- The paper introduces a novel semantic–geometric token pruning method that reduces token count significantly while maintaining or improving 3D QA accuracy.
- It employs a dual-stage process combining 3D-aware feature construction with saliency and geometry-based diversified token selection to optimize multi-view feature aggregation.
- The approach achieves up to 86% latency reduction and retains only 23% of tokens on ScanQA, demonstrating robustness even under extreme token compression.
SeGPruner: Semantic–Geometric Visual Token Pruner for 3D Question Answering
Introduction and Contribution
SeGPruner introduces a paradigm for visual token selection in 3D Question Answering (3D QA) using off-the-shelf Vision-LLMs (VLMs) that process multi-view 2D images. Standard multi-view token aggregation leads to massive redundancy, prohibiting efficient deployment under constrained token budgets. Existing pruning solutions either operate in pure 2D space or use weak geometric cues, failing to both explicitly preserve semantically critical tokens and guarantee diverse spatial coverage. SeGPruner addresses these limitations by enforcing a semantic–geometry aware selection process, resulting in improved reasoning fidelity while providing significant token and latency reductions.
Methodology
SeGPruner is an inference-time module inserted between the visual encoder and the LLM, decomposed into three stages:
- 3D-Aware Feature Construction: Visual tokens are back-projected into a unified 3D coordinate frame using calibrated depth maps and camera poses for all input views, supporting spatial comparisons of tokens across viewpoints.
- Saliency-aware Token Selector: High-importance tokens are scored using column-averaged attention maps from the visual encoder, ensuring that object-centric and context-relevant tokens are preserved. Top-k tokens by attention are selected as salient.
- Geometry-aware Token Diversifier: After salient token selection, the remaining tokens are sampled to maximize 3D spatial coverage while penalizing semantic redundancy. A semantic–spatial fusion metric is computed by combining normalized Euclidean distances in 3D and feature similarities, iteratively selecting farthest-point tokens as in FPS.
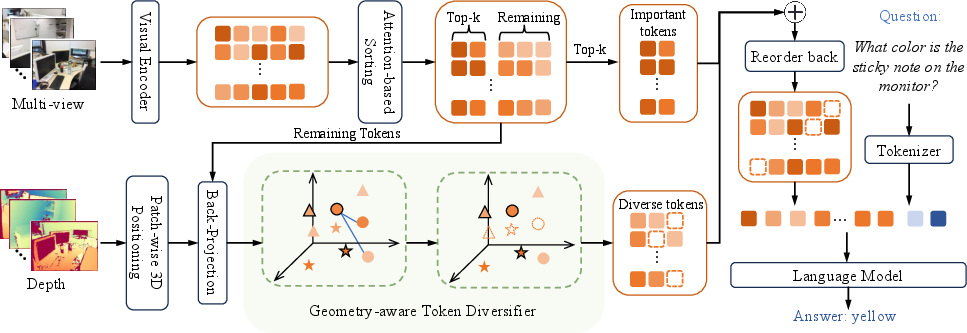
Figure 1: SeGPruner's architecture interleaves saliency importance and geometry-aware diversification between multi-view visual encoding and LLM processing, yielding compact tokens for robust cross-modal reasoning.
Formally, for each visual patch, its back-projected world coordinate is
ci=∣Ωi∣1p∈Ωi∑Π(d(p),K−1,T)
Tokens are aggregated across all views for downstream importance and diversity selection. Distance for diversification is
drjgeo=λdx∣∣cr−cj∣∣2+(1−λ)(1−srj)
with srj the cosine similarity, λ the fusion coefficient.
The final reduced token set comprises the union of salient and spatially diverse tokens, concatenated and fed to the LLM for question answering.
Experimental Results
SeGPruner is evaluated with LLaVA-OneVision-7B on ScanQA and OpenEQA, the de-facto benchmarks for open-vocabulary 3D QA and embodied multi-modal reasoning. The module is strictly training-free and preserves the backbone's weights.
Efficiency Gains:
- On ScanQA, only 23% of original visual tokens are retained, and inference latency is reduced by 86%.
- Even more aggressive pruning (down to 9% retention) delivers 95.3% of the base accuracy, demonstrating robustness to extreme token budgets.
Accuracy Preservation:
- SeGPruner often matches or slightly surpasses the base model's EM@1 score at moderate retention, due to the removal of redundant or misleading tokens.
- At 23% retention, SeGPruner outperforms both DTC (3D-only) and VisPruner (2D attention-based), highlighting the complementary benefit of saliency and spatial diversity.
- On OpenEQA, SeGPruner gives higher LLM-Match scores compared to both baselines under aggressive reduction.
These results support a bold claim: purely attention-based or purely geometric reduction is outperformed by their principled integration as in SeGPruner, especially under tight inference constraints.
(Figure 2)
Figure 2: 2D-only pruning leads to background redundancy, while geometric token selection guarantees object-centric and spatially even coverage in 3D QA settings.
Ablation and Qualitative Analysis
Ablations reveal that removing either the Saliency-aware Token Selector or the Geometry-aware Token Diversifier reduces accuracy, and uniform/semantic-only baselines degrade rapidly when retention is harsh. The two modules provide complementary error correction—saliency for object importance, diversity for structural coverage.
Qualitative outputs (see ablation studies and qualitative figures in the paper) demonstrate that SeGPruner preserves both key objects and fine-grained spatial/structural details, preventing information loss typical in uniform or 2D-only approaches. This is further validated by point cloud visualizations, where SeGPruner's token set reconstructs scene geometry and object completeness superior to baselines.
Practical and Theoretical Implications
Practically, SeGPruner enables the deployment of multi-view VLMs for 3D QA in latency or memory-constrained environments (e.g., robotics, AR/VR, or mobile), by reducing token counts without architectural retraining or external supervision. Theoretically, its results support the hypothesis that joint semantic and spatial modeling is indispensable for robust 3D scene understanding, even when only multi-view 2D images are available.
Methodologically, SeGPruner's separation of saliency preservation and spatial diversification defines an extensible template for future inference-time token selection research. The fusion metric can be further generalized for dynamic balancing or augmented with external geometric priors.
Future Research Directions
- Extension to dynamic scenes and temporal reasoning by incorporating 4D space-time token representations.
- Adaptive tuning of the semantic–geometric trade-off coefficient (λ) via downstream feedback or reinforcement signals.
- Integration with more advanced or structurally aware visual encoders (e.g., spatial transformers with explicit 3D positional encoding).
- Exploration of hierarchical token pruning for scalable long-context multi-modal models in real-time applications.
Conclusion
SeGPruner operationalizes a semantic–geometry aware token reduction module that achieves substantial inference acceleration for multi-view 3D QA with negligible loss, or even improvement, in accuracy. Its principled decomposition into salient object-centric and geometry-aware diverse token selection sets a new standard for plug-and-play VLM compression in spatial reasoning tasks, with strong implications for efficient embodied AI.
(2603.29437)