- The paper introduces a debiased token estimator (DVTIE) that omits shallow-layer bias to better retain semantically important 3D tokens.
- It employs an adaptive token rebalancing (ATR) strategy to dynamically adjust pruning based on scene complexity.
- Experimental results demonstrate up to 90% token reduction with maintained or improved accuracy, cutting compute on benchmarks like Scan2Cap.
Efficient3D: Adaptive and Debiased Token Reduction for 3D Multimodal LLMs
Introduction
The exponential growth in Multimodal LLMs (MLLMs), particularly in 3D scene understanding and spatial reasoning, has imposed significant inference and resource demands due to the high dimensionality of 3D input features and expansive model architectures. "Efficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs" (2604.02689) systematically addresses these scalability bottlenecks by introducing a robust token pruning framework that significantly reduces computational overhead while retaining, and in some cases surpassing, the semantic completeness and prediction accuracy of baseline models.
Motivation and Architectural Bottlenecks
Traditional visual token pruning schemes aggregate attention patterns across all layers to determine token importance, leading to biased importance propagation favoring shallow-layer outputs. This bias results in the retention of redundant visual tokens and suboptimal pruning, as deep-layer semantic features are suppressed by overwhelming early-layer attention dynamics. Empirical analysis (Figure 1a) demonstrates the disproportionate focus of initial 3D MLLM layers on visual tokens, culminating in inefficiencies detrimental to deployment on resource-constrained platforms.
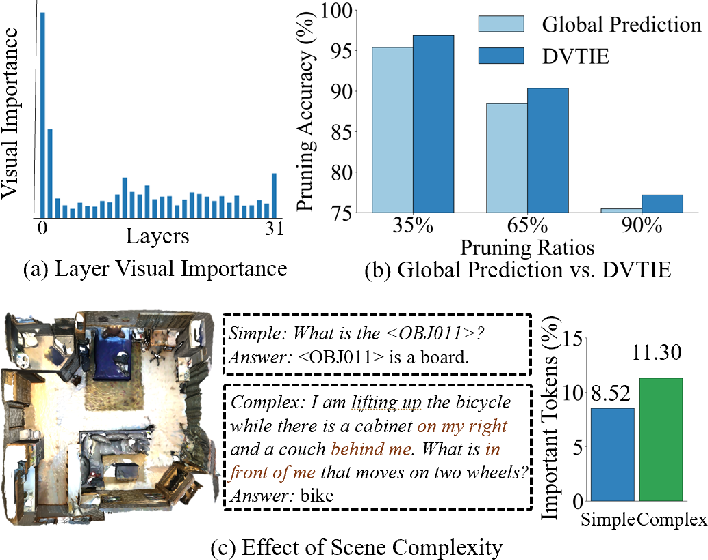
Figure 1: (a) Initial layers in 3D MLLM focus on visual tokens on ScanRefer; (b) DVTIE corrects pruning compared to global prediction; (c) Token pruning differs between simple (single-object) and complex (multi-object) questions.
Furthermore, prior methods largely rely on fixed pruning ratios, neglecting the semantic variability intrinsic to 3D visual question answering and scene captioning, where information needs differ substantially between queries of varying complexity. Such static approaches frequently either oversuppress or underexploit critical visual information, impairing cross-modal reasoning.
Efficient3D Framework Overview
Efficient3D comprises two principal components: the Debiased Visual Token Importance Estimator (DVTIE) and the Adaptive Token Rebalancing (ATR) strategy. The former targets attention aggregation bias by omitting initial layers during token importance computation, while the latter dynamically adapts pruning based on contextual scene complexity.
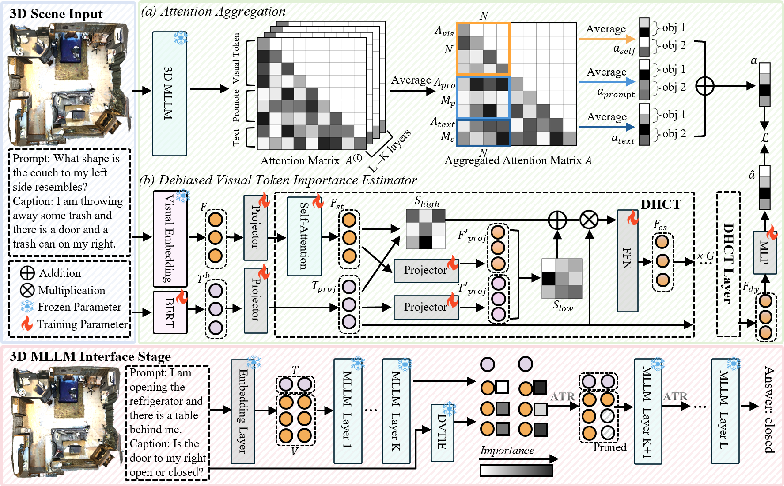
Figure 2: Efficient3D pipeline: (1) unpruned MLLM training and extraction of token importance, (2) DVTIE prediction supervision, and (3) inference-time pruning informed by DVTIE and adaptive ATR.
Debiased Visual Token Importance Estimator (DVTIE)
DVTIE is constructed around the observation that attention maps from deep MLLM layers are more discriminative for token importance estimation. By extracting and aggregating attention only from deeper layers (discarding the shallowest K layers), DVTIE delivers superior ranking and fidelity in visual token selection, aligning retained tokens with scene semantics and query intent. Attention supervision for DVTIE is multi-sourced—incorporating self-attention, prompt-aware, and caption-aware signals—facilitating nuanced importance prediction. Training employs a multi-objective loss that couples rank consistency with KL-divergence for attention distribution alignment.
Adaptive Token Rebalancing (ATR) Strategy
ATR introduces dynamic, context-aware pruning informed by both DVTIE's predictions and adaptive scaling ("shadow factor"). ATR adjusts the pruning ratio in real time, scaling suppression in proportion to scene complexity—complex multi-object queries retain more tokens, while simple single-object queries allow for aggressive compression. The pruning process is executed progressively from a designated layer, ensuring stability of attention distributions and preventing over-pruning through mask-based accumulation and thresholding on cumulative token importance.
Experimental Evaluation
The framework is evaluated across five major 3D vision-language benchmarks: ScanRefer (single-object grounding), Multi3DRefer (multi-object grounding), Scan2Cap (dense captioning), ScanQA, and SQA3D (visual question answering). Chat-Scene is adopted as the base MLLM, with DVTIE and ATR integrated for pruning and adaptation.
Notably, the Efficient3D framework demonstrates strong CIDEr improvements of +2.57% on Scan2Cap under a 35% pruning ratio, consistently surpassing both static and dynamic state-of-the-art methods at higher pruning rates. DVTIE's token retention under extreme pruning ratios (up to 90%) maintains baseline or superior performance, directly contradicting the common assumption that aggressive compression inherently degrades semantic coverage.

Figure 3: DVTIE under 35%, 65%, and 90% pruning—retained objects (orange) capture semantically critical elements; red boxes highlight query-referenced objects.
Ablation and Analysis
Comprehensive ablation confirms the criticality of both elements:
- Omitting shallow layers in aggregation for DVTIE targets directly increases accuracy, especially evident for Scan2Cap and SQA3D.
- DHCT layers in DVTIE outperform both basic cross-attention and high-rank alternatives, enhancing focus on informative tokens.
- Low-rank dimensionality tuning in DVTIE achieves optimal trade-offs at 64 dimensions.
- Multi-source attention targets provide substantial performance benefits in importance supervision.
- The ATR strategy synergizes with DVTIE, further reducing compute to as little as 0.38× baseline FLOPs while improving or equalling accuracy to unpruned models, a result not consistently achievable by static or prior dynamic pruning baselines.
Practical and Theoretical Implications
Efficient3D makes a compelling case for integrating learned, debiased importance measures and adaptive pruning into 3D MLLM pipelines, especially for real-time, resource-constrained inference. The modularity of the DVTIE and ATR components permits straightforward transplantation into future MLLM or specialized 3D architectures. The empirical evidence for improved generalization and retention of semantic content under extreme pruning regimes challenges established heuristics about pruning-accuracy trade-offs.
Theoretically, Efficient3D's approach to attention debiasing and context-sensitive compression sets groundwork for more interpretable and controllable token pruning methods. Future directions may include extending DVTIE for cross-domain adaptation or leveraging ATR in reinforcement learning settings for online pruning ratio selection.
Conclusion
Efficient3D (2604.02689) presents a unified, effective approach to efficient inference in 3D MLLMs by coupling debiased visual token importance estimation with adaptive pruning mechanisms. This framework minimizes computational overhead without sacrificing, and sometimes enhancing, model accuracy and semantic expressiveness. The demonstrated improvements invite broader adoption and further exploration of context-aware token reduction strategies in multimodal LLM architectures.