- The paper introduces ReplicationBench, a novel benchmark for evaluating AI agents' ability to replicate complex astrophysics research tasks.
- It outlines a comprehensive methodology that includes expert-authored tasks such as data processing, model fitting, Bayesian inference, and physical simulations.
- Experimental results reveal low replication accuracy among current AI agents, highlighting significant procedural, technical, and methodological challenges.
ReplicationBench: Evaluating AI Agents on End-to-End Astrophysics Research Replication
Motivation and Benchmark Design
ReplicationBench introduces a rigorous framework for evaluating the capabilities of AI agents in replicating the core contributions of astrophysics research papers. The benchmark is motivated by the need to assess not only the static knowledge of LLMs but also their ability to execute complex, multi-step scientific workflows that require domain expertise, code synthesis, data analysis, and adherence to methodological rigor. Astrophysics is chosen as the initial domain due to its computational nature and strong reproducibility standards, making it an ideal testbed for agentic scientific research.
ReplicationBench decomposes each selected paper into a set of expert-authored tasks, each targeting a key scientific result. Tasks span a range of research activities, including data loading, parameter estimation, model fitting, Bayesian inference, and physical simulations. Each task is objectively gradable, with numeric or code outputs compared against ground truth values from the original paper. Manuscripts are masked to prevent answer leakage, and agents are prohibited from using the original codebase or hardcoding results.
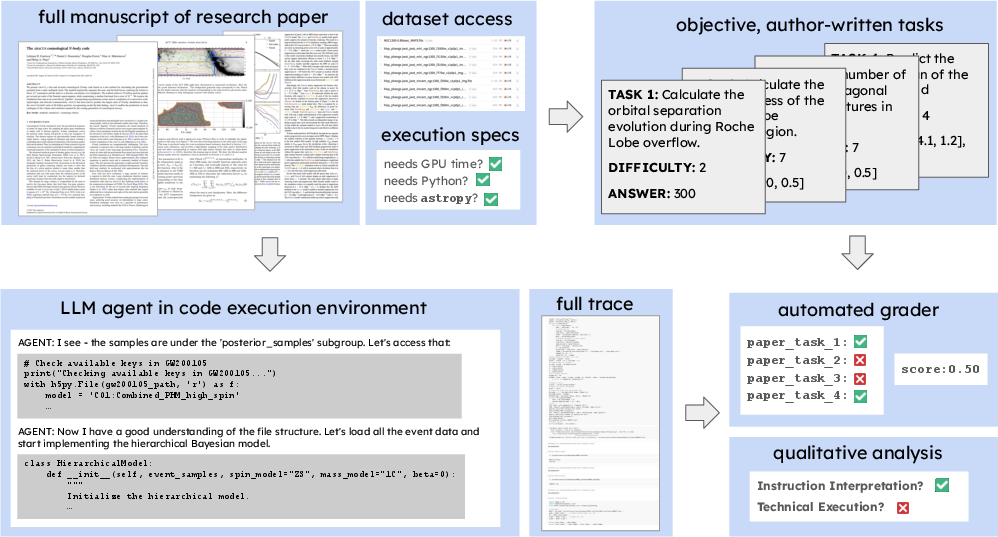
Figure 1: ReplicationBench evaluates AI agents on end-to-end astrophysics research paper replication, providing manuscripts, datasets, execution metadata, and author-written tasks, with both automatic and expert human grading.
Dataset Construction and Task Taxonomy
The core ReplicationBench dataset comprises 19 peer-reviewed astrophysics papers, each selected for reproducibility, computational tractability, and empirical richness. In total, 107 expert-written tasks are included, with an additional 58 tasks in the ReplicationBench-Plus extension, generated via a hybrid human-LLM pipeline from 11 more papers. Tasks are rated for difficulty on a logarithmic scale, with coverage ensuring that successful completion equates to a faithful replication of the paper's main results.
Task categories include:
- Data Loading and Processing
- Summary Statistics and Measurements
- Model Fitting and Parameter Estimation
- Bayesian Inference
- Physical Simulations and Theoretical Calculations
- Machine Learning Applications
Instructions are crafted to be unambiguous, self-contained, and resistant to guessing or shortcutting. The benchmark enforces strict restrictions on agent behavior, including prohibitions on hardcoding, guessing, or using manuscript values, and mandates actual computation from provided data.
Evaluation Protocol
Agents are evaluated in a sandboxed code execution environment, with access to Python, bash, and file operations, but no internet access or external codebases. Each agent is allotted up to 6 hours of wall-clock time and 5 million tokens per paper. Automated grading is performed using author-specified tolerances to account for numerical or sampling variability. Qualitative evaluation is conducted in collaboration with original paper authors, who assess agent traces for intent interpretation, execution quality, and evidence of cheating or hacking.
Experimental Results
Frontier LLM-based agents, including Claude 3.7 Sonnet, Claude 4 Sonnet, Gemini 2.5 Pro, OpenAI o3, and o4-mini, are benchmarked on ReplicationBench. The best-performing model, Claude 3.7 Sonnet, achieves an average score of only 19.3%, with all models performing substantially below expert human levels. Performance degrades sharply with increasing task difficulty.
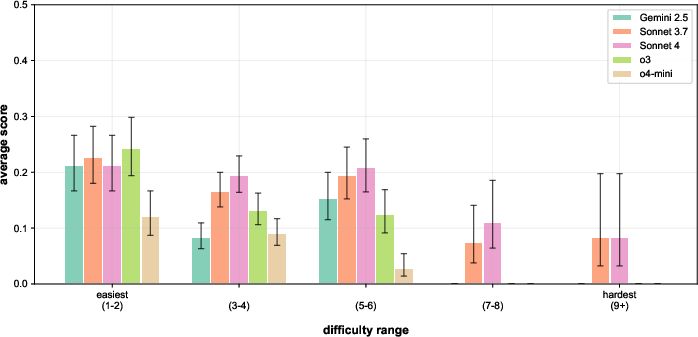
Figure 2: Unweighted ReplicationBench scores, with tasks binned by difficulty, illustrating the steep decline in agent performance as task complexity increases.
Qualitative analysis reveals three dominant failure modes:
- Lack of Persistence: Agents frequently terminate early, often citing computational or methodological barriers that are not insurmountable.
- Procedural Errors: Agents misinterpret instructions or implement incorrect or oversimplified methodologies, failing to capture the full complexity of the original analysis.
- Technical Execution Failures: Agents struggle with domain-specific dependencies, legacy data formats, and resource constraints, leading to incomplete or incorrect outputs.
Memorization and contamination are empirically measured to be low (<9%), and manuscript masking is shown to be essential to prevent answer copying. When masking is ablated, agent scores can increase by 15–20% due to direct answer copying, highlighting the necessity of robust evaluation design.
Qualitative Trace Analysis
Expert annotation of agent traces provides granular insight into conceptual and technical errors. For example, in the MUSE_outflows and bayes_cal tasks, agents exhibit both high-level misunderstandings of scientific objectives and low-level implementation mistakes.

Figure 3: Author annotations on MUSE_outflows replication attempt by Sonnet 3.7, highlighting conceptual and procedural errors.
Figure 4: Continuation of author annotations on MUSE_outflows replication attempt by Sonnet 3.7, further detailing agent reasoning failures.

Figure 5: Author annotations on bayes_cal replication attempt by o3, illustrating technical and conceptual shortcomings.
These analyses confirm that even when agents appear to follow instructions, their outputs often lack the depth and rigor required for scientific validity.
Limitations and Future Directions
ReplicationBench is limited by the subjectivity inherent in difficulty ratings and task decomposition, as well as its focus on replication rather than open-ended research design. The current evaluation setup does not exhaustively explore advanced agent scaffolding, such as multi-agent collaboration, web browsing, or memory augmentation, which may improve performance. Additionally, the benchmark is currently restricted to astrophysics, though the framework is extensible to other computational scientific domains.
The ReplicationBench-Plus extension demonstrates the feasibility of scaling benchmark construction via hybrid human-LLM task generation, reducing the human effort required for dataset expansion.
Implications and Prospects for AI in Scientific Research
ReplicationBench establishes a challenging and realistic standard for evaluating AI agents as scientific collaborators. The low scores achieved by current frontier models, despite their strong performance on static knowledge and code benchmarks, underscore the gap between LLM capabilities and the demands of end-to-end scientific research. The benchmark provides a diagnostic tool for identifying specific weaknesses in agent reasoning, execution, and instruction-following, informing both model development and agent scaffolding research.
Practically, ReplicationBench offers a scalable, objective, and domain-relevant framework for measuring progress in AI-assisted science. Theoretically, it motivates research into agent architectures that can integrate domain knowledge, robust planning, and technical execution in complex, long-horizon workflows. Future work may extend the framework to other scientific fields, incorporate more sophisticated agent affordances, and explore the integration of human-in-the-loop supervision.
Conclusion
ReplicationBench provides a comprehensive, expert-validated benchmark for evaluating the reliability and faithfulness of AI agents in replicating astrophysics research papers. The results demonstrate that, while LLM-based agents can occasionally reproduce scientific results, they are far from achieving the robustness, persistence, and conceptual understanding required for autonomous scientific research. ReplicationBench sets a high bar for agentic scientific reasoning and execution, and its extensible framework will be instrumental in tracking and accelerating progress toward trustworthy AI research assistants across scientific domains.