- The paper presents a novel multi-stage pruning framework using hierarchical segmentation, frame-level diversity maximization via DPP, and progressive layer-level token reduction.
- Empirical results demonstrate up to 76% FLOPs reduction while retaining over 98% performance on VideoLLM benchmarks, even with aggressive token pruning.
- The training-free, plug-and-play approach enables real-time video processing on long-duration content and paves the way for efficient multimodal models.
HieraVid: Hierarchical Token Pruning for Fast Video LLMs
Introduction and Motivation
The deployment of Video LLMs (VideoLLMs) is fundamentally hindered by the excessive computational cost induced by the quadratic complexity of self-attention with respect to input sequence length. Standard VideoLLMs inherit the inefficiency of processing all visual tokens with equal importance, leading to substantial redundancy due to the temporal continuity and frequent static content in videos. This inefficiency extends to both memory consumption and inference latency, severely limiting practical utility, especially for long-duration or real-time video understanding. Existing state-of-the-art solutions are typically constrained to either pre-LLM or post-encoder pruning and commonly leverage proxy metrics (attention scores, cosine similarities), which do not fully leverage the hierarchical structural properties inherent in video and transformer architectures.
HieraVid Framework
HieraVid introduces a multi-level and dynamic approach to visual token pruning specifically tailored for VideoLLMs. The pivotal insight is that both video data and the progression of multimodal information through transformer layers are inherently structured, and pruning should account for hierarchical video decomposition and internal layerwise redundancy propagation. HieraVid operates in three coordinated stages: segment-level merging, frame-level diversity maximization, and progressive layer-level pruning.
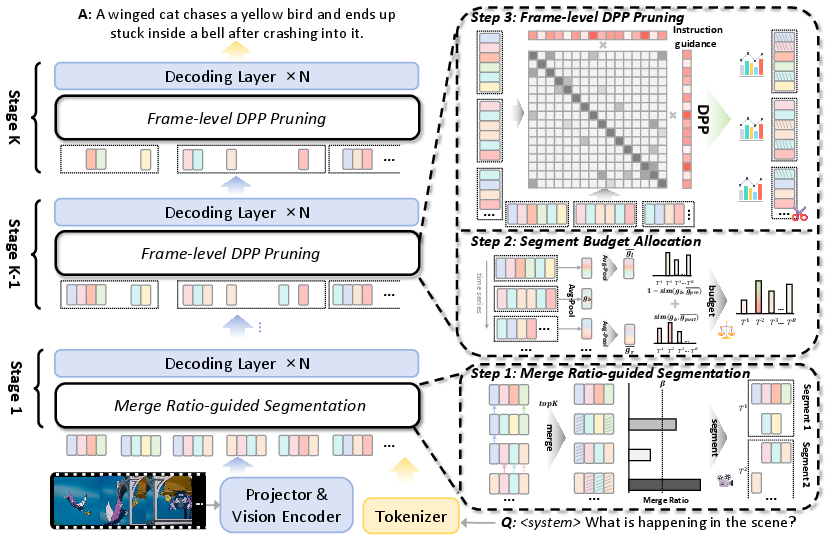
Figure 1: The HieraVid framework divides the pruning process into three stages: merge ratio-guided segmentation, segment budget allocation, and frame-level DPP pruning.
Segment-level Merge Ratio-guided Segmentation
Rather than employing coarse global frame features or hand-tuned temporal splits, HieraVid computes local contextual similarities between consecutive frames via a fine-grained spatial similarity map. It defines video segments using a merge ratio: for every frame, the spatial overlap with the previous frame is computed, and a new segment boundary is marked if the overlap falls below a threshold β. This achieves semantically coherent segments reflecting temporal dynamics. Within segments, static visual content (tokens at the same spatial location with high similarity across time) are merged—further reducing spatial-temporal redundancy while explicitly preserving diversity across segments.
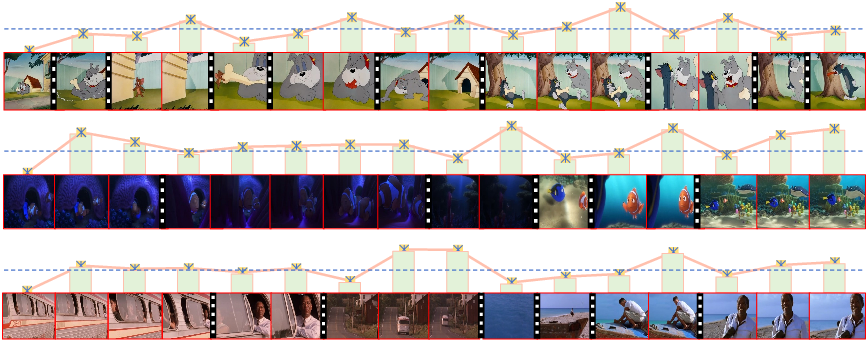
Figure 2: Segmentation visualization showing boundaries determined by low inter-frame similarity (lower bars/dashes). Segments group high-similarity frames, separated by transitions.
Each segment, after segmentation and merging, is allocated a dynamic pruning budget proportional to the representational diversity and relative uniqueness with respect to neighboring segments. This design ensures informative or scene-changing segments are pruned less aggressively, while redundant regions are heavily compressed.
Frame-level Diversity Maximization via DPP
Most prior methods focus solely on importance or relevance, which can induce representational collapse by over-selecting similar tokens. HieraVid instead applies segment-based Determinantal Point Process (DPP) sampling to maximize intra-segment diversity. Given visual token embeddings per segment, DPP constructs a kernel matrix incorporating both visual diversity (via the embedding inner product) and instruction relevance (softmax distance to the last instruction token). Token selection within each segment solves a max-determinant subset problem, efficiently yielding diverse representative frames, and thereby optimally preserves the informational content after aggressive pruning.
Layer-level Progressive Pruning
Transformer-based LLMs display a progressive information fusion pattern: lower layers primarily adapt visual information, middle layers integrate instruction-relevant visual tokens, and upper layers propagate fused multimodal representations. HieraVid exploits this by partitioning the LLM into N consecutive stages and assigning decreasing numbers of visual tokens deeper into the network. Early (shallow) layer pruning is thus minimized to preserve initial information flow, while pruning intensity is maximized in deeper layers where redundancy has compounded. This adaptive, stage-wise reduction balances the risk of early information loss against the inefficiency of redundant deep-layer computation.
Experimental Results
HieraVid’s efficacy is assessed across LLaVA-Video-7B, LLaVA-OneVision-7B, and Qwen2-VL benchmarks on multiple video understanding datasets, including NExT-QA, MVBench, EgoSchema, and VideoMME, covering a range of video durations and complexities.
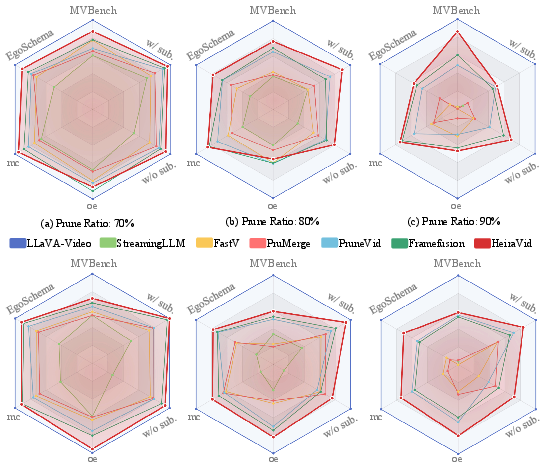
Figure 3: HieraVid consistently outperforms existing VideoLLM pruning methods across all pruning ratios and benchmarks, maintaining high accuracy with reduced FLOPs.
Notable outcomes:
- 30% token retention: HieraVid achieves 98.4% (LLaVA-Video-7B) and 99.3% (LLaVA-OneVision-7B) of the original performance with 75-76% FLOPs reduction.
- 10% token retention: It retains 92.4% and 94.8% of baseline performance, with computational costs down to 8-9% of original, surpassing all previous baselines.
- On long-form video benchmarks (VideoMME, videos up to 60 min), the segment-level approach delivers up to 2.6 percentage points higher accuracy than the best prior art.
- On Qwen2-VL, HieraVid attains 98.0% of the unpruned model's average score at 30% token budget.
Ablation Analyses
- Omitting layer-level balancing reduces average accuracy by >4%, underscoring the criticality of progressive pruning aligned with internal information flow.
- Disabling merge ratio-guided segmentation or switching to average pooling-based segmentation delivers notably inferior results, especially on long-form or complex scene videos.
- Replacing frame-level DPP with attention or mean similarity selection reduces accuracy by up to 14.6%, confirming the necessity of diversity-driven token selection, especially under aggressive pruning.
- Using only the last instruction token for instruction relevance in the DPP kernel outperforms approaches using all instruction tokens, consistent with observed integration patterns in multimodal LLMs.
Implications and Future Directions
HieraVid establishes a theoretically grounded, training-free paradigm for robust visual token sparsification in VideoLLMs. By integrating hierarchical video and model structure into the token selection process, the method achieves order-of-magnitude improvements in computational cost-efficiency while preserving downstream video understanding accuracy across diverse tasks and architectures.
On a practical level, HieraVid enables real-time and resource-constrained deployment of VideoLLMs on long-duration content, which was previously infeasible. Its training-free, plug-and-play nature facilitates integration into existing multimodal pipelines.
From a theoretical perspective, the work motivates deeper exploration into structured, model-aware tokenization schemes, including adaptive pruning policies coupled to LLM dynamics, and further opportunities in joint temporal-spatial-architecture co-adaptation. There is potential for unifying hierarchical token pruning methods with continual video understanding and efficient memory-augmented transformers to handle exascale visual data streams.
Conclusion
HieraVid leverages inherent video structure and internal multimodal information flow within LLMs to yield a hierarchical, diversity-preserving pruning framework for VideoLLMs. This method enables substantial acceleration and memory reduction in video understanding tasks without sacrificing semantic fidelity. The methodology and empirical results provide strong foundations for future scalable, efficient multimodal reasoning systems.