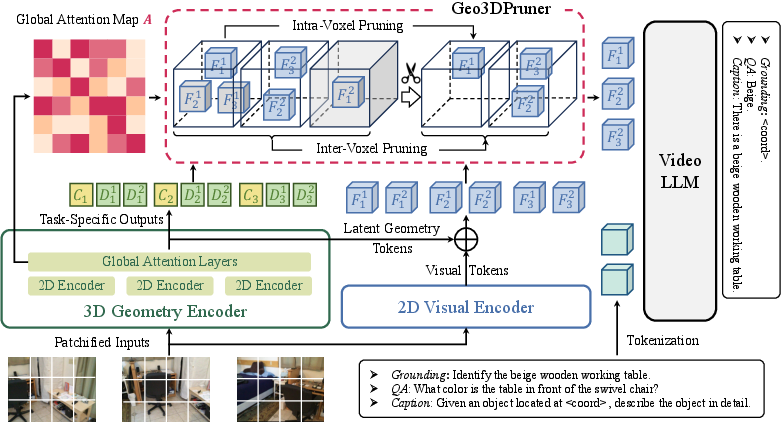
Geometry-Guided 3D Visual Token Pruning for Video-Language Models
Abstract: Multimodal LLMs have demonstrated remarkable capabilities in 2D vision, motivating their extension to 3D scene understanding. Recent studies represent 3D scenes as 3D spatial videos composed of image sequences with depth and camera pose information, enabling pre-trained video-LLMs to perform 3D reasoning tasks. However, the large number of visual tokens in spatial videos remains a major bottleneck for efficient inference and context management. Existing pruning methods overlook the view consistency of spatial videos and the spatial diversity of the remaining tokens, which prevents them from effectively removing inter-frame redundancy and preserving scene completeness. In this paper, we propose Geo3DPruner, a Geometry-Guided 3D Visual Token Pruning framework. Geo3DPruner first models cross-frame relevance through geometry-aware global attention, and then performs a two-stage pruning process. The intra-voxel stage selects representative multi-view features within each voxel, while the inter-voxel stage preserves spatial diversity by selecting a globally distributed subset of voxels. Extensive experiments on multiple 3D scene understanding benchmarks demonstrate that Geo3DPruner retains over 90% of the original performance while pruning 90% of visual tokens, significantly outperforming existing text-guided and vision-guided pruning methods.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Geo3DPruner: A simple explanation of the paper
What is this paper about?
This paper is about making AI systems that understand videos of 3D scenes run faster and more efficiently without losing much accuracy. The authors focus on a common problem: when you film a room from many angles, the AI collects a huge number of small “pieces of information” from every frame. Many of those pieces are repeated because they show the same objects (like the same chair) from different views. The paper introduces Geo3DPruner, a method that smartly throws away duplicate or less useful pieces while keeping the important ones, so the AI can think faster and still understand the scene well.
What questions are the authors trying to answer?
- How can we cut down the number of visual “tokens” (small chunks of image information) from videos of 3D scenes without hurting the AI’s performance?
- How can we remove duplicates across different video frames that show the same place or object from different angles?
- How can we keep a good overall picture of the entire scene (not just one object) after throwing away most tokens?
How does the method work? (Explained simply)
Think of analyzing a room like building a model with LEGO:
- Each small plastic brick is like a “voxel,” which is a tiny 3D box in space (a 3D version of a pixel).
- Each video frame gives you many “visual tokens,” which are little snippets of information from image patches (like small tiles cut from the picture).
The problem: filming the room from many angles creates lots of tokens that repeat the same object. That wastes time and memory.
Geo3DPruner solves this in two main steps, guided by geometry (the 3D structure of the scene):
- Two kinds of “eyes” watch the video:
- A 2D visual encoder looks at colors and textures (what things look like).
- A 3D geometry encoder figures out where things are in space (depth and camera position), and builds a big “who-is-related-to-who” map across all frames. You can think of this map as an attention map: it tells the model which patches in one frame match the same places or objects in other frames.
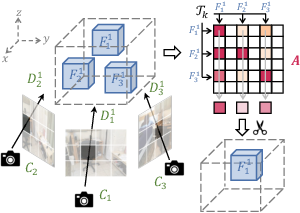
- Put information into 3D space:
- Using the 3D geometry, the method places all the tokens into their correct 3D boxes (voxels), so tokens that describe the same spot end up together.
- Prune in two stages:
- Stage A: Intra-voxel view consistency
- Inside each voxel (tiny 3D box), many tokens describe the same spot from different frames. The method looks at the attention scores (how strongly tokens relate to each other) and keeps only the most representative tokens. This is like keeping the best photo of a chair from a set of similar shots.
- Stage B: Inter-voxel spatial diversity
- Now look across all voxels to make sure the final selection covers the whole room, not just one object. The method iteratively chooses voxels that are important but also spread out. It avoids picking many voxels from the same object so that the AI still “sees” the entire scene.
- Stage A: Intra-voxel view consistency
Everyday analogy:
- Imagine you took 100 photos of your room from all around. Many photos show the same table and chair. First, you pick the best photos of each small spot in the room (Stage A). Then, you make sure your final album has photos covering every part of the room, not just 10 pictures of the table (Stage B).
A few helpful terms in plain language:
- Visual token: a small piece of information from an image patch.
- Voxel: a tiny 3D box, like a 3D pixel or a LEGO brick in a grid.
- Attention: a score that says how much one piece of information cares about or matches another piece.
- Pruning: removing tokens that are repeated or less useful, to save time and memory.
What did they find?
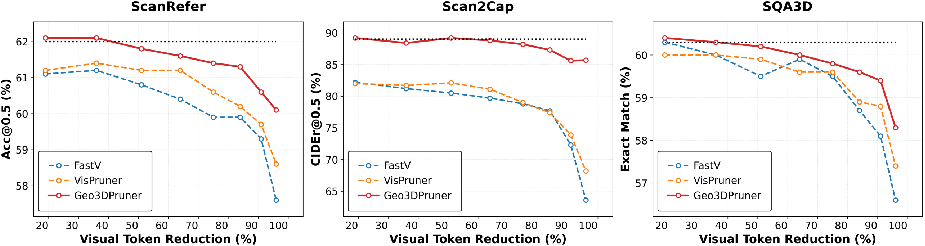
Across several 3D tasks (like finding objects described by text, writing descriptions for objects in a scene, and answering questions about the scene), Geo3DPruner:
- Removed about 90% of the visual tokens but kept over 90% of the original performance.
- Beat other popular pruning methods that either use text to guide pruning or only look at visuals frame-by-frame.
- Worked well on both shorter (16-frame) and longer (32-frame) videos.
- Sometimes even did slightly better than the unpruned model when pruning a small amount, because it removed noisy or redundant tokens.
Why this is impressive:
- Keeping only 10% of the tokens but still performing almost as well means the AI can run faster, use less memory, and respond more quickly, which is crucial for real-time applications.
Why does this matter?
- Faster, cheaper, and greener AI: Less computation means quicker answers and less energy use.
- Better for real-world uses: Robots, AR/VR headsets, and home assistants need to understand 3D spaces in real time. This method helps them do that efficiently.
- Scales to bigger scenes and longer videos: By removing repeated information across frames while keeping coverage of the whole scene, the method lets AI handle more data within limited memory.
Final takeaway
Geo3DPruner shows a smart way to compress 3D video information: use geometry to spot duplicates across frames, keep the best views of each 3D spot, and make sure the final selection covers the whole scene. The result is much faster processing with almost no loss in accuracy—exactly what’s needed to bring advanced 3D understanding into everyday devices and real-time applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper and points to actionable directions for future research:
- Robustness to geometry errors: The method relies on geometry-aware attention and predicted camera parameters/depth from VGGT; quantify how pruning quality degrades under noisy geometry, calibration errors, or poor reconstruction and develop uncertainty-aware pruning that adapts to geometry confidence.
- Static-scene assumption: The voxel assignment and cross-view consistency implicitly assume rigid scenes; evaluate and extend Geo3DPruner to dynamic environments with moving objects, human activity, or non-rigid deformations where voxel consistency breaks.
- Domain generalization: Experiments are limited to indoor ScanNet-derived tasks; assess performance on outdoor, large-scale, cluttered, or low-texture scenes (e.g., Matterport3D, KITTI, nuScenes, Replica) and study transfer across domains and sensors.
- Real-time and streaming constraints: Global cross-frame attention is non-causal and requires access to all frames; explore streaming/online pruning with partial context (e.g., sliding windows, causal attention, memory modules) and measure latency in real-time settings.
- Computational overhead and end-to-end efficiency: Adding a frozen VGGT-1B geometry encoder introduces pre-processing cost; report wall-clock latency, GPU memory, throughput (tokens/sec), and energy consumption for the full pipeline and quantify net gains vs. baseline and other pruning methods.
- Scalability of attention map computation: The global attention map is O(N2) in tokens; characterize memory/time overhead for typical N (e.g., 32 frames at 576 tokens/frame) and investigate low-rank, sparse, or blockwise approximations to reduce attention cost.
- Hyperparameter sensitivity and adaptivity: Voxel size δ=0.1m, intra-voxel ratio α=50%, and SDP step K=8 are fixed; perform systematic sweeps, per-scene adaptation, or learned policies to optimize δ, α, and K based on scene scale, token budget, and task.
- Extreme pruning regimes: Results cover up to 90% pruning; test ultra-aggressive settings (e.g., 95–99% reduction) and characterize failure modes and graceful degradation across tasks.
- Longer sequences and higher resolutions: Evaluate pruning effectiveness beyond 32 frames and at higher input resolutions; analyze how redundancy and coverage trade-offs scale with sequence length and pixel granularity.
- Ground-truth depth vs. learned geometry: Although ScanNet provides depth, the paper opts for VGGT features; compare pruning guided by ground-truth depth/poses versus learned geometry, and study hybrid schemes combining both.
- Fusion strategy of 2D and 3D features: Geometry-augmented features use simple addition F=E+G; investigate more principled fusion (e.g., cross-attention, gating, modulation, residual adapters) and its impact on pruning decisions and performance.
- Text-conditioned pruning: The approach is task-agnostic and vision/geometry-guided; explore combining geometry cues with text-guided relevance (question or instruction tokens) to better serve text-specific tasks (QA, grounding with complex referring expressions).
- Token merging vs. hard pruning: Geo3DPruner selects tokens but does not merge or compress them; study learned intra-voxel aggregation, pooling, or token merging to preserve information while further reducing token count.
- Diversity selection optimality: SDP is an iterative heuristic; formalize voxel selection as submodular maximization, determinantal point processes, facility-location, or clustering-based coverage, and benchmark against theoretically grounded diversity objectives.
- Instance-awareness without segmentation: SDP aims to suppress intra-object redundancy but does not use instance segmentation; examine integrating lightweight instance proposals or objectness priors to enforce instance-level diversity more directly.
- Occlusion and viewpoint extremes: Analyze performance in scenes with heavy occlusions, extreme viewpoints, specular/transparent surfaces, or motion blur; develop occlusion-aware pruning that prioritizes complementary viewpoints.
- Cross-encoder generality: The pipeline uses SigLIP (2D) and VGGT (3D) with Qwen2-7B; test other visual encoders (e.g., CLIP variants, InternViT) and geometry models (DUSt3R/MASt3R/Fast3R), and quantify sensitivity to backbone choices.
- Training-time adaptation: The method is training-free at inference; evaluate whether fine-tuning the VideoLM (or lightweight adapters) with pruned-token distributions improves downstream accuracy and robustness.
- Question-conditioned frame sampling: Only uniform sampling is used; explore content- or geometry-aware frame selection policies (e.g., coverage maximization, viewpoint diversity) tailored to the text query and token budget.
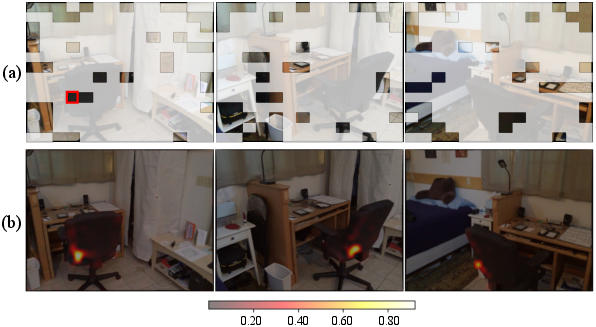
- Quantitative spatial coverage metrics: Beyond qualitative visualizations, develop metrics to quantify spatial/instance coverage of retained tokens (e.g., fraction of object boxes covered, voxel occupancy diversity) and use them to drive or evaluate pruning.
- Error detection and recovery: Investigate mechanisms to detect harmful pruning decisions (e.g., missed objects critical to the query) and to dynamically reallocate tokens (fallback frames, re-expansion) when confidence drops.
- Multi-camera or multi-modal inputs: Extend the approach to multi-camera setups and additional modalities (IMU, audio), addressing cross-sensor alignment and pruning across heterogeneous streams.
- Calibration and camera parameter modeling: The geometry head predicts intrinsics/extrinsics; report calibration accuracy, failure cases (e.g., rolling shutter, lens distortion), and its impact on voxel assignment and pruning reliability.
- Safety-critical applications: For embodied or assistive scenarios, assess whether pruning affects safety-related reasoning (e.g., obstacle detection) and devise conservative policies that guarantee minimum coverage of critical regions.
- Reproducibility details: Provide full hyperparameters, seeds, and open-sourced implementation of the geometry-attention extraction and voxel assignment steps to ensure exact replication and facilitate benchmarking across labs.
Practical Applications
Practical Applications of Geo3DPruner
Geo3DPruner introduces a geometry-guided, two-stage token pruning pipeline (intra-voxel view-consistency and inter-voxel spatial-diversity) that removes 60–90% of visual tokens from 3D spatial videos while preserving 92–99% of task performance on 3D grounding, dense captioning, and QA. This enables faster, cheaper, and more scalable 3D video-language inference with minimal accuracy loss.
Below are actionable use cases and their feasibility, organized by deployment horizon.
Immediate Applications
The following applications can be deployed now with modest engineering effort, using the released code and existing 3D video-language stacks.
- Geo-accelerated 3D VLM inference for existing products
- Sectors: software, cloud/edge AI platforms, MLOps
- Tools/products/workflows:
- Integrate Geo3DPruner as a preprocessing layer in Video-3D LLM/VG LLM pipelines (e.g., SigLIP + VGGT + Qwen2/LLaVA-Video).
- Workflow: run geometry encoder → voxelize frames → intra-voxel pruning (α ≈ 50%) → inter-voxel iterative selection → feed compact tokens to the LLM.
- Offer as a “geometry-guided token reducer” SDK or a Triton/TensorRT microservice to cut serving latency and GPU memory.
- Assumptions/dependencies: access to a geometry encoder (e.g., VGGT) and multi-view RGB; works best for indoor/static scenes; mild domain adaptation for out-of-distribution content may be needed.
- On-device or edge 3D understanding for AR/VR headsets and mobile robots
- Sectors: AR/VR/XR, robotics
- Tools/products/workflows:
- Deploy pruning to keep 3D QA, dense captioning, and grounding within mobile/edge compute budgets, extending battery life and FPS.
- Pair with lightweight geometry models (or distilled VGGT) for embedded inference.
- Assumptions/dependencies: camera intrinsics/extrinsics or reliable pose/depth estimation; thermal/power constraints; careful latency profiling (prune early to save most FLOPs).
- Warehouse, logistics, and AMR navigation with language grounding
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows:
- Use pruned tokens to sustain multi-camera, multi-view perception for SLAM-enhanced language tasks (e.g., “find the blue bin next to conveyor 3”).
- Enable higher-resolution or more frames without exceeding compute limits, improving spatial grounding.
- Assumptions/dependencies: static-ish layouts or robust handling of moderate dynamics; safety validation for failure cases (small-object misses).
- Indoor AEC/Facilities scanning and rapid semantic reporting
- Sectors: construction (AEC), digital twins, facility management
- Tools/products/workflows:
- Faster dense captioning/object grounding on RGB-D/phone LiDAR scans; generate room-level semantic summaries, asset lists, and QA reports on the fly.
- Integrate into BIM/twin pipelines as a semantic enrichment stage.
- Assumptions/dependencies: indoor bias (trained/evaluated on ScanNet-like scenes); IFC/BIM integration via adapters.
- Retail and smart-store analytics on edge cameras
- Sectors: retail, IoT/edge
- Tools/products/workflows:
- Multi-view 3D grounding for planogram compliance and shelf audits; in-store assistants answer “Where is X?” with 3D localization.
- Use pruning to scale to more camera feeds per GPU.
- Assumptions/dependencies: store layout variability; lighting/occlusion robustness; calibration for multi-camera setups.
- Smart-home assistants with spatial understanding
- Sectors: consumer devices, smart home
- Tools/products/workflows:
- Run 3D captioning/QA locally (privacy-friendly) on home robots or smart displays: “Which chair is closest to the window?”
- Pruning reduces the memory footprint so models fit on consumer-grade GPUs/NPUs.
- Assumptions/dependencies: reliable pose/depth estimation (monocular or RGB-D); guardrails for privacy and consent.
- Faster human-in-the-loop 3D labeling and dataset curation
- Sectors: data services, academia, simulation
- Tools/products/workflows:
- Use pruned inference for pre-annotations (3D boxes + captions + referring expressions) to accelerate labeling UIs.
- Active-learning loops can score uncertainty over compact tokens to prioritize labeling.
- Assumptions/dependencies: annotation QA still required; domain shifts (industrial/outdoor) may need fine-tuning.
- Cost and carbon footprint reduction for cloud 3D video analytics
- Sectors: cloud, sustainability
- Tools/products/workflows:
- Lower GPU-hours per scene by 60–90% token cuts; track “cost-per-scene” and “kgCO2e-per-scene” KPIs in MLOps dashboards.
- Assumptions/dependencies: pruning overhead is amortized by earlier layers; net savings depend on where in the stack pruning occurs and batching.
- Academic benchmarking and method development
- Sectors: academia/research
- Tools/products/workflows:
- A strong, training-free baseline for 3D-aware token pruning; plug into new VLMs to test generalization.
- Ablations on voxel size, α, and iterative K can rapidly guide architecture design.
- Assumptions/dependencies: open-source code availability; reproducibility of geometry encoder outputs.
Long-Term Applications
These concepts are promising but need further research for robustness, broader domain coverage, or certification.
- Real-time 4D spatial assistants on AR glasses
- Sectors: AR/XR, assistive tech
- Tools/products/workflows:
- Always-on spatial QA, step-by-step guidance, and safety alerts in dynamic scenes with persistent state.
- Research needed: streaming geometry estimation (e.g., StreamVGGT) under motion/occlusion; energy-aware scheduling; continual scene-state maintenance.
- City-scale digital twins with semantic layers
- Sectors: smart cities, infrastructure, energy
- Tools/products/workflows:
- Periodic scans (vehicle/foot-mounted cameras) pruned for scalable semantic indexing and QA over large environments.
- BIM/IFC and GIS integration to answer multi-building queries.
- Research needed: outdoor robustness (weather, lighting), multi-sensor fusion (LiDAR/cameras), standard-compliant data pipelines, storage/query optimization.
- Autonomous driving and outdoor robotics with 3D VLMs
- Sectors: automotive, drones, delivery robots
- Tools/products/workflows:
- Language-based 3D reasoning for scene understanding, hazard explanation, and operator queries.
- Research needed: training on outdoor datasets; fast, accurate geometry under high ego-motion; safety cases and certification; real-time guarantees.
- Surgical AR and clinical spatial assistants
- Sectors: healthcare
- Tools/products/workflows:
- In-procedure spatial QA (“Which instrument is closest to the retractor?”), sterile field monitoring, and OR inventory management.
- Research needed: medical-grade reliability, regulation (FDA/CE), data privacy, domain-specific geometry priors, robust small-object retention.
- Industrial inspection and disaster response at the edge
- Sectors: energy, utilities, public safety
- Tools/products/workflows:
- Drone/robot inspections with pruned 3D captioning/QA for cracks, corrosion, or hazards; bandwidth-efficient transmission using compact token streams.
- Research needed: harsh environment robustness, long-range geometry estimation, mission-critical failure modes, human-in-the-loop workflows.
- Privacy-preserving, on-device spatial understanding
- Sectors: policy, consumer devices, enterprise IT
- Tools/products/workflows:
- Keep inference local and share only compact, de-identified semantic outputs for compliance.
- Research needed: formal privacy guarantees (e.g., DP), secure enclaves, standards for summarization without leakage.
- Green AI standards and procurement policies for multimodal systems
- Sectors: policy, standards bodies
- Tools/products/workflows:
- Efficiency benchmarks (tokens per scene, FLOPs, kgCO2e) for 3D VLM deployments; procurement checklists favoring geometry-aware pruning.
- Research needed: standardized reporting, third-party audits, lifecycle impact models for multimodal systems.
- Consumer-grade VR training and education with spatial QA
- Sectors: education, workforce training
- Tools/products/workflows:
- Run spatially coherent QA and dense captioning on commodity hardware for training simulators (labs, factories, emergency response).
- Research needed: content alignment for specific curricula; robust performance in crowded, dynamic virtual scenes.
Cross-cutting Assumptions and Dependencies
- Geometry encoder availability: current performance relies on a capable geometry module (e.g., VGGT) to produce cross-frame attention. Simpler similarity-based versions work but degrade results.
- Scene characteristics: best validated on indoor, relatively static scenes (ScanNet-like); dynamic/outdoor domains need adaptation and additional training data.
- Sensor inputs: RGB-only pipelines must reliably estimate depth/pose or use multi-view consistency; RGB-D or calibrated multi-camera setups simplify deployment.
- Hyperparameters and budgets: voxel size (e.g., 0.1 m), intra-voxel α, and iterative selection K affect coverage/performance; tuning is recommended per domain.
- Net efficiency: to realize real-world speedups, prune as early as possible in the pipeline; measure end-to-end latency including geometry extraction overhead.
- Safety and reliability: for safety-critical use, add conservatism (e.g., higher token budgets around small/critical objects), monitoring for failure modes, and human oversight.
By introducing geometry-aware, cross-frame pruning that preserves spatial completeness, Geo3DPruner immediately unlocks faster and cheaper 3D video-language systems and lays the groundwork for long-horizon spatial assistants and large-scale digital twins.
Glossary
- 3D dense captioning: A task that detects objects in a 3D scene and generates textual descriptions for them. "This property is essential for object-centric 3D tasks, including 3D dense captioning and 3D visual grounding."
- 3D positional encodings: Encodings that inject 3D spatial information into visual tokens to make them position-aware. "transforms depth information into 3D coordinates and integrates these with the visual embeddings using 3D positional encodings."
- 3D spatial videos: Video sequences augmented with spatial cues (e.g., poses, depth) to represent 3D scenes. "reformulate 3D scenes as 3D spatial videos, defined as sequences of image frames augmented with spatial cues such as camera poses and depth information."
- 3D visual grounding: Localizing objects in a 3D scene based on natural language descriptions. "including 3D dense captioning and 3D visual grounding."
- BLEU-4: A 4-gram precision-based metric for evaluating generated text against references. "such as BLEU-4~\cite{BLEU} and CIDEr~\cite{CIDEr}"
- Camera extrinsics: Parameters specifying a camera’s orientation and position in the world coordinate system. "camera extrinsics "
- Camera intrinsics: Parameters that define a camera’s internal characteristics (e.g., focal length, principal point). "intrinsics "
- CIDEr: A consensus-based metric for evaluating image/video captions by weighting n-grams by term frequency-inverse document frequency. "such as BLEU-4~\cite{BLEU} and CIDEr~\cite{CIDEr}"
- CLS token: A special classification token used in Transformers to aggregate information for downstream tasks. "identifying salient tokens via cross-attention with a [CLS] token"
- Cross-attention: An attention mechanism that relates one modality or sequence to another (e.g., text to vision). "Text-Guided Pruning~\cite{FastV, SparseVLM, PyramidDrop, FitPrune}, which exploits cross-attention between textual and visual features"
- Cross-frame attention: Attention computed across tokens from different frames to capture temporal or multi-view relations. "the global attention map produced by the cross-frame attention layers"
- Cross-view correspondences: Associations between pixels or features that refer to the same 3D point across different views. "encode pixel-aligned 3D geometry and cross-view correspondences within a unified framework."
- Exact match (EM): A metric that measures whether a predicted answer matches a reference answer exactly. "we use CIDEr~\cite{CIDEr} and exact match~(EM) as evaluation metrics."
- Feed-forward reconstruction paradigms: Approaches that infer 3D scene geometry in a single forward pass without per-scene optimization. "feed-forward reconstruction paradigms have emerged, aiming to infer scene geometry through a single network forward pass."
- Geometry-augmented visual features: Visual features enhanced by adding geometry-derived representations to encode spatial priors. "We construct geometry-augmented visual features as "
- Geometry-aware global attention: Attention that incorporates geometric cues to model relevance across frames/views. "Geo3DPruner first models cross-frame relevance through geometry-aware global attention"
- Geometry encoder: A network branch dedicated to extracting 3D geometric features from video frames. "a 3D geometry encoder~(\eg, VGGT~\cite{VGGT}) captures 3D geometric features."
- Global attention map: The full attention matrix capturing pairwise relevance among all tokens across frames. "let represent the global attention map produced by the cross-frame attention layers"
- Global cross-frame relevance: A measure of how tokens from different frames relate globally within a scene. "leverages global cross-frame relevance to eliminate visual redundancy arising from different viewpoints"
- Inter-Voxel Spatial Diversity Pruning (SDP): A pruning stage that selects a spatially diverse subset of voxels to preserve scene coverage. "we propose Inter-Voxel Spatial Diversity Pruning~(SDP)"
- Intersection over Union (IoU): The ratio of intersection to union between predicted and ground-truth regions, used for localization accuracy. "thresholded accuracy based on Intersection over Union~(IoU) thresholds"
- Intra-Voxel View Consistency Pruning (VCP): A pruning stage that selects the most representative multi-view tokens within each voxel. "we propose Intra-Voxel View Consistency Pruning~(VCP)"
- Inverse camera projection: The operation mapping 2D pixel coordinates and depth into 3D world coordinates. "its 3D position in the world coordinate system is computed via inverse camera projection."
- Long-range dependencies: Relationships between distant tokens or frames modeled by attention mechanisms. "a global attention mechanism models long-range dependencies across inter-frame features"
- Multi-view stereo: A class of methods that reconstruct 3D geometry from multiple 2D images by matching across views. "learning-based multi-view stereo methods~\cite{MVSNet, CasMVSNet}"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities such as text and images/videos. "multimodal LLMs~(MLLMs)"
- Neural rendering: Techniques that synthesize novel views or reconstruct scenes using neural networks. "generalizable neural rendering methods~\cite{pixelNeRF, IBRNet}"
- Object-centric 3D scenes: Scenes where distinct objects are the primary focus of representation and reasoning. "in object-centric 3D scenes with high instance diversity"
- Pixel-aligned 3D geometry: 3D representations aligned per-pixel across views to facilitate correspondence and reconstruction. "representations that explicitly encode pixel-aligned 3D geometry"
- Point cloud: A set of 3D points representing scene geometry, often obtained from depth sensors or reconstruction. "point clouds, meshes"
- Pointmap-based representations: Structures that map image pixels to 3D points, enabling explicit 2D–3D alignment. "introduces pointmap-based representations that explicitly encode pixel-aligned 3D geometry"
- Pruning ratio: The proportion of tokens removed relative to the original count. "When the pruning ratio increases to 80\%"
- RGB-D: Data combining RGB images with depth information for 3D understanding. "ScanNet~\cite{ScanNet} is a large-scale RGB-D video dataset"
- Self-attention mechanisms: Attention computed within a single sequence to relate tokens to each other. "through internal self-attention mechanisms"
- Spatial diversity: Ensuring retained tokens cover varied spatial regions or objects in a scene. "overlooking the spatial diversity of retained tokens"
- Spatiotemporal tokens: Tokens representing combined spatial and temporal information in videos. "PruneVid~\cite{PruneVid} merges spatiotemporal tokens"
- Subset selection problem: Choosing an optimal subset (e.g., of voxels) under a budget to maximize coverage or utility. "we formulate the subsequent voxel-level pruning as a subset selection problem"
- Token budget: A fixed limit on the number of tokens allowed for processing. "until the token budget is met."
- Uniform frame sampling: Evenly selecting frames from a video to limit token count while maintaining coverage. "a uniform frame sampling strategy is applied"
- Video-LLMs (VideoLMs): Models trained to understand and reason over video and language jointly. "video-LLMs~(VideoLMs)"
- Visual token pruning: Reducing the number of visual tokens fed to an LLM to improve efficiency. "visual token pruning strategies"
- Voxel: A volumetric element in 3D space used to discretize and index scene locations. "each token is assigned to a voxel."
- Voxel-local attention submatrix: The attention submatrix restricted to tokens within the same voxel. "We extract the voxel-local attention submatrix from the global attention map:"
- Voxel size: The physical edge length defining the resolution of the voxel grid. "Using a predefined voxel size ~(\eg, 0.1m)"
- View consistency: The property that features from different views corresponding to the same 3D point should be coherent. "overlook the view consistency of spatial videos"
Collections
Sign up for free to add this paper to one or more collections.

