AI-Researcher: Autonomous Scientific Innovation
Abstract: The powerful reasoning capabilities of LLMs in mathematics and coding, combined with their ability to automate complex tasks through agentic frameworks, present unprecedented opportunities for accelerating scientific innovation. In this paper, we introduce AI-Researcher, a fully autonomous research system that transforms how AI-driven scientific discovery is conducted and evaluated. Our framework seamlessly orchestrates the complete research pipeline--from literature review and hypothesis generation to algorithm implementation and publication-ready manuscript preparation--with minimal human intervention. To rigorously assess autonomous research capabilities, we develop Scientist-Bench, a comprehensive benchmark comprising state-of-the-art papers across diverse AI research domains, featuring both guided innovation and open-ended exploration tasks. Through extensive experiments, we demonstrate that AI-Researcher achieves remarkable implementation success rates and produces research papers that approach human-level quality. This work establishes new foundations for autonomous scientific innovation that can complement human researchers by systematically exploring solution spaces beyond cognitive limitations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Overview
Based on the paper “AI-Researcher: Autonomous Scientific Innovation” and its companion benchmark “Scientist-Bench,” the following applications translate the system’s findings, methods, and innovations into practical, real-world use. The items are grouped by time horizon and linked to relevant sectors, with assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed with current LLMs, code execution sandboxes, and existing research workflows.
- AI research copilot for corporate R&D (Software/AI, Robotics, Energy, Finance)
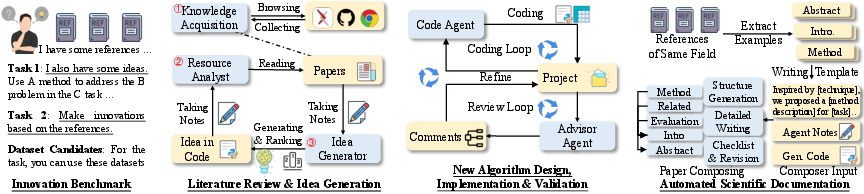
- What it does: End-to-end assistance for literature triage, hypothesis generation, plan-to-code implementation, self-debugging, rapid prototyping, and experiment reporting—mirroring the paper’s Knowledge Acquisition, Resource Analyst, Code Agent, Advisor Agent, and Documentation Agent pipeline.
- Tools/workflows: Internal “ResearchOps” portal; secure Dockerized sandboxes; repo mining from GitHub; RAG over LaTeX sources; multi-stage refinement loops; automatic LaTeX/PDF manuscript drafts for technical memos.
- Dependencies/assumptions: Access to high-quality LLMs (e.g., Claude/GPT), curated reference sets and datasets, internal governance for safe code execution, and license-aware code retrieval.
- Reproducibility and SOTA replication service (Academia, Software/AI)
- What it does: Automated reproduction of target papers using Scientist-Bench-style inputs (references, dataset, anonymized instructions), code verification, and pairwise quality assessment aligned with ICLR-like criteria.
- Tools/workflows: “Autonomous Reproduction Bot”; code correctness and completion metrics; pairwise LLM review panels with random-swap debiasing.
- Dependencies/assumptions: Stable compute budget; access to datasets; reliable repo quality; human-in-the-loop for final sign-off.
- Literature-to-code mapping for engineering teams (Software/AI, Robotics)
- What it does: The Resource Analyst maps math formulations to code implementations across repos, helping teams identify canonical implementations, component-level dependencies, and integration points.
- Tools/workflows: “Math-to-Code Mapper” reports; component decomposition; cross-repo dependency graphs.
- Dependencies/assumptions: Availability of LaTeX sources and high-quality repositories; domain adaptation prompts.
- Autonomous technical documentation and manuscript drafting (Academia, Publishing, Software/AI)
- What it does: Hierarchical draft generation from code, logs, and results into consistent, publication-quality documents (internal whitepapers, arXiv drafts, technical design docs).
- Tools/workflows: Documentation Agent; three-phase hierarchical writing; section consistency checks; template libraries (ICLR/NeurIPS-style).
- Dependencies/assumptions: Clear experiment artifacts; review checklists; editorial oversight.
- Journal/conference triage and review assistance (Academia, Publishing)
- What it does: Panel-style LLM reviews aligned with top-tier criteria to support desk rejections, reproducibility checks, and initial novelty screens; pairwise comparison against baselines.
- Tools/workflows: “Scientist-Bench-as-a-Service” for program chairs; randomized paper ordering; multi-LLM ensembles.
- Dependencies/assumptions: Ethical policies for AI-assisted review; transparency requirements; calibration against real decisions.
- Competitive intelligence and patent landscaping (IP/Legal, Finance)
- What it does: Extracts core ideas from literature, links to implementations, identifies conceptual gaps and emerging patterns; anonymization pipeline reduces term-recognition bias.
- Tools/workflows: Idea Generator divergence–convergence analysis; concept lineage maps; “gap radar” dashboards.
- Dependencies/assumptions: Legal/compliance review; careful handling of proprietary materials.
- Teaching assistant for research methods (Education)
- What it does: Constructs literature maps, generates research plans, builds weak-to-strong prototypes, and drafts reports for coursework (with academic integrity safeguards).
- Tools/workflows: Assignment scaffolds tied to Scientist-Bench rubrics; code review and documentation feedback loops.
- Dependencies/assumptions: Institution-approved usage; plagiarism detection; disclosure norms.
- Secure agent execution for IT/DevSecOps (Software/IT)
- What it does: Deploys agent workflows in Dockerized containers with strict permissions, dynamic dependency management, and safe execution of third-party code.
- Tools/workflows: Preconfigured ML images (e.g., PyTorch); network policies; artifact logging; audit trails.
- Dependencies/assumptions: Sandboxing infrastructure; supply-chain scanning; secrets management.
- AutoML augmentation with research-grade ideas (Software/AI)
- What it does: Feeds AutoML with agent-generated, vetted variations (architectures/losses/training curricula) and runs rapid “minimum viable experiments.”
- Tools/workflows: Idea feasibility filters; small-epoch pilot runs; advisor-guided iteration.
- Dependencies/assumptions: Compute budget controls; robust early-stopping/NaN guards; evaluation baselines.
- Open-source maintenance and documentation uplift (Software/AI)
- What it does: Analyzes repos to align docs with math/theory, generates missing READMEs/tutorials, flags conceptual omissions or broken training loops.
- Tools/workflows: Repo auditor; “paper–code alignment” reports; doc-generation bots.
- Dependencies/assumptions: License compliance; maintainer consent; CI integration.
Long-Term Applications
These require further research, integration with physical systems, regulatory evolution, or scaling across domains beyond AI.
- Closed-loop, self-driving labs (Healthcare, Materials, Energy)
- What it does: Integrates AI-Researcher with lab robotics/instrumentation to propose hypotheses, design experiments, run them, analyze results, and iterate—autonomous discovery in chemistry, materials, and bio.
- Tools/workflows: LIMS integration; experiment schedulers; simulation-to-real loops; safety guardrails.
- Dependencies/assumptions: Reliable lab APIs; high-fidelity simulators; biosafety/ethics compliance; robust causal inference under noise.
- Autonomous grant writing and program evaluation (Policy, Government, Philanthropy)
- What it does: Drafts proposals aligned with strategic priorities; evaluates portfolios with Scientist-Bench-like metrics for novelty, rigor, and validation; horizon scans for promising gaps.
- Tools/workflows: Portfolio “innovation dashboards”; standardized review panels; proposal-to-outcome tracking.
- Dependencies/assumptions: Policy acceptance of AI-assisted evaluation; transparency and appeal mechanisms; bias auditing.
- Industrial “always-on” research engines (Enterprise R&D across sectors)
- What it does: Continuous, open-ended exploration pipelines that scout literature, propose directions, execute pilots, and escalate promising lines of work to human teams.
- Tools/workflows: Research backlog triage; compute schedulers; escalation policies; ROI tracking.
- Dependencies/assumptions: Governance for autonomous spending; risk management; human oversight thresholds.
- Peer review transformation with AI panels (Publishing, Academia)
- What it does: Institutionalizes panel-style multi-LLM reviews with bias controls (e.g., random-swap), reproducibility verification, and code execution checks as standard practice.
- Tools/workflows: Journal submission pipelines with sandboxed runs; structured justifications; conflict-of-interest checks.
- Dependencies/assumptions: Community buy-in; standardized artifacts; legal/ethical frameworks for AI reviewers.
- Domain-general Scientist-Bench extensions (Healthcare, Climate, Economics, Education)
- What it does: Expands benchmark beyond AI/ML to include domain-specific datasets, lab protocols, and evaluation rubrics, enabling cross-field comparison of autonomous research capability.
- Tools/workflows: Anonymization protocols per field; multi-modal inputs (omics, sensor logs); domain LLMs.
- Dependencies/assumptions: Curated public datasets; expert-provided rubrics; secure data handling.
- Patentable AI-generated inventions and IP workflows (IP/Legal, Enterprise)
- What it does: Uses idea generation and feasibility filters to produce patent disclosures; drafts claims and prior-art analyses; manages invention pipelines.
- Tools/workflows: “Claims assistant”; prior-art RAG; invention–market fit triage.
- Dependencies/assumptions: Evolving legal frameworks for AI inventorship; human attribution policies; quality control to avoid obviousness.
- Robotics/control algorithm innovation loop (Robotics, Manufacturing)
- What it does: Generates novel control policies and planners, implements them in simulation, and transfers to real robots via closed-loop refinement.
- Tools/workflows: Sim-to-real bridges; safety monitors; hardware-in-the-loop testing.
- Dependencies/assumptions: High-fidelity simulators; safety certification; real-time constraints.
- Finance quant research automation (Finance)
- What it does: Literature scanning, hypothesis generation, backtesting code synthesis, risk analysis documentation, and compliance-ready reporting.
- Tools/workflows: Data firewalls; sandboxed backtesting; model risk documentation; change logs.
- Dependencies/assumptions: Strict guardrails against hallucinated signals; market-impact risk controls; regulatory compliance.
- Personalized research education at scale (Education)
- What it does: AI “co-advisors” that scaffold student research from problem scoping to experiments and writing, aligned with integrity policies and mastery goals.
- Tools/workflows: Adaptive curricula; formative feedback tied to rubrics; plagiarism-aware drafting.
- Dependencies/assumptions: Institutional policy updates; assessment redesign; disclosure norms.
- Enterprise knowledge-brain for R&D (Enterprise R&D)
- What it does: Ingests internal reports, code, and results; maintains math-to-code mappings; suggests next experiments; drafts internal patents and papers.
- Tools/workflows: Secure retrieval over private corpora; access controls; audit trails; model fine-tuning.
- Dependencies/assumptions: Data governance; IP sensitivity; robust privacy-preserving LLMs.
Notes on cross-cutting feasibility:
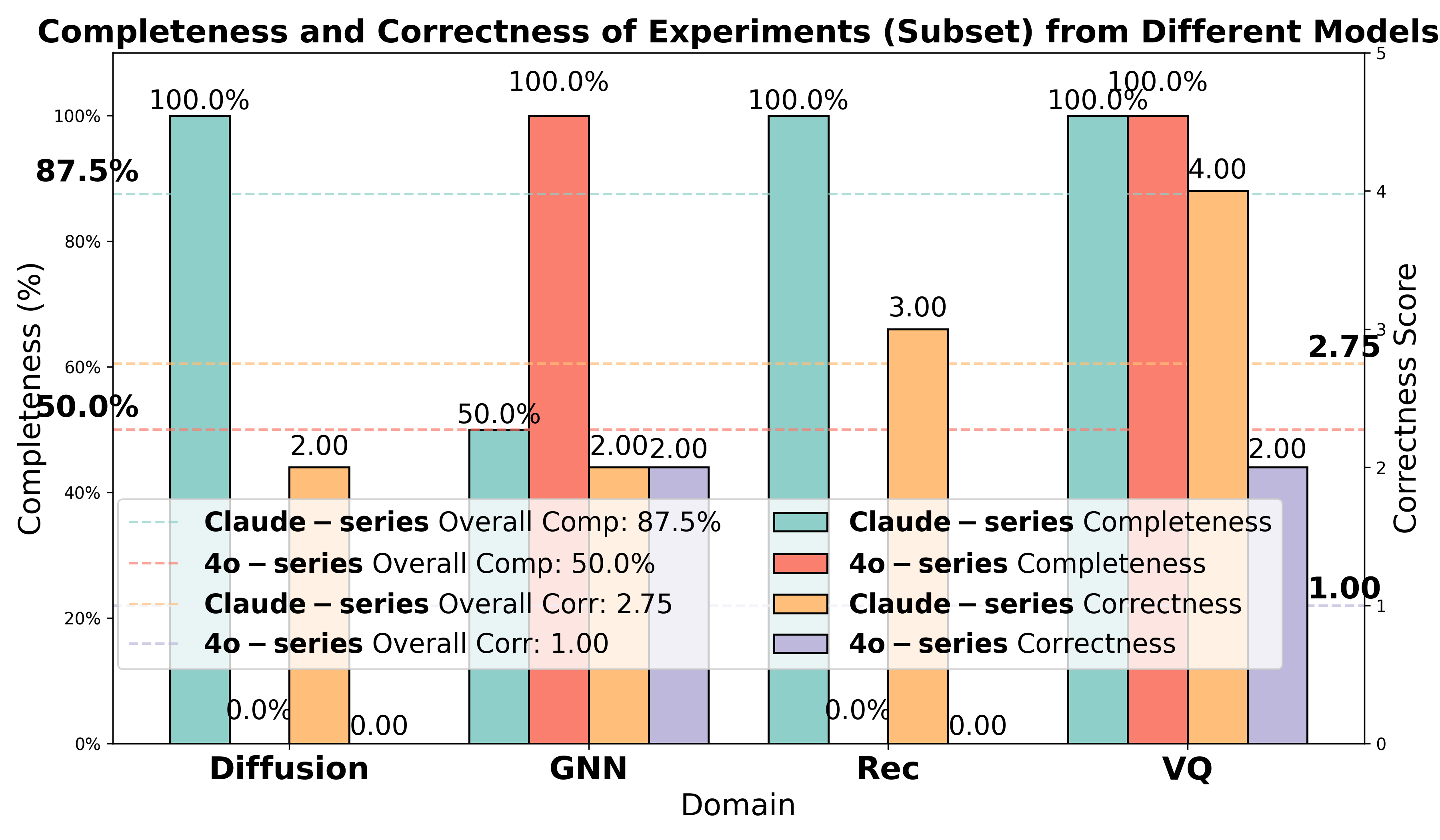
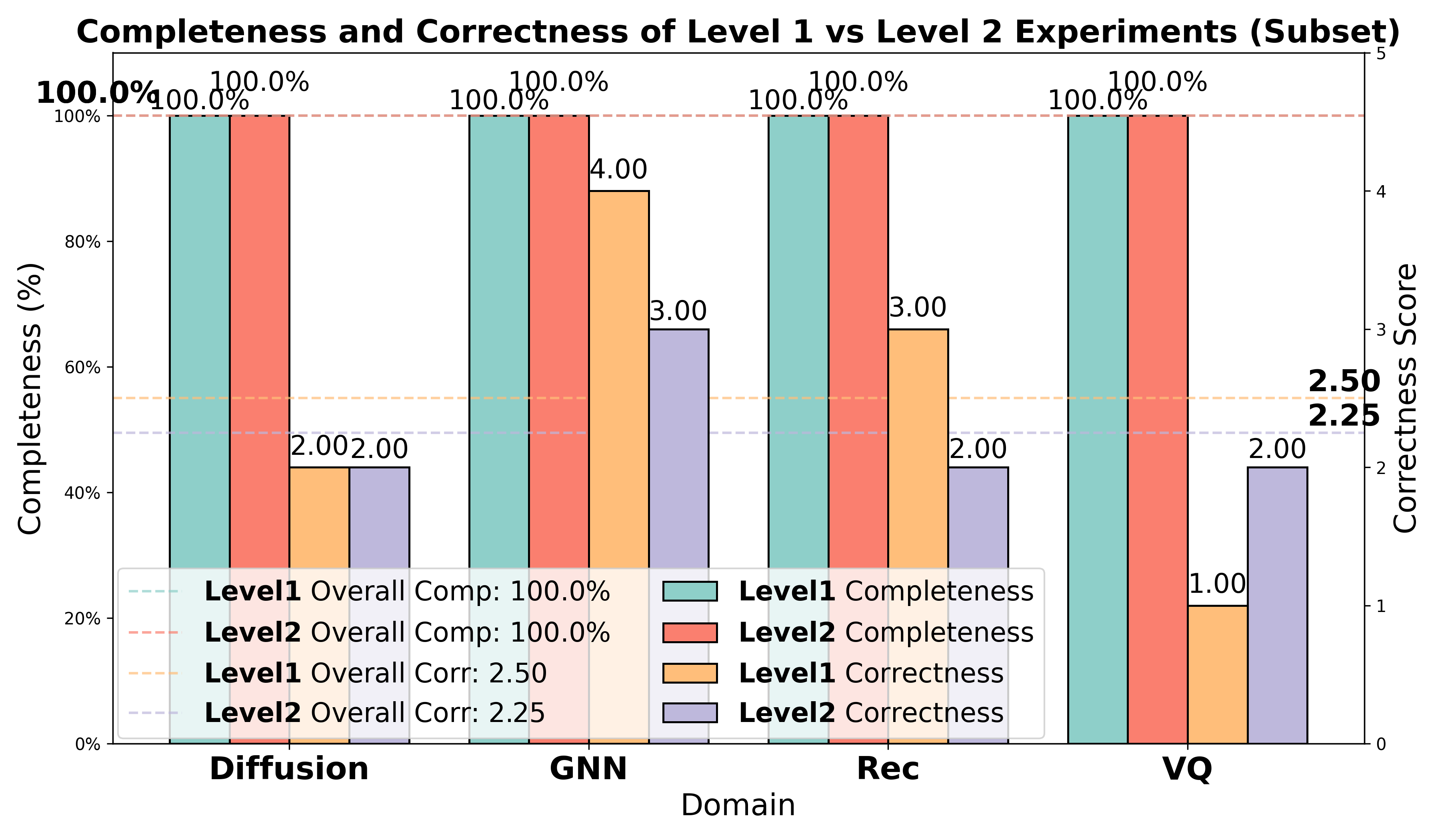
- Model quality and stability: The paper’s results show stronger performance with certain LLM families (e.g., Claude-series) and highlight failure modes (tensor mismatches, missing conceptual components). Production use requires model selection, evaluation, and fallback strategies.
- Safety and governance: Autonomous code execution demands sandboxing (Docker), supply chain security, and human oversight—especially in finance, healthcare, and robotics.
- Data and licensing: Many workflows depend on access to LaTeX sources, datasets, and GitHub repositories; ensure license compliance and secure handling of private data.
- Evaluation robustness: Scientist-Bench’s multi-LLM reviewer ensembles and debiasing are promising, but domain extensions need new rubrics and human calibration.
- Cultural adoption: Academic and policy applications hinge on norms for AI assistance, transparency, and accountability.
Collections
Sign up for free to add this paper to one or more collections.