Read the Paper, Write the Code: Agentic Reproduction of Social-Science Results
Abstract: Recent work has used LLM agents to reproduce empirical social science results with access to both the data and code. We broaden this scope by asking: Can they reproduce results given only a paper's methods description and original data? We develop an agentic reproduction system that extracts structured methods descriptions from papers, runs reimplementations under strict information isolation -- agents never see the original code, results, or paper -- and enables deterministic, cell-level comparison of reproduced outputs to the original results. An error attribution step traces discrepancies through the system chain to identify root causes. Evaluating four agent scaffolds and four LLMs on 48 papers with human-verified reproducibility, we find that agents can largely recover published results, but performance varies substantially between models, scaffolds, and papers. Root cause analysis reveals that failures stem both from agent errors and from underspecification in the papers themselves.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple but important question: If you give an AI the text of a research paper’s methods and the original data—but not the authors’ code—can the AI rebuild the code and recreate the paper’s results? Think of it like this: if a paper is a “recipe” and the data are the “ingredients,” can an AI cook the same dish without seeing the chef’s original instructions step-by-step code?
What the researchers wanted to find out
In plain terms, they wanted to know:
- Can AI agents read the methods section of social-science papers and write new code that gets the same numbers as the original study?
- How well does this work across different AI models and different “scaffolds” (the tools and rules the AI uses)?
- When reproductions fail, is it because the AI messed up, or because the paper didn’t explain its methods clearly enough?
How they did it (explained simply)
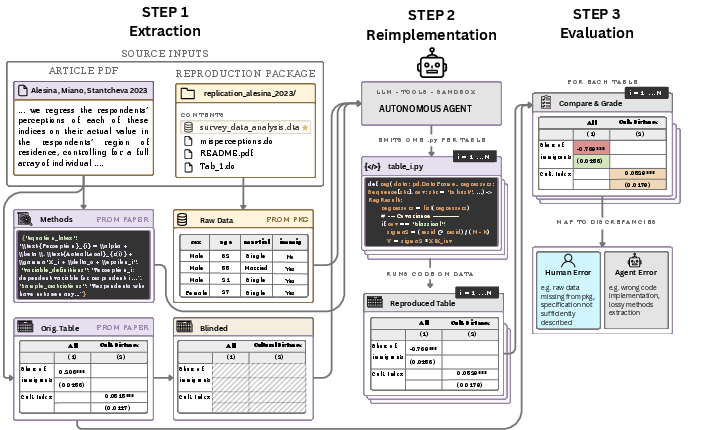
The team built a four-step system. You can think of it as a careful, leak-proof assembly line that keeps the AI honest and makes comparing results fair.
Step 1: Extract (build a clean task for the AI)
- They fed the entire PDF of each paper to an AI to pull out a clear, structured description of the methods—what was studied, which data were used, and what each results table should look like.
- They also pulled the original numbers from the paper’s tables but then “blinded” them (hid the numbers) to prevent the AI from simply copying.
- They identified which data files were needed from each paper’s replication package (the files authors share so others can check their work). If the necessary data weren’t available, that paper was skipped.
Analogy: They created a blank table template (same rows/columns as the paper), a detailed plan for how to fill it, and a clean box of ingredients (data). But they hid the final answers.
Step 2: Re-implement (have the AI write the code)
- The AI was put in a locked workspace containing only:
- the methods description,
- the empty table templates,
- and the data.
- The AI’s job: write separate Python scripts for each table to fill in all the numbers.
Guardrails: The AI was not allowed to see the paper’s code or results or browse the web for them. The team also ran audits to check the AI didn’t cheat (for example, by pasting numbers directly) and that any results came from actual calculations on the data.
Step 3: Evaluate (check the AI’s work)
- Because both the AI-made tables and the paper’s originals used the same structure, the team could compare every table cell directly.
- They measured:
- Direction match: Did the AI’s effect go the same way (positive or negative)?
- Size closeness: How far was the AI’s number from the paper’s number, including a check of whether it fell within the original 95% confidence interval (a common “close enough” statistical range).
- They also converted differences into letter grades (A to F) to keep things easy to read and to avoid single outliers dominating the results.
Step 4: Explain (figure out why differences happened)
- When numbers didn’t match well, another AI (and checks) tried to trace the cause by comparing:
- the paper’s methods vs. the original authors’ code,
- the extracted methods vs. what the AI implemented,
- and whether any data were missing.
- They grouped root causes into:
- Agent errors (AI misunderstood or didn’t follow instructions),
- Extraction errors (the first step misread the paper),
- Paper underspecification (the paper didn’t include enough details to reproduce the exact steps),
- Missing data.
What they found (and why it matters)
Big picture: Yes—AI can usually recreate much of the results just from the paper text and data. But how well it works depends a lot on the AI model and setup.
- Success rates were encouraging:
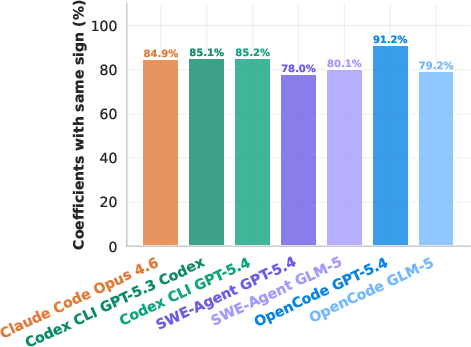
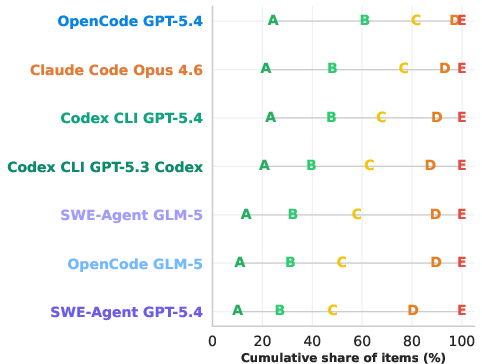
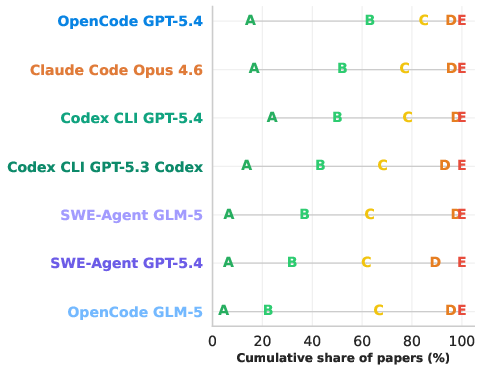
- For the top systems, over 85% of reproduced “effect” numbers (regression coefficients) had the same sign (direction) as the original.
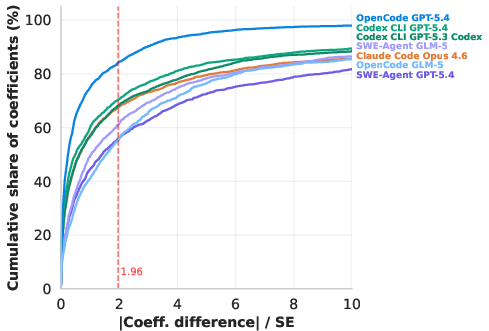
- Around 70–80% of reproduced coefficients were close enough to fall within the original study’s 95% confidence interval.
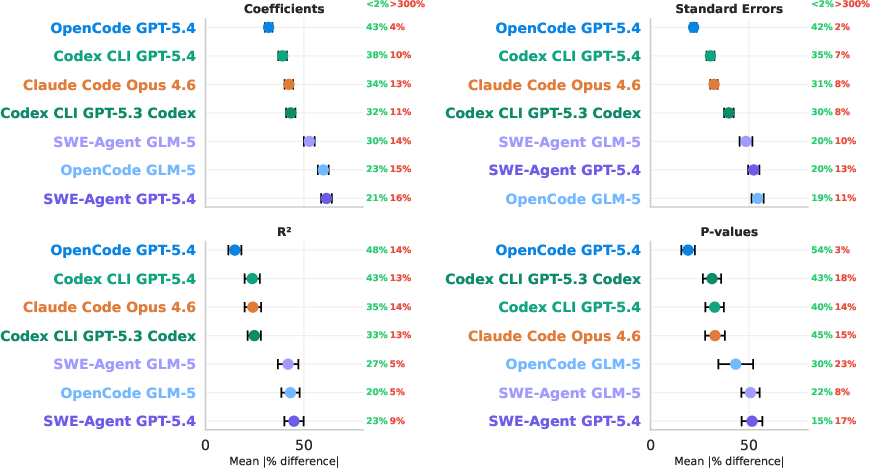
- Not all AIs performed the same:
- The best combination (a GPT-5.4 model using an “OpenCode” scaffold) beat others by a wide margin.
- Performance depended not just on the AI model but also on the scaffold—the tools and workflow around the model.
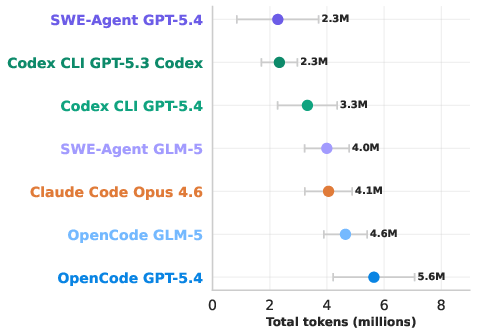
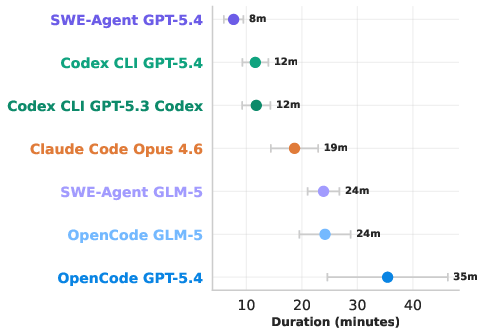
- More effort often meant better results:
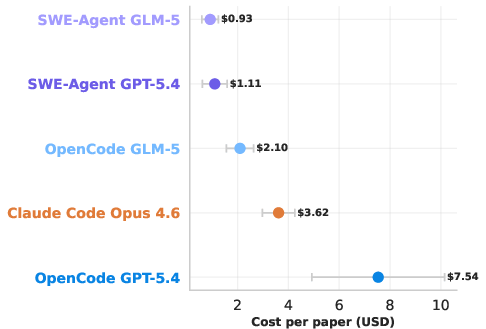
- The top-performing setup used more “tokens” (think: more words processed and produced), took longer, and cost more.
- In other words, throwing more careful reasoning and iterations at the problem helped.
- Why do reproductions fail?
- A lot of failures weren’t the AI’s “fault.” Many papers didn’t fully specify every detail (like a recipe missing a measurement or leaving out a step). This makes it hard—even for people—to recreate results exactly.
- Some failures came from the AI misunderstanding the methods or making wrong assumptions.
- Missing data also caused gaps.
- The evaluation was strict and transparent:
- They compared numbers cell-by-cell and graded them, avoiding “LLM-as-judge” (which can be squishy). This makes the results more trustworthy.
Why this matters: If AIs can “read the paper and write the code,” then journals, editors, and researchers could more quickly check whether published findings are actually reproducible. That could save time and help improve the clarity of papers.
What this could change in the real world
- Better scientific transparency: If authors know their results must be reproducible from the text alone, they may write clearer methods (like better recipes).
- Faster, broader checks: AI agents could help review many more papers than humans can alone, flagging when details are missing or results seem off.
- Teaching and teamwork: Students and researchers can use these tools to learn how analyses are done and to double-check their own work.
- Limits still matter: The AI works best when papers are precise and data are available. When instructions are vague or data are restricted, performance drops. Also, better performance can cost more compute time and money.
In short, this study shows that modern AI can often recreate the core findings of social-science papers from the methods text and data alone—without seeing the original code. That’s a promising step toward making research more reliable, faster to check, and easier to build on.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper—framed as concrete, actionable directions for future work.
- External validity: Assess generalizability beyond 48 I4Replication-verified papers, which are preselected to be reproducible and may bias results upward relative to the broader literature.
- Coverage of materials: Extend beyond journal PDFs to include online appendices (often containing key specifications) and systematically handle figures/charts, which are currently excluded from core evaluation.
- Figures and VLMs: Develop and validate reliable figure/plot parsing and comparison (with VLMs or alternative methods) to support deterministic evaluation of graphical results.
- Methods extraction validation: Create a gold-standard benchmark of paper-to-methods extractions (with human-annotated ground truth) to quantify extraction accuracy, recall, and the specific failure modes that propagate downstream.
- Table parsing robustness: Systematically evaluate and improve table extraction, especially for landscape and multi-page tables where minor numeric errors were observed; measure error rates across a larger, stratified sample.
- Data availability constraints: Evaluate performance on papers with partially or fully unavailable data (e.g., proprietary, restricted-access) by simulating realistic data acquisition workflows or using author-provided synthetic data.
- Language and toolchain mismatch: Quantify the impact of reimplementing Stata/R code in Python (default settings, estimators, clustering, weighting, and transformations), and test reimplementation in the original language to isolate translation effects.
- Scaling and unit normalization: Incorporate automated unit detection/normalization (e.g., cents vs dollars) into evaluation and/or reimplementation to prevent misclassification of otherwise correct results as large errors.
- Statistical convention alignment: Detect and align implicit choices (e.g., clustering levels, robust SEs, finite-sample corrections, treatment of weights/fixed effects, IV diagnostics) to reduce discrepancies attributable to unreported defaults.
- Deterministic evaluation assumptions: Re-examine the use of original-paper SEs for CI-based comparisons when agents choose different (possibly reasonable) specifications; explore alternative equivalence criteria (e.g., specification matching, tolerance bands that account for estimator choice).
- Grading scheme sensitivity: Test robustness of conclusions to grading thresholds (e.g., A/B breakpoints), treatment of missing cells in denominators, and outlier truncation rules (e.g., 300% cap).
- Leakage and audit rigor: Strengthen and independently validate leakage/hardcoding audits (regex + LLM review), including adversarial tests for subtle exfiltration channels and memorization detection beyond post-2025 spot checks.
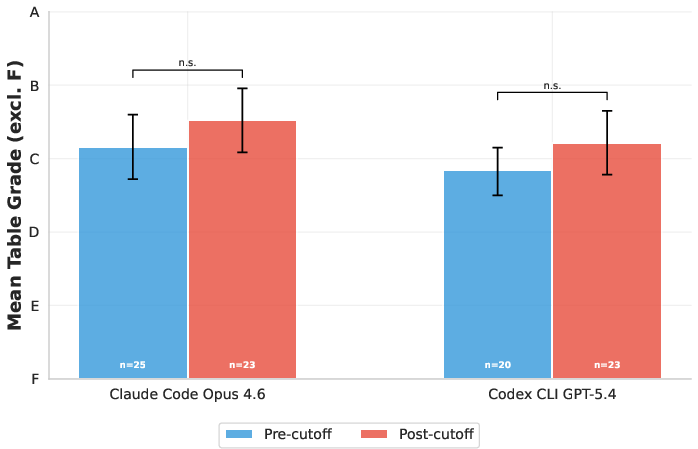
- Pretraining contamination: Report results from the post–knowledge cutoff EJ analysis and broaden leakage tests across more journals, time windows, and models to quantify contamination risks.
- Compute budget confounds: Control (or explicitly vary) token/time budgets across scaffolds when comparing performance to disentangle capability from compute expenditure; characterize the compute–accuracy trade-off curve.
- Scaffold–model interactions: Perform controlled ablations to identify which scaffold components (tools, retry policies, code execution strategies) drive gains with specific models; explore multi-agent or planner–executor designs.
- Effort allocation optimization: Move beyond counts of actions/chars to causal tests of which activities (writing vs execution vs reading) most improve outcomes; design targeted heuristics or policies to allocate effort efficiently.
- Error attribution reliability: Validate the discrepancy analysis pipeline (which relies on LLMs) with human audits and inter-annotator agreement; quantify precision/recall of root-cause labels (agent vs paper vs extraction vs data).
- Paper underspecification taxonomy: Build a structured taxonomy of underspecification (e.g., missing codebook mappings, estimator variants, transformation details) and measure prevalence; test interventions (checklists, templates) to reduce it.
- Human-in-the-loop strategies: Evaluate how minimal human inputs (e.g., clarifying one underspecified detail) change outcomes and cost; identify the highest-yield questions to ask when methods are ambiguous.
- Broader statistical coverage: Benchmark on papers with more complex or non-standard pipelines (e.g., structural models, nonlinear ML, matching/weighting workflows, multi-level/hierarchical models) to probe method limits.
- Cross-disciplinary generalization: Test the pipeline in other empirical domains (e.g., psychology, biomedicine) with different reporting conventions and typical analyses.
- Reproducibility stability: Complete and report multi-run stability analyses (seed sensitivity) across scaffolds/models, including variance in outputs and convergence behavior.
- Code quality and maintainability: Assess the readability, modularity, documentation, and reusability of agent-generated code, beyond numeric fidelity; examine whether resulting scripts are suitable for audit and reuse.
- Environment/version control: Study sensitivity to Python package versions and runtime environments; add mechanisms to capture and standardize dependencies for fully reproducible agent runs.
- Data-file selection heuristics: Validate the “least pre-processed” data-selection rule against ground truth to ensure the agent selects the correct inputs in packages with multiple intermediate datasets.
- Release and reproducibility of the pipeline: Provide (or audit) open resources—code, prompts, extracted methods/results templates, and standardized environments—to enable independent replication and extension of the benchmark.
Practical Applications
Immediate Applications
The paper delivers a practical, end-to-end workflow—methods extraction, code re-implementation in a sandbox, deterministic evaluation, and discrepancy attribution—that can be deployed today for reproducibility and QA at scale. Below are specific, actionable use cases.
- Academic publishing and research integrity (journals, data editors, universities)
- Reproducibility triage in editorial pipelines
- Sector: Academic publishing
- What: “ReproCheck CI” runs the pipeline on submission to verify that main tables are reproducible from the methods + data without access to code; flags underspecifications.
- Outputs: Table-by-table grades, cell-level diffs, underspecification report.
- Dependencies/assumptions: Authors supply data; methods sections not grossly underspecified; compute budget for longer runs; guardrail audits to prevent leakage.
- Author-side pre-submission checker
- Sector: Academia
- What: “Paper-to-Code Self-Check” that writers run locally or via a hosted service to spot missing details before submission.
- Outputs: Missing-methods checklist, unit-scaling warnings, suggested clarifications (e.g., which F-statistic, clustering level).
- Dependencies: Clean PDF, accessible data; trust boundaries for sensitive data.
- Lab QA for research groups and RAs
- Sector: Academia
- What: “RA Validator” reimplements analyses from draft methods and data to detect mismatches between intended and implemented models.
- Outputs: Discrepancy localization (original code vs. re-implementation), intentional vs. accidental choices.
- Dependencies: Sandbox execution; access to draft/manuscript PDF.
- Government and policy evaluation
- Evidence audit of contractor reports
- Sector: Public policy
- What: “Policy Evidence Auditor” re-implements reported analyses from report text + data, comparing to stated results.
- Outputs: Pass/fail flags, list of underspecified or unverifiable steps, reproducibility grades for procurement decisions.
- Dependencies: Contractual requirement to provide data; standardized reporting format; secure compute for confidential datasets.
- Funding and compliance checks
- Sector: Research funding agencies
- What: Automated compliance verification that funded studies’ reported tables are reproducible from documented methods.
- Outputs: Compliance certificate, residual risk/ambiguity log.
- Dependencies: Data sharing policies; guidance on acceptable deviations.
- Industry analytics and internal audit
- Rebuilding analyses from business reports
- Sector: Finance, tech, consumer goods
- What: “Analysis Validator” that regenerates KPIs, A/B test results, or econometric findings from report text and linked data stores—no code required.
- Outputs: KPI match rate, cell-level differences, unit normalization suggestions.
- Dependencies: Access to data warehouse exports; identity and unit mappings; computational budgeting.
- Model governance and SOX/ESG/AI compliance
- Sector: Finance, risk, compliance
- What: “Narrative-to-Code Audit” verifies that model documentation matches implemented analyses; identifies hidden assumptions.
- Outputs: Traceable lineage from doc → code → result; human/agent error attribution.
- Dependencies: Controlled environments; audit logs; model versioning.
- Healthcare and clinical research
- Protocol-to-result verification for observational studies
- Sector: Healthcare/biopharma
- What: Map written protocols and methods sections to executable analysis pipelines for reproducibility of results tables.
- Outputs: Noncompliant steps, missing covariates or clustering instructions, discrepancies in standard errors.
- Dependencies: De-identified data access; GxP-aligned sandboxing; SOP-aligned guardrails.
- Data-monitoring committees support
- Sector: Clinical research oversight
- What: Rapid, independent re-implementation of tables during interim reviews (where allowed).
- Outputs: Confidence interval proximity, sign agreement, outlier diagnostics.
- Dependencies: Strict privacy; IRB constraints; scoped use.
- Education and skills training
- Replication labs from papers without code
- Sector: Higher education
- What: Course modules where students use the pipeline to reproduce published tables and diagnose underspecification.
- Outputs: Teaching artifacts, reproducibility grades, reflection on methodological clarity.
- Dependencies: Public data; curated paper sets; faculty oversight.
- Cross-language code migration (Stata/R → Python)
- Sector: Education/software
- What: Use the methods-extraction + agentic re-implementation to produce equivalent Python pipelines from papers originally written in Stata/R.
- Outputs: Python scripts per table, aligned with structured methods schema.
- Dependencies: Accurate extraction; library parity (e.g., IV variants, clustering).
- Media, NGOs, and civil society
- Fact-checking quantitative claims in reports
- Sector: Data journalism, NGOs
- What: “Result Verifier” regenerates published statistics from narrative methods + public datasets.
- Outputs: Reproduction coverage and deviation summaries, caveat list for missing/ambiguous steps.
- Dependencies: Public-access data; robust table parsing; editorial review.
- Software tooling for open science
- Productized components from the pipeline
- Sector: Software/AI tooling
- What:
- “Methods Extractor” (PDF → structured methods schema)
- “Blind Table Template Generator” (results masked to avoid leakage)
- “Agent Sandbox Runner” (isolated execution with guardrail and hardcoding audits)
- “Deterministic Evaluator” (cell-level comparison and grading)
- “Discrepancy Analyzer” (root-cause attribution)
- Outputs: APIs/CLIs for CI pipelines, GitHub Actions, or journal submission portals.
- Dependencies: Model access; GPU/CPU quotas; organizational policy for LLM use.
Long-Term Applications
The paper also points toward broader changes—standards, products, and policy—once research, tooling, and infrastructure mature (e.g., better VLMs for figures, stronger guardrails, standardized schemas).
- Standards and policy reforms for reproducibility
- Structured Methods Markup Language (SMML)
- Sector: Academia, standards bodies
- What: Community standard for machine-readable methods (datasets, filters, formulas, estimands, SE types, clustering, unit scaling).
- Impact: Reduces underspecification; enables one-click reproduction.
- Dependencies: Journal adoption; tooling support; author incentives.
- Executable papers by default
- Sector: Publishing
- What: Papers bundle methods schema, blinded templates, and validated re-implementation traces; replication badges automated.
- Dependencies: Platform support (e.g., Dataverse/OSF integration); stable environments.
- Multimodal and cross-domain expansion
- Figure reproduction and visual QA at scale
- Sector: All research domains
- What: Robust VLMs generate plots from data + methods and compare against published figures (axes, transformations, CIs).
- Dependencies: Better, validated vision-language reliability; standardized figure metadata.
- Beyond social sciences (biomedicine, climate, ML)
- Sector: Healthcare, climate/energy, ML ops
- What: Apply the pipeline to protocols and model cards to regenerate analyses and metrics from text + data.
- Dependencies: Domain-specific libraries and estimators; ontology alignment; privacy-preserving compute.
- Evidence pipelines for government decision-making
- Continuous, automated evaluation of policy evidence bases
- Sector: Government
- What: Standing “Evidence Hub” that ingests new studies, reproduces key tables, scores methodological clarity, and surfaces credible syntheses.
- Dependencies: Data access agreements; procurement retooling; governance frameworks.
- Compliance and governance in regulated industries
- Secure, privacy-preserving reproduction
- Sector: Finance, healthcare, public sector
- What: Reproduction-as-a-service in secure enclaves or federated settings with full provenance and leakage guarantees.
- Dependencies: Confidential computing; differential privacy or synthetic data; auditability.
- Learning systems that improve methods and reporting
- Underspecification detector and authoring assistant
- Sector: Research tools
- What: Models identify likely missing details (e.g., clustering level, variance estimator) and propose fixes during writing.
- Dependencies: Large annotated corpora of discrepancies; integration into authoring tools.
- Compute-aware agent orchestration
- Sector: AI infrastructure
- What: Controllers that optimize token budgets, retries, and tool selection for cost-accuracy trade-offs; guarantee reproducibility under budget constraints.
- Dependencies: Trace datasets; standardized evaluation harnesses.
- Market infrastructure and incentives
- Replication marketplaces and credits
- Sector: Academia/publishers/funders
- What: Bounties and automated verification pipelines that tokenize or credit successful reproductions; integration with grant/tenure reviews.
- Dependencies: Policy alignment; reliable leaderboards/benchmarks; anti-gaming guardrails.
- Cross-lingual and accessibility expansion
- Global reproducibility support
- Sector: International research
- What: Methods extraction and re-implementation across languages and legacy/scanned PDFs.
- Dependencies: High-quality OCR and translation; multilingual models; local data policies.
- Continuous, “living” papers and registries
- Auto-updating results with data refresh
- Sector: Data-intensive fields
- What: Papers that re-run when new data arrives; agents track drift, re-generate tables, and update confidence assessments.
- Dependencies: Versioned data registries; archival environments; governance for updates.
Cross-cutting assumptions and dependencies
- Data availability: Many immediate uses require access to the same (or minimally processed) data. Proprietary or sensitive data introduce access and privacy constraints.
- Methods clarity: Success depends on sufficient detail in the methods. The paper’s underspecification findings imply that standards and authoring support are key.
- Leakage prevention: Strong guardrails (path audits, hardcoding checks, isolation) are necessary to ensure genuine re-implementation, not retrieval.
- Model and scaffold variance: Performance varies by LLM and scaffold; budgets (tokens, time) materially affect outcomes. Organizations must set cost–accuracy policies.
- Tooling maturity: Table and figure extraction reliability, library parity (e.g., IV diagnostics, clustered SEs), and unit scaling normalization affect feasibility.
- Human oversight: Deterministic grading and root-cause reports aid review, but edge cases and policy decisions require expert judgment.
- Legal/ethical constraints: Use with PII/PHI, compliance frameworks (e.g., GxP, SOX), and IP/licensing must be respected.
- Versioning and provenance: Reproducibility claims require captured environment specs, model versions, and execution traces.
Glossary
- Agent scaffold: The orchestration framework that structures an LLM agent’s tools, steps, and interaction loop during a task. Example: "Evaluating four agent scaffolds and four LLMs on 48 papers with human-verified reproducibility, we find that agents can largely recover published results, but performance varies substantially between models, scaffolds, and papers."
- Agentic reproduction system: An autonomous, multi-step agent pipeline designed to re-implement analyses and reproduce results from papers and data. Example: "We develop an agentic reproduction system that extracts structured methods descriptions from papers, runs reimplementations under strict information isolation—agents never see the original code, results, or paper—and enables deterministic, cell-level comparison of reproduced outputs to the original results."
- Blinding (of results): Removing or masking numerical outputs so agents cannot copy targets and must compute them. Example: "Results extraction and blinding."
- Compute budget: The practical limit of computation (e.g., tokens/time) an agent expends on a task. Example: "differences in observed accuracy may partly reflect differences in implicit compute budgets rather than purely differences in capability."
- Confidence interval (95% CI): A statistical range that, under repeated sampling, contains the true parameter 95% of the time. Example: "The value of the CDF at x = 1.96 indicates the share of reproduced estimates which lie within the 95% confidence interval (CI), meaning they are not statistically different from the original estimates."
- Cumulative distribution function (CDF): A function giving the probability that a variable is less than or equal to a given value; used here to summarize error magnitudes. Example: "Next, presents cumulative distributions (CDFs) of the absolute difference of the original and reproduced coefficients, divided by the ground-truth standard error."
- Data leakage: Unintended access to ground-truth code/results during evaluation, compromising validity. Example: "A potential issue with this application is data leakage: tested LLMs may have been exposed to the manuscripts or code during pre-training."
- Deterministic benchmarking: An evaluation approach where reproduced outputs are compared exactly and reproducibly to ground truth. Example: "allowing for deterministic benchmarking."
- Deterministic regex scan: A rule-based, reproducible pattern-matching check used to detect forbidden file/URL access. Example: "The guardrail audit includes a deterministic regex scan, which classifies all accessed file paths and URLs as allowed or forbidden"
- Error attribution: The process of tracing observed discrepancies to specific causes in data, extraction, agent behavior, or paper description. Example: "An error attribution step traces discrepancies through the system chain to identify root causes."
- Ground-truth standard errors: The authoritative uncertainty measures reported in the original paper, used to scale discrepancies. Example: "with adjustments for statistical significance based on ground-truth standard errors."
- Guardrail audit: A compliance check ensuring agents do not access forbidden resources or leak information. Example: "The guardrail audit includes a deterministic regex scan, which classifies all accessed file paths and URLs as allowed or forbidden"
- Hardcoding audit: A check that detects whether numeric outputs were produced without computation (e.g., written as literals). Example: "In parallel, a hardcoding audit checks whether agents output statistical results as numeric literals without a computation path from the data."
- Heredocs: A scripting mechanism for embedding multi-line strings, often used to run inline code. Example: "while GPT-5.4 mostly favors inline Python execution via heredocs"
- ivreg2: A Stata package for instrumental variables regression that provides diagnostics and statistics. Example: "Stata uses ivreg2 (Kleibergen-Paap) widstat F-statistic"
- Kleibergen–Paap statistic: A weak-identification-robust statistic commonly used in IV settings. Example: "(Kleibergen-Paap) Wald F-statistic"
- Knowledge cutoff: The latest date of information included in an LLM’s training data. Example: "model knowledge cutoff, which is August 2025"
- LLM auditor: An LLM used to review and validate consistency and error attribution across artifacts. Example: "For each reported discrepancy, an LLM auditor runs consistency checks comparing the various input and output files."
- LLM-as-judge: An evaluation paradigm where LLMs assess quality instead of deterministic metrics. Example: "Unlike most prior work, which relies on LLM-as-judge evaluation, our evaluation is deterministic"
- LLM table extraction pipeline: An automated LLM process that parses and structures table contents from PDFs. Example: "Coefficients are identified via an LLM table extraction pipeline that classifies all numerical values into one of multiple statistic types."
- Masking (of numerical results): Concealing true numeric values so agents must compute them from data and method descriptions. Example: "where specific numbers are masked."
- Methods extraction: The automated process of extracting structured methodological details from a paper. Example: "Paper vs. Methods Extraction (the methods extraction pipeline did not properly or completely describe the methods)"
- Open-weights (models): Models whose parameters are publicly released for local deployment and fine-tuning. Example: "the open-weights GLM-5"
- Paper underspecification: Insufficient detail in the paper’s methods that prevents unique re-implementation. Example: "We find that errors mostly come from papers' underspecification of methods"
- Re-implementation: Reproducing results by writing new analysis code from the paper’s methods and data, not using the original code. Example: "Our work falls under (2), re-implementation."
- Reproduction package: The bundle of data, code, and documentation provided to enable result regeneration. Example: "We collect the PDFs and reproduction packages of all papers that I4Replication has classified as fully reproducible"
- Replicability: Testing whether findings hold when similar methods are applied to new data (distinct from reproducibility). Example: "A helpful framework ... organizes different forms and components of reproducibility and replicability."
- Sandboxed execution environment: A restricted runtime that isolates the agent from external files and networks. Example: "An autonomous LLM agent, equipped with tools and a sandboxed execution environment, emits one Python script per table"
- Scaffold–model interaction: The way an agent scaffold and an LLM model pair affects performance. Example: "The scaffold-model interaction matters a lot, with GPT-5.4 on OpenCode outperforming GPT-5.4 on the Codex CLI or on mini-SWE-Agent."
- Token usage: The volume of tokens consumed by the LLM during a run, reflecting compute effort and cost. Example: "OpenCode GPT-5.4's better performance is due to much greater token usage, coming at the cost of more expensive API calls and longer analysis runs."
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs, used here for figure-level comparison. Example: "Figure-level comparisons require vision-LLMs whose reliability for this task remains uncertain"
- Wald F-statistic: An F-statistic derived from Wald tests, often used for instrument strength diagnostics. Example: "Wald F-statistic"
- Wald t-statistic: A t-statistic derived from a parameter estimate divided by its standard error. Example: "same units as the Wald t-statistic"
- widstat F-statistic: A specific statistic reported by ivreg2 for weak identification diagnostics. Example: "widstat F-statistic"
Collections
Sign up for free to add this paper to one or more collections.

