- The paper introduces Tango, a framework that leverages diversity-driven token selection and spatio-temporal merging to efficiently prune tokens in Video LLMs.
- It employs the ST-RoPE module to encode positional information, ensuring semantic and geometric integrity while achieving up to 1.88× inference speedup.
- Empirical results show that Tango retains over 98% accuracy at extreme token reductions, outperforming previous methods by up to 2.5% on multiple benchmarks.
Tango: Taming Visual Signals for Efficient Video LLMs
Motivation and Analysis of Token Pruning Limitations
Token pruning has become integral for achieving inference efficiency in Video LLMs (Video LLMs). Two broad paradigms have been adopted: top-k attention-based token selection and similarity-based clustering. The paper provides a rigorous analysis of both, demonstrating that top-k selection often fails due to the inherently multi-modal and long-tailed nature of the attention score distributions. Direct similarity-based clustering, on the other hand, leads to fragmented semantic regions and introduces noisy representations (Figure 1).
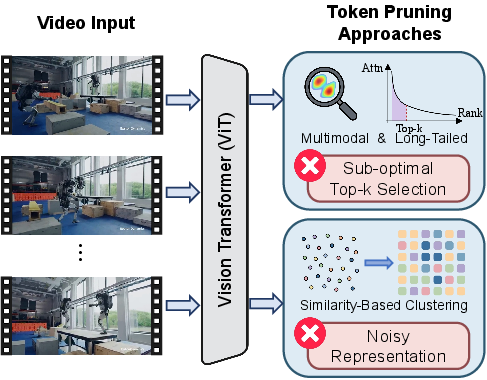
Figure 1: Top-k selection inadequately models multimodal attention, and direct clustering yields noisy, spatially fragmented clusters.
Closer investigation (Figure 2) reveals that salient regions in video frames–such as subtitles or objects–correspond to distinct attention distribution modes, but top-k pruning ignores this multimodality. Baseline similarity clustering methods further exacerbate representation noise by splitting coherent semantic objects across clusters, undermining object integrity in pooled features.

Figure 2: Clustering semantic tokens by similarity alone causes spatial fragmentation, whereas the proposed approach maintains geometric coherence.
Further empirical evidence (Figure 3) confirms that attention scores in video LLMs reliably exhibit long-tailed distributions with minimal variance across instances. Thus, any pruning method that aims for efficiency without major performance degradation must account for this distributional structure.
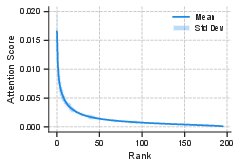
Figure 3: Attention scores are long-tailed and highly stable, underscoring the inadequacy of simplistic pruning heuristics.
Tango Framework: Diversity-Driven Token Selection and Spatio-Temporal Locality
The paper introduces Tango, a token reduction framework that addresses the above deficiencies. The approach integrates three modules:
- Temporal Video Segmentation (TVS): Identifies segments of static content by measuring inter-frame similarity, allowing maximum pruning of temporally redundant tokens.
- Salient Token Selection (STS): Expands the candidate set with an overcomplete pool, then applies density peaks clustering (DPC-KNN) to robustly cover semantic attention distribution modes and perform intra-cluster selection for diversity-driven token retention.
- Spatio-Temporal Merging (STM): Merges redundant features by clustering with an explicit spatio-temporal locality prior.
An overview of this pipeline is provided in Figure 4.
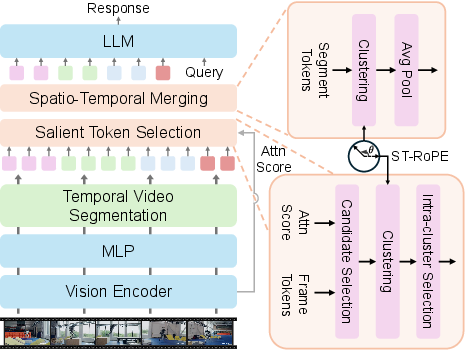
Figure 4: Tango pipeline: segmenting videos, selecting salient tokens via diversity and attention, and performing locality-preserving spatio-temporal merging.
Spatio-Temporal Rotary Position Embedding (ST-RoPE)
Central to Tango is the incorporation of a spatio-temporal locality prior within similarity calculations during clustering. The ST-RoPE module encodes positional information by rotating token embeddings along spatial and temporal axes. This modulation penalizes putative similarities between spatially and temporally distant tokens—an essential property for maintaining geometric and semantic object integrity during clustering (Figure 5).
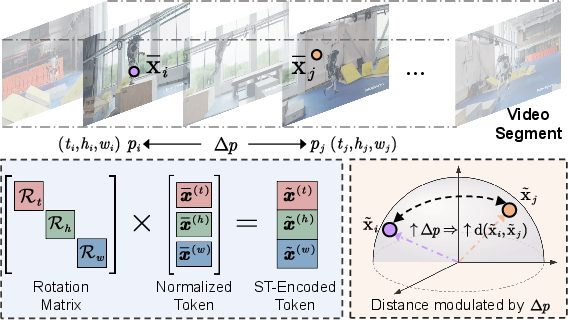
Figure 5: ST-RoPE encodes 3D spatio-temporal positions, promoting locality during feature aggregation.
Experimental Results and Numerical Highlights
Tango is evaluated on four video understanding benchmarks (Video-MME, MVBench, LongVideoBench, and MLVU) across three leading Video LLMs (LLaVA-OneVision-7B, LLaVA-Video-7B, Qwen2.5-VL-7B). The design achieves significant retention of task performance under extreme token budget reduction:
- With only 10% of video tokens retained, Tango preserves 98.9% of LLaVA-OV-7B's original performance and realizes a 1.88× inference speedup.
- Across all tested retention ratios (10%, 15%, 20%), Tango outperforms state-of-the-art pruning methods by margins of up to 2.5% in average accuracy, especially in low-token regimes.
- Gains generalize across model architectures: Tango consistently surpasses FastVID, HoliTom, and VisionZip on both LLaVA-Video-7B and Qwen2.5-VL-7B.
- Combining Tango's pre-LLM pruning with intra-LLM pruning yields additive gains, further enhancing efficiency with minimal degradation.
Scaling analyses (Figure 6) indicate robustness to increased frame counts—a critical property in settings with long-form or high-fps video inputs.
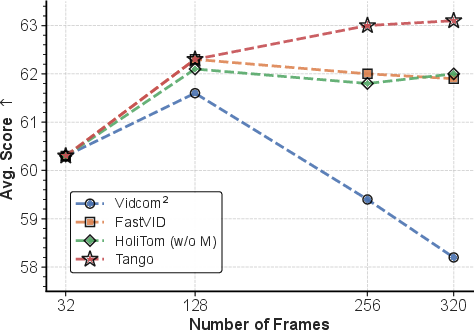
Figure 6: Tango maintains accuracy as input frame count scales, with consistent outperformance over other pruning approaches.
Detailed ablation studies demonstrate the core efficacy of both the diversity-driven token selection and ST-RoPE modules (Figure 7). Uniform or naive top-k strategies underperform dramatically compared to Tango’s approach, particularly on benchmarks requiring precise spatio-temporal reasoning.
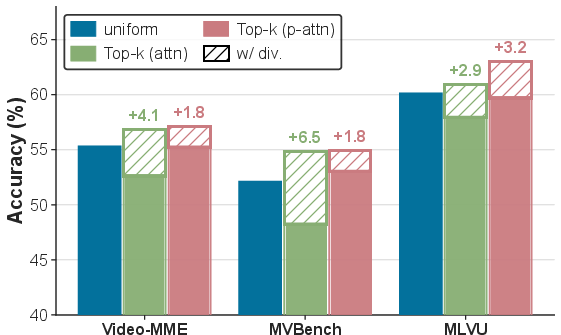
Figure 7: Diversity-driven selection method achieves strong gains over uniform and standard top-k strategies for salient token retention.
Tango's parameter sensitivity is moderate: a modest expansion coefficient for candidate set size and well-chosen RoPE base frequencies deliver optimal results without significant risk of instability or performance loss (Figure 8).
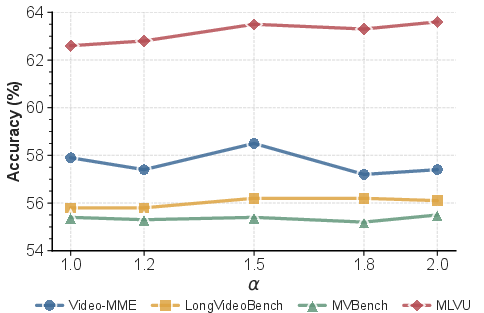
Figure 8: Accuracy remains stable across a range of expansion coefficients; moderate values yield the best trade-off.
Efficiency breakdown analysis (Figure 9) confirms that Tango achieves superior latency-accuracy trade-offs: maintaining 99.7% of full performance at 20% token retention with a 1.63× speedup.
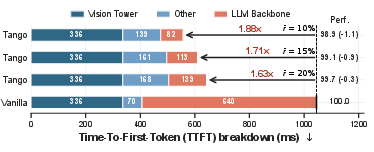
Figure 9: Tango offers near-lossless accuracy at high compression rates, with significant inference speedups.
Qualitative Insights and Analysis
Visualizations of token attention and clustering (Figures 12–14) expose Tango’s qualitative effectiveness at avoiding attention sinks, maintaining semantic coherence, and suppressing representation noise that plagues prior methods. Notably, ST-RoPE’s locality bias improves the geometric integrity of aggregated tokens even in challenging, cluttered video scenes.
Theoretical and Practical Implications
Tango advances the state-of-the-art in Video LLM efficiency by demonstrating that:
- Diversity-driven selection, informed by attention’s multi-modal distribution, is essential for information retention during aggressive token pruning.
- Spatio-temporal positional encoding via ST-RoPE enables clustering algorithms to produce more semantically meaningful, locality-preserving aggregates, with minimal computational overhead.
- The modularity and training-free nature of the method facilitates easy integration with existing Video LLMs, and is broadly adaptable to both pre-LLM and intra-LLM pruning architectures.
This judicious use of visual signals raises avenues for further improvements, such as dynamic adaptation of expansion and decay parameters, more nuanced modeling of spatio-temporal relations (potentially with learned priors or neural attention over ST-RoPE), and the extension of these techniques to even higher-resolution video understanding under severe memory constraints.
Conclusion
Tango systematically addresses critical shortcomings of current token pruning strategies in Video LLMs through diversity-driven token selection and explicit spatio-temporal locality encoding. Extensive experiments evidence strong numerical performance at extreme compression rates, broad generalizability, and superior efficiency–positioning Tango as a robust, practical framework for scalable multimodal AI systems. The theoretical underpinnings and empirical successes of Tango point to locality-aware, semantically diverse feature representations as a prerequisite for the next generation of efficient video-LLMs.

