- The paper introduces a head importance-aware framework that prunes visual tokens based on empirical head specialization and dynamic text guidance, eliminating the need for retraining.
- Using extensive ablation studies, it demonstrates that selective pruning retains up to 96% of performance at high pruning rates while significantly reducing computational load.
- It outperforms baseline methods in memory usage, latency, and accuracy across diverse vision-language benchmarks, underscoring its practical applicability.
Head Importance-Aware Visual Token Pruning for Multimodal Models: A Critical Assessment of HAWK
Motivation and Background
Multimodal LLMs (MLLMs) extend LLMs to vision-language settings via visual tokenization. The quadratic scaling of attention with token counts, especially for high-res images or videos, poses significant inference and memory bottlenecks. Visual token pruning has been explored to address these constraints, typically using context-agnostic (similarity-based), attention-based, or fine-tuned approaches. Most prior work assumes equipotent attention heads for token selection. This paper, "HAWK: Head Importance-Aware Visual Token Pruning in Multimodal Models" (2604.07812), dispels this assumption and proposes a comprehensive framework that leverages empirically-derived head importance and dynamic text guidance for pruning, aiming for task robustness, generalization, and maximal efficiency—fully training-free.
Empirical Analysis of Attention Head Specialization
Ablation studies conducted in this work reveal distinct functional roles across visual attention heads. Systematically masking heads led to marked, benchmark-consistent performance declines, directly evidencing non-uniform visual semantic extraction at the head level.
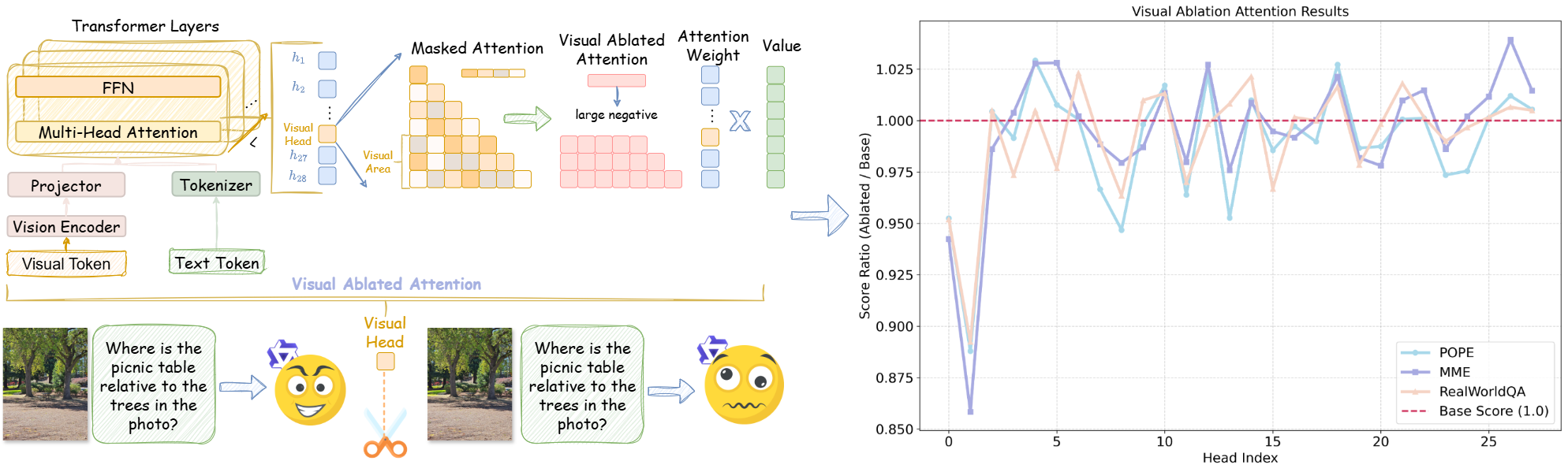
Figure 1: Head ablation clearly demonstrates non-uniform importance of visual attention heads, with specific heads being indispensable for visual comprehension across datasets.
Further cross-benchmark and cross-architecture analysis confirmed that this head ranking is both dataset- and model-intrinsic, not a product of specific task distributions. Certain heads consistently encode critical semantic features for fine-grained visual tasks, while others may aggregate redundancy or even noise.
The HAWK Pruning Framework
HAWK incorporates two central design components: (1) static, data-driven head importance weights, and (2) dynamic, RoPE-free text-guided attention scores. Head importance is quantified via per-head ablation on core datasets, measuring relative performance drops and averaging to produce a reusable weighting vector. Token importance under a specific input is computed as a weighted sum of text-guided relevance across all heads. RoPE is deliberately omitted to produce position-agnostic attention and focus on semantic alignment between text and vision.
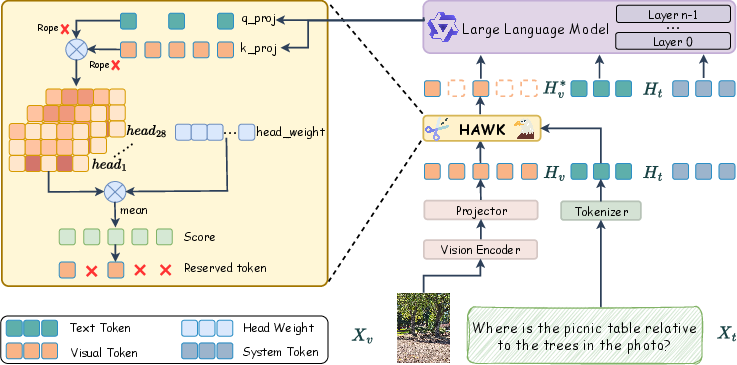
Figure 2: HAWK pipeline overview, integrating dynamic text-guided attention with static head importance for robust token selection.
This approach is modular and training-free, requiring only a one-time head analysis per architecture and supporting plug-and-play deployment.
Evaluation on Diverse Vision-Language Benchmarks
HAWK shows clear, consistent superiority to similarity- and attention-based pruning methods (specifically DivPrune, FastV, and CDPruner) across both fixed and variable resolution settings. At an 80.2% pruning rate on Qwen2.5-VL-7B, HAWK retains 96.0% of original performance, outpacing baselines by up to 3.4 points. Similar gaps are reported for InternVL3-8B and native resolution evaluations.
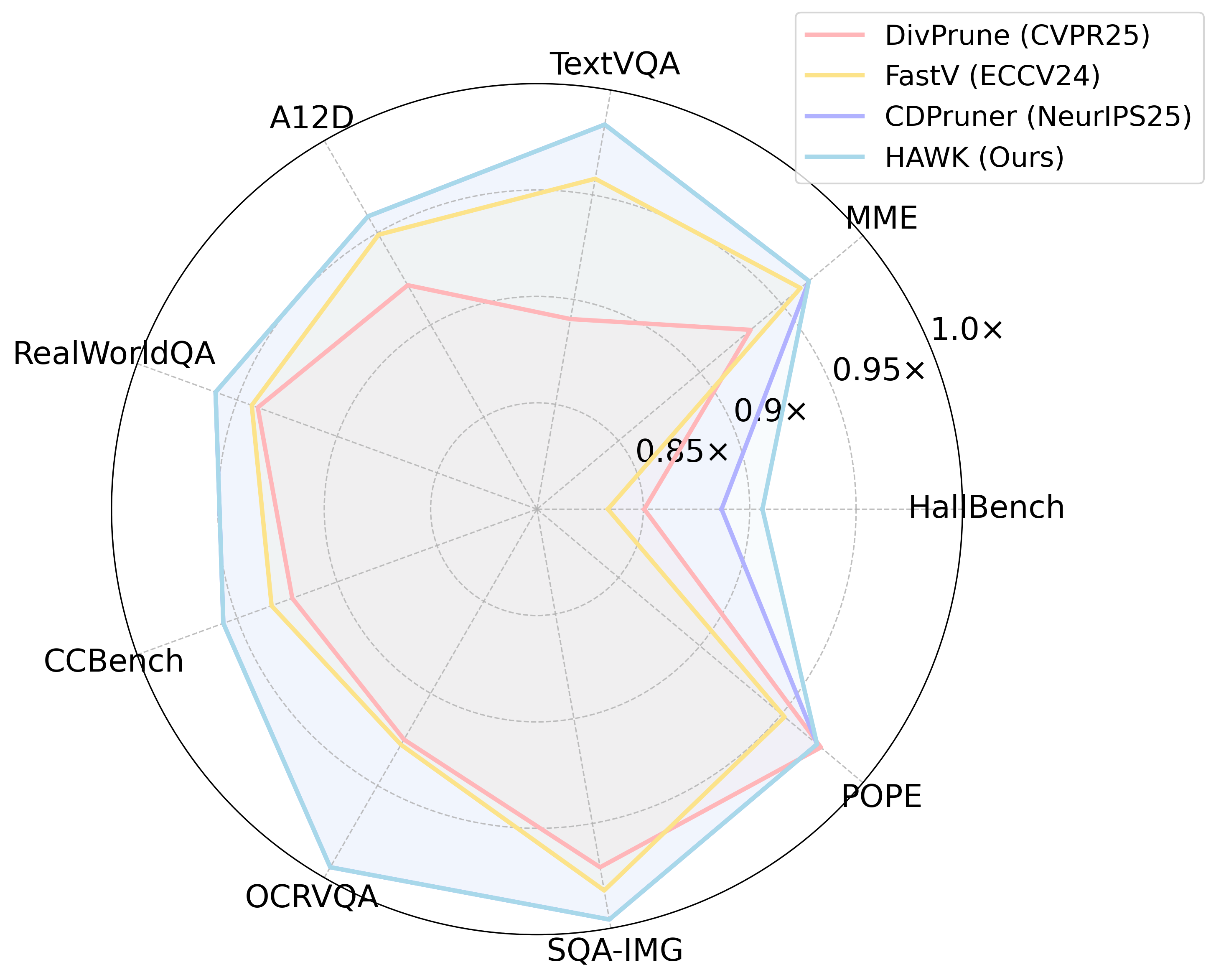
Figure 3: Across multiple benchmarks, HAWK provides the best trade-off between aggressive pruning and performance retention.
HAWK maintains accuracy with substantially reduced memory, attention computation, and E2E latency. For MME, latency is reduced to 74.4% of baseline values with negligible accuracy loss. For video tasks, where token lengths are extreme, HAWK again leads: at 60% pruning it preserves 98.8% of performance, and even at 90% pruning, it outperforms baselines by several points.
Component and Design Analysis
Ablation experiments validate each element of HAWK's design. Replacing head-aware weighting with uniform averaging, using suboptimal query tokens, or reintroducing positional encodings all produce significant performance degradation—demonstrating the necessity of each design choice for optimal pruning.
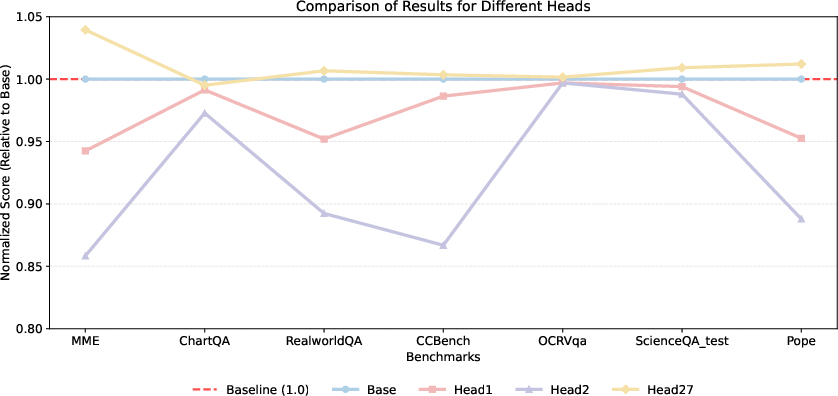
Figure 4: Visual head ablation shows performance is highly sensitive to head selection, confirming the necessity of head importance modeling.
Qualitative Insights
Attention heatmaps and qualitative assessments indicate HAWK discards semantically irrelevant tokens and preserves those critical for context-sensitive reasoning and visual text understanding tasks.
Figure 5: HAWK heatmaps reveal focused token retention aligned with textual queries, improving both interpretability and answer fidelity.
Implications, Limitations, and Future Directions
HAWK fundamentally shifts the token pruning paradigm by discarding the assumption of head symmetry, leading to improved robustness, task generalization, and efficiency without retraining. As visual foundation models increase in complexity, methods such as HAWK that incorporate architectural inductive bias through empirical analysis will be essential for scalable deployment, including on edge devices and in low-latency contexts.
One open challenge is the transferability of head importance weights across even more diverse MLLMs and tasks (e.g., multi-lingual or domain-specialized models), or adapting importance criteria to non-Transformer architectures. In addition, the current static weighting is computed offline, and (semi-)dynamic approaches or a mixture-of-experts formulation could further enhance adaptability.
Conclusion
HAWK establishes the necessity of head importance-aware strategies for visual token pruning in multimodal LLMs. Its combination of empirical head specialization and dynamic text-guided relevance yields consistent SOTA retention/efficiency trade-offs, especially for high-load image and video tasks. The training-free architecture makes HAWK readily deployable, and its head importance methodology sets a precedent for future pruning and interpretability research in large-scale multimodal systems.