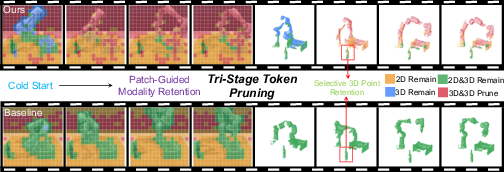
- The paper presents a tri-stage token pruning framework that leverages dynamic 2D and 3D salience analysis to accelerate MVLA inference with minimal accuracy loss.
- It employs a systematic three-stage approach—preprocessing, semantic synthesis, and temporal adaptation—that achieves a speedup of up to 2.69x while maintaining robust task performance.
- Experimental evaluations in simulation and real-world settings validate the framework's scalability and effectiveness in enabling efficient, real-time robotic control.
Tri-Stage Token Pruning with Modality Salience Awareness in Multi-Visual-Modal VLA Models
Introduction and Motivation
The recent evolution of Vision-Language-Action (VLA) models has led to the widespread deployment of multi-visual-modal architectures (MVLA) that integrate both 2D and 3D sensory modalities for embodied AI control. While this expansion to 3D point clouds alongside 2D images significantly augments spatial perception and manipulation capabilities, it also introduces a steep rise in sequence lengths due to an increased number of input tokens. These enlarged token sequences escalate inference latency and computational overhead—inhibiting real-time robotic control and limiting practical deployment. Traditional token pruning techniques, initially developed for single-visual-modal (SVLA) models, do not account for the discrepant task relevance and salience between 2D and 3D modalities in MVLA settings. The paper addresses this critical limitation by proposing a principled, tri-stage analysis of token salience and a matching tri-stage token pruning framework with explicit modality awareness, yielding substantial acceleration with negligible loss in policy performance (2604.09244).
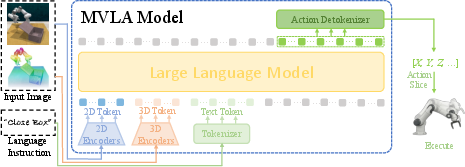
Figure 2: Standard MVLA architectures combine 2D/3D encoders, an LLM backbone, and action decoders with concatenated visual tokens and instructions.
Analysis of Modality Salience Across MVLA Inference
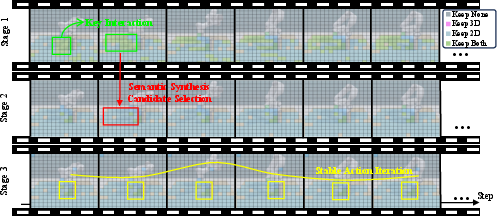
The core insight is that modality salience—i.e., the contribution of 2D and 3D features to downstream decisions—varies dynamically not just across modalities, but also as a function of inference stage and task phase. The authors conduct a comprehensive, three-stage analysis:
- Data Preprocessing Stage: Here, feature norm statistics from the final model layer reveal that, generally, 2D tokens exhibit higher salience than 3D tokens. Pruning experiments show pronounced degradation when 2D tokens are pruned, but often improved or stable performance when pruning 3D tokens, indicating that redundancy in 3D information is more tolerable for many tasks.
- Semantic Synthesis Stage: The model’s attention matrices are clustered to partition visual tokens into semantic regions (background, robot, object). Analysis demonstrates that 2D salience dominates in backgrounds, while 3D tokens gain prominence in certain task-critical regions—especially the robot and manipulation targets. Furthermore, overlapping redundant representations (i.e., orthogonal/parallel attention) can be decomposed to isolate irreducible modality contributions.
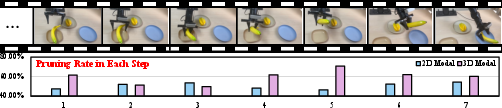
- Action Iteration Stage: During real-time control, the modality salience distribution is not static: temporal evolution (as shown via rolling averages of norm and attention-based metrics) indicates the necessity of temporal smoothing and adaptive decision policies to avoid flicker and instability in pruning masks.
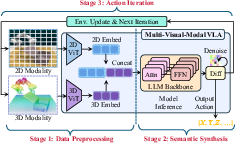
Figure 3: The MVLA inference data flow is segmented into preprocessing, semantic fusion, and actuation with dynamic token importance.
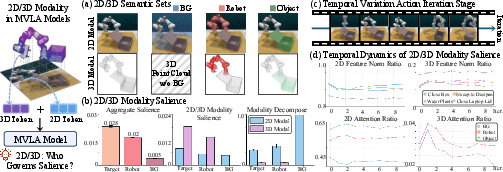
Figure 4: Salience decomposition during semantic fusion (a) and temporal dynamics in action iteration (b).
Tri-Stage Token Pruning Framework
Building on the tri-stage analysis, the authors design a matching tri-stage pruning scheme:
- Stage 1 (Preprocessing Candidate Selection): Patch-level modality preference is estimated via feature norms and mapped into pruning candidate sets using a dual-threshold scheme, isolating regions retainable by only 2D, only 3D, or both.
- Stage 2 (Semantic Synthesis Pruning): Attention-driven clustering subdivides visual patches by semantic role; pruning rates are then adaptively assigned with semantic and modality salience constraints—e.g., aggressive random pruning for backgrounds (up to 90%), semantic safeguarding for object/robot patches, and fallbacks for ambiguous intersections.
- Stage 3 (Temporal Adaptation): All per-modality/region metrics are temporally smoothed using EMA and sliding window mechanisms, enabling adaptive, predictive mask updates that prevent oscillations and ensure stable control even under sensor/scene variations.
Candidate sets from all three stages are fused (intersection with conflict resolution) to generate final retention masks. The result is a coarse-to-fine, semantically driven, and temporally stable pruning pipeline, maximizing speed without compromising task-critical token availability.
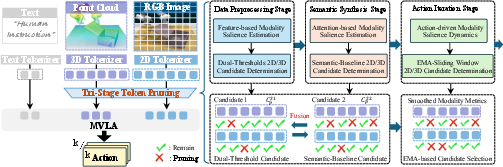
Figure 5: The tri-stage token pruning pipeline fuses stagewise candidate token sets for robust, dynamic inference acceleration.
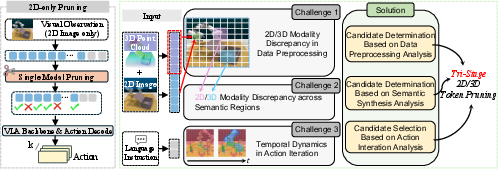
Figure 6: Comparison of naive and tri-stage token pruning, emphasizing the modality- and semantic-aware advantage of the proposed pipeline.

Figure 8: Visualization demonstrates gradual, context-driven updates in candidate selection during the “Take Umbrella” real-world task.
Experimental Evaluation
Simulation Results
Extensive simulation experiments on RLBench tasks validate the tri-stage framework. Compared to naively/uniformly pruned or SVLA-designed baselines (e.g., SP-VLA, VLA-Pruner), the method consistently achieves:
Real-World Experiments
Evaluated in real-robot deployments, the framework maintains robust real-time performance and effective policy stabilization:
Ablation and Overhead
Ablation studies show strong complementarity between the three stages: semantic-aware pruning is critical for SR robustness, while temporal adaptation supplies most of the acceleration. The framework’s computational overhead is modest (5.8% total), confirmed by step-by-step runtime breakdowns.
Implications and Future Directions
The tri-stage modality-aware approach provides a systematic, interpretable, and highly effective alternative to uniform or SVLA-derived pruning paradigms for MVLA models. By directly quantifying token relevance at each processing and semantic level, this framework facilitates robust pruning policies that adapt to changing sensory conditions, complex manipulation scenes, and real-world noise. Important practical advances include:
Conclusion
The paper provides a comprehensive modality salience analysis and proposes a principled, tri-stage token pruning framework that substantially accelerates MVLA inference by leveraging stage-specific, semantic, and temporal token relevance. Numerical results demonstrate strong superiority over baselines, low sensitivity to hyperparameters, and practical deployability in real robotic control. This methodology lays groundwork for future advances in efficient, scalable, and adaptive multi-modal embodied AI.