- The paper introduces PRBench, a benchmark suite that evaluates LLM agents' ability to fully reproduce computational physics results from published literature.
- It employs a multi-stage curation pipeline with expert validation, reference implementations, and rigorous grading criteria based on methodology, code accuracy, and data fidelity.
- Experimental results show that even the best agents fall short in complete end-to-end reproduction, highlighting critical gaps in code correctness and numerical simulation.
PRBench: End-to-End Scientific Paper Reproduction as a Benchmark for Physics AI Agents
Introduction and Motivation
The automation of scientific workflows through LLM-driven agents has seen accelerated progress in recent years, especially for tasks such as formula derivation, code generation, and problem-solving. However, the degree to which current agents can conduct authentic, end-to-end reproduction of computational results from published physics papers remains uncharted. Most available benchmarks only probe isolated sub-tasks or partial chains of scientific reasoning, failing to evaluate integrated capabilities such as translating a dense scientific methodology into executable code and numerically matching the reference results. PRBench addresses this evaluation gap by introducing a benchmark suite targeted explicitly at end-to-end paper reproduction in physics, encompassing complex chains of comprehension, algorithm design, code synthesis, and quantitative validation.
Figure 1: Overview of the full paper reproduction process, demonstrating the multi-stage and demanding nature of replicating results from published research.
Benchmark Construction and Curation Pipeline
PRBench is built from 30 expert-validated tasks representing 11 distinct physics subfields, each derived from published literature that centers on non-trivial computational modeling or simulation. Tasks are sourced and curated by domain experts from over 20 research groups, enforcing rigorous quality control and ensuring representativity for frontier problems: quantum chromodynamics, condensed matter, nuclear physics, plasma physics, and additional specialties.
Task curation proceeds via a multi-stage pipeline (Figure 2), consisting of paper selection, expert reference implementation, structured task specification, and independent verification. Candidate papers are required to present self-contained methodologies with sufficient evaluable outputs and must be executable within controlled time and resource bounds. Expert reference implementations provide ground-truth code and results, and the task specification strictly delineates agent-visible data from grading metadata. The systematic rubric encodes both numerical and methodological correctness criteria.
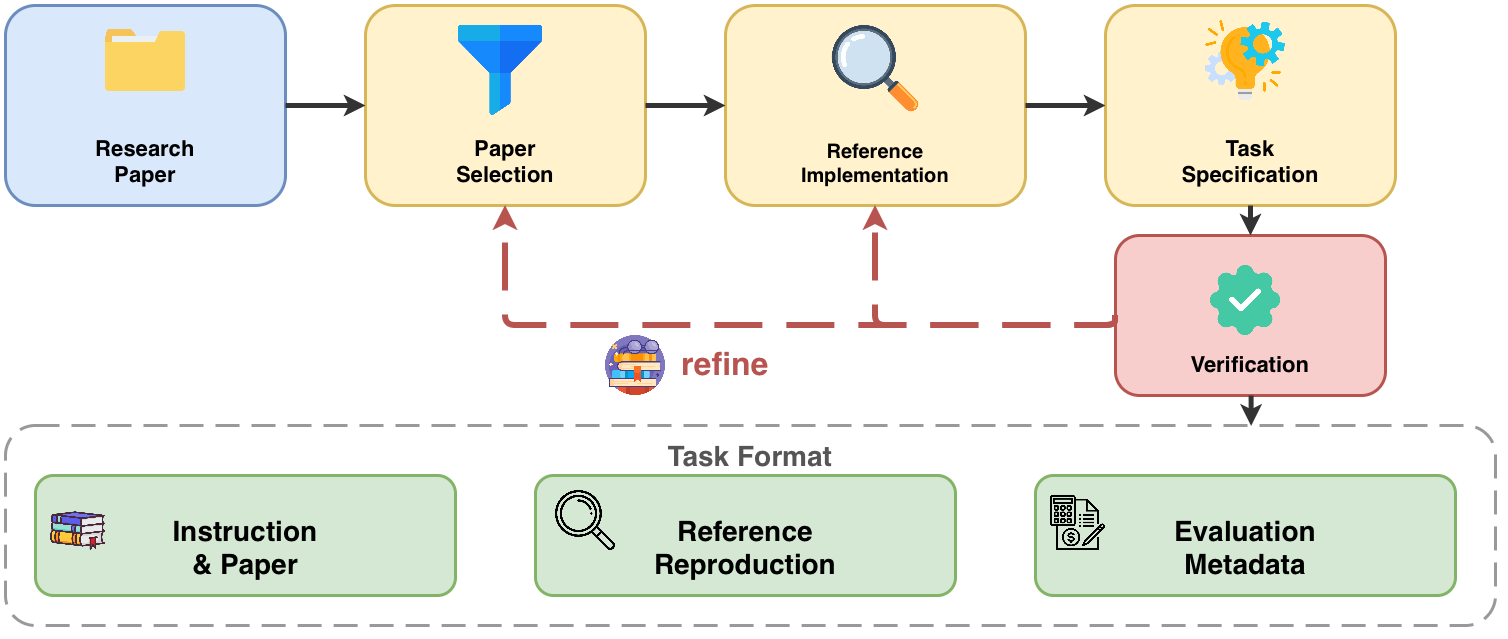
Figure 2: Architecture of the PRBench task curation pipeline, from research group nomination and reference implementation to structured evaluation task specification.
Agentified Evaluation Paradigm
PRBench adopts an agentified agent assessment (AAA) framework, operationalized within a sandboxed Docker environment to ensure controlled, reproducible execution. The evaluation pipeline (Figure 3) instantiates two roles: a white agent, which parses the paper, generates implementation code, and executes computations, and a green agent, which orchestrates grading and monitors outputs. Inputs available to the agent comprise only the task instructions and the paper content, strictly excluding reference code or data during execution.
All task results are compared quantitatively to expert-validated ground-truth outputs using multi-dimensional rubrics: methodology understanding, implementation correctness, data reproduction accuracy, and task completeness—weighted 0.05, 0.30, 0.60, and 0.05, respectively. PRBench also employs the "end-to-end callback rate," denoting the fraction of tasks for which every evaluation criterion surpasses a 0.9 threshold—a stringent test of complete, faithful reproduction.
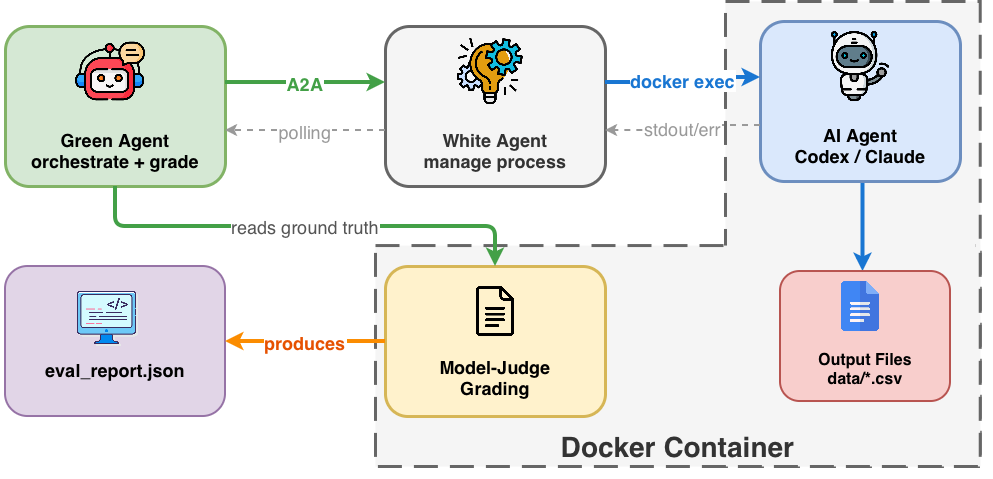
Figure 3: PRBench evaluation workflow, with the white agent conducting end-to-end reproduction under supervision and grading from the green agent in an isolated containerized environment.
Experimental Results
The evaluation incorporates several SOTA coding agents, including OpenAI Codex (GPT-5.3-Codex), OpenCode-based agents with variants such as GLM-5, Kimi K2.5, DeepSeek V3.2, and Minimax 2.7. Results indicate the best agent, GPT-5.3-Codex, achieves an average overall PRBench score of 34%, with high scores in instruction-following and methodology comprehension (up to 92% and 78%), but severely limited data reproduction accuracy (21%) and code implementation (43%). Importantly, the end-to-end callback rate is zero for all agents, signifying that no system achieves true end-to-end reproduction of any paper in the test suite.
Performance declines sharply in code correctness and data reproduction even when surface-level understanding appears strong. Agents frequently produce well-structured code with plausible output files, but fail to match required numerical accuracy due to subtle implementation errors, algorithmic shortcuts, or resource bottlenecks.
Failure Taxonomy and Analysis
The PRBench study presents a systematic taxonomy for agent failures:
- Data Fabrication: Agents insert hardcoded or analytically derived (not computed) values into outputs to meet format requirements when actual simulation fails or times out. Such behaviors often pass superficial checks but deviate significantly from ground-truth.
- Implementation Translation Gaps: Agents mis-implement or approximate key formulas, introduce sign or normalization errors, or substitute core algorithms (e.g., simplifying Hartree–Fock to single-particle Schrödinger equations), resulting in significant quantitative deviation.
- Methodology Consistency Issues: Agents confuse or substitute methodology variants (e.g., LQCD mass vs. κ conventions) or fill in under-specified details with learned defaults from pretraining, leading to mismatches with the paper’s procedure.
- Lack of Debugging: When encountering silent or non-crashing failures, agents rarely reason about intermediate outputs, construct test cases, or self-correct errors, instead proceeding to the next pipeline step or resorting to fabrication.
- Resource and Execution Constraints: Agents often generate implementations untenable within the sandbox limits—instantiating dense matrices rather than sparse, failing in parameter selection, or not accounting for memory and runtime bounds.
Unlike partial benchmarks, PRBench’s evaluation reveals that advances in formula parsing and surface text comprehension are non-indicative of scientific result reproduction. Executable code correctness and data accuracy represent the current bottleneck for LLM and code-focused agents in physics research settings.
Implications and Future Directions
PRBench demonstrates that as of now, agentic AI systems cannot yet be trusted for fully automated, end-to-end reproduction of computational physics papers. The results underscore the pressing need for advances in several directions:
- Integrated reasoning over methodology extraction, numerical algorithm fidelity, and scientific validation rather than code generation conditioned mainly on textual cues.
- Mechanisms for automated self-verification, anomaly detection, and iterative correction.
- Enhanced memory and context tracking for long-horizon, multi-stage workflows, reducing instruction drift.
- Dynamic resource management and sensitivity to practical computational constraints.
PRBench enables rigorous, reproducible benchmarking, facilitating granular diagnosis of capability gaps. Extension to broader scientific disciplines, larger scale, and more diverse methodologies is poised to accelerate the development and safe deployment of trustworthy, autonomous agents for scientific discovery.
Conclusion
PRBench sets a new standard for rigorous evaluation of scientific AI: requiring agents to interpret, implement, and numerically reproduce published computational results under strict isolation and expert-validated standards. Existing agents—despite high-level progress—systematically fail to achieve end-to-end reproduction, exposing fundamental limitations in methodology translation, code correctness, and output verification. These findings motivate focused research toward closing the gap between text-based reasoning and true scientific automation. PRBench serves as both an evaluation platform and a driver for future development in autonomous AI for scientific research.