e.g., biomedical, physical sciences);
- Incorporation of human-in-the-loop feedback for constraint satisfaction and adaptive reward modeling.
Conclusion
HiRAS introduces a new paradigm for agent-based experiment reproduction by leveraging hierarchical multi-agent orchestration with explicit managerial supervision. The empirical results, ablation studies, and detailed analysis collectively demonstrate its superiority over previous multi-agent and sequential agent pipelines. The parallel introduction of a robustified evaluation protocol (P2C-Ex) further strengthens the reliability and interpretability of automated paper-to-code systems, marking a significant methodological advancement for agentic scientific AI and reproducibility research.