- The paper presents GoToHunt, a training-free hierarchical algorithm that scales Visual Geometry Transformers by reducing global attention complexity.
- It employs a two-stage process: diversity-driven inter-frame selection and layer-adaptive intra-frame pruning, optimizing token efficiency.
- Empirical results show over 85% inference time reduction on 500-frame inputs, with competitive or improved accuracy in 3D reconstruction tasks.
Introduction and Motivation
Visual Geometry Transformers (VGTs) have emerged as leading architectures for feed-forward multi-view 3D reconstruction, enabling joint prediction of geometric attributes (e.g., camera parameters, depth maps, pointmaps) from large image collections in a single forward pass. Despite their substantial advancements over optimization-based pipelines, these models are handicapped by the quadratic computational complexity of global attention layers—specifically, O(N2L2) scaling in the number of input frames (N) and per-frame tokens (L). This computation bottleneck severely limits scalability, especially for dense and long-sequence inputs commonly required in practical 3D reconstruction scenarios.
The paper "Good Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers" (2605.23892) proposes GoToHunt, a principled, training-free algorithm for token selection in global attention layers. It introduces a two-stage hierarchical approach: the first stage selects diverse frames (inter-frame selection), and the second discards redundant tokens within each frame (intra-frame selection), enabling near-linear scaling with input sequence length.
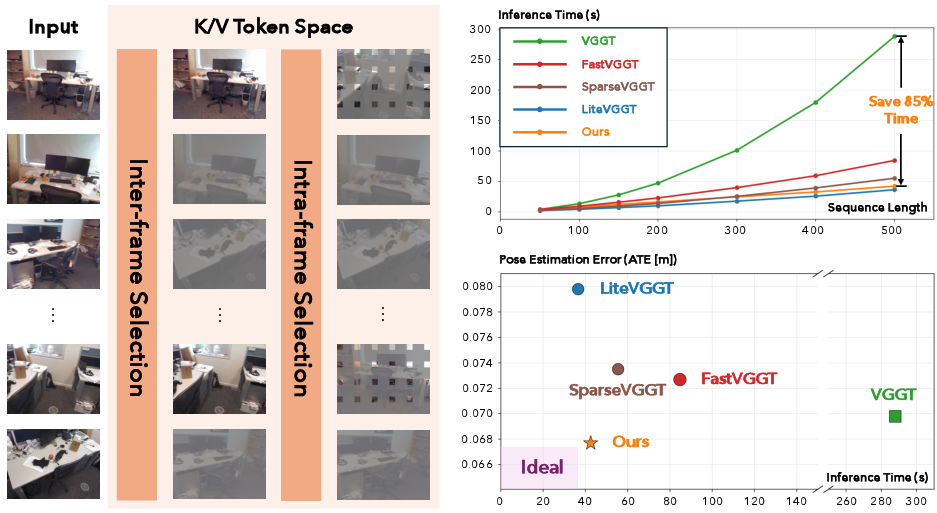
Figure 1: Hierarchical scheme accelerates VGTs via inter-frame and intra-frame token selection, achieving near-linear inference scaling and competitive speed-accuracy ratios compared to retrained solutions like LiteVGGT.
Two-Stage Token Selection Pipeline
GoToHunt operates by restricting each query token's interaction to a carefully selected budget of key/value tokens. Rather than brute-force selection across all input tokens or costly full-model retraining, the algorithm hierarchically narrows token interaction: (1) inter-frame selection identifies a distinct subset of frames; and (2) intra-frame selection prunes irrelevant tokens within each selected frame.
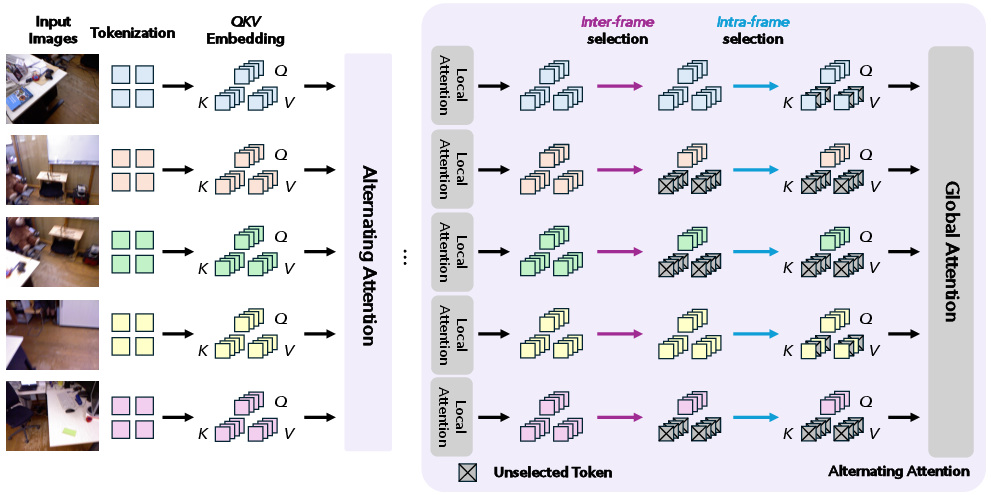
Figure 2: GoToHunt pipeline: Token selection is performed in K/V space prior to global attention, organized as inter-frame followed by intra-frame selection.
Inter-frame Selection: Maximizing Scene Coverage
Empirical analysis shows that naive strategies—such as temporal proximity, co-visibility maximization, or activation-based selection—lead to considerable accuracy degradation. GoToHunt instead leverages diversity-driven frame selection inspired by keyframe SLAM: using a farthest point sampling (FPS) heuristic to maximize coverage in feature space. Each query attends to a common set of anchor frames, consistently representing the scene's spatial diversity. This minimizes the largest distance from any frame to the closest selected anchor, solving a classical K-center objective efficiently.

Figure 3: Farthest-point sampled anchor frames (red) form a diverse subset among input views (blue), optimizing coverage under limited computational budgets.
Intra-frame Selection: Layer-Adaptive Token Pruning
Uniform downsampling of tokens within selected frames, as used in prior methods (e.g., AVGGT), results in non-negligible performance drops. Attention pattern analysis reveals that global attention layers in VGTs exhibit diluted near-uniform distributions in early layers and strongly peaked activations in later layers.
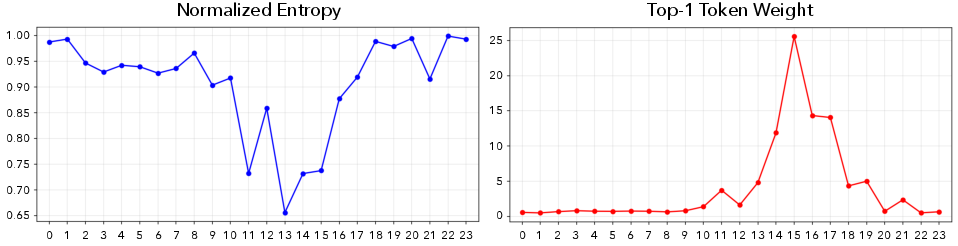
Figure 4: Attention pattern analysis across 24 global attention layers: early layers display diluted near-uniform distributions, while mid/late layers are more selective and peaked.
This motivates layer-adaptive token pruning:
- Early layers: Aggressive intra-frame downsampling is safe as attention is highly diluted and less informative.
- Middle layers: Conservative pruning is necessary; tokens with high activation should be retained to avoid disrupting critical attention dynamics.
- Late layers: Conservative or moderate pruning is used depending on the entropy and attention pattern.
Combining these, GoToHunt applies local attention or aggressive pruning in early layers, standard downsampling in intermediate ones, and activation-aware strategies in highly selective late layers. Performance remains robust to partitioning thresholds, demonstrating insensitivity to hyperparameter choices and validating the practical applicability across VGT architectures.
Empirical Results
GoToHunt demonstrates a superior speed-quality tradeoff across diverse benchmarks. With 500 input frames, it reduces inference time by over 85% compared to base VGGT and consistently outperforms prior training-free and retrained acceleration methods (e.g., FastVGGT, SparseVGGT, LiteVGGT, Speed3R) both in camera pose estimation and point cloud reconstruction. Notably, GoToHunt occasionally improves baseline performance—a counter-intuitive result attributed to mitigation of attention dilution in global layers.
On video depth estimation tasks, GoToHunt successfully operates on sequences exceeding 800 frames without memory bottlenecks, outperforming base models. Inference time scales near-linearly with sequence length, substantially improving efficiency for long input sequences.
Theoretical and Practical Implications
The study establishes that optimized token selection schemes can effectively circumvent the quadratic cost bottleneck inherent in global attention layers. The diversity-driven frame selection and entropy-informed intra-frame pruning principles provide guidance for designing routing-based attention mechanisms and layer-wise sparsification protocols in future architectures.
The occasional improvement in performance upon aggressive token selection challenges the assumption that maximal context always yields maximal accuracy—suggesting that attention dilution is detrimental and global attention layers may benefit from architectural rethinking, including possible layer skipping or hierarchical sparsification.
Practically, GoToHunt democratizes large-scale 3D reconstruction: its training-free nature enables scalable deployment on modest hardware without retraining, facilitating real-time applications and robust performance in resource-constrained scenarios.
Future Directions
GoToHunt’s hierarchical principles are likely to be extensible to broader transformer paradigms, including streaming visual geometry, dynamic scene reconstruction, and integration with test-time training (TTT) modules for further efficiency gains. Combining diversity-based token routing with adaptive sparsification may produce architectures capable of handling kilometer-scale environments and edge deployment in robotics and AR.
The theoretical insights into attention entropy, anchor frame selection, and layer partitioning are expected to inform future work on scalable transformer architectures and efficient 3D vision pipelines both in academic and industrial contexts.
Conclusion
GoToHunt introduces a general, training-free hierarchical token selection framework that allows visual geometry transformers to scale efficiently and retain or even improve prediction accuracy relative to baseline and retrained models. Its diversity-based inter-frame selection and layer-adaptive intra-frame pruning principles challenge simplistic assumptions about global context and offer robust, empirically validated guidelines for the next generation of efficient transformer-based 3D reconstruction architectures (2605.23892).

