- The paper introduces a novel mutual information approach to token pruning, directly linking visual and textual embeddings.
- It employs a greedy submodular optimization framework, yielding a (1-1/e) approximation guarantee for efficient token selection.
- The method significantly reduces computational cost by retaining only the most semantically relevant tokens across diverse MLLM architectures.
Introduction
The computational burden of Multimodal LLMs (MLLMs) is driven largely by the need to process high numbers of visual tokens, due to the quadratic complexity of attention mechanisms particularly for vision-LLMs handling high-resolution images. Although most current token pruning techniques utilize attention scores extracted from the vision encoder or LLM decoder as a proxy for token importance, these approaches are limited by architectural biases and insufficient alignment with the actual semantics targeted by the user's prompt. The paper “MI-Pruner: Crossmodal Mutual Information-guided Token Pruner for Efficient MLLMs” (2604.03072) advances a principled, information-theoretic token pruning approach by explicitly utilizing mutual information (MI) between visual and textual embeddings in the projection space, decoupled from model-specific attention heuristics.
Methodology
MI-Pruner introduces a submodular optimization framework for token selection, grounded in the formalism of mutual information. Visual (V) and textual (T) embeddings are extracted via the standard MLLM encoder-projection pipeline. The aim is to maximize the mutual information between a pruned subset of visual tokens Vkeep⊂V and the textual context T. This is operationalized through a greedy strategy, leveraging conditional independence assumptions, which renders the selection problem tractable and maintains a (1−1/e) approximation guarantee.
After normalization onto the hypersphere, similarity matrices for both crossmodal (vi, tj) and intra-modal (vi, vj) pairs are computed. These are transformed into softmax-based conditional probability distributions, yielding pointwise mutual information (PMI) values for each token pair. Importantly, the scoring aggregates the maximal PMI over text tokens (“pivot word”) for each visual token, and maximal intra-modal redundancy (“pivot patch”), enabling both high relevance to the prompt and diversity among the selected visual patches.
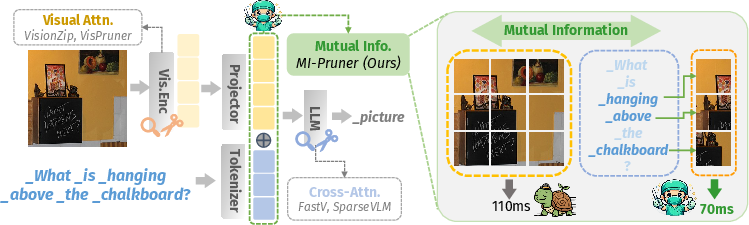
Figure 1: Overview of MI-Pruner, contrasting attention-based pruning with MI-based scoring in the projection space.
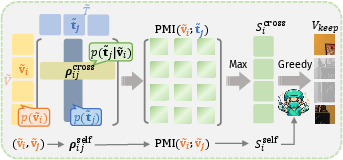
Figure 2: Illustration of MI-based pruning logic using crossmodal and internal similarity matrices to construct the PMI calculation.
Pruning Algorithm and Efficiency
The greedy selection process ranks candidate tokens according to their MI-derived marginal gain, optionally balancing crossmodal relevance (parameter λ) against redundancy. This is achieved without reliance on decoder/encoder internal attention weights, making MI-Pruner model-agnostic and highly efficient. The selection step exhibits linear time complexity relative to the number of input tokens, which is a substantial improvement over classic greedy search or combinatorial diversity approaches.
Experimental Evaluation
Extensive benchmarking demonstrates that MI-Pruner outperforms both attention-based and diversity-driven pruning methods across a suite of widely adopted datasets (GQA, SQA, TextVQA, MMVet, MMET0, POPE) and MLLM platforms (LLaVA1.5, Qwen2VL/3VL, Video-LLaVA). Strong results are maintained even under extreme compression rates (as low as 5% of tokens retained in video QA tasks) without significant decline in accuracy or task performance. Notably, MI-Pruner maintains a balanced and robust “Yes/No” distribution on object hallucination detection tasks (POPE), where competing methods often degrade substantially.

Figure 3: Pruning visualization on LLaVA1.5-7B. MI-Pruner selectively preserves queried semantic regions as the token budget decreases, whereas baselines increasingly omit relevant content.
Generalization and Model-Agnostic Deployment
Unlike attention-based approaches that fail to generalize to newer models lacking explicit [CLS] or fixed architectural conventions, MI-Pruner’s design facilitates seamless application to models of diverse architectures and input regimes (static/dynamic resolution). Experiments on Qwen3VL demonstrate consistent selection of prompt-relevant patches while avoiding common failure modes of attention heuristics, such as redundancy and prompt-agnostic bias.
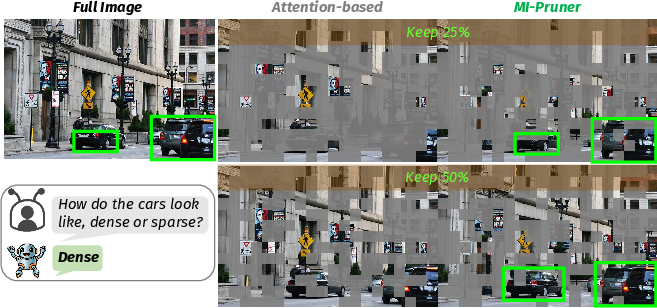

Figure 4: MI-Pruner pruning effects on Qwen3VL-2B, retaining prompt-aligned object regions adaptively.
Computational and Memory Efficiency
Empirical measurements highlight MI-Pruner’s low memory footprint and significantly reduced latency relative to attention-based or diversity-maximizing counterparts. The simplicity of required operations—projection space normalization, similarity computation, and heap-based top-k selection—facilitates practical integration into existing deployment pipelines with minimal overhead.
Ablation and Analysis
The study isolates the utility of max versus mean aggregation in PMI computation, showing that max aggregation provides superior sensitivity to the target object. The analysis of the balancing factor T1 reveals that open-ended question answering benefits from considering intra-modal diversity, whereas categorical or closed-form datasets are well served by prioritizing crossmodal relevance exclusively. Finally, the temperature parameter T2 is validated through ablation, with T3 yielding strongest overall robustness.
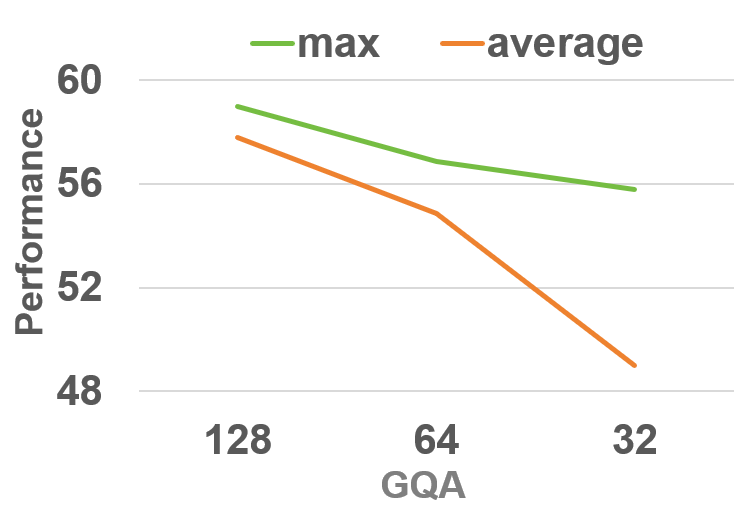
Figure 5: Aggregation strategy ablation results, where maximal PMI aggregation achieves clearer prompt-object alignment.
Theoretical and Practical Implications
The shift from attention-based heuristics to mutual information–based scoring establishes a more interpretable and theoretically sound framework for token pruning. Practically, this directly enhances the scalability of large MLLMs, enabling real-time deployment in latency- and compute-constrained environments. The method’s model-agnostic nature and demonstrated efficiency suggest wide applicability in both research and production settings. Future directions include relaxation of the uniform prior assumption for visual tokens and potential extension to joint pruning of textual tokens—especially for information-dense “needle-in-a-haystack” scenarios.
Conclusion
MI-Pruner introduces a principled, efficient, and highly effective paradigm for token pruning in MLLMs, leveraging mutual information as a direct measure of token relevance and redundancy in the projection space. The approach achieves state-of-the-art accuracy and inference efficiency across major model architectures and datasets, while providing interpretability and theoretical guarantees absent in prior art. The formulation serves as a foundational advance towards scalable, context-aware multimodal systems and offers a template for further research in efficient multimodal representation learning.